
 The NVIDIA platform, powered by the A100 Tensor Core GPU, delivers leading performance and versatility for accelerated HPC.
The NVIDIA platform, powered by the A100 Tensor Core GPU, delivers leading performance and versatility for accelerated HPC.
High-performance computing (HPC) has become the essential instrument of scientific discovery.
Whether it is discovering new, life-saving drugs, battling climate change, or creating accurate simulations of our world, these solutions demand an enormous—and rapidly growing—amount of processing power. They are increasingly out of reach of traditional computing approaches.
That is why industry has embraced NVIDIA GPU-accelerated computing. Combined with AI, it is bringing millionfold leaps in performance for scientific advancement. Today, 2,700 applications can benefit from NVIDIA GPU acceleration, and that number continues to rise, backed by a growing community of three million developers.
HPC application performance improvements
Delivering the many-fold speedups across the entire breadth of HPC applications takes relentless innovation at every level of the stack. This starts with chips and systems and goes through to the application frameworks themselves.
The NVIDIA platform continues to deliver significant performance improvements each year, with relentless advancements in architecture and across the NVIDIA software stack. Compared to the P100 released just six years ago, the H100 Tensor Core GPU is expected to deliver an estimated 26x higher performance, more than 3x faster than Moore’s Law.

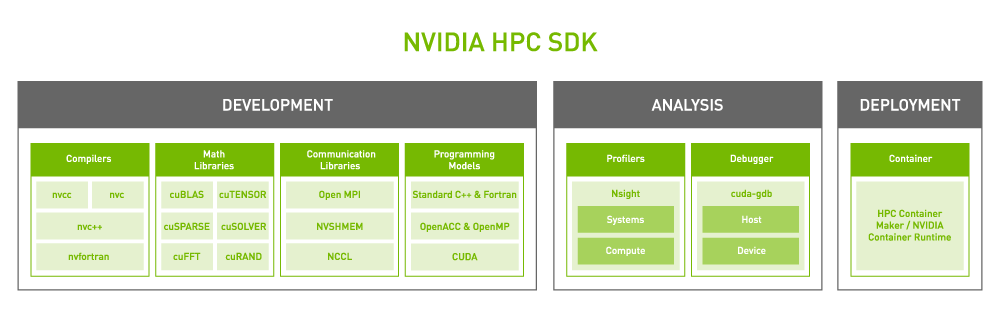
Core to the NVIDIA platform is a feature-rich and high-performance software stack. To facilitate GPU acceleration for the widest range of HPC applications, the platform includes the NVIDIA HPC SDK. The SDK provides unmatched developer flexibility, enabling the creation and porting of GPU-accelerated applications using standard languages, directives, and CUDA.
The power of the NVIDIA HPC SDK lies in a vast suite of highly optimized GPU-accelerated math libraries, enabling you to harness the full performance potential of NVIDIA GPUs. For the best multi-GPU and multi-node performance, the NVIDIA HPC SDK also provides powerful communications libraries:
- NVSHMEM creates a global address space for data that spans the memory of multiple GPUs.
- NVIDIA Collective Communications Library (NCCL) optimizes inter-GPU communication.
Altogether, this platform provides the highest performance and flexibility to support the large and growing universe of GPU-accelerated HPC applications.
HPC performance and energy efficiency
To showcase how the NVIDIA full-stack innovation translates into the highest performance for accelerated HPC, we compared the performance of a server from HPE with four NVIDIA GPUs with that of a similarly configured server based on an equal number of accelerator modules from another vendor.
We tested a set of five widely used HPC applications using a wide variety of datasets. While the NVIDIA platform accelerates 2,700 applications spanning every industry, the applications we could use in this comparison were limited by the selection of software and application versions that are available for the other vendor’s accelerators.
For all workloads except for NAMD, which is software for molecular dynamics simulation, our results are calculated using the geomean of results across multiple datasets to minimize the influence of outliers and to be representative of customer experiences.
We also tested these applications in multi-GPU and single-GPU scenarios.
In the multi-GPU scenario, with all accelerators in the tested systems being used to run a single simulation, the A100 Tensor Core GPU-based server delivered up to 2.1x higher performance than the alternative offering.
