
 Learn to build and deploy a deep learning model for automated flood detection using satellite imagery in this new self-paced course from the NVIDIA Deep Learning Institute.
Learn to build and deploy a deep learning model for automated flood detection using satellite imagery in this new self-paced course from the NVIDIA Deep Learning Institute.
Month: May 2022
The promise of deep reinforcement learning (RL) in solving complex, high-dimensional problems autonomously has attracted much interest in areas such as robotics, game playing, and self-driving cars. However, effectively training an RL policy requires exploring a large set of robot states and actions, including many that are not safe for the robot. This is a considerable risk, for example, when training a legged robot. Because such robots are inherently unstable, there is a high likelihood of the robot falling during learning, which could cause damage.
The risk of damage can be mitigated to some extent by learning the control policy in computer simulation and then deploying it in the real world. However, this approach usually requires addressing the difficult sim-to-real gap, i.e., the policy trained in simulation can not be readily deployed in the real world for various reasons, such as sensor noise in deployment or the simulator not being realistic enough during training. Another approach to solve this issue is to directly learn or fine-tune a control policy in the real world. But again, the main challenge is to assure safety during learning.
In “Safe Reinforcement Learning for Legged Locomotion”, we introduce a safe RL framework for learning legged locomotion while satisfying safety constraints during training. Our goal is to learn locomotion skills autonomously in the real world without the robot falling during the entire learning process. Our learning framework adopts a two-policy safe RL framework: a “safe recovery policy” that recovers robots from near-unsafe states, and a “learner policy” that is optimized to perform the desired control task. The safe learning framework switches between the safe recovery policy and the learner policy to enable robots to safely acquire novel and agile motor skills.
The Proposed Framework
Our goal is to ensure that during the entire learning process, the robot never falls, regardless of the learner policy being used. Similar to how a child learns to ride a bike, our approach teaches an agent a policy while using “training wheels”, i.e., a safe recovery policy. We first define a set of states, which we call a “safety trigger set”, where the robot is close to violating safety constraints but can still be saved by a safe recovery policy. For example, the safety trigger set can be defined as a set of states with the height of the robots being below a certain threshold and the roll, pitch, yaw angles being too large, which is an indication of falls. When the learner policy results in the robot being within the safety trigger set (i.e., where it is likely to fall), we switch to the safe recovery policy, which drives the robot back to a safe state. We determine when to switch back to the learner policy by leveraging an approximate dynamics model of the robot to predict the future robot trajectory. For example, based on the position of the robot’s legs and the current angle of the robot based on sensors for roll, pitch, and yaw, is it likely to fall in the future? If the predicted future states are all safe, we hand the control back to the learner policy, otherwise, we keep using the safe recovery policy.
 |
| The state diagram of the proposed approach. (1) If the learner policy violates the safety constraint, we switch to the safe recovery policy. (2) If the learner policy cannot ensure safety in the near future after switching to the safe recovery policy, we keep using the safe recovery policy. This allows the robot to explore more while ensuring safety. |
This approach ensures safety in complex systems without resorting to opaque neural networks that may be sensitive to distribution shifts in application. In addition, the learner policy is able to explore states that are near safety violations, which is useful for learning a robust policy.
Because we use “approximated” dynamics to predict the future trajectory, we also examine how much safer a robot would be if we used a much more accurate model for its dynamics. We provide a theoretical analysis of this problem and show that our approach can achieve minimal safety performance loss compared to one with a full knowledge about the system dynamics.
Legged Locomotion Tasks
To demonstrate the effectiveness of the algorithm, we consider learning three different legged locomotion skills:
- Efficient Gait: The robot learns how to walk with low energy consumption and is rewarded for consuming less energy.
- Catwalk: The robot learns a catwalk gait pattern, in which the left and right two feet are close to each other. This is challenging because by narrowing the support polygon, the robot becomes less stable.
