
 With the increasing demand for access to pretrained large language model (LLM) weights, the climate around LLM sharing is changing. Recently, Meta released Open Pretrained…
With the increasing demand for access to pretrained large language model (LLM) weights, the climate around LLM sharing is changing. Recently, Meta released Open Pretrained…
With the increasing demand for access to pretrained large language model (LLM) weights, the climate around LLM sharing is changing. Recently, Meta released Open Pretrained Transformer, a language model with 175 billion parameters. BigScience is on schedule to release its multilingual language model with 176 billion parameters in a few months.
As more LLMs become available, industries need techniques for solving real-world natural language tasks. It has been shown that model prompting methods can elicit good zero– and few-shot performance from LLMs and help yield quality results on various downstream natural language processing (NLP) tasks. The whitepaper proposed prompting as a solution to make general, pretrained LLMs practically useful in the new pretrain, prompt, and predict paradigm that is becoming increasingly popular in the NLP field.
However, when you are applying prompting methods to industrial NLP applications, there are other challenges to consider. For any downstream NLP task, you must collect labeled data to instruct the language model on how to produce the expected results.
Although for many tasks there is plenty of labeled English data, there are few benchmark-worthy, non-English, downstream datasets. Scarcity of labeled data is the number one challenge for industry to perform NLP tasks in low-resource language environments.
Furthermore, companies usually must dynamically solve multiple downstream NLP tasks that can evolve over time. Continuous learning for new tasks without forgetting previously learned tasks is still a hot research topic. A nice and clean solution means lower model maintenance, lower deployment costs, and fast development.
In this post, we show you how to adapt p-tuning, a prompt learning method, to low-resource language settings. We use an improved version of p-tuning implemented in NVIDIA NeMo that enables the continuous multitask learning of virtual prompts. In particular, we focus on adapting our English p-tuning workflow to Swedish. Learn more about how a consortium in Sweden plans to make the language model available in Nordic regions.
Our proposed workflow is generic and can easily be modified for other languages.
Why large language models?
As shown in the language model scaling law study by OpenAI, language model performance improves as the language model size increases. This has led to a race to train larger and larger language models.
NVIDIA recently trained a Megatron Turing NLG 530B model, which has superior zero– and few-shot learning performance. To access LLMs, researchers can use paid model APIs such as the ones provided by OpenAI or deploy publicly released models locally.
When you have an LLM that understands language well, you can apply prompt learning methods to make the model solve a plethora of NLP downstream tasks.
A short overview of prompt learning and p-tuning
Instead of selecting discrete text prompts in a manual or automated fashion, prompt learning uses virtual prompt embeddings that can be optimized using gradient descent. These virtual embeddings get automatically inserted among the discrete token embeddings from a text prompt.

During prompt learning, the entire GPT model is frozen and only these virtual token embeddings are updated at each training step. The prompt learning process results in a small number of virtual token embeddings that can be combined with a text prompt to improve task performance at inference time.
In p-tuning specifically, a small long short-term memory (LSTM) model is used as a prompt encoder. The input to the prompt encoder is a task name and the outputs are task-specific virtual token embeddings that are passed into the LLM along with the text prompt embeddings.

A multitask continuous learning solution
Figure 2 shows that p-tuning uses a prompt encoder to generate virtual token embeddings. In the original p-tuning paper, the prompt encoder can only work for one task. We extended it in our NeMo implementation so that the prompt encoder can be conditioned on different tasks’ names.
When the prompt encoder is trained, it maps the task names to a set of virtual token embeddings. This enables you to build an embedding table that stores the mapping between task names and virtual token embeddings for each task. Using this embedding table enables you to continuously learn new tasks and avoid catastrophic forgetting. For example, you can start p-tuning with tasks A and B.
After training, you can save the virtual token embeddings for tasks A and B in the table and freeze them. You can proceed to train task C with another fresh prompt encoder. Similarly, after the training, you save the virtual token embeddings for task C in the prompt table. During the inference, the model can look up the prompt table and use the correct virtual token embeddings for different tasks.
In addition to the continuous learning capability, our modified version of p-tuning has several other benefits. First, our implementation elicits quality model predictions. In our session at GTC 2022 earlier this year on using P-tuning to Significantly Improve the Performance of Your Large NLP Model, we showed that p-tuning helped achieve state-of-art accuracy for downstream NLP tasks.
Second, p-tuning requires only a few labeled data points to give reasonable results. For example, for an FIQA sentiment analysis task, it used 1,000 data examples to achieve 92% accuracy.