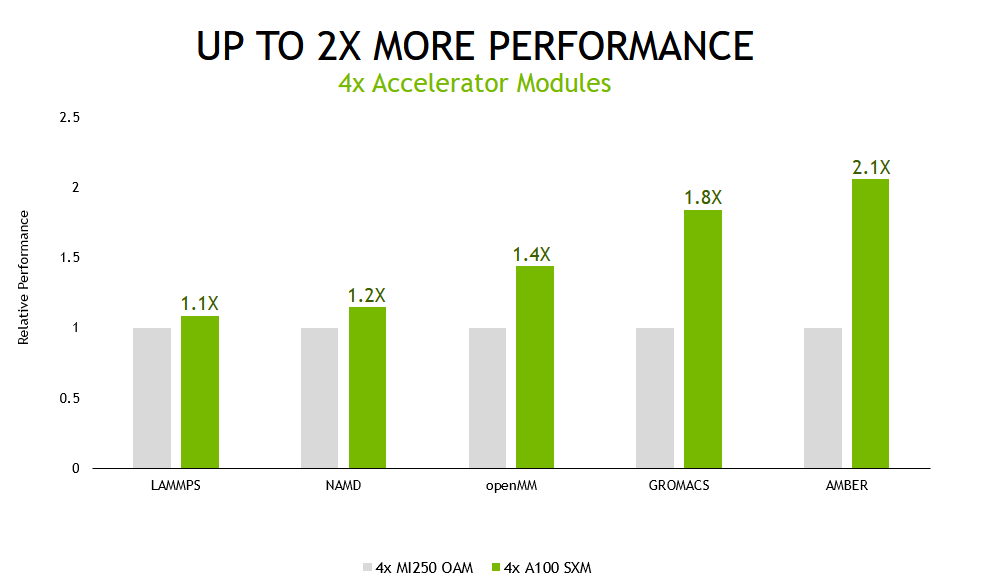
Fueled by continued advances in compute performance, the field of molecular dynamics is moving towards simulating ever-larger systems of atoms for longer periods of simulated time. These advances enable researchers to simulate an increasing set of biochemical mechanisms, such as photosynthetic electron transport and vision signal transduction. These and other processes have long been the subject of scientific debate because they have been beyond the reach of simulation, which is the primary tool for validation. This was due to the prohibitively long amount of time needed to complete the simulations.
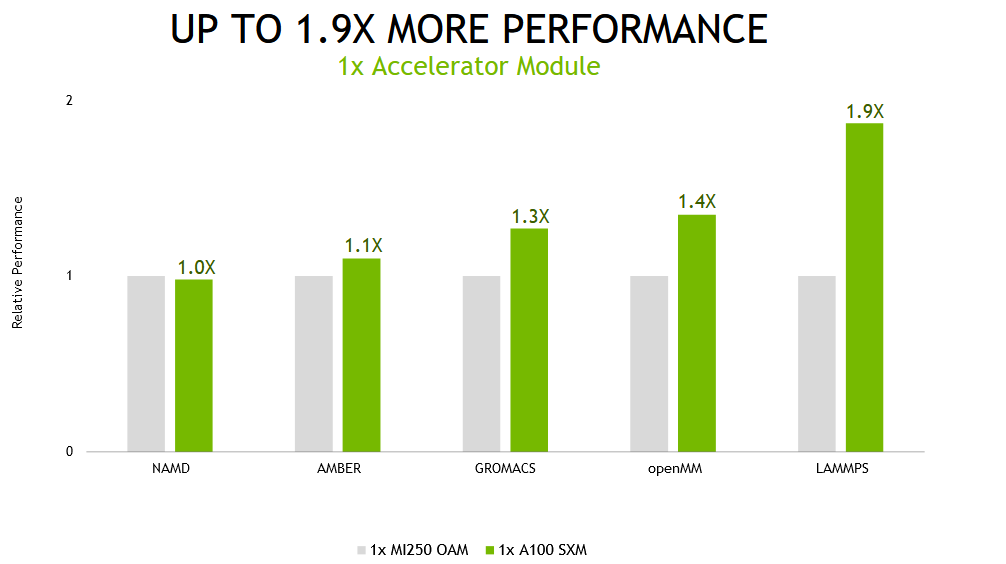
However, we recognize that not all users of these applications run them with multiple GPUs per simulation. For optimal throughput, the best execution method is often to assign one GPU per simulation.
