I’m both a collector and a coin dealer. I look through tens of thousands of coins a week for rare dates, errors, etc. But as I get older, my eyes are not what they use to be. So it’s getting somewhat difficult for me to see the key details on the coin. So I decided to make a setup that can look through coins for me. I’ve been greatly influenced by this machine that does everything I want, but I need something a lot smaller.
I do have a basic background in coding and how it works. But I have little experience with making an AI. I’ve watched many video tutorials and I now understand clearly how an AI learns. I think the best route is to use Python, TensorFlow, and open-cv. But I keep getting some kind of errors that have been a major roadblock for me.
If this is relevant. My company setup is a ryzen 9 5900x. 3080 gpu and has 64gb of ram.
I’m looking for someone who can guide me through installing and training an AI model. I will compensate for your time, either in money or in collectible coins. What I mean for collectable coins is good quality coins. Not those cheapy coins you pick up from gift shops. But actually pieces of history. I’ve got silver coins, I’ve got a ton of English coins from 1600s-1800s. You can check out my ebay store to get a idea of what I have to offer. https://www.ebay.com/sch/uncommoncentscoins/m.html?_nkw&_armrs=1&_ipg&_from&LH_Complete=1&LH_Sold=1&rt=nc&_trksid=p2046732.m1684
I was chatting with an artist today and he was showing me some AI art he created. Basically he’d create base artwork and then process it through an AI to add some random stylization. I asked him about the process and he was pretty secretive about it, but mentioned he uses Tensor Flow. He couldn’t give any more details.
I’m in love with the idea and I was curious if anyone knew of any sample projects that do something similar, or any resources to get me started?
Boost productivity and model training with new pretrained models and features such as ONNX model weights import, REST APIs, and TensorBoard visualization.
Today, NVIDIA announced the general availability of the latest version of the TAO Toolkit. As a low-code version of the NVIDIA Train, Adapt and Optimize (TAO) framework, the toolkit simplifies and accelerates the creation of AI models for speech and vision AI applications.
With TAO, developers can use the power of transfer learning to create production-ready models customized and optimized for many use-cases. These include detecting defects, translating languages, or managing traffic—without the need for massive amounts of data.
This version boosts developer productivity with new pretrained vision and speech models. It also includes key new features such as ONNX model weights import, REST APIs, and TensorBoard integration.
Deploy TAO Toolkit as-a-Service with REST APIs:Build a new AI service or integrate into an existing one with REST APIs. You can manage and orchestrate the TAO Toolkit service on Kubernetes. With TAO Toolkit as-a-service IT managers can deliver scalable services using industry-standard APIs.
Bring your own model weights: Fine-tune and optimize your non-TAO models with TAO. Import pretrained weights from ONNX and take advantage of TAO features like pruning and quantization on your own model. This is supported for image classification and segmentation tasks.
Visualize with TensorBoard: Understand your model training performance by visualizing scalars such as training and validation loss, model weights, and predicted images in TensorBoard. Compare results between experiments by changing hyperparameters and choose the one that best fits your needs.
Pretrained models: Pretrained models speed up the customization process for you to fine-tune through the power of transfer learning, with less data.
Some of the new pretrained models in this latest version can:
Apply data gathered from LIDAR sensors for robotics and automotive applications.
Classify human actions based on human poses that can be used in public safety, retail, and worker safety use cases.
Estimate keypoints on humans, animals, and objects to help portray actions or simply define the object shape.
Create custom voices with just 30 minutes of recorded data to power smart devices, game characters, and quick service restaurants.
Enterprise support for TAO Toolkit is available with NVIDIA AI Enterprise, an end-to-end software suite for AI development and deployment. This new release of TAO Toolkit will be included in the next quarterly update to NVIDIA AI Enterprise.
Watch demo videos of new features including Rest APIs, TensorBoard, and pretrained models.
Solutions using TAO Toolkit
Develop and deploy AI-powered Robots with NVIDIA Isaac Sim and NVIDIA TAO.
Read the partner blog from LexSet on how to use their platform to generate synthetic data and fine-tune object detection and segmentation models with the TAO Toolkit.
Computer vision specialist Landing AI has a unique calling card: Its co-founder and CEO is a tech rock star. At Google Brain, Andrew Ng became famous for showing how deep learning could recognize cats in a sea of images with uncanny speed and accuracy. Later, he founded Coursera, where his machine learning courses have attracted Read article >
Join NVIDIA at Automate 2022, June 6-9, to learn about AI platforms for manufacturing, robotics, and logistics that improve efficiency, scalability, and production across industries.
Clara Parabricks now includes rapid variant annotation tools, support for tumor-only variant calling in clinical settings, and additional support on ampere GPUs.
