
Advances in machine learning (ML) often come with advances in hardware and computing systems. For example, the growth of ML-based approaches in solving various problems in vision and language has led to the development of application-specific hardware accelerators (e.g., Google TPUs and Edge TPUs). While promising, standard procedures for designing accelerators customized towards a target application require manual effort to devise a reasonably accurate simulator of hardware, followed by performing many time-intensive simulations to optimize the desired objective (e.g., optimizing for low power usage or latency when running a particular application). This involves identifying the right balance between total amount of compute and memory resources and communication bandwidth under various design constraints, such as the requirement to meet an upper bound on chip area usage and peak power. However, designing accelerators that meet these design constraints is often result in infeasible designs. To address these challenges, we ask: “Is it possible to train an expressive deep neural network model on large amounts of existing accelerator data and then use the learned model to architect future generations of specialized accelerators, eliminating the need for computationally expensive hardware simulations?”
In “Data-Driven Offline Optimization for Architecting Hardware Accelerators”, accepted at ICLR 2022, we introduce PRIME, an approach focused on architecting accelerators based on data-driven optimization that only utilizes existing logged data (e.g., data leftover from traditional accelerator design efforts), consisting of accelerator designs and their corresponding performance metrics (e.g., latency, power, etc) to architect hardware accelerators without any further hardware simulation. This alleviates the need to run time-consuming simulations and enables reuse of data from past experiments, even when the set of target applications changes (e.g., an ML model for vision, language, or other objective), and even for unseen but related applications to the training set, in a zero-shot fashion. PRIME can be trained on data from prior simulations, a database of actually fabricated accelerators, and also a database of infeasible or failed accelerator designs1. This approach for architecting accelerators — tailored towards both single- and multi-applications — improves performance upon state-of-the-art simulation-driven methods by about 1.2x-1.5x, while considerably reducing the required total simulation time by 93% and 99%, respectively. PRIME also architects effective accelerators for unseen applications in a zero-shot setting, outperforming simulation-based methods by 1.26x.
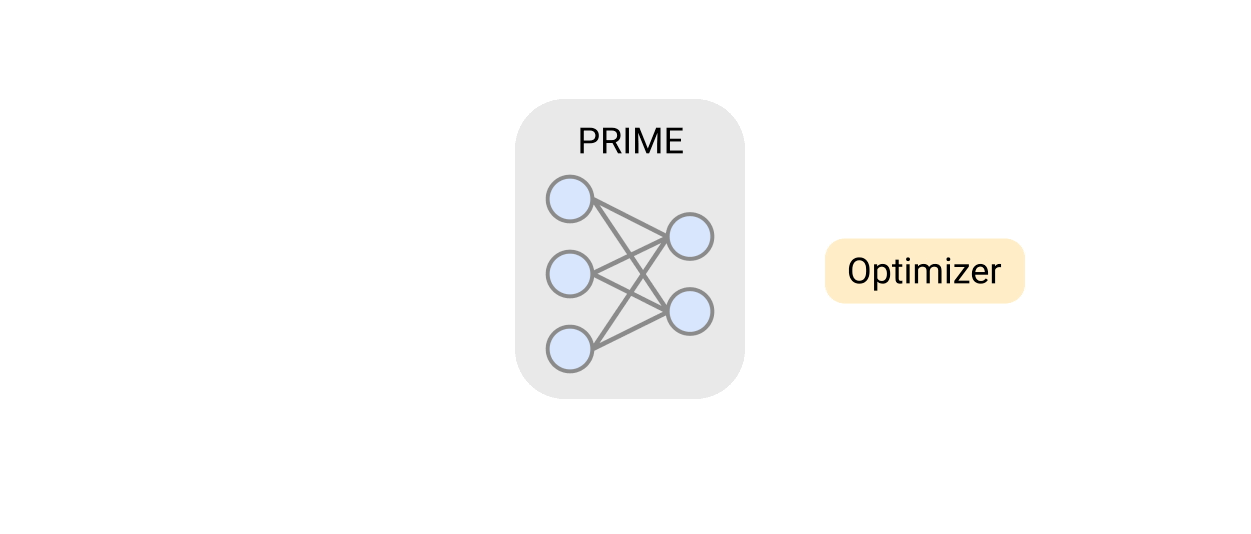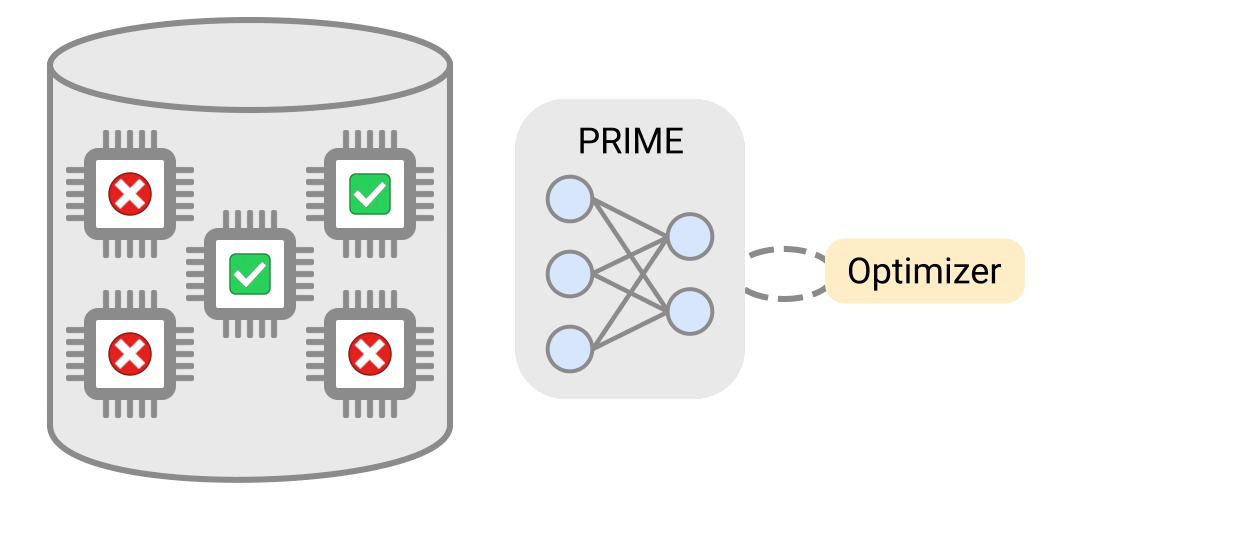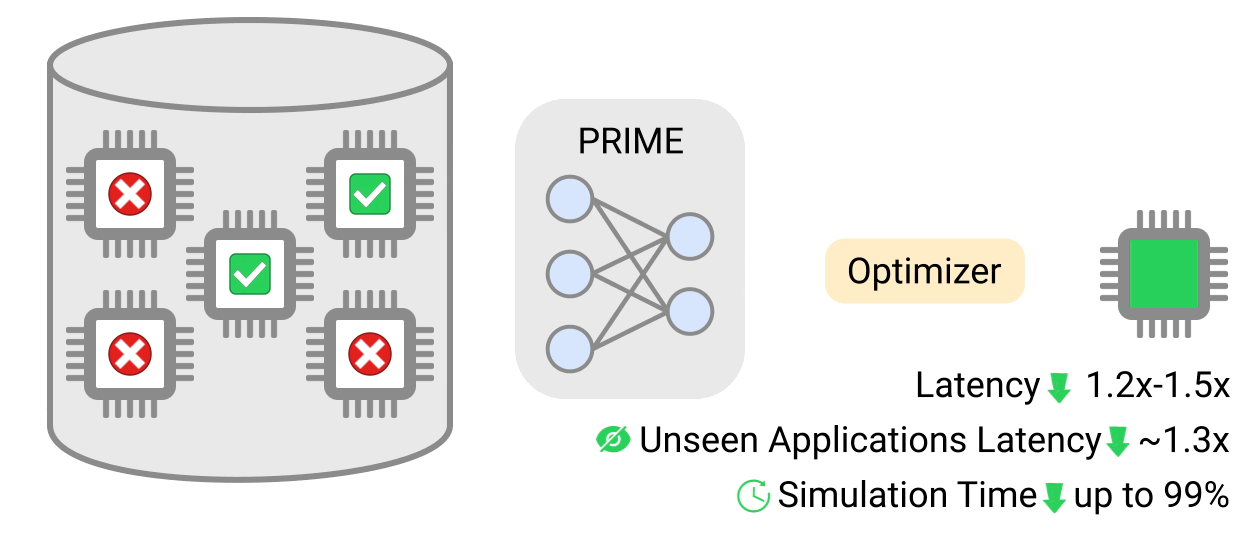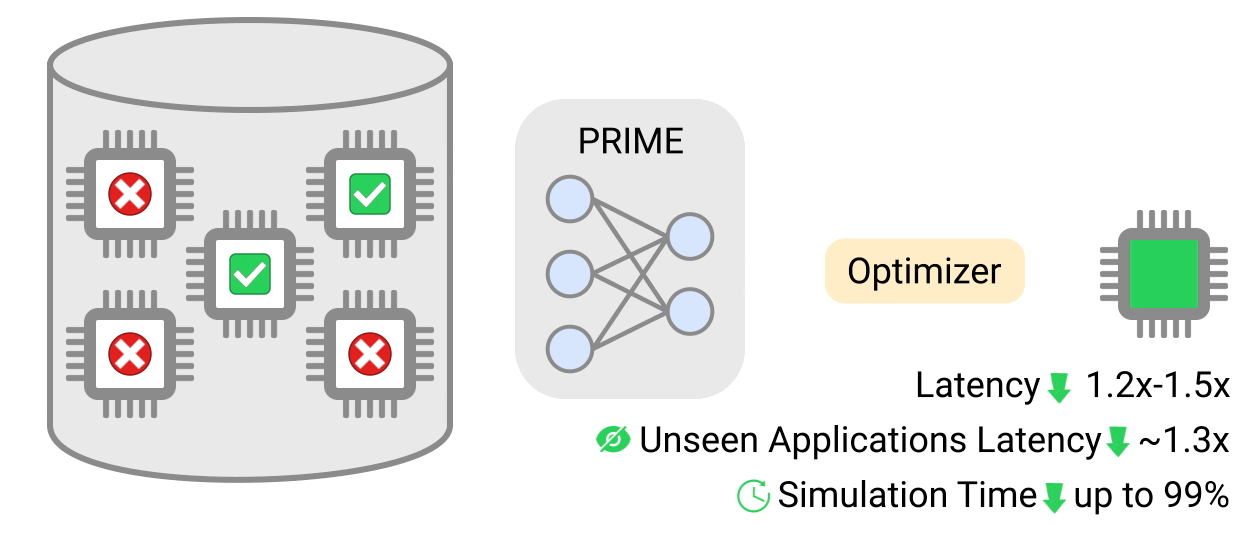 |
| PRIME uses logged accelerator data, consisting of both feasible and infeasible accelerators, to train a conservative model, which is used to design accelerators while meeting design constraints. PRIME architects accelerators with up to 1.5x smaller latency, while reducing the required hardware simulation time by up to 99%. |
The PRIME Approach for Architecting Accelerators
Perhaps the simplest possible way to use a database of previously designed accelerators for hardware design is to use supervised machine learning to train a prediction model that can predict the performance objective for a given accelerator as input. Then, one could potentially design new accelerators by optimizing the performance output of this learned model with respect to the input accelerator design. Such an approach is known as model-based optimization. However, this simple approach has a key limitation: it assumes that the prediction model can accurately predict the cost for every accelerator that we might encounter during optimization! It is well established that most prediction models trained via supervised learning misclassify adversarial examples that “fool” the learned model into predicting incorrect values. Similarly, it has been shown that even optimizing the output of a supervised model finds adversarial examples that look promising under the learned model2, but perform terribly under the ground truth objective.
