
 Use NVIDIA CloudXR alongside AWS to build immersive XR experiences from the cloud for key advantages at every stage from development to distribution.
Use NVIDIA CloudXR alongside AWS to build immersive XR experiences from the cloud for key advantages at every stage from development to distribution.
Creating immersive applications with high-fidelity 3D graphics has never been more accessible thanks to recent advances in extended reality (XR) hardware and software. Despite this growth, developing augmented reality (AR) and virtual reality (VR) applications still come with challenges:
- Large investments must be made in local development workstations.
- Computing power of end-user devices is still limited.
- Deploying applications to distributed users can introduce management and security complexities.
By using NVIDIA CloudXR alongside Amazon NICE DCV streaming protocols, you can use on-demand compute resources for all aspects of your immersive application development. This includes services to support end-to-end workflows, tight control over the security of your data, and simplifying the management of deploying and delivering application updates.
Advantages of AWS and NVIDIA CloudXR
Production-grade interactive XR applications require a collection of supporting technologies to successfully build, deliver, and consume content. The advent of microservices from cloud infrastructure has made it easier to deploy these components to an end-to-end solution. The compute, storage, and networking resources of Amazon Web Services (AWS) can be used to develop, deploy, and distribute XR applications. These can then be remotely rendered and streamed using NVIDIA CloudXR over distributed networks.
Leveraging both AWS and NVIDIA CloudXR presents several advantages:
- First, reliable cloud networks and security tools provide a consistent security boundary around your valuable data.
- Second, this solution makes it possible to remotely render high fidelity, low latency, experiences with globally available, graphics accelerated instances.
- Finally, providing on-demand resources for distributed XR development teams enables you to scale your workforce with little operational overhead.
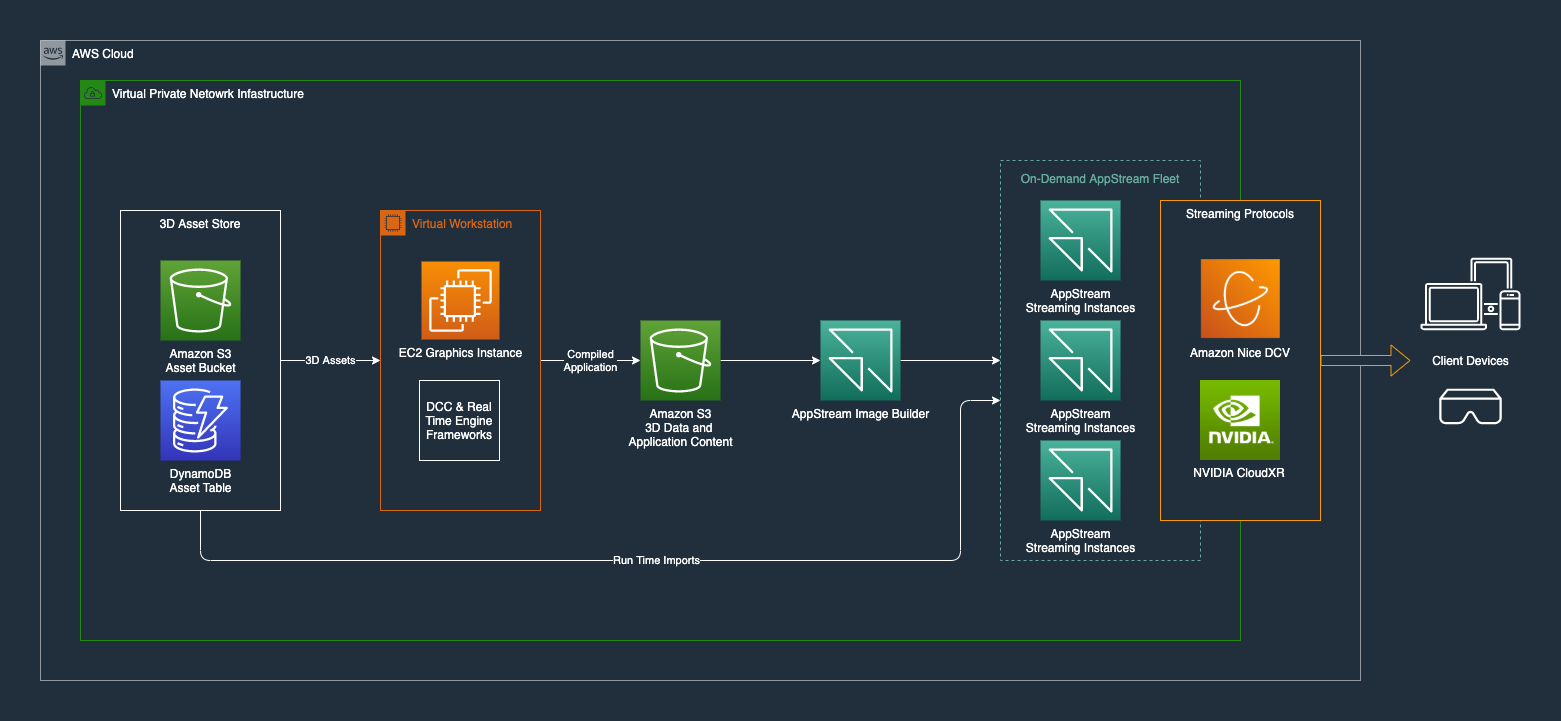
Figure 1 demonstrates an example configuration of NVIDIA CloudXR with AWS services to develop, deploy, and distribute XR applications.
