
 Learn industry insights and best practice when implementing data science and AI at the edge.
Learn industry insights and best practice when implementing data science and AI at the edge.
Whether your organization is new to data science or has a mature strategy in place, many come to a similar realization: Most data does not originate at the core.
Scientists often want access to amounts of data that are unreasonable to securely stream to the data center in real time. Whether the distance is 10 miles or thousands of miles, the bounds of traditional IT infrastructure are simply not designed to stretch outside of fixed campuses.
This has led organizations to realize that no data science strategy is complete without an edge strategy.
Read on to learn industry insights on the benefits of coupling data science and edge computing, the challenges faced, solutions to these challenges, and register to view a demo of an edge architecture blueprint.
Edge Architectures
Edge computing is a style of IT architecture that is typically employed to create systems that are tolerant of geographically distributed data sources and high latency and low-bandwidth interconnects.
Due to restrictions imposed by the operating environment, computing systems designed in this way are typically identifiable by compromises on computational speed and high availability.
Today, there are three types of edge architectures that are commonly being used by organizations: streaming data, edge preprocessing, and autonomous systems.
Edge Architecture 1: Streaming data
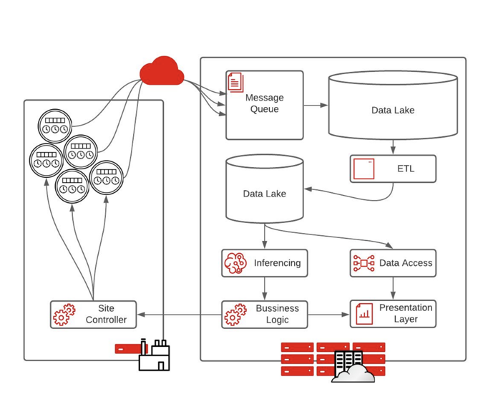
Today, streaming data, the “classical big data” architecture, is the most popular prototypical architecture for organizations that are just starting to implement an edge strategy. This architecture starts with IoT devices, usually sensors, placed anywhere from a factory floor, hospital, or retail store. The data is then sent through the cloud to an IT system.
As data processing abilities increase, the classic big data architecture can be a hindrance because of the level of infrastructure required and the large quantity of data that needs to move from the edge to core.
Edge Architecture 2: Edge Pre-Processing
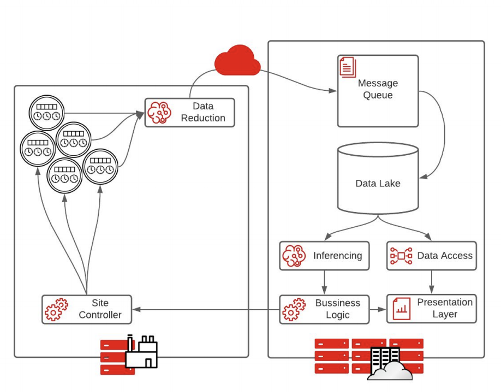
The edge preprocessing model is the most common architecture for organizations transitioning to the edge.
Instead of sensor data feeding directly into a pipeline running in the data center, data is fed into an intelligent data reduction application. This is usually an intelligent machine-learning algorithm that decides what data is important and needs to be sent back to the data center.
Extraction, transformation, and loading (ETL) processes are less important in these architectures because data reduction has already occurred at the edge. Therefore, there is no need for two data lakes, and inference can happen more quickly. The result is faster execution on business logic.
This is a good stepping stone for creating fully autonomous systems, allowing for an unlimited amount of data compression.
Edge Architecture 3: Autonomous Systems
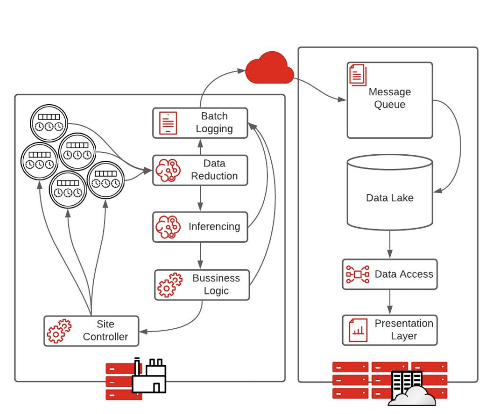
Fully autonomous systems are characterized by sensors collecting data at the edge to make rapid decisions with low latency. With no time to send data back to a data center or cloud to make a proper decision, processing happens at the edge and actions are taken automatically.
With this architecture, every step of the pipeline is sent to a logging mechanism to record the decisions made at the edge. The batch logging will send messages to the cloud or core data center to allow for analytics and system adjustments on the decisions made.
Industry Insights for Building the Intelligent Edge
Building an intelligent edge solution is not just about pushing a container to tens or thousands of sites. While it may seem like a trivial task, your organization’s success relies heavily on the infrastructure that you put in place, not just the data science.
There are many complexities that need to be taken into consideration when building an intelligent edge solution such as scale, interoperability, and consistency.
Suggested technologies to build intelligent solutions are:
- Linux edge systems
- Containers
- Kubernetes
- Messaging protocols (Kafka, MQTT, BYO)
Edge Infrastructure in Practice
As organizations look to meet their business needs and enable data science to drive innovation, your options should not be limited to your architecture. Implementing an edge architecture will help you future-proof your platform against new use cases and technologies.
While it is helpful to understand where your architecture stands among different stages of edge implementation, it is often best to view a live demonstration.
For more information, view our webinar, “Data Scientists on the Loose: Lessons Learned while Enabling the Intelligent Edge” for best practice regarding how to implement a Kubernetes system at the edge and the capabilities it can give your organization.
Or, learn more about edge computing and data science.