Bioinformaticians are constantly looking for new tools that simplify and enhance genomic analysis pipelines. With over 60 tools, NVIDIA Clara Parabricks powers accurate and accelerated genomic analysis for germline and somatic workflows in research and clinical settings.
The rapid increase in sequencing data demands faster variant call format (VCF) reading and writing speeds. Clara Parabricks 3.8 expands rapid variant annotation, post-variant calling, support of custom database annotation with snpswift, and variant consequence calling with bcftools. On Clara Parabricks, snpswift provides fast and accurate VCF database annotation and leverages a wide range of databases.
Advances in sequencing technologies are amplifying the role of genomics in clinical oncology. NVIDIA Clara Parabricks now provides tumor-only calling with somatic callers LoFreq and Mutect2 for clinical cancer workflows. Tumor-normal calling is available on Parabricks with LoFreq, Mutect2, Strelka2, SomaticSniper, Muse.
Genomic scientists can further accelerate genomic analysis workflows by running Clara Parabricks with a wider array of GPU architectures, including A6000, A100, A10, A30, A40, V100, and T4. This also supports customers using next-generation sequencing instruments powered by specific NVIDIA GPUs for basecalling that want to use the same GPUs for secondary analysis with Clara Parabricks.
Expanded rapid variant annotation
In the January release of Clara Parabricks 3.7, a new variant annotation tool was added that helps provide functional information of a variant for downstream genomic analysis. This is important, as correct variant annotation can assist with final conclusions of genomic studies and clinical diagnosis.
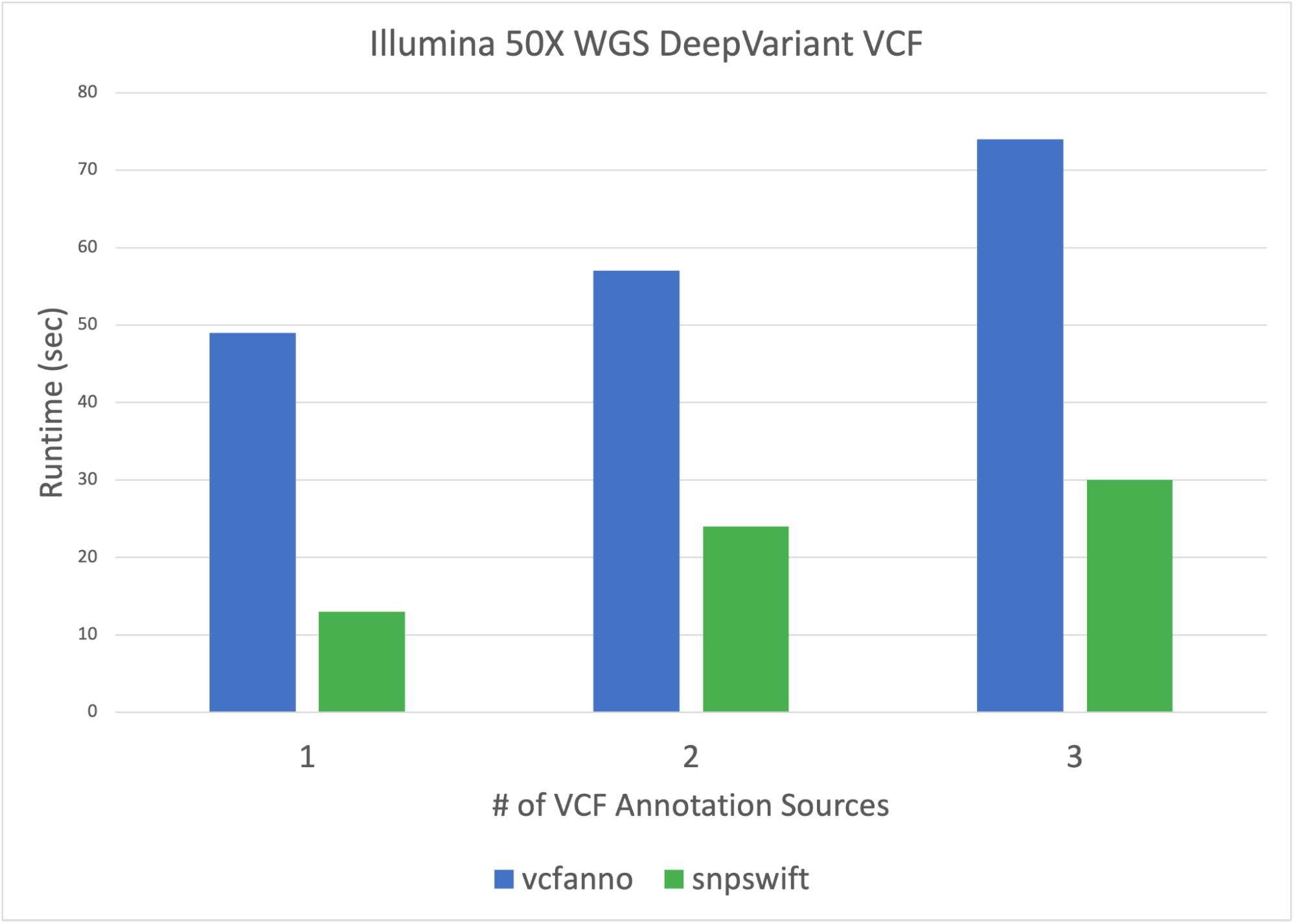
Parabricks’ variant annotation tool, snpswift, provides fast and accurate VCF database annotation that delivers results in shorter runtimes than other community variant annotation solutions such as vcfanno. Snpswift brings more functionality and acceleration while retaining the essential functionality of accurate allele-based database annotation of VCF files. The new snpswift tool also supports annotating a VCF file with gene name data from ENSEMBL, helping to make sense of coding variants.
