Posted by Sneha Kudugunta, Research Software Engineer and Orhan Firat, Research Scientist, Google Research
Scaling large language models has resulted in significant quality improvements natural language understanding (T5), generation (GPT-3) and multilingual neural machine translation (M4). One common approach to building a larger model is to increase the depth (number of layers) and width (layer dimensionality), simply enlarging existing dimensions of the network. Such dense models take an input sequence (divided into smaller components, called tokens) and pass every token through the full network, activating every layer and parameter. While these large, dense models have achieved state-of-the-art results on multiple natural language processing (NLP) tasks, their training cost increases linearly with model size.
An alternative, and increasingly popular, approach is to build sparsely activated models based on a mixture of experts (MoE) (e.g., GShard-M4 or GLaM), where each token passed to the network follows a separate subnetwork by skipping some of the model parameters. The choice of how to distribute the input tokens to each subnetwork (the “experts”) is determined by small router networks that are trained together with the rest of the network. This allows researchers to increase model size (and hence, performance) without a proportional increase in training cost.
While this is an effective strategy at training time, sending tokens of a long sequence to multiple experts, again makes inference computationally expensive because the experts have to be distributed among a large number of accelerators. For example, serving the 1.2T parameter GLaM model requires 256 TPU-v3 chips. Much like dense models, the number of processors needed to serve an MoE model still scales linearly with respect to the model size, increasing compute requirements while also resulting in significant communication overhead and added engineering complexity.
In “Beyond Distillation: Task-level Mixture-of-Experts for Efficient Inference”, we introduce a method called Task-level Mixture-of-Experts (TaskMoE), that takes advantage of the quality gains of model scaling while still being efficient to serve. Our solution is to train a large multi-task model from which we then extract smaller, stand-alone per-task subnetworks suitable for inference with no loss in model quality and with significantly reduced inference latency. We demonstrate the effectiveness of this method for multilingual neural machine translation (NMT) compared to other mixture of experts models and to models compressed using knowledge distillation.
Training Large Sparsely Activated Models with Task Information
We train a sparsely activated model, where router networks learn to send tokens of each task-specific input to different subnetworks of the model associated with the task of interest. For example, in the case of multilingual NMT, every token of a given language is routed to the same subnetwork. This differs from other recent approaches, such as the sparsely gated mixture of expert models (e.g., TokenMoE), where router networks learn to send different tokens in an input to different subnetworks independent of task.
Inference: Bypassing Distillation by Extracting Subnetworks
A consequence of this difference in training between TaskMoE and models like TokenMoE is in how we approach inference. Because TokenMoE follows the practice of distributing tokens of the same task to many experts at both training and inference time, it is still computationally expensive at inference.
For TaskMoE, we dedicate a smaller subnetwork to a single task identity during training and inference. At inference time, we extract subnetworks by discarding unused experts for each task. TaskMoE and its variants enable us to train a single large multi-task network and then use a separate subnetwork at inference time for each task without using any additional compression methods post-training. We illustrate the process of training a TaskMoE network and then extracting per-task subnetworks for inference below.
 |
| During training, tokens of the same language are routed to the same expert based on language information (either source, target or both) in task-based MoE. Later, during inference we extract subnetworks for each task and discard unused experts. |
To demonstrate this approach, we train models based on the Transformer architecture. Similar to GShard-M4 and GLaM, we replace the feedforward network of every other transformer layer with a Mixture-of-Experts (MoE) layer that consists of multiple identical feedforward networks, the “experts”. For each task, the routing network, trained along with the rest of the model, keeps track of the task identity for all input tokens and chooses a certain number of experts per layer (two in this case) to form the task-specific subnetwork. The baseline dense Transformer model has 143M parameters and 6 layers on both the encoder and decoder. The TaskMoE and TokenMoE that we train are also both 6 layers deep but with 32 experts for every MoE layer and have a total of 533M parameters. We train our models using publicly available WMT datasets, with over 431M sentences across 30 language pairs from different language families and scripts. We point the reader to the full paper for further details.
Results
In order to demonstrate the advantage of using TaskMoE at inference time, we compare the throughput, or the number of tokens decoded per second, for TaskMoE, TokenMoE, and a baseline dense model. Once the subnetwork for each task is extracted, TaskMoE is 7x smaller than the 533M parameter TokenMoE model, and it can be served on a single TPUv3 core, instead of 64 cores required for TokenMoE. We see that TaskMoE has a peak throughput twice as high as that of TokenMoE models. In addition, on inspecting the TokenMoE model, we find that 25% of the inference time has been spent in inter-device communication, while virtually no time is spent in communication by TaskMoE.
