Join this digital conference from August 2-4 to learn how science is being advanced through the work done at Open Hackathons or accelerated using OpenACC.
Join this digital conference from August 2-4 to learn how science is being advanced through the work done at Open Hackathons or accelerated using OpenACC.
A new approach to data The convergence of AI and IoT has shifted the center of gravity for data away from the cloud and to the edge of the network. In retail stores, factories,…
A new approach to data
The convergence of AI and IoT has shifted the center of gravity for data away from the cloud and to the edge of the network. In retail stores, factories, fulfillment centers, and other distributed locations, thousands of sensors are collecting petabytes of data that power insights for innovative AI use cases. Because the most valuable insights are generated at the edge, organizations have quickly adopted new technologies and processes to better capitalize on this new center of gravity.
One of the major technologies adopted is edge computing, the process of bringing the computing power for an application to the same physical location where sensors are collecting information. When this computing method is used to power AI applications at the edge, it’s referred to as edge AI.
To ensure that these edge locations harvesting valuable insights do not exist in isolated silos, organizations are increasingly working to integrate their edge computing solutions into their existing workflows to develop, test, and optimize applications. By having a seamless path from the development process to the deployment process, teams are able to simultaneously have strong visibility into how applications are operating in production environments while also taking advantage of the data and insights collected by the applications at edge locations.
This process will only become more important as AI models are quickly and constantly retrained and iterated on based on new data collected at edge locations.
Machine learning operations and edge AI
Machine learning operations (MLOps) is a system of processes to streamline the development, deployment, monitoring, and ongoing management of machine learning models. It allows organizations to quickly scale the development process for applications and enables rapid iterations between data science and IT teams. MLOps platforms organize that philosophy into a set of tools that can be used cross-functionally in an organization to speed up the rate of innovation.
Figure 1. The four phases of the data science lifecycle: develop, deploy, monitor, and manage
Integrating MLOps platforms and edge computing solutions allows for a seamless and rapid workflow for data scientists and IT teams to collaboratively develop and deploy applications in production environments. With a complete workflow, teams can significantly increase the rate of innovation as they constantly iterate, test, deploy, and retain based on insights and information collected at edge sites. And for organizations diligently working to capitalize on the new data paradigm, innovation is paramount.
Integrating Domino Data Lab and NVIDIA Fleet Command
The Domino Data Lab Enterprise MLOps Platform and NVIDIA Fleet Command are now integrated to provide data scientists and IT teams with a consistent, simplified flow from model development to deployment.
Domino Data Lab provides an enterprise MLOps platform that powers model-driven business to accelerate the development and deployment of data science work while increasing collaboration and governance. It allows data scientists to experiment, research, test, and validate AI models before deploying them into production.
NVIDIA Fleet Command is a managed platform for container orchestration that streamlines provisioning and deployment of systems and AI applications at the edge. It simplifies the management of distributed computing environments with the scale and resiliency of the cloud, turning every site into a secure, intelligent location.