- Two-leg Balance: The robot learns a two-leg balance policy, in which the front-right and rear-left feet are in stance, and the other two are lifted. The robot can easily fall without delicate balance control because the contact polygon degenerates into a line segment.
 |
| Locomotion tasks considered in the paper. Top: efficient gait. Middle: catwalk. Bottom: two-leg balance. |
Implementation Details
We use a hierarchical policy framework that combines RL and a traditional control approach for the learner and safe recovery policies. This framework consists of a high-level RL policy, which produces gait parameters (e.g., stepping frequency) and feet placements, and pairs it with a low-level process controller called model predictive control (MPC) that takes in these parameters and computes the desired torque for each motor in the robot. Because we do not directly command the motors’ angles, this approach provides more stable operation, streamlines the policy training due to a smaller action space, and results in a more robust policy. The input of the RL policy network includes the previous gait parameters, the height of the robot, base orientation, linear, angular velocities, and feedback to indicate whether the robot is approaching the safety trigger set. We use the same setup for each task.
We train a safe recovery policy with a reward for reaching stability as soon as possible. Furthermore, we design the safety trigger set with inspiration from capturability theory. In particular, the initial safety trigger set is defined to ensure that the robot’s feet can not fall outside of the positions from which the robot can safely recover using the safe recovery policy. We then fine-tune this set on the real robot with a random policy to prevent the robot from falling.
Real-World Experiment Results
We report the real-world experimental results showing the reward learning curves and the percentage of safe recovery policy activations on the efficient gait, catwalk, and two-leg balance tasks. To ensure that the robot can learn to be safe, we add a penalty when triggering the safe recovery policy. Here, all the policies are trained from scratch, except for the two-leg balance task, which was pre-trained in simulation because it requires more training steps.
Overall, we see that on these tasks, the reward increases, and the percentage of uses of the safe recovery policy decreases over policy updates. For instance, the percentage of uses of the safe recovery policy decreases from 20% to near 0% in the efficient gait task. For the two-leg balance task, the percentage drops from near 82.5% to 67.5%, suggesting that the two-leg balance is substantially harder than the previous two tasks. Still, the policy does improve the reward. This observation implies that the learner can gradually learn the task while avoiding the need to trigger the safe recovery policy. In addition, this suggests that it is possible to design a safe trigger set and a safe recovery policy that does not impede the exploration of the policy as the performance increases.
 |
| The reward learning curve (blue) and the percentage of safe recovery policy activations (red) using our safe RL algorithm in the real world. |
In addition, the following video shows the learning process for the two-leg balance task, including the interplay between the learner policy and the safe recovery policy, and the reset to the initial position when an episode ends. We can see that the robot tries to catch itself when falling by putting down the lifted legs (front left and rear right) outward, creating a support polygon. After the learning episode ends, the robot walks back to the reset position automatically. This allows us to train policy autonomously and safely without human supervision.
 |
| Early training stage. |
 |
| Late training stage. |
 |
| Without a safe recovery policy. |
Finally, we show the clips of learned policies. First, in the catwalk task, the distance between two sides of the legs is 0.09m, which is 40.9% smaller than the nominal distance. Second, in the two-leg balance task, the robot can maintain balance by jumping up to four times via two legs, compared to one jump from the policy pre-trained from simulation.
 |
| Final learned two-leg balance. |
Conclusion
We presented a safe RL framework and demonstrated how it can be used to train a robotic policy with no falls and without the need for a manual reset during the entire learning process for the efficient gait and catwalk tasks. This approach even enables training of a two-leg balance task with only four falls. The safe recovery policy is triggered only when needed, allowing the robot to more fully explore the environment. Our results suggest that learning legged locomotion skills autonomously and safely is possible in the real world, which could unlock new opportunities including offline dataset collection for robot learning.
No model is without limitation. We currently ignore the model uncertainty from the environment and non-linear dynamics in our theoretical analysis. Including these would further improve the generality of our approach. In addition, some hyper-parameters of the switching criteria are currently being heuristically tuned. It would be more efficient to automatically determine when to switch based on the learning progress. Furthermore, it would be interesting to extend this safe RL framework to other robot applications, such as robot manipulation. Finally, designing an appropriate reward when incorporating the safe recovery policy can impact learning performance. We use a penalty-based approach that obtained reasonable results in these experiments, but we plan to investigate this in future work to make further performance improvements.
Acknowledgements
We would like to thank our paper co-authors: Tingnan Zhang, Linda Luu, Sehoon Ha, Jie Tan, and Wenhao Yu. We would also like to thank the team members of Robotics at Google for discussions and feedback.

 The latest release of the NVIDIA DOCA software framework focuses on enhancements to DOCA infrastructure services.
The latest release of the NVIDIA DOCA software framework focuses on enhancements to DOCA infrastructure services.
