
 The NCCL 2.12 release significantly improves all2all communication collective performance, with the PXN feature.
The NCCL 2.12 release significantly improves all2all communication collective performance, with the PXN feature.
Collective communications are a performance-critical ingredient of modern distributed AI training workloads such as recommender systems and natural language processing.
NVIDIA Collective Communication Library (NCCL), a Magnum IO Library, implements GPU-accelerated collective operations:
- all-gather
- all-reduce
- broadcast
- reduce
- reduce-scatter
- point-to-point send and receive
NCCL is topology-aware and is optimized to achieve high bandwidth and low latency over PCIe, NVLink, Ethernet, and InfiniBand interconnect. NCCL GCP plugin and NCCL AWS plugin enable high-performance NCCL operations in popular cloud environments with custom network connectivity.
NCCL releases have been relentlessly focusing on improving collective communication performance. This post focuses on the improvements that come with the NCCL 2.12 release.
Combining NVLink and network communication
The new feature introduced in NCCL 2.12 is called PXN, as PCI × NVLink, as it enables a GPU to communicate with a NIC on the node through NVLink and then PCI. This is instead of going through the CPU using QPI or other inter-CPU protocols, which would not be able to deliver full bandwidth. That way, even though each GPU still tries to use its local NIC as much as possible, it can reach other NICs if required.
Instead of preparing a buffer on its local memory for the local NIC to send, the GPU prepares a buffer on an intermediate GPU, writing to it through NVLink. It then notifies the CPU proxy managing that NIC that the data is ready, instead of notifying its own CPU proxy. The GPU-CPU synchronization might be a little slower because it may have to cross CPU sockets, but the data itself only uses NVLink and PCI switches, guaranteeing maximum bandwidth.
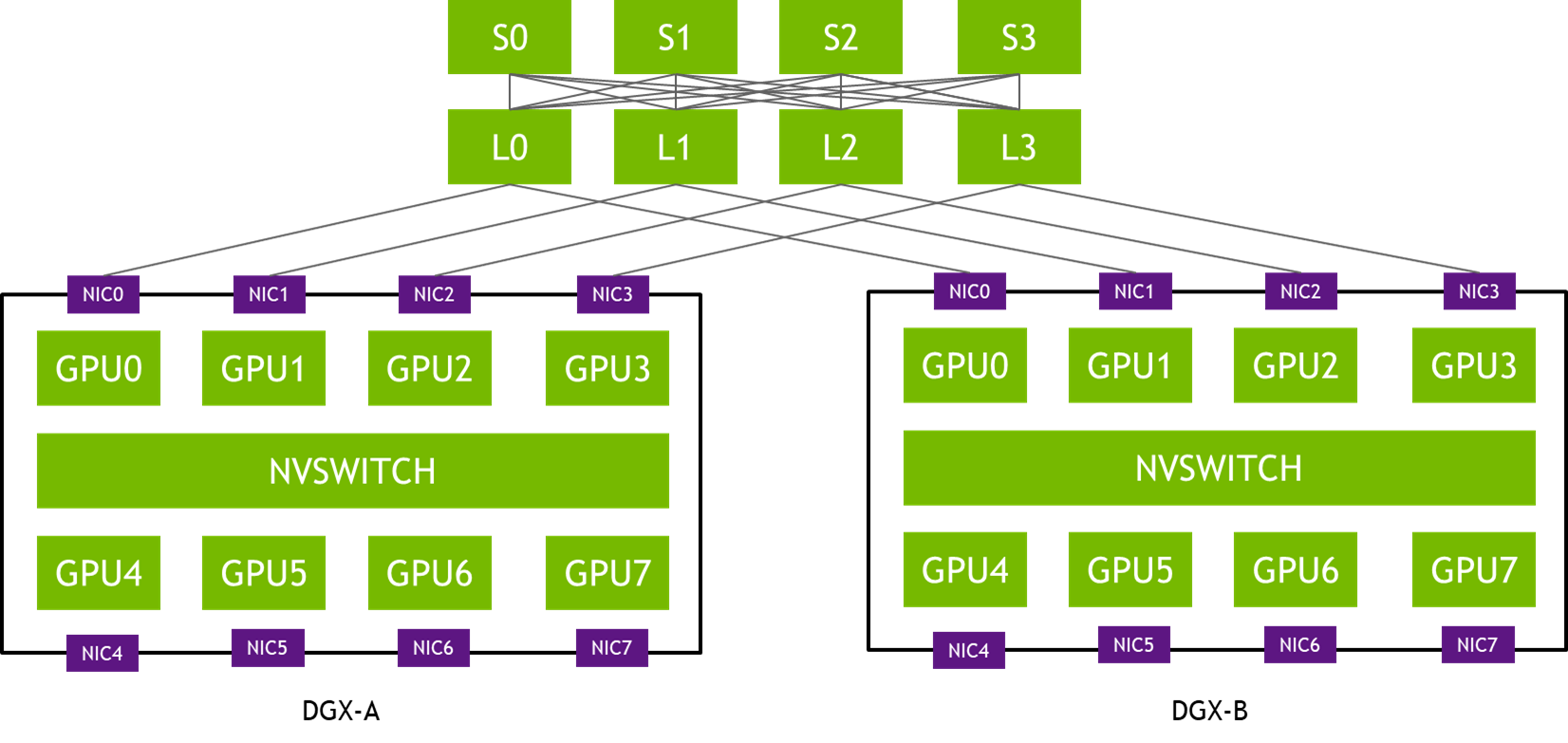
In the topology in Figure 1, NIC-0 from each DGX system is connected to the same leaf switch (L0), NIC-1s are connected to the same leaf switch (L1), and so on. Such a design is often called rail-optimized. Rail-optimized network topology helps maximize all-reduce performance while minimizing network interference between flows. It can also reduce the cost of the network by having lighter connections between rails.