To address this limitation, PRIME learns a robust prediction model that is not prone to being fooled by adversarial examples (that we will describe shortly), which would be otherwise found during optimization. One can then simply optimize this model using any standard optimizer to architect simulators. More importantly, unlike prior methods, PRIME can also utilize existing databases of infeasible accelerators to learn what not to design. This is done by augmenting the supervised training of the learned model with additional loss terms that specifically penalize the value of the learned model on the infeasible accelerator designs and adversarial examples during training. This approach resembles a form of adversarial training.
In principle, one of the central benefits of a data-driven approach is that it should enable learning highly expressive and generalist models of the optimization objective that generalize over target applications, while also potentially being effective for new unseen applications for which a designer has never attempted to optimize accelerators. To train PRIME so that it generalizes to unseen applications, we modify the learned model to be conditioned on a context vector that identifies a given neural net application we wish to accelerate (as we discuss in our experiments below, we choose to use high-level features of the target application: such as number of feed-forward layers, number of convolutional layers, total parameters, etc. to serve as the context), and train a single, large model on accelerator data for all applications designers have seen so far. As we will discuss below in our results, this contextual modification of PRIME enables it to optimize accelerators both for multiple, simultaneous applications and new unseen applications in a zero-shot fashion.
Does PRIME Outperform Custom-Engineered Accelerators?
We evaluate PRIME on a variety of actual accelerator design tasks. We start by comparing the optimized accelerator design architected by PRIME targeted towards nine applications to the manually optimized EdgeTPU design. EdgeTPU accelerators are primarily optimized towards running applications in image classification, particularly MobileNetV2, MobileNetV3 and MobileNetEdge. Our goal is to check if PRIME can design an accelerator that attains a lower latency than a baseline EdgeTPU accelerator3, while also constraining the chip area to be under 27 mm2 (the default for the EdgeTPU accelerator). Shown below, we find that PRIME improves latency over EdgeTPU by 2.69x (up to 11.84x in t-RNN Enc), while also reducing the chip area usage by 1.50x (up to 2.28x in MobileNetV3), even though it was never trained to reduce chip area! Even on the MobileNet image-classification models, for which the custom-engineered EdgeTPU accelerator was optimized, PRIME improves latency by 1.85x.
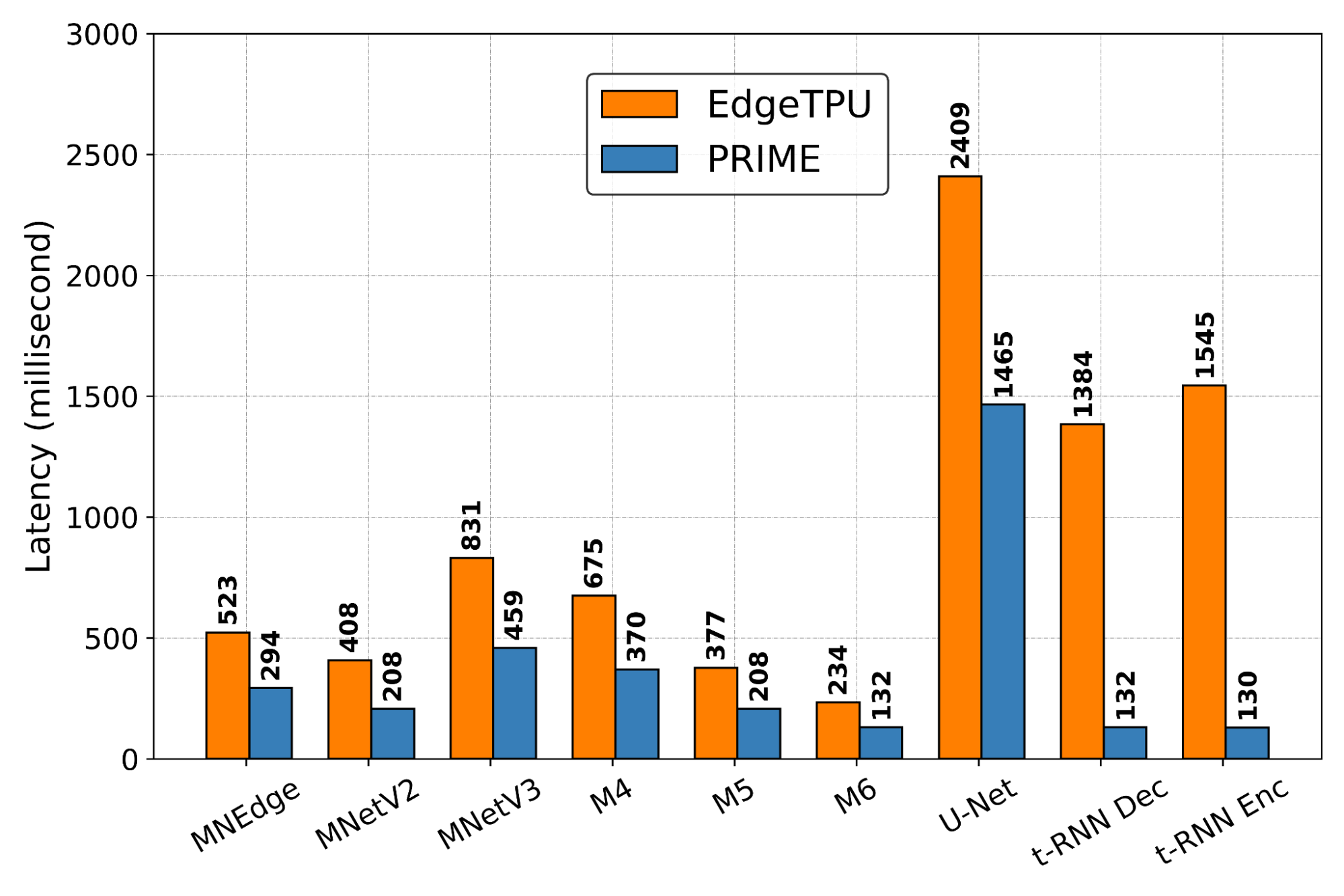 |
| Comparing latencies (lower is better) of accelerator designs suggested by PRIME and EdgeTPU for single-model specialization. |
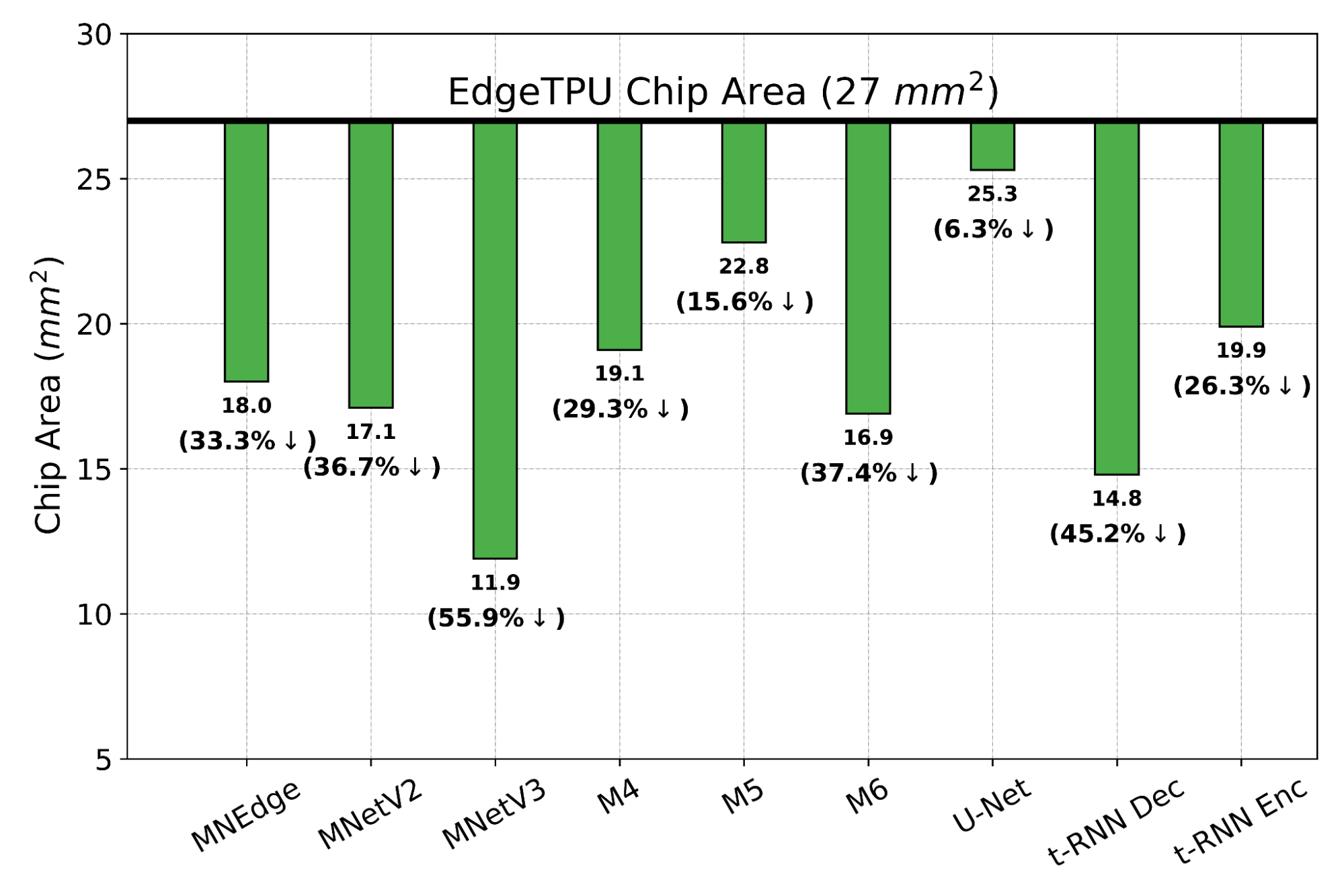 |
| The chip area (lower is better) reduction compared to a baseline EdgeTPU design for single-model specialization. |
Designing Accelerators for New and Multiple Applications, Zero-Shot