The NVIDIA DOCA software framework provides a comprehensive, open development platform to accelerate the creation of DPU applications. DOCA continues to gain momentum and push the boundaries of the data center to offload, accelerate, and isolate network, storage, security, and management infrastructure. The release of the NVIDIA DOCA 1.3 software framework focuses on new features and enhancements of the software.
Key capabilities of DOCA 1.3
- DOCA FLOW Lib with Optimized Flow Insertion
- DOCA Communications Channel Library
- DOCA Regex Library
- DOCA App Shield SDK
- OVN IPsec Encryption Full Offload
- DOCA Services additions and enhancements include:
- DOCA Telemetry
- DOCA Host Based Networking
- DOCA Flow Inspector
DOCA FLOW with Optimized Flow Insertion
DOCA FLOW is an API that serves as an abstraction layer API for network acceleration. DOCA FLOW is the most fundamental API for building generic SDN execution pipelines in hardware.
The main goal of DOCA FLOW is to provide a simple, complete framework for fast packet processing in data plane applications. The API provides a set of libraries for specific environments through the creation of an abstraction layer. DOCA FLOW makes it easy to develop HW-accelerated applications that have a match on up to two layers of tunneled packets.
With the addition of Optimized Flow Insertion (OFI), DOCA FLOW now offers a new way to manage the packet steering table of the DPU, offering several additional benefits. These include an increased flow insertion rate with more than a 10X performance increase for scaling to over 1M rules/sec. An improved security posture that eliminates the ability to hijack the underlying driver, and more flexibility are also key features.
DOCA Communications Channel
This release also introduces the DOCA Communications Channel for secure, flexible, and efficient application offload. DOCA Communications Channel is for isolated communication between the host software and the DOCA services running on the DPU. This gives, for example, Windows VM the ability to securely communicate with the service on the DPU Arm processors, without leveraging the regular network stack and risking exposure to malicious activity. Examples of DOCA services benefiting from this communication method include streaming services, Telemetry, App Shield monitoring, Remote APIs Orchestration, and Flow Inspection.
Regex Library
Regular expression, also known as Regex, is a standard pattern-matching tool used in many scripting languages. With it, you can create filters that can match patterns of text, rather than just single words or phrases. Regex was designed for high throughput, low latency Deep Packet Inspection applications that require packet payload inspection and anomaly detection, which can be achieved using RegEx pattern matching and string matching. The DOCA Regex Library is an important security and telemetry function that is now available in DOCA 1.3.
DOCA App Shield
DOCA App Shield was introduced in DOCA 1.2 for early access developers and has been enhanced in the DOCA 1.3 release.
App Shield provides host monitoring, for cybersecurity vendors to create accelerated intrusion detection system solutions to identify an attack on any physical or virtual machine. It can feed data application status to security information and event management or extended detection and response tools. It can also enhance forensic investigations and incident response.
Security teams can protect their application processes, continuously validate integrity, and detect malicious activity with App Shield. If an attacker kills the machine security agent’s processes, App Shield can isolate the compromised host and prevent the malware from accessing confidential data or spreading to other resources. App Shield is an important advancement in the fight against cybercrime and an effective tool for zero-trust security.
DOCA 1.3 now offers the App Shield Lib with a reference application and a supporting user’s guide for early access members.
OVN IPsec encryption full offload
DOCA 1.3 includes support for existing OVN deployments to accelerate IPsec datapath packet processing. OVN networks tunnel packets between physical devices and provides a single global configuration option for IPsec encryption for all OVN tunneled traffic in the network. With DOCA 1.3, drivers and runtime components have been updated to offload IPSec packet encryption and decryption and HMAC authentication, all with zero host CPU utilization based on the BlueField DPU.
Host Based Networking
Host Based Networking (HBN) on the BlueField DPU helps manage and monitor traffic between VMs or containers on the same node. It also analyzes and encrypts (or decrypts then analyzes) traffic to and from the node—tasks that no ToR switch can perform.
HBN with BlueField DPUs revolutionizes how customers build and think about data center networks with a simplification of the ToR switch requirements as more intelligence is placed on the DPU. BlueField also provides an isolated environment for network policy configuration and enforcement, without software or dependencies on the host.