PXN leverages NVIDIA NVSwitch connectivity between GPUs within the node to first move data on a GPU on the same rail as the destination, then send it to the destination without crossing rails. That enables message aggregation and network traffic optimization.
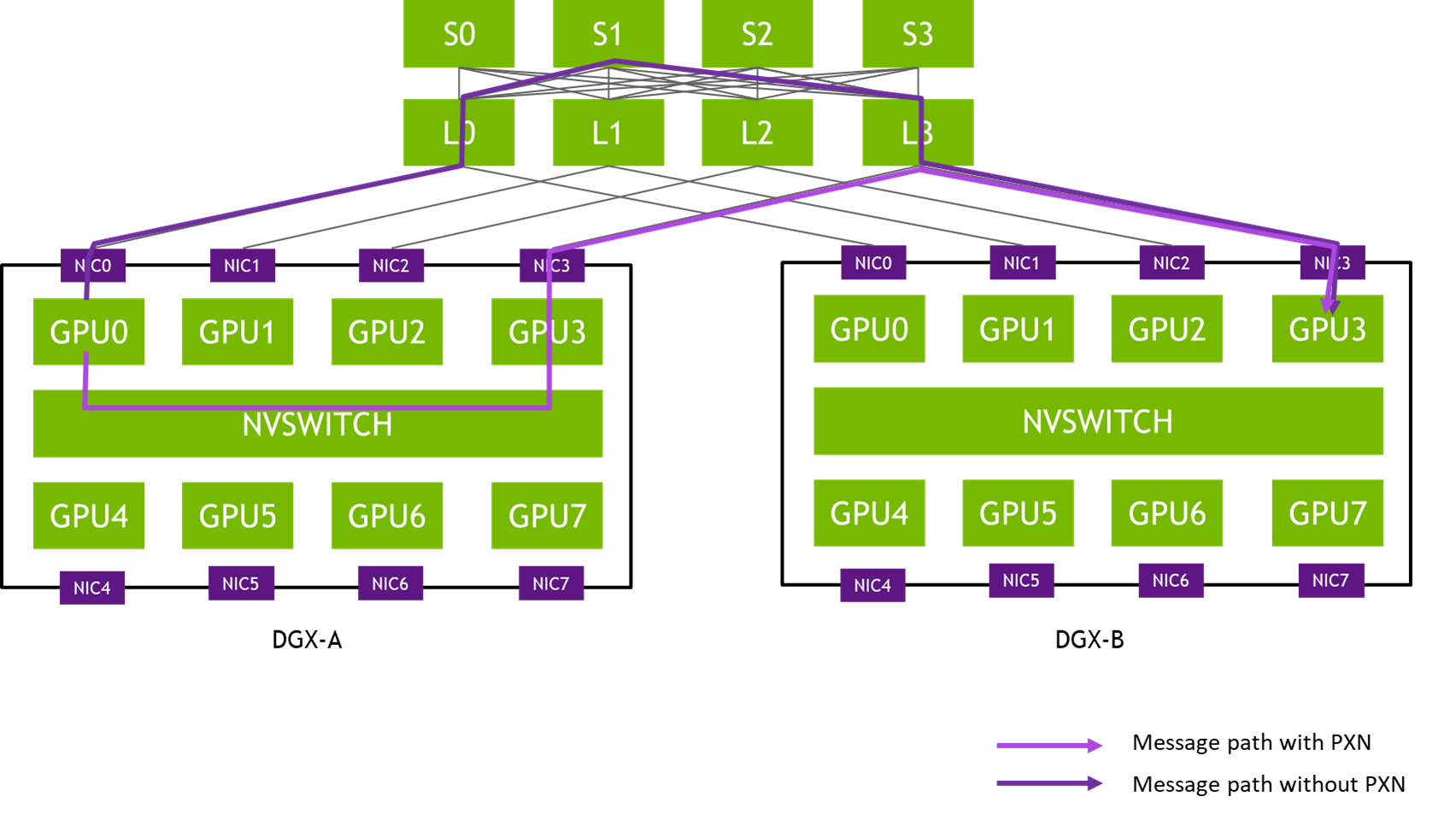
Before NCCL 2.12, the message in Figure X would have traversed through three hops of network switches (L0, S1, and L3), potentially causing contention and being slowed down by other traffic. The messages passed between the same pair of NICs are aggregated to maximize effective message rate and network bandwidth.