From development to deployment
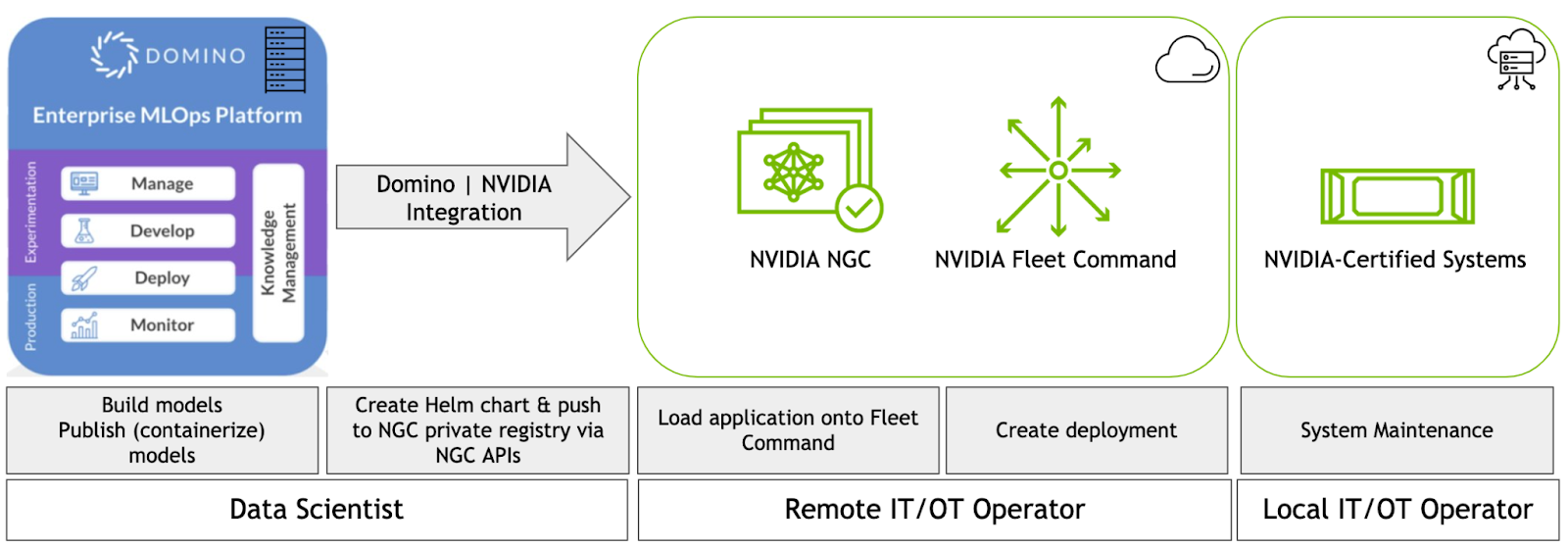
The integration with NVIDIA Fleet Command provides Domino Data Lab users an easy avenue to deploy models they are working on to edge locations. The integration bridges the gap between the data scientist team developing applications and IT teams deploying them, allowing both teams access to the entire application lifecycle.
“The integration with NVIDIA Fleet Command is the last piece in the puzzle to give data scientists access to the complete workflow for developing and deploying AI applications to the edge,” says Thomas Robinson, VP of Strategic Partnerships and Corporate Development at Domino Data Lab. “Full visibility into production deployments is critical for teams to take advantage of the data and insights generated at the edge, ultimately producing better applications faster.”
Data scientists can use the Domino Data MLOps Platform to quickly iterate on models they are working on. Through the same interface, users have the ability to load their new models onto Fleet Command, making them available to deploy to any connected location. Once deployed, administrators have remote access to the applications for monitoring and troubleshooting, providing critical feedback that can be used in the next iteration of the model.
Figure 2. Development to workflow between Domino Data Lab Enterprise MLOps Platform and NVIDIA Fleet Command
A data scientist working on a quality inspection application for a beverage manufacturing plant is one example of this integration used in production environments. The application is used to visually catch dents and defects on cans to prevent them from reaching consumers. The challenge is that the packaging on the cans changes frequently as new designs are tested, seasonal products are released, and event-based packages go to market. The application needs to be able to learn new designs quickly and frequently while still maintaining precise levels of success. This requires a high rate of innovation in order to keep up with the frequent changes in packaging. To achieve this, the data scientist uses Domino Data Lab Enterprise MLOps Platform and NVIDIA Fleet Command to create a fast and seamless flow from the development and iteration efforts to the deployment and monitoring efforts. By doing so, they are able to increase the rate of innovation by easily deploying new models with limited disruption in service as products change. Additionally, model monitoring ensures that the data scientist catches any issues with the quality or predictive power of their models.
Watch an end-to-end demo of model development, deployment, and monitoring in the oil and gas space using Domino and NVIDIA Fleet Command.