Third, p-tuning as described in the original paper, and even more so in our specific implementation, is extremely parameter-efficient. During p-tuning, an LSTM with parameters equal to a small fraction of the original GPT model’s parameters is tuned while the GPT model weights remain frozen. At the end of training, the LSTM network can be discarded and only the virtual prompts themselves need to be saved. This means parameters totaling less than ~0.01% of the GPT model’s size must be stored and used during inference to achieve dramatically improved task performance compared to zero– and few-shot inference.
Fourth, p-tuning is also more resource-efficient during training. Freezing the GPT model means that we didn’t have to store optimizer states for those model parameters and we didn’t have to spend time updating GPT model weights. This saved a considerable amount of GPU memory.
Lastly, the virtual prompt token parameters are decoupled from the GPT model. This yields the ability to distribute small virtual token parameter files that can be plugged into a shared access GPT model without the need for also sharing updated GPT model weights, as would be required if the GPT model were fine-tuned.
Creating Swedish downstream task datasets
To apply p-tuning to non-English downstream tasks, we labeled data in the target language. As there is an abundance of labeled English downstream task data, we used a machine translation model to translate this English labeled data into the target low-resource language. For this post, we translated our English data into Swedish. Thanks to p-tuning’s low labeled data requirements, we didn’t have to translate a lot of labeled data points.
To have complete control of the translation model, we chose to use an in-house translation model trained from scratch. This model is trained with English to Swedish/ Norwegian (one-to-many) direction using the NeMo NMT toolkit. The training data (parallel corpus) was obtained from Opus. The English to Swedish translation quality was manually evaluated by a native bilingual English and Swedish speaker.
We also used other translation models to help check the quality of our translation model. We translated a handful of random samples from the original English benchmark data and manually checked the quality of the other model translations compared with our own. We used deepL, the Google translation API, and DeepTranslator.
Apart from some clock-and-time systematic errors, the overall translation quality was good enough for us to proceed with converting the English-labeled data into Swedish. With the training and verification of our NeMo NMT English to Swedish translation model complete, we used the model to translate two English benchmark datasets:
- Financial Sentiment Analysis (FIQA)
- Assistant Benchmarking (Assistant)
For convenience, we use svFIQA and svAssistant to distinguish between the original English and the translated Swedish benchmark datasets.
Here are randomly selected examples of training records from FIQA and svFIQA, respectively:
English:
{"taskname": "sentiment-task", "sentence": "Barclays PLC & Lloyds Banking Group PLC Are The 2 Banks I'd Buy Today. Sentiment for Lloyds ", "label": "positive"}
Swedish:
{"taskname": "sentiment-task", "sentence": "Barclays PLC & Lloyds Banking Group PLC är de 2 banker jag skulle köpa idag.. Känslor för Lloyds", "label": "positiva"}
The translated dataset should preserve the correct grammar structure of the actual English source data. Because the sentiment refers to the two banks, it’s plural. The ground truth label translated to Swedish should also reflect the correct Swedish grammar, that is, ‘’positiva’’.
For completeness, we also randomly selected one example each from Assistant and svAssistant:
English:
{"taskname": "intent_and_slot", "utterance": "will you please get the coffee machine to make some coffee", "label": "nIntent: iot_coffeenSlots: device_type(coffee machine)"}
Swedish:
{"taskname": "intent_and_slot", "utterance": "kommer du snälla få kaffemaskinen för att göra lite kaffe", "label": "Intent: iot _ kaffe Slots: enhet _ typ (kaffemaskin)"}
GPT models
The Swedish GPT-SW3 checkpoints used in the following experiments were a result of a partnership between AI Sweden and NVIDIA. More specifically, AI Sweden’s GPT-SW3 checkpoint with 3.6 billion parameters is pretrained using Megatron-LM. This model was used to conduct the Swedish multitask p-tuning experiments described in this post.
Multitask p-tuning experiments
To simulate the typical enterprise customer use case, we imagined a scenario where a user first needs to solve a sentiment analysis NLP task with high accuracy. Later, as the business evolves, the user needs to continue to solve a virtual assistant task with the same model to reduce cost.
We ran p-tuning twice in a continuous learning setup for Swedish. We used the svFIQA dataset for the first NLP task. We then used the svAssistant dataset for the second NLP task.
We could have p-tuned both tasks simultaneously. However, we choose to do two rounds of p-tuning consecutively to showcase the continuous prompt learning capability in NeMo.
We first conducted a series of short hyperparameter tuning experiments for svFIQA and svAssistant using a slightly modified version of this p-tuning tutorial notebook. In these experiments, we identified the optimal number of virtual tokens and best virtual token placements for each task.