Additional DOCA 1.3 SDK updates
- LAG with Multi-host support
- VirtIO enhancements
Community
DOCA supports an open ecosystem for developers by providing industry-standard open APIs and frameworks and continuous improvements of DOCA Libs and services. To learn more about the community, or contribute to the innovation on the NVIDIA NGC catalog, join us on our forum.
Watch the following on-demand GTC sessions to learn more about DOCA
- From Zero to Hero: Transforming Cloud Data Centers with NVIDIA BlueField DPUs and DOCA SDK
- Accelerated Software-defined Infrastructure for Today’s Data Centers
- Accelerate Kubernetes Hybrid Clouds with BlueField DPUs and OpenShift for Ultimate Security and Efficiency
- BlueField Partner’s DPU Storage Solutions and Use Cases
Categories
MobileNetV2 for multiple detection
I have a model trained w/ mobilenetv2 for a specific project. The machine were the model is integrated can only accept one object at a time. The problem is I cannot control the user input since the machine will interact with lots of users there may be a;
a case where 2 or more objects are presented to the machine, I want to know if it’s possible for the model to determine that 2 or more objects with diff classification is indeed present in the machine, or if not what can be my work around?
My datasets doesnt have annotation but I’m not quite sure annotation would help since I’m only taking still images.
submitted by /u/clareeenceee
[visit reddit] [comments]
Here is my use case. I have a image set of a full 360 walk around of a vehicle. I want to be able to classify which images are of the front, rear, passenger side, and driver side of the vehicle. I can train a model with hundreds of these image sets, all of different vehicles, each with around 100 frames per set.
I’m wondering if Tensorflow would be effective in classifying images into those four categories. I understand it would probably be good at classifying types of vehicles. I’m just uncertain if it would be good at this classification which is essentially a rotation of the various vehicles.
submitted by /u/LordPSIon
[visit reddit] [comments]
Enjoy the finer things in life. May is looking pixel perfect for GeForce NOW gamers. RTX 3080 members can now take their games to the next level, streaming at 4K resolution on the GeForce NOW PC and Mac native apps — joining 4K support in the living room with SHIELD TV. There’s also a list Read article >
The post GFN Thursday Caught in 4K: 27 Games Arriving on GeForce NOW in May, Alongside 4K Streaming to PC and Mac Apps appeared first on NVIDIA Blog.
Hi eveyone, i am a novice with tensorflow and i am trying to build a simple model with 1 custom layer with 1 trainable parameter M and a skip connection between the input and the final custom layer. The custom layer should calculate
$$M + ln(x) + 0.5* [inputpreviouslayer]*x^2 $$
where x is the input of the network (hence the skip connection). In other words i want that the neural network learn M and the inputpreviouslayer.
i tried with:
class SimpleLayer(tf.keras.layers.Layer):
def __init__(self):
”’Initializes the instance attributes”’
super(SimpleDense, self).__init__()
def build(self, input_shape):
”’Create the state of the layer (weights)”’
q_init = tf.zeros_initializer()
self.M = tf.Variable(name=”Nuisance”,initial_value=q_init(shape=(1), dtype=’float32′),trainable=True)
def call(self, inputs):
”’Defines the computation from inputs to outputs”’
tf.math.log
return (self.M + tf.math.log( inputs[0], name=None ) +0.5 (1- inputs[1]*inputs[0] ))
and
from keras.layers import Input, concatenate
from keras.models import Model
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import regularizers
def prova():
inputs = Input(shape=(1,))
hidden = Dense(200,activation=”relu”)(inputs)
hidden = Dropout(0.1)(hidden, training=True)
hidden = Dense(300,activation=”relu”)(hidden)
hidden = Dropout(0.1)(hidden, training=True)
hidden = Dense(200,activation=”relu”)(hidden)
hidden = Dropout(0.1)(hidden, training=True)
deceleration = Dense(1)(hidden)
hidden = concatenate([inputs,deceleration])
params_mc = SimpleLayer(hidden)
testmodel = Model(inputs=inputs, outputs=params_mc)
return testmodel
and
nn = prova()
nn.compile(Adam(learning_rate=0.02), loss=”mse”)
history = nn.fit(x, y, epochs=15000 , verbose=0,batch_size=1048)
but when i try to run it i get
> __init__() takes 1 positional argument but 2 were given
can anybody tell me how to correctly modify the custom layer? how can i solve this issue? thanks
submitted by /u/ilrazziatore
[visit reddit] [comments]
CFO Commentary to Be Provided in Writing Ahead of CallSANTA CLARA, Calif., May 04, 2022 (GLOBE NEWSWIRE) — NVIDIA will host a conference call on Wednesday, May 25, at 2 p.m. PT (5 p.m. ET) to …
 Jetson Project of the Month “LiveChess2FEN” is a fully-functional framework that automatically digitizes a chessboard in real time using NVIDIA Jetson Nano.
