
In 2017, Google introduced federated learning (FL), an approach that enables mobile devices to collaboratively train machine learning (ML) models while keeping the raw training data on each user’s device, decoupling the ability to do ML from the need to store the data in the cloud. Since its introduction, Google has continued to actively engage in FL research and deployed FL to power many features in Gboard, including next word prediction, emoji suggestion and out-of-vocabulary word discovery. Federated learning is improving the “Hey Google” detection models in Assistant, suggesting replies in Google Messages, predicting text selections, and more.
While FL allows ML without raw data collection, differential privacy (DP) provides a quantifiable measure of data anonymization, and when applied to ML can address concerns about models memorizing sensitive user data. This too has been a top research priority, and has yielded one of the first production uses of DP for analytics with RAPPOR in 2014, our open-source DP library, Pipeline DP, and TensorFlow Privacy.
Through a multi-year, multi-team effort spanning fundamental research and product integration, today we are excited to announce that we have deployed a production ML model using federated learning with a rigorous differential privacy guarantee. For this proof-of-concept deployment, we utilized the DP-FTRL algorithm to train a recurrent neural network to power next-word-prediction for Spanish-language Gboard users. To our knowledge, this is the first production neural network trained directly on user data announced with a formal DP guarantee (technically ρ=0.81 zero-Concentrated-Differential-Privacy, zCDP, discussed in detail below). Further, the federated approach offers complimentary data minimization advantages, and the DP guarantee protects all of the data on each device, not just individual training examples.
Data Minimization and Anonymization in Federated Learning
Along with fundamentals like transparency and consent, the privacy principles of data minimization and anonymization are important in ML applications that involve sensitive data.
Federated learning systems structurally incorporate the principle of data minimization. FL only transmits minimal updates for a specific model training task (focused collection), limits access to data at all stages, processes individuals’ data as early as possible (early aggregation), and discards both collected and processed data as soon as possible (minimal retention).
Another principle that is important for models trained on user data is anonymization, meaning that the final model should not memorize information unique to a particular individual’s data, e.g., phone numbers, addresses, credit card numbers. However, FL on its own does not directly tackle this problem.
The mathematical concept of DP allows one to formally quantify this principle of anonymization. Differentially private training algorithms add random noise during training to produce a probability distribution over output models, and ensure that this distribution doesn’t change too much given a small change to the training data; ρ-zCDP quantifies how much the distribution could possibly change. We call this example-level DP when adding or removing a single training example changes the output distribution on models in a provably minimal way.
Showing that deep learning with example-level differential privacy was even possible in the simpler setting of centralized training was a major step forward in 2016. Achieved by the DP-SGD algorithm, the key was amplifying the privacy guarantee by leveraging the randomness in sampling training examples (“amplification-via-sampling”).
However, when users can contribute multiple examples to the training dataset, example-level DP is not necessarily strong enough to ensure the users’ data isn’t memorized. Instead, we have designed algorithms for user-level DP, which requires that the output distribution of models doesn’t change even if we add/remove all of the training examples from any one user (or all the examples from any one device in our application). Fortunately, because FL summarizes all of a user’s training data as a single model update, federated algorithms are well-suited to offering user-level DP guarantees.
Both limiting the contributions from one user and adding noise can come at the expense of model accuracy, however, so maintaining model quality while also providing strong DP guarantees is a key research focus.
The Challenging Path to Federated Learning with Differential Privacy
In 2018, we introduced the DP-FedAvg algorithm, which extended the DP-SGD approach to the federated setting with user-level DP guarantees, and in 2020 we deployed this algorithm to mobile devices for the first time. This approach ensures the training mechanism is not too sensitive to any one user’s data, and empirical privacy auditing techniques rule out some forms of memorization.
However, the amplification-via-samping argument is essential to providing a strong DP guarantee for DP-FedAvg, but in a real-world cross-device FL system ensuring devices are subsampled precisely and uniformly at random from a large population would be complex and hard to verify. One challenge is that devices choose when to connect (or “check in”) based on many external factors (e.g., requiring the device is idle, on unmetered WiFi, and charging), and the number of available devices can vary substantially.
Achieving a formal privacy guarantee requires a protocol that does all of the following:
- Makes progress on training even as the set of devices available varies significantly with time.
- Maintains privacy guarantees even in the face of unexpected or arbitrary changes in device availability.
- For efficiency, allows client devices to locally decide whether they will check in to the server in order to participate in training, independent of other devices.
Initial work on privacy amplification via random check-ins highlighted these challenges and introduced a feasible protocol, but it would have required complex changes to our production infrastructure to deploy. Further, as with the amplification-via-sampling analysis of DP-SGD, the privacy amplification possible with random check-ins depends on a large number of devices being available. For example, if only 1000 devices are available for training, and participation of at least 1000 devices is needed in each training step, that requires either 1) including all devices currently available and paying a large privacy cost since there is no randomness in the selection, or 2) pausing the protocol and not making progress until more devices are available.
Achieving Provable Differential Privacy for Federated Learning with DP-FTRL
To address this challenge, the DP-FTRL algorithm is built on two key observations: 1) the convergence of gradient-descent-style algorithms depends primarily not on the accuracy of individual gradients, but the accuracy of cumulative sums of gradients; and 2) we can provide accurate estimates of cumulative sums with a strong DP guarantee by utilizing negatively correlated noise, added by the aggregating server: essentially, adding noise to one gradient and subtracting that same noise from a later gradient. DP-FTRL accomplishes this efficiently using the Tree Aggregation algorithm [1, 2].
