
 TensorRT 8.2 optimizes HuggingFace T5 and GPT-2 models. With TensorRT-accelerated GPT-2 and T5, you can generate excellent human-like texts and build real-time translation, summarization, and other online NLP applications within strict latency requirements.
TensorRT 8.2 optimizes HuggingFace T5 and GPT-2 models. With TensorRT-accelerated GPT-2 and T5, you can generate excellent human-like texts and build real-time translation, summarization, and other online NLP applications within strict latency requirements.
The transformer architecture has wholly transformed (pun intended) the domain of natural language processing (NLP). Over the recent years, many novel network architectures have been built on the transformer building blocks: BERT, GPT, and T5, to name a few. With increasing variety, the size of these models has also rapidly increased.
While larger neural language models generally yield better results, deploying them for production poses serious challenges, especially for online applications where a few tens of ms of extra latency can negatively affect the user experience significantly.
With the latest TensorRT 8.2, we optimized T5 and GPT-2 models for real-time inference. You can turn the T5 or GPT-2 models into a TensorRT engine, and then use this engine as a plug-in replacement for the original PyTorch model in the inference workflow. This optimization leads to a 3–6x reduction in latency compared to PyTorch GPU inference, and a 9–21x compared to PyTorch CPU inference.
In this post, we give you a detailed walkthrough of how to achieve the same latency reduction, using our newly published example scripts and notebooks based on Hugging Face transformers for the tasks of open-end text generation with GPT-2 and translation and summarization with T5.
Introduction to T5 and GPT-2
In this section, we briefly explain the T5 and GPT-2 models.
T5 for answering questions, summarization, translation, and classification
T5 or Text-To-Text Transfer Transformer is a recent architecture created by Google. It reframes all natural language processing (NLP) tasks into a unified text-to-text format where the input and output are always text strings. T5’s architecture enables applying the same model, loss function, and hyperparameters to any NLP task such as machine translation, document summarization, question answering, and classification tasks such as sentiment analysis.
The T5 model was inspired by the fact that transfer learning has produced state-of-the-art results in NLP. The principle behind transfer learning is that a model pretrained on abundantly available untrained data with self-supervised tasks can be fine-tuned for specific tasks on smaller task-specific labeled datasets. These models have proven to have better results than models trained on task-specific datasets from scratch.
Based on the concept of Transfer Learning, Google proposed the T5 model in Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. In this paper, they also introduced the Colossal Clean Crawled Corpus (C4) dataset. The T5 model, pretrained on this dataset achieves state-of-the-art results on many downstream NLP tasks. Published pretrained T5 models range up to 3B and 11B parameters.
GPT-2 for generating excellent human-like texts
Generative Pre-Trained Transformer 2 (GPT-2) is an auto-regressive unsupervised language model originally proposed by OpenAI. It is built from the transformer decoder blocks and trained on very large text corpora to predict the next word in a paragraph. It generates excellent human-like texts. Larger GPT-2 models, with the largest reaching 1.5B parameters, generally write better, more coherent texts.
Deploying T5 and GPT-2 with TensorRT
With TensorRT 8.2, we optimize the T5 and GPT-2 models by building and using a TensorRT engine as a drop-in replacement for the original PyTorch model. We walk you through scripts and Jupyter notebooks and highlight the important bits, which are based on Hugging Face transformers. For more information, see the example scripts and notebooks for a detailed step-by-step execution guide.
Setting up
The most convenient way to get started is by using a Docker container, which provides an isolated, self-contained, and reproducible environment for the experiments.
Build and launch a TensorRT container:
git clone -b master https://github.com/nvidia/TensorRT TensorRgit clone -b master https://github.com/nvidia/TensorRT TensorRT cd TensorRT git checkout release/8.2 git submodule update --init --recursive ./docker/build.sh --file docker/ubuntu-18.04.Dockerfile --tag tensorrt-ubuntu18.04-cuda11.4 ./docker/launch.sh --tag tensorrt-ubuntu18.04-cuda11.4 --gpus all --jupyter 8888
These commands start the Docker container and JupyterLab. Open the JupyterLab interface in your web browser:
http://:8888/lab/
In JupyterLab, to open a terminal window, choose File, New, Terminal. Compile and install the TensorRT OSS package:
cd $TRT_OSSPATH mkdir -p build && cd build cmake .. -DTRT_LIB_DIR=$TRT_LIBPATH -DTRT_OUT_DIR=`pwd`/out make -j$(nproc)
Now you are ready to proceed with experimenting with the models. In the following sequence, we demonstrate the steps for the T5 model. The following code blocks are not meant to be copy-paste runnable but rather walk you through the process. For reproduction purposes, see the notebooks on the GitHub repository.