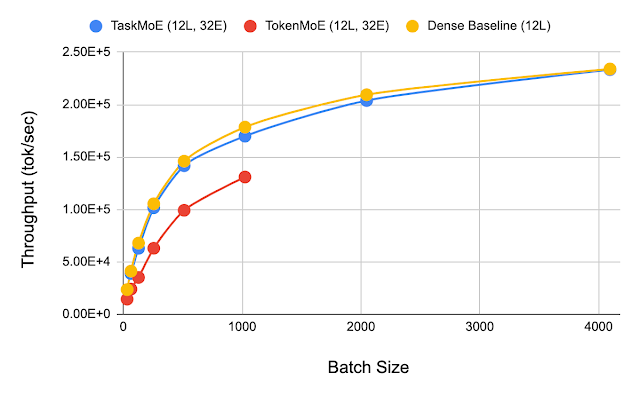 |
| Comparing the throughput of TaskMoE with TokenMoE across different batch sizes. The maximum batch size for TokenMoE is 1024 as opposed to 4096 for TaskMoE and the dense baseline model. Here, TokenMoE has one instance distributed across 64 TPUv3 cores, while TaskMoE and the baseline model have one instance on each of the 64 cores. |
A popular approach to building a smaller network that still performs well is through knowledge distillation, in which a large teacher model trains a smaller student model with the goal of matching the teacher’s performance. However, this method comes at the cost of additional computation needed to train the student from the teacher. So, we also compare TaskMoE to a baseline TokenMoE model that we compress using knowledge distillation. The compressed TokenMoE model has a size comparable to the per-task subnetwork extracted from TaskMoE.
We find that in addition to being a simpler method that does not need any additional training, TaskMoE improves upon a distilled TokenMoE model by 2.1 BLEU on average across all languages in our multilingual translation model. We note that distillation retains 43% of the performance gains achieved from scaling a dense multilingual model to a TokenMoE, whereas extracting the smaller subnetwork from the TaskMoE model results in no loss of quality.
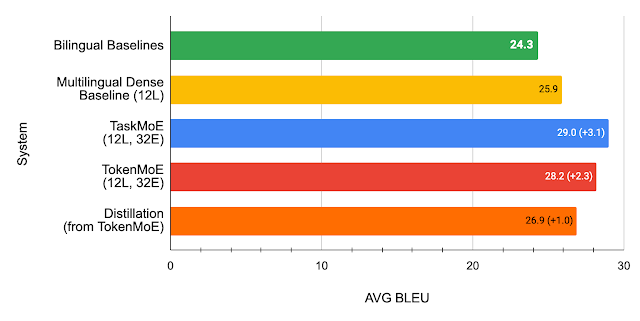 |
| BLEU scores (higher is better) comparing a distilled TokenMoE model to the TaskMoE and TokenMoE models with 12 layers (6 on the encoder and 6 on the decoder) and 32 experts. While both approaches improve upon a multilingual dense baseline, TaskMoE improves upon the baseline by 3.1 BLEU on average while distilling from TokenMoE improves upon the baseline by 1.0 BLEU on average. |
Next Steps
The quality improvements often seen with scaling machine learning models has incentivized the research community to work toward advancing scaling technology to enable efficient training of large models. The emerging need to train models capable of generalizing to multiple tasks and modalities only increases the need for scaling models even further. However, the practicality of serving these large models remains a major challenge. Efficiently deploying large models is an important direction of research, and we believe TaskMoE is a promising step towards more inference friendly algorithms that retain the quality gains of scaling.
Acknowledgements
We would like to first thank our coauthors – Yanping Huang, Ankur Bapna, Maxim Krikun, Dmitry Lepikhin and Minh-Thang Luong. We would also like to thank Wolfgang Macherey, Yuanzhong Xu, Zhifeng Chen and Macduff Richard Hughes for their helpful feedback. Special thanks to the Translate and Brain teams for their useful input and discussions, and the entire GShard development team for their foundational contributions to this project. We would also like to thank Tom Small for creating the animations for the blog post.


") New CUDA 11.6 Toolkit is focused on enhancing the programming model and performance of your CUDA applications.
New CUDA 11.6 Toolkit is focused on enhancing the programming model and performance of your CUDA applications.
 The developer community for NVIDIA DOCA continues to gain momentum around the world.
The developer community for NVIDIA DOCA continues to gain momentum around the world. {kind=link}
{kind=link}