Get started with Domino on NVIDIA Fleet Command
Deploying applications on NVIDIA Fleet Command is currently available to Domino users. The Domino Enterprise MLOps Platform is also accessible on NVIDIA LaunchPad, which provides free short-term access to a catalog of hands-on labs. Quickly test AI initiatives and get practical experience with scaling data science workloads.
Join this webinar and Metropolis meetup on July 20 and 21 to learn how NVIDIA Jetson Orin and NVIDIA Launchpad boost your go-to-market efforts for vision AI applications.
Join this webinar and Metropolis meetup on July 20 and 21 to learn how NVIDIA Jetson Orin and NVIDIA Launchpad boost your go-to-market efforts for vision AI applications.
With the increasing demand for access to pretrained large language model (LLM) weights, the climate around LLM sharing is changing. Recently, Meta released Open Pretrained…
With the increasing demand for access to pretrained large language model (LLM) weights, the climate around LLM sharing is changing. Recently, Meta released Open Pretrained Transformer, a language model with 175 billion parameters. BigScience is on schedule to release its multilingual language model with 176 billion parameters in a few months.
As more LLMs become available, industries need techniques for solving real-world natural language tasks. It has been shown that model prompting methods can elicit good zero– and few-shot performance from LLMs and help yield quality results on various downstream natural language processing (NLP) tasks. The whitepaper proposed prompting as a solution to make general, pretrained LLMs practically useful in the new pretrain, prompt, and predict paradigm that is becoming increasingly popular in the NLP field.
However, when you are applying prompting methods to industrial NLP applications, there are other challenges to consider. For any downstream NLP task, you must collect labeled data to instruct the language model on how to produce the expected results.
Although for many tasks there is plenty of labeled English data, there are few benchmark-worthy, non-English, downstream datasets. Scarcity of labeled data is the number one challenge for industry to perform NLP tasks in low-resource language environments.
Furthermore, companies usually must dynamically solve multiple downstream NLP tasks that can evolve over time. Continuous learning for new tasks without forgetting previously learned tasks is still a hot research topic. A nice and clean solution means lower model maintenance, lower deployment costs, and fast development.
In this post, we show you how to adapt p-tuning, a prompt learning method, to low-resource language settings. We use an improved version of p-tuning implemented in NVIDIA NeMo that enables the continuous multitask learning of virtual prompts. In particular, we focus on adapting our English p-tuning workflow to Swedish. Learn more about how a consortium in Sweden plans to make the language model available in Nordic regions.
Our proposed workflow is generic and can easily be modified for other languages.
Why large language models?
As shown in the language model scaling law study by OpenAI, language model performance improves as the language model size increases. This has led to a race to train larger and larger language models.
NVIDIA recently trained a Megatron Turing NLG 530B model, which has superior zero– and few-shot learning performance. To access LLMs, researchers can use paid model APIs such as the ones provided by OpenAI or deploy publicly released models locally.
When you have an LLM that understands language well, you can apply prompt learning methods to make the model solve a plethora of NLP downstream tasks.
A short overview of prompt learning and p-tuning
Instead of selecting discrete text prompts in a manual or automated fashion, prompt learning uses virtual prompt embeddings that can be optimized using gradient descent. These virtual embeddings get automatically inserted among the discrete token embeddings from a text prompt.
Figure 1. Prompt engineering versus prompt learning
During prompt learning, the entire GPT model is frozen and only these virtual token embeddings are updated at each training step. The prompt learning process results in a small number of virtual token embeddings that can be combined with a text prompt to improve task performance at inference time.
In p-tuning specifically, a small long short-term memory (LSTM) model is used as a prompt encoder. The input to the prompt encoder is a task name and the outputs are task-specific virtual token embeddings that are passed into the LLM along with the text prompt embeddings.
Figure 2. How p-tuning works in the forward pass
A multitask continuous learning solution
Figure 2 shows that p-tuning uses a prompt encoder to generate virtual token embeddings. In the original p-tuning paper, the prompt encoder can only work for one task. We extended it in our NeMo implementation so that the prompt encoder can be conditioned on different tasks’ names.