At a high level, optimizing a Hugging Face T5 and GPT-2 model with TensorRT for deployment is a three-step process:
- Download models from the HuggingFace model zoo.
- Convert the model to an optimized TensorRT execution engine.
- Carry out inference with the TensorRT engine.
Use the generated engine as a plug-in replacement for the original PyTorch model in the HuggingFace inference workflow.
Download models from the HuggingFace model zoo
First, download the original Hugging Face PyTorch T5 model from HuggingFace model hub, together with its associated tokenizer.
T5_VARIANT = 't5-small' t5_model = T5ForConditionalGeneration.from_pretrained(T5_VARIANT) tokenizer = T5Tokenizer.from_pretrained(T5_VARIANT) config = T5Config(T5_VARIANT)
You can then employ this model for various NLP tasks, for example, translating from English to German:
print(tokenizer.decode(outputs[0], skip_special_tokens=Truinputs = tokenizer("translate English to German: That is good.", return_tensors="pt")
# Generate sequence for an input
outputs = t5_model.to('cuda:0').generate(inputs.input_ids.to('cuda:0'))
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
TensorRT 8.2 supports GPT-2 up to the “xl” version (1.5B parameters) and T5 up to 11B parameters, which are publicly available on the HuggingFace model zoo. Larger models can also be supported subject to GPU memory availability.
Converting the model to an optimized TensorRT execution engine.
Before converting the model to a TensorRT engine, you convert the PyTorch model to an intermediate universal format. ONNX is an open format for machine learning and deep learning models. It enables you to convert deep learning and machine-learning models from different frameworks such as TensorFlow, PyTorch, MATLAB, Caffe, and Keras to a single unified format.
Converting to ONNX
For the T5 model, convert the encoder and decoder separately using a utility function.
encoder_onnx_model_fpath = T5_VARIANT + "-encoder.onnx"
decoder_onnx_model_fpath = T5_VARIANT + "-decoder-with-lm-head.onnx"
t5_encoder = T5EncoderTorchFile(t5_model.to('cpu'), metadata)
t5_decoder = T5DecoderTorchFile(t5_model.to('cpu'), metadata)
onnx_t5_encoder = t5_encoder.as_onnx_model(
os.path.join(onnx_model_path, encoder_onnx_model_fpath), force_overwrite=False
)
onnx_t5_decoder = t5_decoder.as_onnx_model(
os.path.join(onnx_model_path, decoder_onnx_model_fpath), force_overwrite=False
)
Converting to TensorRT
Now you are ready to parse the T5 ONNX encoder and decoder and convert them to optimized TensorRT engines. As TensorRT carries out many optimizations, such as fusing operations, eliminating transpose operations, and kernel auto-tuning to find the best performing kernel on a target GPU architecture, this conversion process might take a while.
t5_trt_encoder_engine = T5EncoderONNXt5_trt_encoder_engine = T5EncoderONNXFile(
os.path.join(onnx_model_path, encoder_onnx_model_fpath), metadata
).as_trt_engine(os.path.join(tensorrt_model_path, encoder_onnx_model_fpath) + ".engine")
t5_trt_decoder_engine = T5DecoderONNXFile(
os.path.join(onnx_model_path, decoder_onnx_model_fpath), metadata
).as_trt_engine(os.path.join(tensorrt_model_path, decoder_onnx_model_fpath) + ".engine")
Carry out inference with the TensorRT engine
Finally, you now have an optimized TensorRT engine for the T5 model, ready to carry out inference.
t5_trt_encoder = T5TRTEncoder(
t5_trt_encoder_engine, metadata, tfm_config
)
t5_trt_decoder = T5TRTDecoder(
t5_trt_decoder_engine, metadata, tfm_config
)
#generate output
encoder_last_hidden_state = t5_trt_encoder(input_ids=input_ids)
outputs = t5_trt_decoder.greedy_search(
input_ids=decoder_input_ids,
encoder_hidden_states=encoder_last_hidden_state,
stopping_criteria = StoppingCriteriaList([MaxLengthCriteria(max_length)])
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Similarly, for the GPT-2 model, you can follow the same process to generate a TensorRT engine. The optimized TensorRT engines can be used as a plug-in replacement for the original PyTorch models in the HuggingFace inference workflow.