We now study how PRIME can use logged accelerator data to design accelerators for (1) multiple applications, where we optimize PRIME to design a single accelerator that works well across multiple applications simultaneously, and in a (2) zero-shot setting, where PRIME must generate an accelerator for new unseen application(s) without training on any data from such applications. In both settings, we train the contextual version of PRIME, conditioned on context vectors identifying the target applications and then optimize the learned model to obtain the final accelerator. We find that PRIME outperforms the best simulator-driven approach in both settings, even when very limited data is provided for training for a given application but many applications are available. Specifically in the zero-shot setting, PRIME outperforms the best simulator-driven method we compared to, attaining a reduction of 1.26x in latency. Further, the difference in performance increases as the number of training applications increases.
 |
| The average latency (lower is better) of test applications under zero-shot setting compared to a state-of-the-art simulator-driven approach. The text on top of each bar shows the set of training applications. |
Closely Analyzing an Accelerator Designed by PRIME
To provide more insight to hardware architecture, we examine the best accelerator designed by PRIME and compare it to the best accelerator found by the simulator-driven approach. We consider the setting where we need to jointly optimize the accelerator for all nine applications, MobileNetEdge, MobileNetV2, MobileNetV3, M4, M5, M64, t-RNN Dec, and t-RNN Enc, and U-Net, under a chip area constraint of 100 mm2. We find that PRIME improves latency by 1.35x over the simulator-driven approach.