Message aggregation
With PXN, all GPUs on a given node move their data onto a single GPU for a given destination. This enables the network layer to aggregate messages, by implementing a new multireceive function. The function enables the remote CPU proxy to send all messages as one as soon as they are all ready.
For example, if a GPU on a node is performing an all2all operation and is to receive data from all eight GPUs from a remote node, NCCL calls a multireceive with eight buffers and sizes. On the sender side, the network layer can then wait until all eight sends are ready, then send all eight messages at one time, which can have a significant effect on the message rate.
Another aspect of message aggregation is that connections are now shared between all GPUs of a node for a given destination. This means fewer connections to establish. It can also affect the routing efficiency, if the routing algorithm was relying on having a lot of different connections to get good entropy.
PXN improves all2all performance
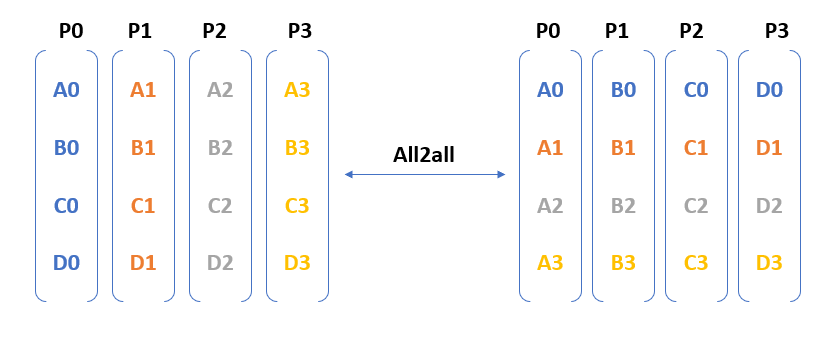
Figure 3 shows that all2all entails communication from each process to every other process. In other words, the number of messages exchanged as part of an all2all operation in an N-GPU cluster is $latex O(N^{2})$.
The messages exchanged between the GPUs are distinct and can’t be optimized using algorithms such as tree/ring (used for allreduce). When you run billion+ parameter models across 100s of GPUs, the number of messages can trigger congestion, create network hotspots, and adversely affect performance.
As discussed earlier, PXN combines NVLink and PCI communications to reduce traffic flow through the second-tier spine switches and optimizes network traffic. It also improves message rates by aggregating up to eight messages into one. Both improvements significantly improve all2all performance.
all-reduce on 1:1 GPU:NIC topologies
Another problem that PXN solves is the case of topologies where there is a single GPU close to each NIC. The ring algorithm requires two GPUs to be close to each NIC. Data must go from the network to a first GPU, go around all GPUs through NVLink, and then exit from the last GPU onto the network. The first and last GPUs must both be close to the NIC. The first GPU must be able to receive from the network efficiently, and the last GPU must be able to send through the network efficiently. If only one GPU is close to a given NIC, then you cannot close the ring and must send data through the CPU, which can heavily affect performance.
With PXN, as long as the last GPU can access the first GPU through NVLink, it can move its data to the first GPU. The data is sent from there to the NIC, keeping all transfers local to PCI switches.
This case is not only relevant for PCI topologies featuring one GPU and one NIC per PCI switch but can also happen on other topologies when an NCCL communicator only includes a subset of GPUs. Consider a node with 8xGPUs interconnected with an NVLink hypercube mesh.