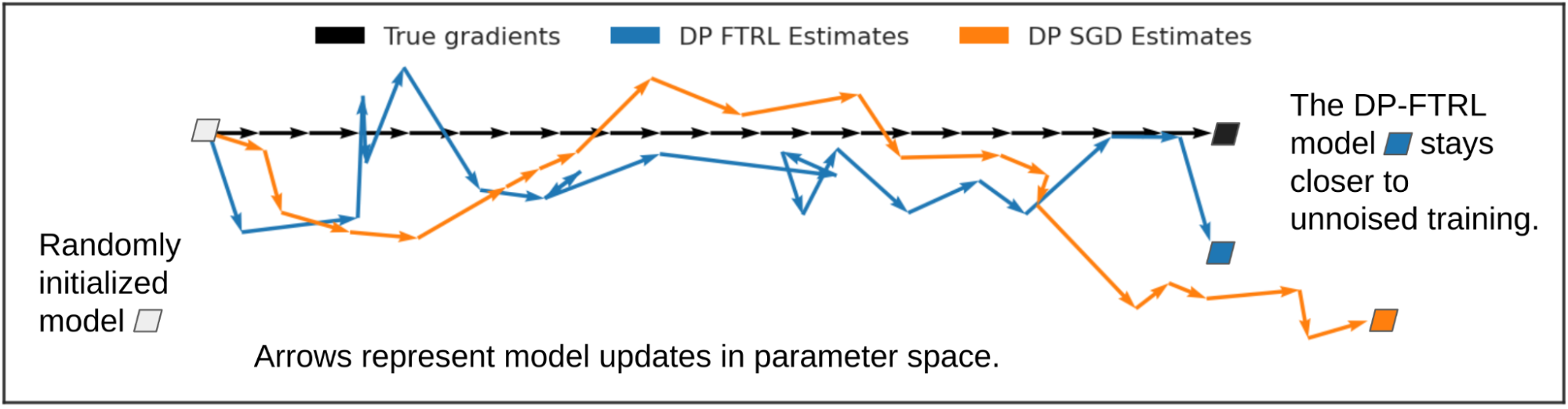
The graphic below illustrates how estimating cumulative sums rather than individual gradients can help. We look at how the noise introduced by DP-FTRL and DP-SGD influence model training, compared to the true gradients (without added noise; in black) which step one unit to the right on each iteration. The individual DP-FTRL gradient estimates (blue), based on cumulative sums, have larger mean-squared-error than the individually-noised DP-SGD estimates (orange), but because the DP-FTRL noise is negatively correlated, some of it cancels out from step to step, and the overall learning trajectory stays closer to the true gradient descent steps.
 |
To provide a strong privacy guarantee, we limit the number of times a user contributes an update. Fortunately, sampling-without-replacement is relatively easy to implement in production FL infrastructure: each device can remember locally which models it has contributed to in the past, and choose to not connect to the server for any later rounds for those models.
Production Training Details and Formal DP Statements
For the production DP-FTRL deployment introduced above, each eligible device maintains a local training cache consisting of user keyboard input, and when participating computes an update to the model which makes it more likely to suggest the next word the user actually typed, based on what has been typed so far. We ran DP-FTRL on this data to train a recurrent neural network with ~1.3M parameters. Training ran for 2000 rounds over six days, with 6500 devices participating per round. To allow for the DP guarantee, devices participated in training at most once every 24 hours. Model quality improved over the previous DP-FedAvg trained model, which offered empirically-tested privacy advantages over non-DP models, but lacked a meaningful formal DP guarantee.
The training mechanism we used is available in open-source in TensorFlow Federated and TensorFlow Privacy, and with the parameters used in our production deployment it provides a meaningfully strong privacy guarantee. Our analysis gives ρ=0.81 zCDP at the user level (treating all the data on each device as a different user), where smaller numbers correspond to better privacy in a mathematically precise way. As a comparison, this is stronger than the ρ=2.63 zCDP guarantee chosen by the 2020 US Census.
Next Steps
While we have reached the milestone of deploying a production FL model using a mechanism that provides a meaningfully small zCDP, our research journey continues. We are still far from being able to say this approach is possible (let alone practical) for most ML models or product applications, and other approaches to private ML exist. For example, membership inference tests and other empirical privacy auditing techniques can provide complimentary safeguards against leakage of users’ data. Most importantly, we see training models with user-level DP with even a very large zCDP as a substantial step forward, because it requires training with a DP mechanism that bounds the sensitivity of the model to any one user’s data. Further, it smooths the road to later training models with improved privacy guarantees as better algorithms or more data become available. We are excited to continue the journey toward maximizing the value that ML can deliver while minimizing potential privacy costs to those who contribute training data.
Acknowledgements
The authors would like to thank Alex Ingerman and Om Thakkar for significant impact on the blog post itself, as well as the teams at Google that helped develop these ideas and bring them to practice:
- Core research team: Galen Andrew, Borja Balle, Peter Kairouz, Daniel Ramage, Shuang Song, Thomas Steinke, Andreas Terzis, Om Thakkar, Zheng Xu
- FL infrastructure team: Katharine Daly, Stefan Dierauf, Hubert Eichner, Igor Pisarev, Timon Van Overveldt, Chunxiang Zheng
- Gboard team: Angana Ghosh, Xu Liu, Yuanbo Zhang
- Speech team: Françoise Beaufays, Mingqing Chen, Rajiv Mathews, Vidush Mukund, Igor Pisarev, Swaroop Ramaswamy, Dan Zivkovic