Supported databases include dbSNP, gnomAD, COSMIC, ClinVar, and 1000 Genomes. Snpswift can annotate these jointly to provide important information for filtering VCF variants and interpreting their significance. Additionally, snpswift is able to annotate VCFs with information from an ENSEMBL GTF to add detailed information and leverage other widely used databases in the field.
Figure 1. Clara Parabricks’ variant annotation tool snpswift provides faster, more accurate VCF database annotation than other community variant annotation tools such as vcfanno
In addition to these widely used databases, many research institutions and companies have their own rich internal datasets, which can provide valuable domain-specific information for each variant.
Snpswift in Clara Parabricks 3.8 now annotates VCFs with multiple custom TSV databases. Snpswift is also able to annotate a 6 million variant HG002 VCF with a custom TSV containing 500K variants in less than 30 seconds. Users are able to annotate VCFs with VCF, GTF, and TSV databases jointly—all with one command and in one run.
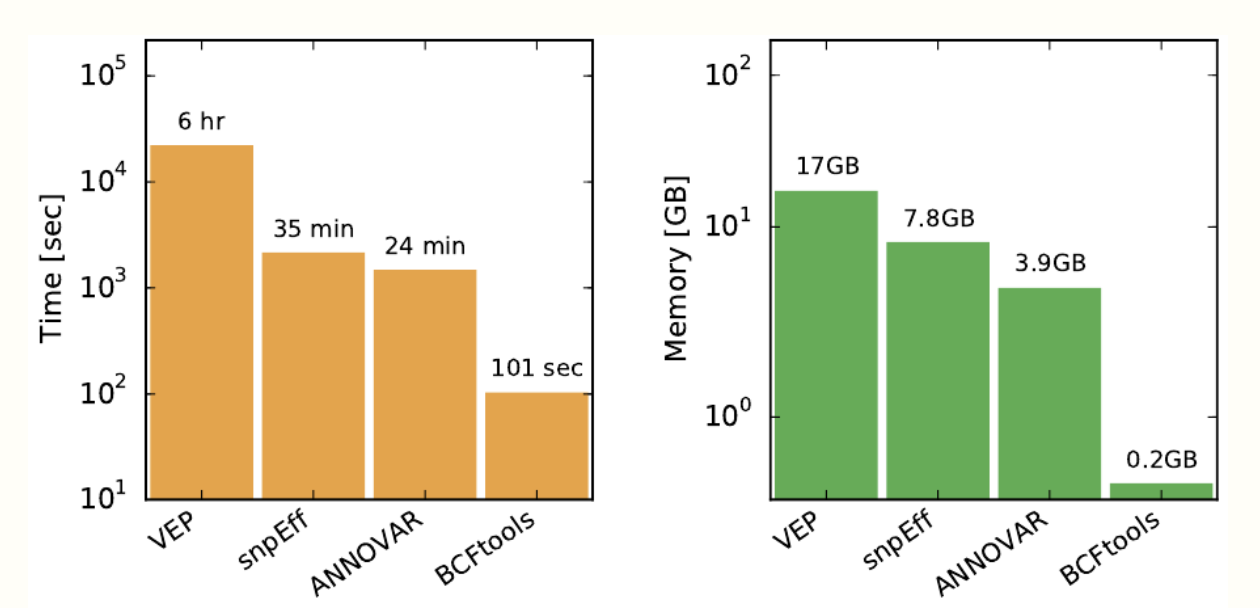
Finally, Clara Parabricks 3.8 has included consequence prediction. Predicting the functional outcome of a variant is a vital step in annotation for categorization and prioritization of genetic variants. Parabricks 3.8 offers a bcftoolscsq command that wraps the well known and extremely fast bcftools csq tool, providing haplotype-aware consequence predictions. This leads to phasing of variants in a VCF file to avoid common errors when variants affect the same codon.
