How do you train a tensorflow model on a set of “background” or “normal” images in order to detect objects that are not “normal”?
I’m using tensorflow to detect birds at a bird feeder via images from a wyze security camera. I have had it working okay on and off over the last several weeks (3:1 false positives to actual positives is about as good as it’s gotten…), but lately it’s been really struggling, especially with wind moving the birdfeeders around (today I had almost 30,000 images, meaning it only dropped about half of all possible images run through the model…). This got me thinking that, from my point of view, it would be easiest to have a model that I continually teach what NOT to call an object and just retrain whenever I find the false positives to be a problem. THEN I can start training it to differentiate between the things that are “not-background”… I’m sure this isn’t a novel idea, so how is this done? I’ve found plenty of tutorials and articles about the opposite (training for recognition of specific objects) but can’t find anything helpful in taking this approach, at least nothing related to how to actually do this…
Where I’m coming from: I’ve some very basic ML exposure with Andrew Ng’s Machine Learning course. I think I’d like to prepare for Google’s TF certificate exam and take the exam by the end of this summer (end of August).
What I’m thinking of doing: I was thinking of implementing all assignments from Ng’s ML course in Python first, then do his Deep Learning specialization and then do Laurence Moroney’s course specifically designed for the exam. (This would probably take ~2 months if I give in 4-5 hrs per day, so I would still have ~1 month to do whatever you guys recommend.)
My questions:
Is Ng’s ML course + deep learning specialization enough to start Moroney’s course?
Should I do anything else before taking the exam? (Kaggle competitions, projects, etc.?)
Migrating from Onyx to NVIDIA Cumulus Linux optimizes operational efficiency, enabling a DevOps approach to data center operations.
Data center organizations are looking for more efficient, modern network architectures that can be managed, monitored, and deployed in a scalable manner. Emerging DevOps and NetDevOps operational models are bringing the agile development models of continuous integration and continuous development (CI/CD) to data center infrastructure.
Why Cumulus Linux?
The Cumulus Linux operating system was built from the ground up to optimize operational efficiency, enabling a DevOps approach to data center operations.
This DevOps-centric approach means that the complete data center network can be simulated in a digital twin hosted on the NVIDIA Air platform. Using a digital twin for validation and automation improves security, reliability, and productivity.
Migrate from Onyx to Cumulus Linux
NVIDIA recommends migrating to the latest version of Cumulus Linux (that is 5.x as of April 2022).
Before starting the Onyx to Cumulus Linux migration, make sure that you have a valid support contract with NVIDIA.
First, back up the Onyx configuration file. Run the following command on every Onyx switch and copy its output to a local file:
Create a Cumulus Linux configuration with NVUE (NVIDIA User Experience) per switch. Before creating a Cumulus configuration, confirm that you have received a valid license to the Cumulus Linux switches.
(Optional) Validate the configuration using a data center digital twin
To ensure configuration integrity, build a data center simulation on NVIDIA Air.
Log in with a business email address.
Choose BUILD A SIMULATION, Build Your Own, and Create your own.
Add Cumulus switches per the number of production switches and connect them accordingly.
Add servers as needed to enable end-to-end testing.
Choose START SIMULATION.
Log in to each switch by clicking it and applying the NVUE configuration created.
Configure the servers with the corresponding interfaces on the production network.
Conduct end-to-end testing.
When testing is complete, apply the configuration to production and repeat testing.
Summary
To maximize the Cumulus Linux operational efficiency features, organizations use NVIDIA Air and integrate it into their CI/CD workflow. Having a data center digital twin helps to eliminate production risks, perform end-to-end testing in a risk-free environment and deploy with confidence.
Using NVIDIA Air should be sufficient in helping you with testing and validating the migration. However, we strongly recommend that you work with an NVIDIA solution architect to validate the migration code integrity and ensure a non-eventful migration.
For more information, see the following resources:
Data privacy and availability remain an issue for enterprises. Delve into how synthetic tabular data generated by NeMo addresses these challenges.
Big data, new algorithms, and fast computation are three main factors that make the modern AI revolution possible. However, data poses many challenges for enterprises: difficulty in data labeling, ineffective data governance, limited data availability, data privacy, and so on.
Synthetically generated data is a potential solution to address these challenges because it generates data points by sampling from the model. Continuous sampling can generate an infinite number of data points including labels. This allows for data to be shared across teams or externally.
Generating synthetic data also provides a degree of data privacy without compromising quality or realism. Successful synthetic data generation involves capturing the distribution while maintaining privacy and conditionally generating new data, which can then be used to make more robust models or used for time-series forecasting.
