
 This post details the latest functionality of RAPIDS Accelerator for Apache Spark.
This post details the latest functionality of RAPIDS Accelerator for Apache Spark.
RAPIDS Accelerator for Apache Spark v21.10 is now available! As an open source project, we value our community, their voice, and requests. This release constitutes community requests for operations that are ideally suited for GPU acceleration.
Important callouts for this release:
- Speed up – performance improvements and cost savings.
- New Functionality – new I/O and nested datatype Qualification and Profiling tool features.
- Community Updates – updates to the spark-examples repository.
Speed up
RAPIDS Accelerator for Apache Spark is growing at a great pace in both functionality and performance. Standard industry benchmarks are a great way to measure performance over a period of time but another barometer to measure performance is to measure performance of common operators that are used in the data preprocessing stage or in data analytics.
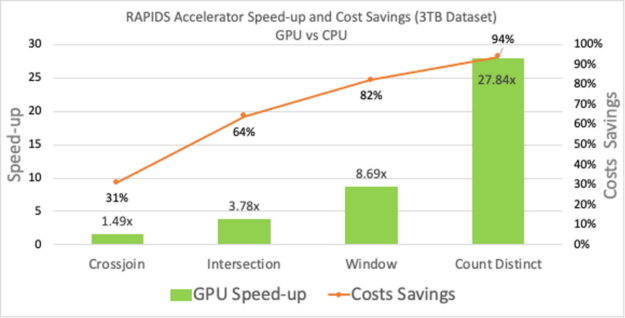
We used four such queries shown in the chart below:
- Count Distinct: a function used to estimate the number of unique page views or unique customers visiting an e-commerce site.
- Window: a critical operator necessary for preprocessing components in analyzing timestamped event data in marketing or financial industry.
- Intersect: an operator used to remove duplicates in a dataframes.
- Cross-join: A common use for a cross join is to obtain all combinations of items.
These queries were run on a Google Cloud Platform (GCP) machine with 2xT4 GPUs each with 104GB RAM. The dataset used was of size 3TB with multiple different data types. More information about the setup and the queries can be found in the spark-rapids-examples repository on GitHub. These four queries show not only performance and cost benefits but also the range of speed-up (27x to 1.5x) varies depending on compute intensity. These queries vary in compute and network utilization similar to a practical use case in data preprocessing.
New functionality
Plug-in
Most Apache Spark users are aware that Spark 3.2 was released this October. The v21.10 release has support for Spark 3.2 and CUDA 11.4. In this release, we focused on expanding support for I/O, nested data processing and machine learning functionality. RAPIDS Accelerator for Apache Spark v21.10 released a new plug-in jar to support machine learning in Spark.
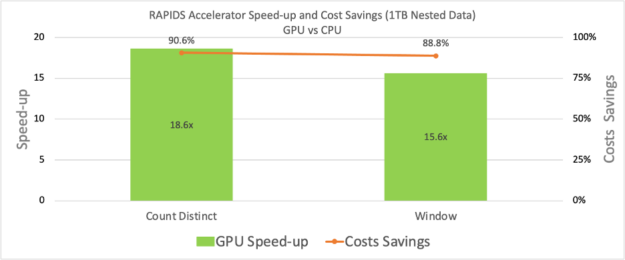
Currently, this jar supports training for the Principal Component Analysis algorithm. The ETL jar extended the input type support for Parquet and ORC. It now also provides users with the functionality to use HashAggregate, Sort, Join SHJ and Join BHJ on nested data. In addition to support for nested datatypes a performance test was also run.
In the figure below, we show that the speed-up is observed for two queries using nested data type input. Some other interesting features that were added in v21.10 are, pos_explode, create_map and so on. Please refer to RAPIDS Accelerator for Apache Spark’s documentation for a detailed list of new features.
Profiling & qualification tool
In addition to the plug-in, multiple new features were also added to RAPIDS Accelerator for Apache Spark’s Qualification and Profiling tool. The Qualification tool can now report the different nested datatypes and write data formats present. It now also includes support for adding conjunction and disjunction filters, and filter based Regular Expressions and usernames.
The Qualifications tool is not the only one with new tricks: the Profiling tool now provides structured output format and support to scale and run a large number of event logs.
Community updates
We are excited to announce that we are in public preview on Azure and we welcome Azure users to try RAPIDS Accelerated for Apache Spark on Azure Synapse.
We invite you to view our talks presented at NVIDIA’s flagship event, GTC, held from Nov. 8-11, to learn how AI is transforming the world. The RAPIDS Accelerator team presented two talks; Accelerating Apache Spark gives an overview of new functionality and other upcoming features. Also, Discover Common Apache Spark Operations Turbocharged with RAPIDS and NVIDIA GPUs covers many microbenchmarks on Apache Spark.
Coming soon
The upcoming versions will introduce support for 128-bit decimal datatype, inference support for the Principle Component Analysis algorithm and additional nested data type support for multi-level struct and maps.
In addition, lookout for MIG support for NVIDIA Ampere Architecture based GPUs (A100/A30) which can help improve throughput on running multiple spark jobs with A100. As always, we want to thank all of you for using RAPIDS Accelerator for Apache Spark and we look forward to hearing from you. Reach out to us on GitHub and let us know how we can continue to improve your experience using RAPIDS Accelerator on Apache Spark.