
 Transformers4Rec makes it easy to use SOTA NLP architectures for sequential and session-based recommendation by leveraging HuggingFace Transformers.
Transformers4Rec makes it easy to use SOTA NLP architectures for sequential and session-based recommendation by leveraging HuggingFace Transformers.
Recommender systems help you discover new products and make informed decisions. Yet, in many recommendation-dependent domains such as e-commerce, news, and streaming media services, users may be untrackable or have rapidly changing tastes depending on their needs at that moment.
Session-based recommendation systems, a sub-area of sequential recommendation, have recently gained popularity because they can recommend items relative to a user’s situation and preferences at any given point in time. Capturing short-term or contextual user preferences towards items is helpful in these domains.

In this post, we introduce the session-based recommendation task, which is supported by Transformers4Rec, a library from the NVIDIA Merlin platform. We then showcase how easy it is to create a session-based recommendation model in a few lines of code using Transformers4Rec and finally conclude with demonstrating an end-to-end session-based recommendation pipeline with NVIDIA Merlin libraries.
Transformers4Rec library features
Released at ACM RecSys’21, the NVIDIA Merlin team designed and open-sourced the NVIDIA Merlin Transformers4Rec library for sequential and session-based recommendation tasks by leveraging state-of-the-art Transformers architectures. The library is extensible by researchers, simple for practitioners, and fast and robust in industrial deployments.
It leverages the SOTA NLP architectures from the Hugging Face (HF) Transformers library, making it possible to quickly experiment with many different Transformer architectures and pretraining approaches in the RecSys domain.
Transformers4Rec also helps data scientists, industry practitioners, and academicians build recommender systems that can leverage the short sequence of past user interactions within the same session and then dynamically suggest the next item that the user may be interested in.

Here are some highlights of the Transformers4Rec library:
- Flexibility and efficiency: Building blocks are modularized and compatible with vanilla PyTorch modules and TF Keras layers. You can create custom architectures, for example, with multiple towers, multiple heads/tasks, and losses. Transformers4Rec supports multiple input features and provides configurable building blocks that can easily be combined for custom architectures.
- Integration with HuggingFace Transformers: Uses cutting-edge NLP research and makes state-of-the-art Transformer architectures available for the RecSys community for sequential and session-based recommendation tasks.
- Support for multiple input features: Transformers4Rec enables the usage of HF Transformers with any type of sequential tabular data.
- Seamless integration with NVTabular for preprocessing and feature engineering.
- Production-ready: Exports trained models to serve on NVIDIA Triton Inference Server in a single pipeline with online features preprocessing and model inference.
Develop your own session-based recommendation model
With only a few lines of code, you can build a session-based model based on a SOTA Transformer architecture. The following example shows how the powerful XLNet Transformer architecture can be used for a next-item prediction task.
As you may notice, the code in building a session-based model with PyTorch and TensorFlow is very similar, with only a couple of differences. The following code example builds an XLNET-based recommendation model with PyTorch and TensorFlow using the Transformers4Rec API:
#from transformers4rec import torch as tr
from transformers4rec import tf as tr
from merlin_standard_lib import Schema
schema = Schema().from_proto_text("schema path>")
max_sequence_length, d_model = 20, 320
# Define input module to process tabular input-features and to prepare masked inputs
input_module = tr.TabularSequenceFeatures.from_schema(
schema,
max_sequence_length=max_sequence_length,
continuous_projection=64,
aggregation="concat",
d_output=d_model,
masking="clm",
)
# Define Next item prediction-task
prediction_task = tr.NextItemPredictionTask(hf_format=True,weight_tying=True)
# Define the config of the XLNet architecture
transformer_config = tr.XLNetConfig.build(
d_model=d_model, n_head=8, n_layer=2,total_seq_length=max_sequence_length
)
# Get the PyT model
model = transformer_config.to_torch_model(input_module, prediction_task)
# Get the TF model
#model = transformer_config.to_tf_model(input_module, prediction_task)
To demonstrate the utility of the library and applicability of Transformer architectures in next-click prediction for user sessions, where sequence lengths are much shorter than those commonly found in NLP, the NVIDIA Merlin team used Transformers4Rec to win two session-based recommendation competitions:
- WSDM WebTour Workshop Challenge 2021 by Booking.com (NVIDIA solution)
- SIGIR eCommerce Workshop Data Challenge 2021 by Coveo (NVIDIA solution)
For more information about the Transformers4Rec library’s flexibility, see Transformers4Rec: A flexible library for Sequential and Session-based recommendation.