When running these same applications on a single accelerator module—a full GPU on the NVIDIA A100 and both compute dies on the alternative product—the NVIDIA A100-based system delivered up to 1.9x faster performance.
Energy costs represent a significant portion of the total cost of ownership (TCO) of data centers and supercomputing centers alike, underscoring the importance of power-efficient computing platforms. Our testing showed that the NVIDIA platform provided up to 2.8x higher throughput-per-watt than the alternative offering.

Efficiency ratio of A100 to MI250 shown – higher is better for NVIDIA. Geomean over multiple datasets (varies) per application. Efficiency is Performance / Power consumption (Watts) as measured for the GPUs using measured using NVIDIA SMI and equivalent functionality in ROCm |
AMD MI250 measured on a GIGABYTE M262-HD5-00 with (2) AMD EPYC 7763 with 4x AMD Instinct MI250 OAM (128 GB HBM2e) 500W GPUs with AMD Infinity Fabric technology. NVIDIA runs on ProLiant XL645d Gen10 Plus using dual EPYC 7713 CPUs and 4x A100 (80 GB) SXM4
MI250 OAM (128 GB HBM2e) 500W GPUs with AMD Infinity Fabric technology. NVIDIA runs on ProLiant XL645d Gen10 Plus using dual EPYC 7713 CPUs and 4x A100 (80 GB) SXM4
LAMMPS develop_db00b49(AMD) develop_2a35ec2(NVIDIA) datasets ReaxFF/c, Tersoff, Leonard-Jones, SNAP | NAMD 3.0alpha9 dataset STMV_NVE | OpenMM 7.7.0 Ensemble runs for datasets: amber20-stmv, amber20-cellulose, apoa1pme, pme|
GROMACS 2021.1(AMD) 2022(NVIDIA) datasets ADH-Dodec (h-bond), STMV (h-bond) | AMBER 20.xx_rocm_mr_202108(AMD) and 20.12-AT_21.12 (NVIDIA) datasets Cellulose_NVE, STMV_NVE | 1x MI250 has 2x GCD
The excellent performance and power efficiency of the NVIDIA A100 GPU is the result of many years of relentless software-hardware co-optimization to maximize application performance and efficiency. For more information about the NVIDIA Ampere architecture, see the NVIDIA A100 Tensor Core GPU whitepaper.
A100 also presents as a single processor to the operating system, requiring that only one MPI rank be launched to take full advantage of its performance. And, A100 delivers excellent performance at scale thanks to the 600-GB/s NVLink connections between all GPUs in a node.
AI and HPC convergence
Just as accelerated computing is bringing many-fold speedups to modeling and simulation applications, the combination of AI and HPC will deliver the next step-function increase in performance to unlock the next wave of scientific discovery.