To manipulate the total number of virtual tokens and their positions within a text prompt, we modified the following sentiment task template within the p-tuning model’s training config file. For more information about the p-tuning configuration file, see the prompt learning config section of our NeMo documentation.
"taskname": "sentiment",
"prompt_template": " {sentence} sentiment:{label}",
"total_virtual_tokens": 16,
"virtual_token_splits": [10,6],
"truncate_field": None,
"answer_only_loss": True,
"answer_field": "label",
This prompt template is language-specific. Apart from the virtual tokens’ placement and the number of virtual tokens used, it is important to translate the words within each prompt template into the target language. Here, the term “sentiment” (added between the final virtual prompt tokens and the label) should be translated into Swedish.
In our experiments, we used 10-fold cross-validation to calculate performance metrics. During our hyperparameter search, we p-tuned the Swedish GPT-SW3 model on the first fold until the validation loss plateaued after 10-20 epochs.
After a few rounds of experimentation in this manner, we decided to use the following template for all 10 folds of the svFIQA dataset:
"taskname": "sentiment-task",
"prompt_template": " {sentence}:{label}",
"total_virtual_tokens": 10,
"virtual_token_splits": [10],
"truncate_field": None,
"answer_only_loss": True,
"answer_field": "label",
The term “sentiment” was removed from the prompt template and was instead directly included in the {sentence} part of the prompt. This allowed us to easily translate “sentiment” into Swedish along with the rest of the English sentence:
{"taskname": "sentiment-task", "sentence": "Barclays PLC & Lloyds Banking Group PLC är de 2 banker jag skulle köpa idag.. Känslor för Lloyds", "label": "positiva"}
After finding an optimal configuration for training, we p-tuned our Swedish GPT-SW3 model on each of the 10 svFIQA folds. We evaluated the p-tuned checkpoint for every fold on its corresponding test split. We added intent and slot prediction capability to our GPT-SW3 model by repeating the same steps with the svAssistant dataset, this time restoring our checkpoints trained on svFIQA and adding the intent and slot task.
Results
To establish a baseline, and because there are no existing benchmarks for Swedish in this context, we used the original AI Sweden GPT-SW3 model’s zero–, one–, and few-shot learning performance as the baseline (Figure 3).

As can be seen, except for zero-shot, the few-shot learning performance on svFIQA is 42-52%. Understandably, the performance of zero-shot is significantly worse due to the fact that the GPT model receives zero labeled examples. The model generates tokens that are most likely unrelated to the given task.
Given the binary nature of this sentiment analysis task, we mapped all Swedish grammatical variants of the words “positiv” and “negativ” to the same format before calculating task accuracy.
positiv, positivt, positiva → positiv negativ, negativt, negativa → negativ
| fold_id | accuracy |
| 0 | 87.18% |
| 1 | 79.49% |
| 2 | 85.47% |
| 3 | 79.49% |
| 4 | 78.63% |
| 5 | 86.32% |
| 6 | 78.63% |
| 7 | 82.91% |
| 8 | 77.78% |
| 9 | 90.60% |
| average across 10 folds | 82.65% |
With this re-mapping mechanism, we achieved fairly good results: 82.65%. The p-tuning performance on the svFIQA test is averaged across all 10 folds.
Table 2 shows the results for the second round of p-tuning on the svAssistant dataset (intent and slot classification). Scores are averaged across all 10 folds as well.