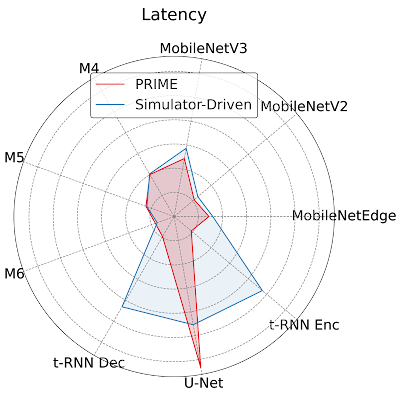 |
| Per application latency (lower is better) for the best accelerator design suggested by PRIME and state-of-the-art simulator-driven approach for a multi-task accelerator design. PRIME reduces the average latency across all nine applications by 1.35x over the simulator-driven method. |
As shown above, while the latency of the accelerator designed by PRIME for MobileNetEdge, MobileNetV2, MobileNetV3, M4, t-RNN Dec, and t-RNN Enc are better, the accelerator found by the simulation-driven approach yields a lower latency in M5, M6, and U-Net. By closely inspecting the accelerator configurations, we find that PRIME trades compute (64 cores for PRIME vs. 128 cores for the simulator-driven approach) for larger Processing Element (PE) memory size (2,097,152 bytes vs. 1,048,576 bytes). These results show that PRIME favors PE memory size to accommodate the larger memory requirements in t-RNN Dec and t-RNN Enc, where large reductions in latency were possible. Under a fixed area budget, favoring larger on-chip memory comes at the expense of lower compute power in the accelerator. This reduction in the accelerator’s compute power leads to higher latency for the models with large numbers of compute operations, namely M5, M6, and U-Net.
Conclusion
The efficacy of PRIME highlights the potential for utilizing the logged offline data in an accelerator design pipeline. A likely avenue for future work is to scale this approach across an array of applications, where we expect to see larger gains because simulator-driven approaches would need to solve a complex optimization problem, akin to searching for needle in a haystack, whereas PRIME can benefit from generalization of the surrogate model. On the other hand, we would also note that PRIME outperforms prior simulator-driven methods we utilize and this makes it a promising candidate to be used within a simulator-driven method. More generally, training a strong offline optimization algorithm on offline datasets of low-performing designs can be a highly effective ingredient in at the very least, kickstarting hardware design, versus throwing out prior data. Finally, given the generality of PRIME, we hope to use it for hardware-software co-design, which exhibits a large search space but plenty of opportunity for generalization. We have also released both the code for training PRIME and the dataset of accelerators.
Acknowledgments
We thank our co-authors Sergey Levine, Kevin Swersky, and Milad Hashemi for their advice, thoughts and suggestions. We thank James Laudon, Cliff Young, Ravi Narayanaswami, Berkin Akin, Sheng-Chun Kao, Samira Khan, Suvinay Subramanian, Stella Aslibekyan, Christof Angermueller, and Olga Wichrowskafor for their help and support, and Sergey Levine for feedback on this blog post. In addition, we would like to extend our gratitude to the members of “Learn to Design Accelerators”, “EdgeTPU”, and the Vizier team for providing invaluable feedback and suggestions. We would also like to thank Tom Small for the animated figure used in this post.
1The infeasible accelerator designs stem from build errors in silicon or compilation/mapping failures. ↩
2This is akin to adversarial examples in supervised learning – these examples are close to the data points observed in the training dataset, but are misclassified by the classifier. ↩
3The performance metrics for the baseline EdgeTPU accelerator are extracted from an industry-based hardware simulator tuned to match the performance of the actual hardware. ↩
4These are proprietary object-detection models, and we refer to them as M4 (indicating Model 4), M5, and M6 in the paper. ↩