When the prompt encoder is trained, it maps the task names to a set of virtual token embeddings. This enables you to build an embedding table that stores the mapping between task names and virtual token embeddings for each task. Using this embedding table enables you to continuously learn new tasks and avoid catastrophic forgetting. For example, you can start p-tuning with tasks A and B.
After training, you can save the virtual token embeddings for tasks A and B in the table and freeze them. You can proceed to train task C with another fresh prompt encoder. Similarly, after the training, you save the virtual token embeddings for task C in the prompt table. During the inference, the model can look up the prompt table and use the correct virtual token embeddings for different tasks.
Second, p-tuning requires only a few labeled data points to give reasonable results. For example, for an FIQA sentiment analysis task, it used 1,000 data examples to achieve 92% accuracy.
Third, p-tuning as described in the original paper, and even more so in our specific implementation, is extremely parameter-efficient. During p-tuning, an LSTM with parameters equal to a small fraction of the original GPT model’s parameters is tuned while the GPT model weights remain frozen. At the end of training, the LSTM network can be discarded and only the virtual prompts themselves need to be saved. This means parameters totaling less than ~0.01% of the GPT model’s size must be stored and used during inference to achieve dramatically improved task performance compared to zero– and few-shot inference.
Fourth, p-tuning is also more resource-efficient during training. Freezing the GPT model means that we didn’t have to store optimizer states for those model parameters and we didn’t have to spend time updating GPT model weights. This saved a considerable amount of GPU memory.
Lastly, the virtual prompt token parameters are decoupled from the GPT model. This yields the ability to distribute small virtual token parameter files that can be plugged into a shared access GPT model without the need for also sharing updated GPT model weights, as would be required if the GPT model were fine-tuned.
Creating Swedish downstream task datasets
To apply p-tuning to non-English downstream tasks, we labeled data in the target language. As there is an abundance of labeled English downstream task data, we used a machine translation model to translate this English labeled data into the target low-resource language. For this post, we translated our English data into Swedish. Thanks to p-tuning’s low labeled data requirements, we didn’t have to translate a lot of labeled data points.
To have complete control of the translation model, we chose to use an in-house translation model trained from scratch. This model is trained with English to Swedish/ Norwegian (one-to-many) direction using the NeMo NMT toolkit. The training data (parallel corpus) was obtained from Opus. The English to Swedish translation quality was manually evaluated by a native bilingual English and Swedish speaker.
We also used other translation models to help check the quality of our translation model. We translated a handful of random samples from the original English benchmark data and manually checked the quality of the other model translations compared with our own. We used deepL, the Google translation API, and DeepTranslator.
Apart from some clock-and-time systematic errors, the overall translation quality was good enough for us to proceed with converting the English-labeled data into Swedish. With the training and verification of our NeMo NMT English to Swedish translation model complete, we used the model to translate two English benchmark datasets:
For convenience, we use svFIQA and svAssistant to distinguish between the original English and the translated Swedish benchmark datasets.
Here are randomly selected examples of training records from FIQA and svFIQA, respectively:
English:
{"taskname": "sentiment-task", "sentence": "Barclays PLC & Lloyds Banking Group PLC Are The 2 Banks I'd Buy Today. Sentiment for Lloyds ", "label": "positive"}
Swedish:
{"taskname": "sentiment-task", "sentence": "Barclays PLC & Lloyds Banking Group PLC är de 2 banker jag skulle köpa idag.. Känslor för Lloyds", "label": "positiva"}
The translated dataset should preserve the correct grammar structure of the actual English source data. Because the sentiment refers to the two banks, it’s plural. The ground truth label translated to Swedish should also reflect the correct Swedish grammar, that is, ‘’positiva’’.