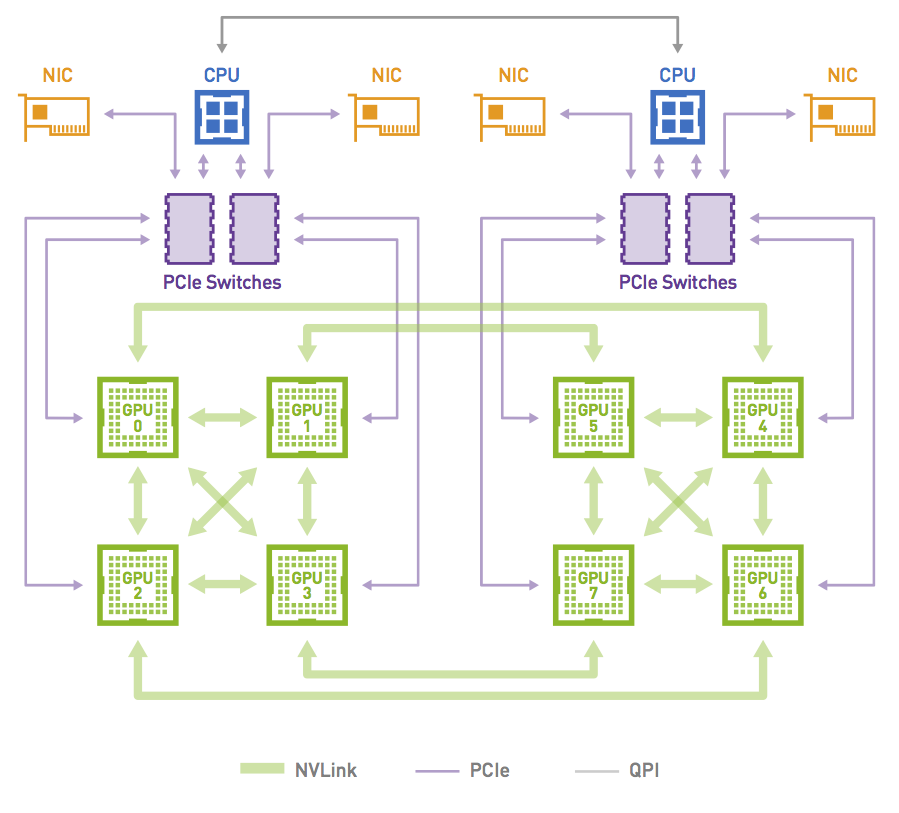
Figure 5 shows a ring that can be formed by leveraging the high-bandwidth NVLink connections that are available in the topology when the communicator includes all the 8xGPUs in the system. This is possible as both GPU0 and GPU1 share access to the same local NIC.
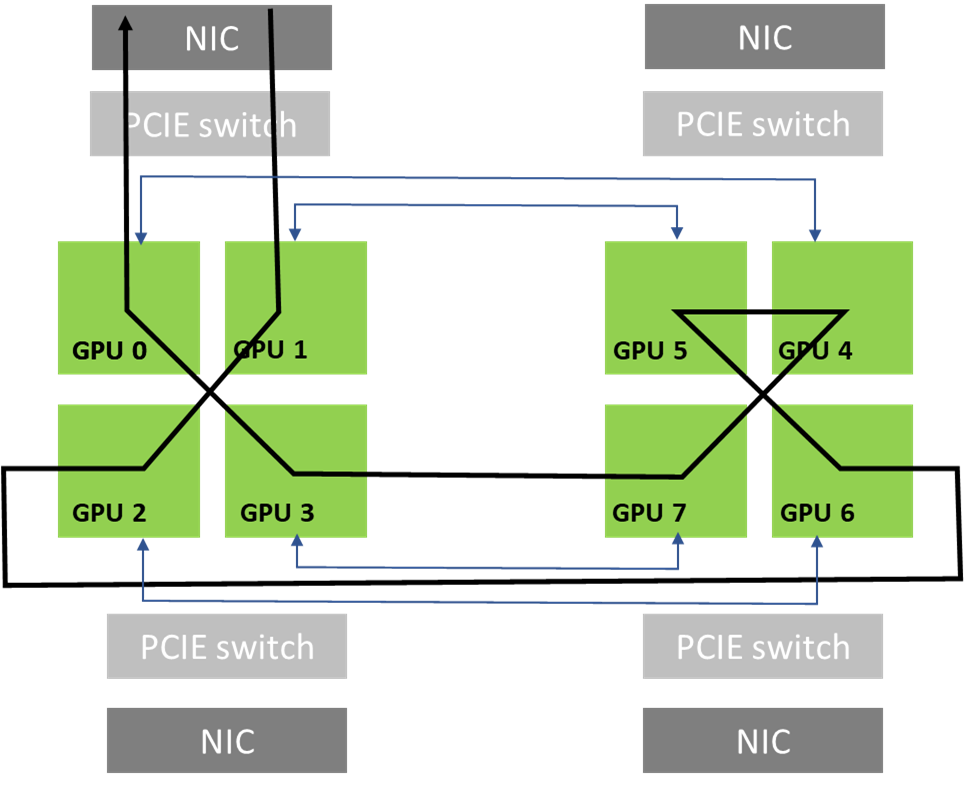
The communicator can just include a subset of the GPUs. For example, it can just include GPUs 0, 2, 4, and 6. In that case, creating rings is impossible without crossing rails: rings entering the node from GPU 0 would have to exit from GPUs 2, 4, or 6, which do not have direct access to the local NICs of GPUs 0 (NICs 0 and 1).