Figure 2. Image taken from this Consequence Calling GitHub link. Performance comparison of BCFtools/csq with three popular consequence callers using a single-sample VCF with 4.5M sites
Clara Parabricks has demonstrated 60x acceleration for state-of-the-art bioinformatics tools compared to CPU-based environments. End-to-end analysis of whole-genome workflows runs in 22 minutes and exome workflows in just 4 minutes. Large-scale sequencing projects and other whole-genome studies are able to analyze over 60 genomes a day on a single DGX server while reducing associated costs and generating more useful insights than ever before.
To get started on NVIDIA Clara Parabricks for your germline, cancer, and RNA-Seq analysis workflows, try a free 90-day trial. You can access Clara Parabricks on premise or in the cloud with AWS Marketplace.
An overview of how to annotate variants with Parabricks 3.8 and run consequence prediction using example data is available here as a GitHub Gist.
I have adapted this autoencoder code from one of the tutorials and is as below. I am training the network on mnist images.
I found while experimenting with the network that model.fit() fires encoder-decoder network twice; even when the number of training sample is just 1 and number of epochs selected is also 1 with batch_size is None
import numpy as np import tensorflow as tf import tensorflow.keras as k import matplotlib.pyplot as plt from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, UpSampling2D # seed values np.random.seed(111) tf.random.set_seed(111)
# Encoder Network class Encoder(k.layers.Layer): def __init__(self): super(Encoder, self).__init__() self.conv1 = Conv2D(filters=32, kernel_size=3, strides=1, activation = 'relu', padding='same') self.conv2 = Conv2D(filters=32, kernel_size=3, strides=1, activation='relu', padding='same') self.conv3 = Conv2D(filters=16, kernel_size=3, strides=1, activation='relu', padding='same') self.pool = MaxPooling2D(padding='same') def call(self, input_features): x = self.conv1(input_features) x = self.pool(x) x = self.conv2(x) x = self.pool(x) x = self.conv3(x) x = self.pool(x) return x # Decoder Network class Decoder(k.layers.Layer): def __init__(self): super(Decoder, self).__init__() self.conv1 = Conv2D(filters=16, kernel_size=3, strides=1, activation='relu', padding='same') self.conv2 = Conv2D(filters=32, kernel_size=3, strides=1, activation='relu', padding='same') self.conv3 = Conv2D(filters=32, kernel_size=3, strides=1, activation='relu', padding='valid') self.conv4 = Conv2D(filters = 1, kernel_size=3, strides=1, activation='softmax', padding='same') self.upsample = UpSampling2D(size=(2,2)) def call(self, encoded_features): x = self.conv1(encoded_features) x = self.upsample(x) x = self.conv2(x) x = self.upsample(x) x = self.conv3(x) x = self.upsample(x) x = self.conv4(x) return x # Autoencoder Network class Autoencoder(k.Model): def __init__(self): super(Autoencoder, self).__init__() self.encoder = Encoder() self.decoder = Decoder() def call(self, input_features): print("Autoencoder call") encode = self.encoder(input_features) decode = self.decoder(encode) return decode
Train the model
model = Autoencoder() model.compile(loss='binary_crossentropy', optimizer='adam') sample = np.expand_dims(x_train[1], axis=0) sample_noisy = np.expand_dims(x_train_noisy[1], axis=0) print("shape of sample: {}".format(sample.shape)) print("shape of sample_noisy: {}n".format(sample_noisy.shape)) loss = model.fit(x=sample_noisy, y=sample, epochs=1)
I am training the model on only one sample for only 1 iteration. However, the print statements shows that my autoencoder.call() function is getting called twice.
I have trained a model on my computer using the YoloV5 algorithm and I was trying to run it on my Raspberry Pi. It was a classification model and I converted the model from .pt to .tflite. Unfortunately, when I run it, it tells me the index is out of range. Did I convert the file wrong? My labels file has the right amount of classes…

") Boost productivity and model training with new pretrained models and features such as ONNX model weights import, REST APIs, and TensorBoard visualization.
Boost productivity and model training with new pretrained models and features such as ONNX model weights import, REST APIs, and TensorBoard visualization. Join NVIDIA at Automate 2022, June 6-9, to learn about AI platforms for manufacturing, robotics, and logistics that improve efficiency, scalability, and production across industries.
Join NVIDIA at Automate 2022, June 6-9, to learn about AI platforms for manufacturing, robotics, and logistics that improve efficiency, scalability, and production across industries.  Clara Parabricks now includes rapid variant annotation tools, support for tumor-only variant calling in clinical settings, and additional support on ampere GPUs.
Clara Parabricks now includes rapid variant annotation tools, support for tumor-only variant calling in clinical settings, and additional support on ampere GPUs.