For completeness, we also randomly selected one example each from Assistant and svAssistant:
English:
{"taskname": "intent_and_slot", "utterance": "will you please get the coffee machine to make some coffee", "label": "nIntent: iot_coffeenSlots: device_type(coffee machine)"}
Swedish:
{"taskname": "intent_and_slot", "utterance": "kommer du snälla få kaffemaskinen för att göra lite kaffe", "label": "Intent: iot _ kaffe Slots: enhet _ typ (kaffemaskin)"}
GPT models
The Swedish GPT-SW3 checkpoints used in the following experiments were a result of a partnership between AI Sweden and NVIDIA. More specifically, AI Sweden’s GPT-SW3 checkpoint with 3.6 billion parameters is pretrained using Megatron-LM. This model was used to conduct the Swedish multitask p-tuning experiments described in this post.
Multitask p-tuning experiments
To simulate the typical enterprise customer use case, we imagined a scenario where a user first needs to solve a sentiment analysis NLP task with high accuracy. Later, as the business evolves, the user needs to continue to solve a virtual assistant task with the same model to reduce cost.
We ran p-tuning twice in a continuous learning setup for Swedish. We used the svFIQA dataset for the first NLP task. We then used the svAssistant dataset for the second NLP task.
We could have p-tuned both tasks simultaneously. However, we choose to do two rounds of p-tuning consecutively to showcase the continuous prompt learning capability in NeMo.
We first conducted a series of short hyperparameter tuning experiments for svFIQA and svAssistant using a slightly modified version of this p-tuning tutorial notebook. In these experiments, we identified the optimal number of virtual tokens and best virtual token placements for each task.
To manipulate the total number of virtual tokens and their positions within a text prompt, we modified the following sentiment task template within the p-tuning model’s training config file. For more information about the p-tuning configuration file, see the prompt learning config section of our NeMo documentation.
This prompt template is language-specific. Apart from the virtual tokens’ placement and the number of virtual tokens used, it is important to translate the words within each prompt template into the target language. Here, the term “sentiment” (added between the final virtual prompt tokens and the label) should be translated into Swedish.
In our experiments, we used 10-fold cross-validation to calculate performance metrics. During our hyperparameter search, we p-tuned the Swedish GPT-SW3 model on the first fold until the validation loss plateaued after 10-20 epochs.
After a few rounds of experimentation in this manner, we decided to use the following template for all 10 folds of the svFIQA dataset:
The term “sentiment” was removed from the prompt template and was instead directly included in the {sentence} part of the prompt. This allowed us to easily translate “sentiment” into Swedish along with the rest of the English sentence:
{"taskname": "sentiment-task", "sentence": "Barclays PLC & Lloyds Banking Group PLC är de 2 banker jag skulle köpa idag.. Känslor för Lloyds", "label": "positiva"}
After finding an optimal configuration for training, we p-tuned our Swedish GPT-SW3 model on each of the 10 svFIQA folds. We evaluated the p-tuned checkpoint for every fold on its corresponding test split. We added intent and slot prediction capability to our GPT-SW3 model by repeating the same steps with the svAssistant dataset, this time restoring our checkpoints trained on svFIQA and adding the intent and slot task.
Results
To establish a baseline, and because there are no existing benchmarks for Swedish in this context, we used the original AI Sweden GPT-SW3 model’s zero–, one–, and few-shot learning performance as the baseline (Figure 3).
Figure 3. Zero-, one-, and few-shot learning performance obtained through the GPT-SW3 model
As can be seen, except for zero-shot, the few-shot learning performance on svFIQA is 42-52%. Understandably, the performance of zero-shot is significantly worse due to the fact that the GPT model receives zero labeled examples. The model generates tokens that are most likely unrelated to the given task.
Given the binary nature of this sentiment analysis task, we mapped all Swedish grammatical variants of the words “positiv” and “negativ” to the same format before calculating task accuracy.
Table 1. First round of p-tuning performance on svFIQA 10 folds average accuracy
With this re-mapping mechanism, we achieved fairly good results: 82.65%. The p-tuning performance on the svFIQA test is averaged across all 10 folds.
Table 2 shows the results for the second round of p-tuning on the svAssistant dataset (intent and slot classification). Scores are averaged across all 10 folds as well.