Jetson Project of the Month “LiveChess2FEN” is a fully-functional framework that automatically digitizes a chessboard in real time using NVIDIA Jetson Nano.
American chess grandmaster and the eleventh World Chess Champion Bobby Fischer once said, “All that matters on the chessboard is good moves.”
Easy for him to say. But, if you are new to the game or looking to get better, how can you know that the moves you are making are in fact good ones? Wouldn’t it be great if you could analyze your game, play by play?
To address this problem, the latest Jetson Project of the Month winners developed LiveChess2FEN—a framework that automatically digitizes the configuration of a chessboard in real time—optimized on an NVIDIA Jetson Nano.
“This is the first attempt at deploying a chess digitization framework onto an embedded platform, obtaining similar if not better execution times than other approaches, which at least used a midrange laptop,” LiveChess2FEN creators David Mallasén Quintana, Alberto A. Del Barrio, and Manuel Prieto-Matias state in their paper.
LiveChess2FEN digitizes a chess game using the Forsyth–Edwards Notation (FEN), which is a standard notation using letters and numbers that represent a particular board position during a chess game. The project was created for amateur players or tournaments, where a webcam watches the board continuously and checks if the position of any of the pieces on the board has changed. The video is streamed through the learning models and returns any changing board position as a new FEN string.
In the NVIDIA Developer Forum, the developers state, “Previous work has shown promising results, but the recognition accuracy and the latency of state-of-the-art techniques still need further enhancements to allow their practical and affordable deployment.”
Additionally, current hardware solutions such as specialized boards or robotic arms can be expensive and difficult to deploy. Using the Jetson Nano, the team found a way to address these shortcomings.
The problem can be divided into two main parts. The first is recognizing the chessboard and its orientation, and then identifying the chess pieces and their precise position afterward.
To tackle the challenge, the team used a variety of software, including Keras API on top of TensorFlow to define and train the convolutional neural networks (CNNs) to test piece classification. To train their models, they used two labeled datasets of chess pieces that consisted of nearly 55,000 images.
They also used ONNX Runtime, TensorRT, ONNX-TensorRT, and several Python libraries. To help monitor compute resource usage on a Jetson Nano, they used the system monitoring utility jtop.
Using the Jetson Nano and optimizing the CNNs with ONNX Runtime and TensorRT they reduced the inference latency from 16.38 seconds down to 3.84 seconds.
Adding domain-specific knowledge to the inference of the models provided an edge when it came to accuracy. By testing different CNNs on TensorRT, the team achieved latency times ranging from 6 seconds down to 0.46 seconds. There were some tradeoffs between accuracy and speed, which are shown in the graph below.
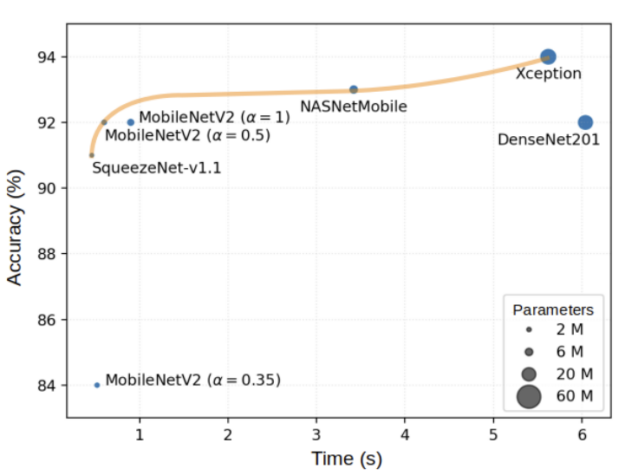
The team then devised a way to check if the pieces on the chessboard are in the same location by calculating if the grid of squares lines up with what the AI previously detected. This helps avoid constant recalculations based on observing the board, in order to determine the coordinates of the chess pieces more quickly. By checking if the chessboard pieces moved since the last inference, which takes 150 ms, the team saw a massive improvement in inference times.