On the other hand, PXN enables rings to be formed as GPU 2 could move data back to GPU 0 before going through NIC 0/1.
This case is common with model parallelism, depending on how the model is split. If for example a model is split between GPUs 0-3, then another model runs on GPUs 4-7. That means GPU 0 and 4 take care of the same part of the model, and an NCCL communicator is created with all GPUs 0 and 4 on all nodes, to perform all-reduce operations for the corresponding layers. Those communicators can’t perform all-reduce operations efficiently without PXN.
The only way to have efficient model parallelism so far was to split the model on GPUs 0, 2, 4, 6 and 1, 3, 5, 7 so that NCCL subcommunicators would include GPUs [0,1], [2,3], [4,5] and [6,7] instead of [0,4], [1,5], [2,6], and [3,7]. The new PXN feature gives you more flexibility and eases the use of model parallelism.
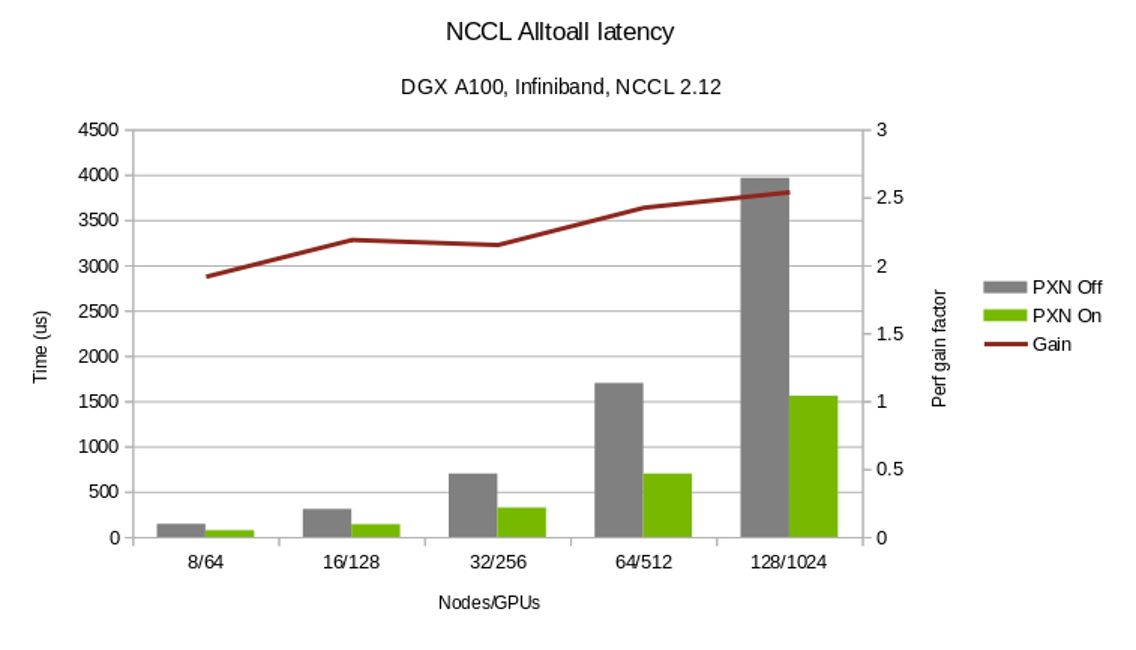
Figure 6 contrasts the time to complete alltoall collective operations with and without the PXN. In addition, PXN enables a more flexible choice of GPUs for all-reduce operations.
Summary
The NCCL 2.12 release significantly improves all2all communication collective performance. Download the latest NCCL release and experience the improved performance firsthand.