Precision
Recall
F1 -Score
average
88.00%
65.00%
73.00%
Table 2. Second round of p-tuning performance on the svAssistant dataset
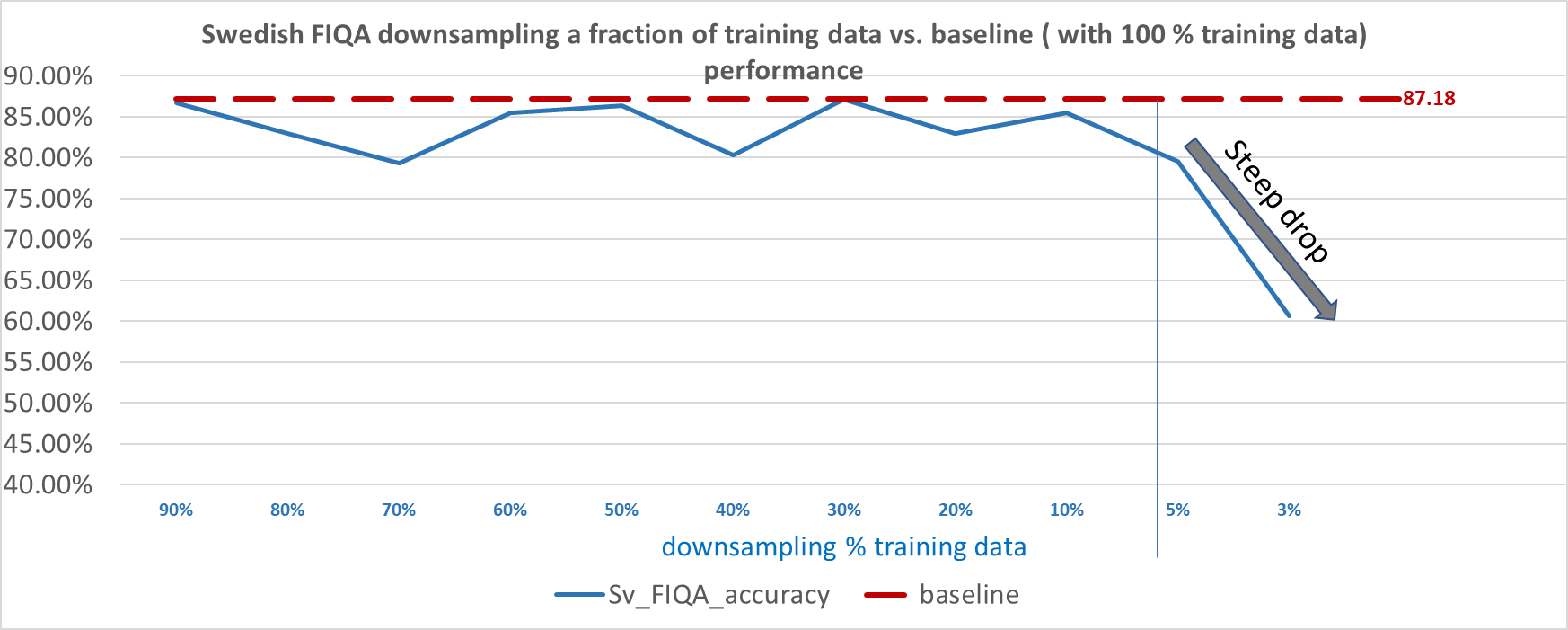
Next, we further explored the question, “How much can we reduce the total amount of training data without decreasing performance?”
For the svFIQA dataset, we discovered that we can get away with as little as one-tenth of the training data in each training run and still maintain acceptable performance. However, from 5% training data onwards (with only 47 data points for training), we started to see steep degradation of performance and the performance became unstable at around 1% (as little as nine data points for training, averaged across six training runs, each with nine randomly sampled data points).