CloudXR overview
NVIDIA CloudXR is an SDK that enables you to implement real-time GPU rendering and streaming of rich VR, AR, and XR applications on remote servers, including the cloud. Applications that typically require tethered HMDs can connect and stream remotely on low-powered VR devices or tablets without degrading performance.
NVIDIA CloudXR fulfills the key component of XR streaming and enables AWS customers to use the cloud for end-to-end XR application development. The NVIDIA CloudXR Amazon Machine Image is bundled with RTX Virtual Workstation and currently supports Amazon EC2 G4 instances.
NICE DCV overview
Amazon NICE DCV is a high-performance remote display protocol. It lets you securely deliver remote desktops and application streaming from any cloud or data center to any device, over varying network conditions. By using NICE DCV with Amazon EC2, you can run graphics-intensive applications remotely on Amazon EC2 instances.
Powered by the latest NVIDIA GPUs, NICE DCV delivers low-latency performance for artists and developers building next-generation immersive applications. You can then stream the results to more modest client machines, eliminating the need for expensive dedicated workstations.
Managing content in the cloud
Streaming applications require content in order to be useful. When creating an asset management pipeline for immersive applications in the cloud, AWS services like Amazon Simple Storage Service (S3), Amazon DynamoDB (a NoSQL low-latency database), and Amazon API Gateway serve as core components.
- S3 becomes the datastore for storing 3D assets and application build artifacts.
- DynamoDB tables are used for storing and accessing asset metadata and application server information.
- API Gateway acts as the front door to your data in AWS that your client-side immersive application interacts with.
When your application is ready to be deployed, build artifacts can be sent from S3 to Amazon AppStream 2.0, a fully managed nonpersistent desktop and application-streaming service, or an NVIDIA GPU-equipped Amazon EC2 instance. These instances are also configured with an NVIDIA CloudXR SDK server, which allows them to receive requests from devices loaded with the NVIDIA CloudXR client.

Summary
By streaming experiences with NVIDIA CloudXR, data never leaves the data center. Globally available AWS instances allow you to render experiences close to your end users, but NVIDIA CloudXR does the heavy lifting to reduce the perceived latency and provide a smooth experience for end users. Using NVIDIA CloudXR as part of your development and testing process means you can build applications for the same target platform for testing as well as final deployment.
Using NVIDIA CloudXR to stream immersive experiences from the AWS cloud, you can deliver high-fidelity graphics to untethered AR and VR devices. With development workstations running NICE DCV on Amazon EC2, you can spin up graphics workstations for your team from any location. The AWS cloud for development, deployment, and distribution of your immersive applications is a highly scalable, secure, and resilient single source of truth for all of your 3D content.
Next steps
To get started with NVIDIA CloudXR on AWS, see the NVIDIA CloudXR AMI listed on the AWS Marketplace.
For more information about running virtual workstations on AWS, see Nimble Studio, which gives you the tools to get up and running quickly, with graphics workstations streamed from the cloud.
Finally, be sure to check out AppStream 2.0, a fully managed service to deploy streaming applications to any type of device.