TensorRT transformer optimization specifics
Transformer-based models are a stack of either transformer encoder or decoder blocks. Encoder (decoder) blocks have the same architecture and number of parameters. T5 consists of stacks of transformer encoders and decoders, while GPT-2 is composed of only transformer decoder blocks (Figure 1).
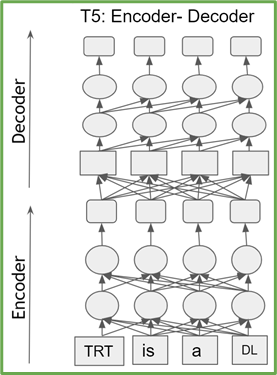
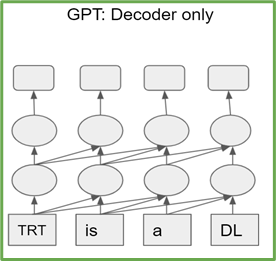
Each transformer block, also known as the self-attention block, consists of three projections by using fully connected layers to project the input into three different subspaces, termed query (Q), key (K), and value (V). These matrices are then transposed, with QT and KT being used to compute the normalized dot-product attention values, before being combined with VT to produce the final output (Figure 2).
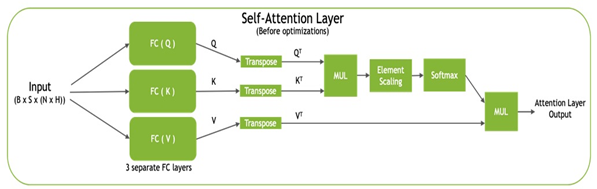
TensorRT optimizes the self-attention block by pointwise layer fusion:
- Reduction is fused with power ops (for LayerNorm and residual-add layer).
- Scale is fused with softmax.
- GEMM is fused with ReLU/GELU activations.
Additionally, TensorRT also optimizes the network for inference:
- Eliminating transpose ops.
- Fusing the three KQV projections into a single GEMM.
- When FP16 mode is specified, controlling layer-wise precisions to preserve accuracy while running the most compute-intensive ops in FP16.
TensorRT vs. PyTorch CPU and GPU benchmarks
With the optimizations carried out by TensorRT, we’re seeing up to 3–6x speedup over PyTorch GPU inference and up to 9–21x speedup over PyTorch CPU inference.
Figure 3 shows the inference results for the T5-3B model at batch size 1 for translating a short phrase from English to German. The TensorRT engine on an A100 GPU provides a 21x reduction in latency compared to PyTorch running on a dual-socket Intel Platinum 8380 CPU.
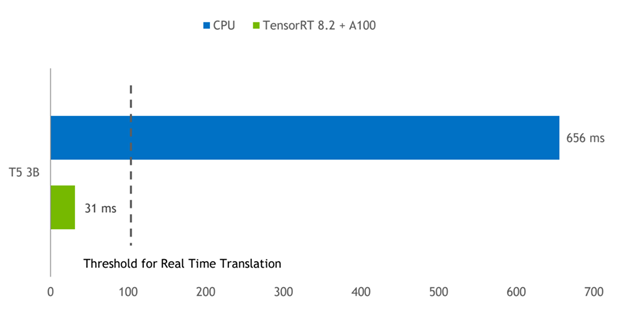
CPU: Intel Platinum 8380, 2 sockets.
GPU: NVIDIA A100 PCI Express 80GB. Software: PyTorch 1.9, TensorRT 8.2.0 EA.
Task: “Translate English to German: that is good.”
Conclusion
In this post, we walked you through converting the Hugging Face PyTorch T5 and GPT-2 models to an optimized TensorRT engine for inference. The TensorRT inference engine is used as a drop-in replacement for the original HuggingFace T5 and GPT-2 PyTorch models and provides up to 21x CPU inference speedup. To achieve this speedup for your model, get started today with TensorRT 8.2.