In this post, we explain how synthetic data can be artificially produced with transformer models, using NVIDIA NeMo as an example. We explain how synthetically generated data can be used as a valid substitute for real-life data in machine learning algorithms to protect user privacy while making accurate predictions.
Transformers: the better synthetic data generator
Deep learning generative models are a natural fit to model complicated real-world data. Two popular generative models have achieved some success in the past: Variational Auto-Encoder (VAE) and Generative Adversarial Network (GAN).
However, there are known issues with VAE and GAN models for synthetic data generation:
The mode collapse problem in the GAN model causes the generated data to miss some modes in the training data distribution.
The VAE model has difficulty generating sharp data points due to non-autoregressive loss.
Transformer models have recently achieved great success in the natural language processing (NLP) domain. The self-attention encoding and decoding architecture of the transformer model has proven to be accurate in modeling data distribution and is scalable to larger datasets. For example, the NVIDIA Megatron-Turing NLG model obtains excellent results with 530B parameters.
GPT
OpenAI’s GPT3 uses the decoder part of the transformer model and has 175B parameters. GPT3 has been widely used across multiple industries and domains, from productivity and education to creativity and games.
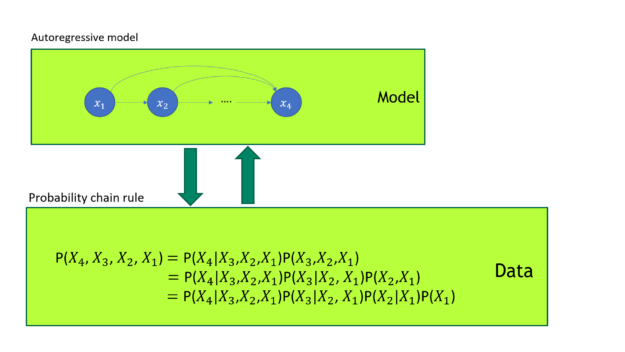
The GPT model turns out to be a superior generative model. As you may know, any joint probability distribution can be factored into the product of a series of conditional probability distributions according to the probability chain rule. The GPT autoregressive loss directly models the data joint probability distribution shown in Figure 1.
Figure 1. GPT model training
In Figure 1, the GPT model training uses autoregressive loss. It has a one-to-one mapping to the probability chain rule. GPT directly models the data joint probability distribution.
Because tabular data is composed of different types of data as rows or columns, GPT can understand the joint data distribution across multiple table rows and columns, and generate synthetic data as if it were NLP-textual data. Our experiments show that indeed the GPT model generates higher-quality tabular synthetic data.
A higher-quality tabular data tokenizer
Despite its superiority, there are a number of challenges with using GPT to model tabular data: the data inputs to the GPT model are sequences of token IDs. For NLP datasets, you could use a byte-pair encoding (BPE) tokenizer to convert the text data into sequences of token IDs.
It is natural to use the generic GPT BPE tokenizer for tabular datasets; however, there are a few problems with this approach.
First, when the GPT BPE tokenizer splits the tabular data into tokens, the number of tokens is usually not fixed for the same column at different rows, because the number is determined by the occurrence frequencies of the individual subtokens. This means that the columnar information in the table is lost if you use an ordinary NLP tokenizer.
Another problem with the NLP tokenizer is that a long string in a column would consist of a large number of tokens. This is wasteful considering that GPT has a limited capacity for modeling the sequences of tokens. For example, the merchant name Mitsui Engineering & Shipbuilding Co needs 7 tokens to encode it ([44, 896, 9019, 14044, 1222, 16656, 16894, 1766]) with a BPE tokenizer.
As discussed in the TabFormer paper, a viable solution is to build a specialized tokenizer for the tabular data that considers the table’s structural information. The TabFormer tokenizer uses a single token for each of the columns, which can cause either accuracy loss if the number of tokens is small for the column, or weak generalization if the number of tokens is too large.
We improve it by using multiple tokens to code the columns.
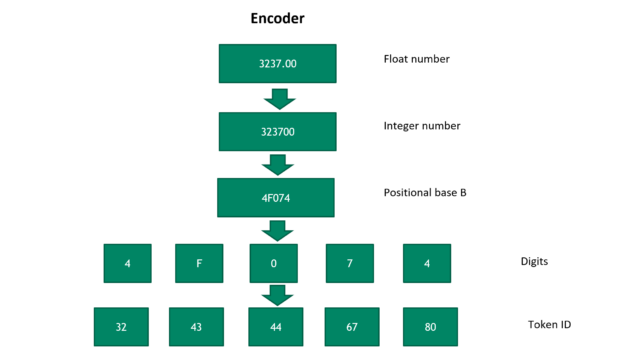
Figure 2. Convert float numbers into a sequence of token IDs
Figure 2 shows the steps of converting a float number into a sequence of token IDs. First, we reversibly convert the float number into a positive integer. Then, it is transformed into a number with positional base B, where B is a hyperparameter. The larger the base B number is, the fewer tokens it needs to represent the number.