In addition to a dedicated NVIDIA GPU, the system integrates a quad-core ARM CPU capable of performing the sequential computation necessary to detect the chessboards. This type of architecture has been widely used successfully for more than a decade in tasks related to image processing.
The result is a framework that can automatically digitize a chess position from an image in less than 1 second, with an accuracy of 92% classifying a piece, and 95% detecting changes on the board.
The source code of the LiveChess2FEN framework is available with an open-source license in GitHub.
Graphs are very common representations of natural systems that have connected relational components, such as social networks, traffic infrastructure, molecules, and the internet. Graph neural networks (GNNs) are powerful machine learning (ML) models for graphs that leverage their inherent connections to incorporate context into predictions about items within the graph or the graph as a whole. GNNs have been effectively used to discover new drugs, help mathematicians prove theorems, detect misinformation, and improve the accuracy of arrival time predictions in Google Maps.
A surge of interest in GNNs during the last decade has produced thousands of GNN variants, with hundreds introduced each year. In contrast, methods and datasets for evaluating GNNs have received far less attention. Many GNN papers re-use the same 5–10 benchmark datasets, most of which are constructed from easily labeled academic citation networks and molecular datasets. This means that the empirical performance of new GNN variants can be claimed only for a limited class of graphs. Confounding this issue are recently published works with rigorous experimental designs that cast doubt on the performance rankings of popular GNN models reported in seminal papers.
Recent workshops and conference tracks devoted to GNN benchmarking have begun addressing these issues. The recently-introduced Open Graph Benchmark (OGB) is an open-source package for benchmarking GNNs on a handful of massive-scale graph datasets across a variety of tasks, facilitating consistent GNN experimental design. However, the OGB datasets are sourced from many of the same domains as existing datasets, such as citation and molecular networks. This means that OGB does not solve the dataset variety problem we mention above. Therefore, we ask: how can the GNN research community keep up with innovation by experimenting on graphs with the large statistical variance seen in the real-world?
To match the scale and pace of GNN research, in “GraphWorld: Fake Graphs Bring Real Insights for GNNs”, we introduce a methodology for analyzing the performance of GNN architectures on millions of synthetic benchmark datasets. Whereas GNN benchmark datasets featured in academic literature are just individual “locations” on a fully-diverse “world” of potential graphs, GraphWorld directly generates this world using probability models, tests GNN models at every location on it, and extracts generalizable insights from the results. We propose GraphWorld as a complementary GNN benchmark that allows researchers to explore GNN performance on regions of graph space that are not covered by popular academic datasets. Furthermore, GraphWorld is cost-effective, running hundreds-of-thousands of GNN experiments on synthetic data with less computational cost than one experiment on a large OGB dataset.
 |
| Illustration of the GraphWorld pipeline. The user provides configurations for the graph generator and the GNN models to test. GraphWorld spawns workers, each one simulating a new graph with diverse properties and testing all specified GNN models. The test metrics from the workers are then aggregated and stored for the user. |
The Limited Variety of GNN Benchmark Datasets
To illustrate the motivation for GraphWorld, we compare OGB graphs to a much larger collection (5,000+) of graphs from the Network Repository. While the vast majority of Network Repository graphs are unlabelled, and therefore cannot be used in common GNN experiments, they represent a large space of graphs that are available in the real world. We computed two properties of the OGB and Network Repository graphs: the clustering coefficient (how interconnected nodes are to nearby neighbors) and the degree distribution gini coefficient (the inequality among the nodes’ connection counts). We found that OGB datasets exist in a limited and sparsely-populated region of this metric space.
 |
| The distribution of graphs from the Open Graph Benchmark does not match the larger population of graphs from the Network Repository. |
Dataset Generators in GraphWorld
A researcher using GraphWorld to investigate GNN performance on a given task first chooses a parameterized generator (example below) that can produce graph datasets for stress-testing GNN models on the task. A generator parameter is an input that controls high-level features of the output dataset. GraphWorld uses parameterized generators to produce populations of graph datasets that are varied enough to test the limits of state-of-the-art GNN models.