Steps for building an end-to-end, session-based recommendation pipeline using NVIDIA Merlin
Figure 3 shows the end-to-end pipeline for a session-based recommendation pipeline using NVIDIA Merlin Transformers4Rec.
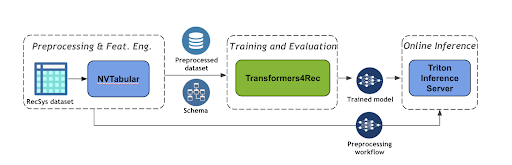
NVTabular is a feature engineering and preprocessing library for tabular data designed to quickly and easily manipulate the terabyte-scale datasets used to train large-scale recommender systems. It provides a high-level abstraction to simplify code and accelerates computation on the GPU using the RAPIDS cuDF library.
NVTabular supports different feature engineering transformations required by deep learning (DL) models such as categorical encoding and numerical feature normalization. It also supports feature engineering and generating sequential features. For more information about the supported features, see here.
In the following code example, you can easily see how to can create an NVTabular preprocessing workflow to group interactions at the session level, sorting the interactions by time. At the end, you obtain a processed dataset where each row represents a user session and corresponding sequential features for that session.
import nvtabular as nvt
# Define Groupby Operator
features = ['session_id', 'item_id', 'timestamp', 'category']
groupby_features = features >> nvt.ops.Groupby(
groupby_cols=["session_id"],
sort_cols=["timestamp"],
aggs={
'item_id': ["list", "count"],
'category': ["list"],
'timestamp': ["first"],
},
name_sep="-")
# create dataset object
dataset = nvt.Dataset(interactions_df)
workflow = nvt.Workflow(groupby_features)
# Apply the preprocessing workflow on the dataset
sessions_gdf = workflow.transform(dataset).compute()
Use Triton Inference Server to simplify the deployment of AI models at scale in production. Triton Inference Server enables you to deploy and serve your model for inference. It supports a number of different machine learning frameworks, such as TensorFlow and PyTorch.
The last step of the machine learning (ML) pipeline is to deploy the ETL workflow and trained model to production for inference. In the production setting, you want to transform the input data as done during training (ETL). For example, you should use the same normalization statistics for continuous features and the same mapping to encode the categories into contiguous IDs before you use the ML/DL model for a prediction.
Fortunately, the NVIDIA Merlin framework has an integrated mechanism to deploy both the preprocessing workflow (modeled with NVTabular) with a PyTorch or TensorFlow model as an ensemble model to NVIDIA Triton Inference. The ensemble model guarantees that the same transformation is applied to the raw inputs.
The following code example showcases how easy it is to create ensemble configuration files using the NVIDIA Merlin Inference API functions, and then serve the model to TIS.
import tritonhttpclient
import nvtabular as nvt
workflow = nvt.Workflow.load("")
from nvtabular.inference.triton import export_tensorflow_ensemble as export_ensemble
#from nvtabular.inference.triton import export_pytorch_ensemble as export_ensemble
export_ensemble(
model,
workflow,
name="ensemble model name>",
model_path="model path>",
label_columns=["label column names>"],
sparse_max=dict or None>
)
tritonhttpclient.InferenceServerClient(url="ip:port>")
triton_client.load_model(model_name="ensemble model name>")
With a few lines of code, you can serve the NVTabular workflow, a trained PyTorch or TensorFlow model, and an ensemble model to NVIDIA Triton Inference Server, in order to execute end-to-end model deployment. Using the NVIDIA Merlin Inference API, you can send a raw dataset as a request (query) to the server and then obtain the prediction results from the server.
In essence, NVIDIA Merlin Inference API creates model pipelines using the NVIDIA Triton ensembling feature. An NVIDIA Triton ensemble represents a pipeline of one or more models and the connection of input and output tensors between those models.
Conclusion
In this post, we introduced you to NVIDIA Merlin Transformers4Rec, a library for sequential and session-based recommendation tasks that seamlessly integrates with NVIDIA NVTabular and NVIDIA Triton Inference Server to build end-to-end ML pipelines for such tasks.
For more information, see the following resources:
- Transformers4Rec GitHub repo
- NVIDIA Merlin org on GitHub
- Transformers4Rec: Bridging the Gap between NLP and Sequential / Session-Based Recommendation (ACM RecSys 2021)
- Transformers with multi-modal features and post-fusion context for e-commerce session-based recommendation (SIGIR eCommerce Workshop Data Challenge 2021)
- GRU4Rec-Recurrent Neural Networks with Top-k Gains for Session-based Recommendations
- BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
- SasRec: Self-Attentive Sequential Recommendation