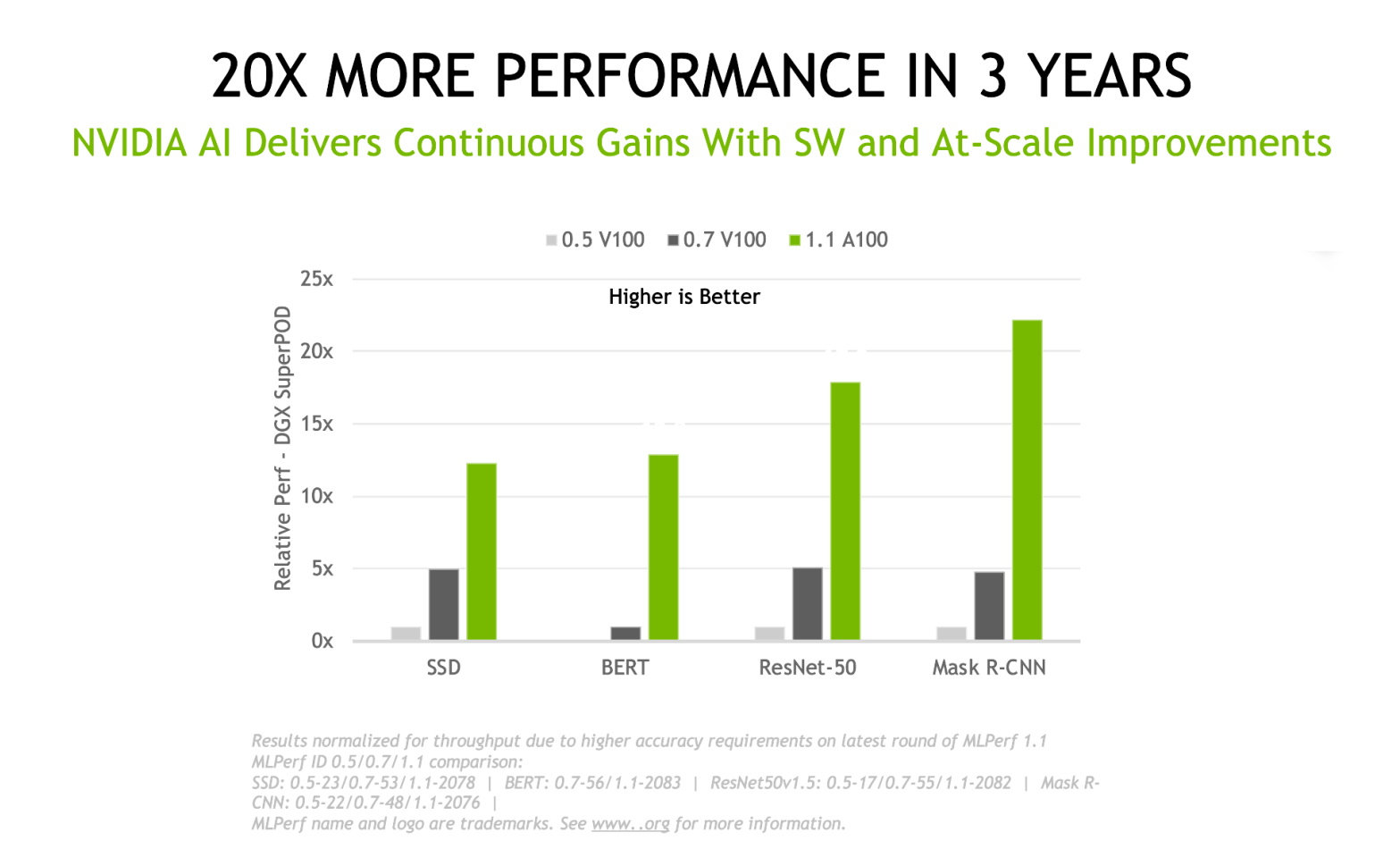
In the three years between our first MLPerf training submissions and the most recent results, the NVIDIA platform has delivered 20x more deep learning training performance on this industry-standard, peer-reviewed suite of benchmarks. The gains come from a combination of chip, software, and at-scale improvements.
Scientists and researchers are already using the power of AI to deliver dramatic improvements in performance, turbocharging scientific discovery:
- Enabling a 105 reduction in the time required for identifying gravitational waves.
- Providing a 1,000x speed-up for simulating the Delta SARS-CoV-2 virus in a respiratory droplet with more than a billion atoms.
- Accelerating the development of clean fusion energy.
- Creating predictive digital twins for heat recovery steam generator (HRSG) plants.
Supercomputing centers around the world are continuing to adopt accelerated AI supercomputers.
- The Polaris supercomputer at the Argonne Leadership Computing Facility (ALCF), Perlmutter at NERSC, and Leonardo at CINECA are all powered by A100 Tensor Core GPUs.
- The upcoming Alps supercomputer based on our upcoming Grace Hopper Superchip will come online in 2023.
- The upcoming Venado system at Los Alamos National Laboratory, scheduled for delivery in 2023, will include both the Grace Hopper Superchip as well as Grace CPU Superchip nodes.
For more information about the latest performance data, see HPC Application Performance.