For instance, a popular task for GNNs is node classification, in which a GNN is trained to infer node labels that represent some unknown property of each node, such as user interests in a social network. In our paper, we chose the well-known stochastic block model (SBM) to generate datasets for this task. The SBM first organizes a pre-set number of nodes into groups or “clusters“, which serve as node labels to be classified. It then generates connections between nodes according to various parameters that (each) control a different property of the resulting graph.
One SBM parameter that we expose to GraphWorld is the “homophily” of the clusters, which controls the likelihood that two nodes from the same cluster are connected (relative to two nodes from different clusters). Homophily is a common phenomenon in social networks in which users with similar interests (e.g., the SBM clusters) are more likely to connect. However, not all social networks have the same level of homophily. GraphWorld uses the SBM to generate graphs with high homophily (below on the left), graphs with low homophily (below on the right), and millions more graphs with any level of homophily in-between. This allows a user to analyze GNN performance on graphs with all levels of homophily without depending on the availability of real-world datasets curated by other researchers.
 |
| Examples of graphs produced by GraphWorld using the stochastic block model. The left graph has high homophily among node classes (represented by different colors); the right graph has low homophily. |
GraphWorld Experiments and Insights
Given a task and parameterized generator for that task, GraphWorld uses parallel computing (e.g., Google Cloud Platform Dataflow) to produce a world of GNN benchmark datasets by sampling the generator parameter values. Simultaneously, GraphWorld tests an arbitrary list of GNN models (chosen by the user, e.g., GCN, GAT, GraphSAGE) on each dataset, and then outputs a massive tabular dataset joining graph properties with the GNN performance results.
In our paper, we describe GraphWorld pipelines for node classification, link prediction, and graph classification tasks, each featuring different dataset generators. We found that each pipeline took less time and computational resources than state-of-the-art experiments on OGB graphs, which means that GraphWorld is accessible to researchers with low budgets.
The animation below visualizes GNN performance data from the GraphWorld node classification pipeline (using the SBM as the dataset generator). To illustrate the impact of GraphWorld, we first map classic academic graph datasets to an x–y plane that measures the cluster homophily (x-axis) and the average of the node degrees (y-axis) within each graph (similar to the scatterplot above that includes the OGB datasets, but with different measurements). Then, we map each simulated graph dataset from GraphWorld to the same plane, and add a third z-axis that measures GNN model performance over each dataset. Specifically, for a particular GNN model (like GCN or GAT), the z-axis measures the mean reciprocal rank of the model against the 13 other GNN models evaluated in our paper, where a value closer to 1 means the model is closer to being the top performer in terms of node classification accuracy.
The animation illustrates two related conclusions. First, GraphWorld generates regions of graph datasets that extend well-beyond the regions covered by the standard datasets. Second, and most importantly, the rankings of GNN models change when graphs become dissimilar from academic benchmark graphs. Specifically, the homophily of classic datasets like Cora and CiteSeer are high, meaning that nodes are well-separated in the graph according to their classes. We find that as GNNs traverse toward the space of less-homophilous graphs, their rankings change quickly. For example, the comparative mean reciprocal rank of GCN moves from higher (green) values in the academic benchmark region to lower (red) values away from that region. This shows that GraphWorld has the potential to reveal critical headroom in GNN architecture development that would be invisible with only the handful of individual datasets that academic benchmarks provide.
 |
| Relative performance results of three GNN variants (GCN, APPNP, FiLM) across 50,000 distinct node classification datasets. We find that academic GNN benchmark datasets exist in GraphWorld regions where model rankings do not change. GraphWorld can discover previously unexplored graphs that reveal new insights about GNN architectures. |
Conclusion
GraphWorld breaks new ground in GNN experimentation by allowing researchers to scalably test new models on a high-dimensional surface of graph datasets. This allows fine-grained analysis of GNN architectures against graph properties on entire subspaces of graphs that are distal from Cora-like graphs and those in the OGB, which appear only as individual points in a GraphWorld dataset. A key feature of GraphWorld is its low cost, which enables individual researchers without access to institutional resources to quickly understand the empirical performance of new models.
With GraphWorld, researchers can also investigate novel random/generative graph models for more-nuanced GNN experimentation, and potentially use GraphWorld datasets for GNN pre-training. We look forward to supporting these lines of inquiry with our open-source GraphWorld repository and follow-up projects.
Acknowledgements
GraphWorld is joint work with Brandon Mayer and Bryan Perozzi from Google Research. Thanks to Tom Small for visualizations.