Figure 4. Reduced on-training data versus the performance on the svFIQA dataset
Future work
We noticed that the results for intent and slot classification can be improved. They are heavily dependent on the translation model’s ability to translate non-natural text from English to Swedish. In the following example, the English intent and slot prompt formatting were difficult for the translation model to translate accurately, compromising the quality of the Swedish translations.
The label for English is “Intent: alarm_set Slots: date(sunday), time (eight am)”.
When it is translated to Swedish, it became “tid (åtta am)”.
The translation model skipped the words “Intent:” and “Slot:” completely. It also dropped the translation for alarm_set in the intent as well as date(sunday) in the slot.
In the future, we will formulate source language data as natural language before translating it into the target language. We are also experimenting with a pretrained mT5 model that can skip the translation steps completely. The early results are promising, so stay tuned for the full results.
Lastly, we also plan to compare prompt learning methods against full fine-tuning of the base GPT models. This will enable us to compare trade-offs between the two task adaptation approaches.
Conclusion
In this post, we demonstrated a parameter-efficient solution to solving multiple NLP tasks in a low-resource language setting. Focusing on the Swedish language, we translated English sentiment classification and intent/slot classification datasets into Swedish. We then p-tuned the Swedish GPT-SW3 model on these datasets and achieved good performance compared to our few-shot learning baselines.
We showed that our approach can help you train the prompt encoder with as little as one-tenth of the original training data tuning less than 0.1% of the model’s original parameters, while still maintaining performance.
Because the LLM is frozen during training, p-tuning requires fewer resources and the whole training process can be done efficiently and quickly, which democratizes LLM access for anyone. You can bring your own data and tune the model for your own use cases.
In our NeMo p-tuning implementation, we make lightweight, continuous learning easy as well. You can use our approach to continuously learn and deploy new tasks without degrading the performance of previously added tasks.
Tourer vehicles just became a little more grand. Electric vehicle maker Human Horizons provided a detailed glimpse earlier this month of its latest production model: the GT HiPhi Z. The intelligent EV is poised to redefine the grand tourer vehicle category with innovative, software-defined capabilities that bring luxurious cruising to the next level. The vehicle’s Read article >
NVIDIA today announced a unified computing platform for speeding breakthroughs in quantum research and development across AI, HPC, health, finance and other disciplines.
Kristel Michielsen was into quantum computing before quantum computing was cool. The computational physicist simulated quantum computers as part of her Ph.D. work in the Netherlands in the early 1990s. Today, she manages one of Europe’s largest facilities for quantum computing, the Jülich Unified Infrastructure for Quantum Computing (JUNIQ) . Her mission is to help Read article >
NVIDIA introduces QODA, a new platform for hybrid quantum-classical computing, enabling easy programming of integrated CPU, GPU, and QPU systems.
The past decade has seen quantum computing leap out of academic labs into the mainstream. Efforts to build better quantum computers proliferate at both startups and large companies. And while it is still unclear how far we are away from using quantum advantage on common problems, it is clear that now is the time to build the tools needed to deliver valuable quantum applications.
To start, we need to make progress in our understanding of quantum algorithms. Last year, NVIDIA announced cuQuantum, a software development kit (SDK) for accelerating simulations of quantum computing. Simulating quantum circuits using cuQuantum on GPUs enables algorithms research with performance and scale far beyond what can be achieved on quantum processing units (QPUs) today. This is paving the way for breakthroughs in understanding how to make the most of quantum computers.
In addition to improving quantum algorithms, we also need to use QPUs to their fullest potential alongside classical computing resources: CPUs and GPUs. Today, NVIDIA is announcing the launch of Quantum Optimized Device Architecture (QODA), a platform for hybrid quantum-classical computing with the mission of enabling this utility.
As quantum computing progresses, all valuable quantum applications will be hybrid, with the quantum computer working alongside high-performance classical computing. GPUs, which were created purely for graphics, transformed into essential hardware for high-performance computing (HPC). This required new software to enable powerful and straightforward programming. The transformation of quantum computers from science experiments to useful accelerators also requires new software.