| Precision | Recall | F1 -Score | |
| average | 88.00% | 65.00% | 73.00% |
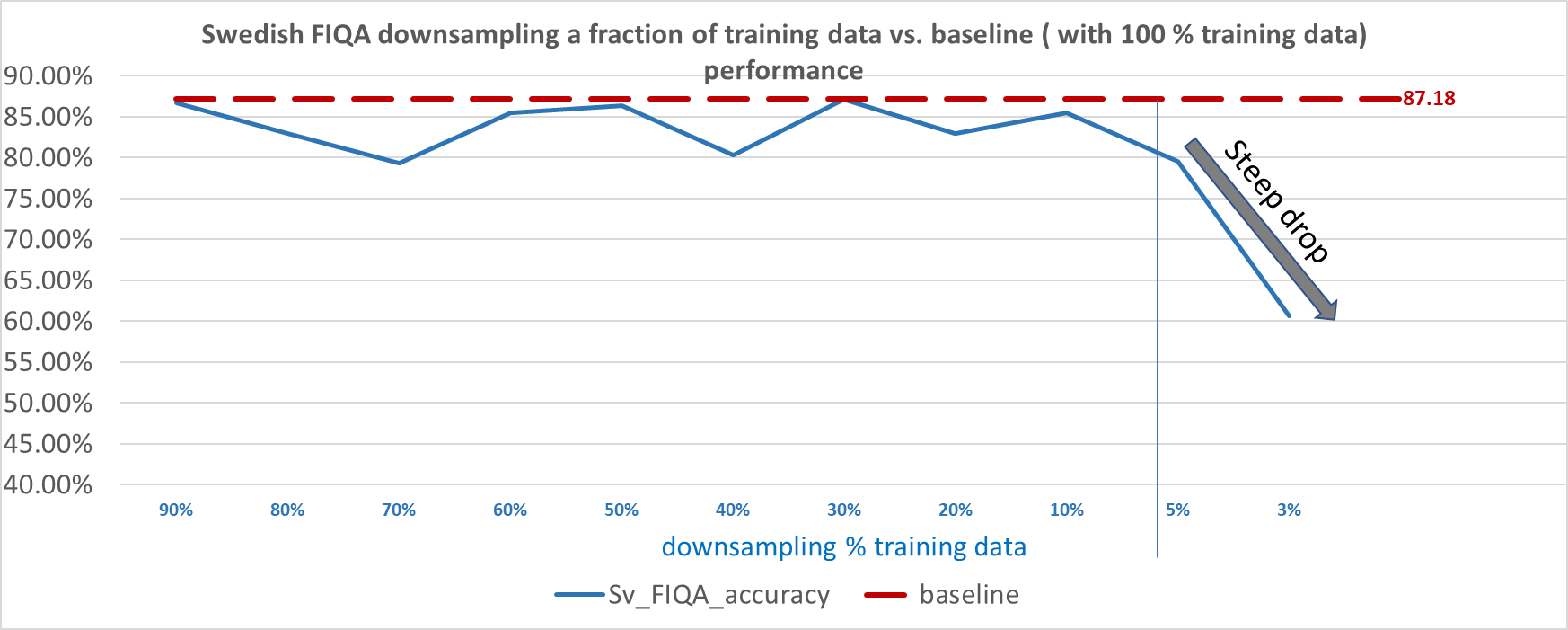
Next, we further explored the question, “How much can we reduce the total amount of training data without decreasing performance?”
For the svFIQA dataset, we discovered that we can get away with as little as one-tenth of the training data in each training run and still maintain acceptable performance. However, from 5% training data onwards (with only 47 data points for training), we started to see steep degradation of performance and the performance became unstable at around 1% (as little as nine data points for training, averaged across six training runs, each with nine randomly sampled data points).
Future work
We noticed that the results for intent and slot classification can be improved. They are heavily dependent on the translation model’s ability to translate non-natural text from English to Swedish. In the following example, the English intent and slot prompt formatting were difficult for the translation model to translate accurately, compromising the quality of the Swedish translations.
- The label for English is “Intent: alarm_set Slots: date(sunday), time (eight am)”.
- When it is translated to Swedish, it became “tid (åtta am)”.
The translation model skipped the words “Intent:” and “Slot:” completely. It also dropped the translation for alarm_set in the intent as well as date(sunday) in the slot.
In the future, we will formulate source language data as natural language before translating it into the target language. We are also experimenting with a pretrained mT5 model that can skip the translation steps completely. The early results are promising, so stay tuned for the full results.
Lastly, we also plan to compare prompt learning methods against full fine-tuning of the base GPT models. This will enable us to compare trade-offs between the two task adaptation approaches.
Conclusion
In this post, we demonstrated a parameter-efficient solution to solving multiple NLP tasks in a low-resource language setting. Focusing on the Swedish language, we translated English sentiment classification and intent/slot classification datasets into Swedish. We then p-tuned the Swedish GPT-SW3 model on these datasets and achieved good performance compared to our few-shot learning baselines.
We showed that our approach can help you train the prompt encoder with as little as one-tenth of the original training data tuning less than 0.1% of the model’s original parameters, while still maintaining performance.
Because the LLM is frozen during training, p-tuning requires fewer resources and the whole training process can be done efficiently and quickly, which democratizes LLM access for anyone. You can bring your own data and tune the model for your own use cases.
In our NeMo p-tuning implementation, we make lightweight, continuous learning easy as well. You can use our approach to continuously learn and deploy new tasks without degrading the performance of previously added tasks.
Acknowledgments
We are immensely grateful to Amaru Cuba Gyllensten (amaru.cuba.gyllensten@ri.se), Ariel Ekgren (ariel.ekgren@ai.se), and Magnus Sahlgren (magnus.sahlgren@ai.se) for sharing their GPT-SW3 model checkpoint with us and for their insights and suggestions for this post.