However, a larger base B sacrifices the generality for new numbers. In the last step, the digit numbers are mapped to unique token IDs. To convert the token IDs to a float number, run through these steps in reverse order. The float number decoding accuracy is then determined by the number of tokens and the choice of positional base B.
Scaling model training with NeMo framework
NeMo is a framework for training conversational AI models. In the released code inside the NeMo repository, our tabular data tokenizer supports both integer and categorical data, handles NaN values, and supports different scalar transformations to minimize the gaps between the numbers. For more information, see our source code implementation.
You can use the special tabular data tokenizer to train a tabular synthetic data generation GPT model of any size. Large models can be difficult to train due to memory constraints. NeMo Megatron is a toolkit for training large language models within NeMo and provides both tensor model parallel and pipeline model parallelism.
This enables the training of transformer models with billions of parameters. On top of the model parallelism, you can apply data parallelism during training to fully use all GPUs in the cluster. According to OpenAI’s scaling law of natural language and theory of over-parameterization of deep learning models, it is recommended to train a large model to get reasonable validation loss given the training data size.
Applying GPT models to real-world applications
In our recent GTC talk, we showed that a trained large GPT model produces high-quality synthetic data. If we continue sampling the trained tabular GPT model, it can produce an infinite number of data points, which all follow the joint distribution as the original data. The generated synthetic data provides the same analytical insights as the original data without revealing the individual’s private information. This makes safe data sharing possible.
Moreover, if you condition the generative model on past data to generate future synthetic data, the model is actually predicting the future. This is attractive to customers in the financial services industry who are dealing with financial time series data. In collaboration with Cohen & Steers, we implemented a tabular GPT model to forecast economic and market indicators including inflation, volatility, and equity markets with quality results.
Bloomberg presented at GTC 2022 how they applied our proposed synthetic data method to analyze the patterns of credit card transaction data while protecting user data privacy.
Apply your knowledge
In this post, we introduced the idea of using NeMo for synthetic tabular data generation and showed how it can be used to solve real-world problems. For more information, see The Data-centric AI Movement.
If you are interested in applying this technique to your own synthetic data generation, use this NeMo Megatron Synthetic Tabular Data Generation notebook tutorial. For hands-on training on applying this method to generate synthetic data, reach out to us directly.
For more information, see the following GTC sessions:
Working as an aerospace engineer in Malaysia, Chee How Lim dreamed of building a startup that could really take off. Today his company, Tapway, is riding a wave of computer vision and AI adoption in Southeast Asia. A call for help in 2019 with video analytics led to the Kuala Lumpur-based company’s biggest project to Read article >
I want to load the weights from a checkpoint file from one of my old projects, but I don’t remember the architecture of the model that was used. Is it possible somehow to get the architecture from the checkpoint file?
Lets assume f is our NN. Individual data points are (x, y) and batch data is (X, Y)
y = f(x), then I’ll take gradient of y with respect to every parameter of NN, this I’ll represent as g.
Y = f(X), this is vectorization. Now if I take gradient of Y with respect to params of NN, then I’ll get G.
What is the relation between G and g? Whether G is average of all g in that batch or something else.
For the context, I am facing this difficulty while implement the policy gradient (reinforcement learning) algorithm. In the policy gradient we have to average over some of the gradients of the policy function. The confusion is that should I do that for individual states or should I use batch of states, because for both the cases, the gradients are of same dimensions.
Suppose I have a simple 4 layered NN. I want to train this to recognize pattern in this data. I have two ways to train this:
I pass one data sample, calculate the loss, calculate the gradients for that loss with respect to the parameters (weights and biases) of neural network, adjust the parameters of NN and repeat this until loss is minimized.
I pass batches of data, and do the rest as mentioned above. This is called vectorization.
So my question is does the gradients are averaged out between all the samples in a batch?

 Migrating from Onyx to NVIDIA Cumulus Linux optimizes operational efficiency, enabling a DevOps approach to data center operations.
Migrating from Onyx to NVIDIA Cumulus Linux optimizes operational efficiency, enabling a DevOps approach to data center operations. Data privacy and availability remain an issue for enterprises. Delve into how synthetic tabular data generated by NeMo addresses these challenges.
Data privacy and availability remain an issue for enterprises. Delve into how synthetic tabular data generated by NeMo addresses these challenges.