This new era of quantum software will enable performant hybrid computation and increase the accessibility of quantum computers for the broader group of scientists and innovators.
Figure 1. NVIDIA QODA is the world’s first platform for hybrid quantum-classical computing with applications spanning drug discovery, chemistry, weather, finance, logistics, and more
Quantum programming landscape
The last five years have seen the development of quantum programming approaches targeting small-scale, noisy quantum computing architectures. This development has been great for algorithm developers and enabled early prototyping of both standard quantum algorithms as well as hybrid variational approaches.
Due to the scarcity of quantum resources and practicalities of hardware implementations, most of these programming approaches have been at the pure Python level supporting a remote, cloud-based execution model.
As quantum architectures improve and algorithm developers consider true quantum acceleration of existing classical heterogeneous computing, the question arises: How should we support quantum coprocessing in the traditional HPC context?
NVIDIA has been a true pioneer in the development of HPC programming models, heterogeneous compiler platforms, and high-level application libraries that accelerate traditional scientific computing workflows with one or many NVIDIA GPUs.
We see quantum computing as another element of a heterogeneous HPC system architecture and envision a programming model that seamlessly incorporates quantum coprocessing into our existing CUDA ecosystem. Current approaches that start at the Python language level are not sufficient in this regard and will ultimately limit performant integration of classical and quantum compute resources.
QODA for HPC
NVIDIA is developing an open specification for programming hybrid quantum-classical compute architectures in an HPC context. We are announcing the QODA programming model specification and corresponding NVQ++ compiler platform enabling a backend-agnostic (physical, simulated), single-source, modern C++ approach to quantum-accelerated high-performance computing.
QODA is inherently interoperable with existing classical parallel programming models such as CUDA, OpenMP, and OpenACC. This compiler implementation also lowers quantum-classical C++ source code representations to binary executables that natively target cuQuantum-enabled simulation backends.
This programming and compilation workflow enables a performant programming environment for accelerating hybrid algorithm research and development activities through standard interoperability with GPU processing and circuit simulation that scales from laptops to distributed multi-node, multi-GPU architectures.
auto ghz = [](const int N) __qpu__ {
qoda::qreg q(N);
h(q[0]);
for (auto i : qoda::irange(N-1)) {
cnot(q[i], q[i+1]);
}
mz(q);
};
// Sample a GHZ state on 30 qubits
auto counts = qoda::sample(ghz, 30);
counts.dump();
As shown in the code example, QODA provides a CUDA-like kernel-based programming approach, with a modern C++ focus. You can define quantum device code as standalone function objects or lambdas annotated with __qpu__ to indicate that this is to be compiled to and executed on the quantum device.
By relying on function objects over free functions (the CUDA kernel approach), you can enable an efficient approach to building up generic standard quantum library functions that can take any quantum kernel expression as input.
One simple example of this is the standard sampling QODA function (qoda::sample(...)), which takes a quantum kernel instance and any concrete arguments for which the kernel is to be evaluated as the input, and returns the familiar mapping of observed qubit measurement bit strings to the corresponding number of times observed.
QODA kernel programmers have access to certain built-in types pertinent for quantum computing (qoda::qubit, qoda::qreg, qoda::spin_op, and so on), quantum gate operations, and all traditional classical control flow inherited from C++.
An interesting aspect of the language compilation approach detailed earlier is the ability to compile QODA codes that contain CUDA kernels, OpenMP and OpenACC pragmas, and higher-level CUDA library API calls. This feature will enable hybrid quantum-classical application developers to truly take advantage of multi-GPU processing in tandem with quantum computing.
Future quantum computing use cases will require classical parallel processing for things like data preprocessing and postprocessing, standard quantum compilation tasks, and syndrome decoding for quantum error correction.
An early look at quantum-classical applications
A prototypical hybrid quantum-classical algorithm targeting noisy, near-term quantum computing architectures is the variational quantum eigensolver (VQE). The goal for VQE is to compute the minimum eigenvalue for a given quantum mechanical operator, such as a Hamiltonian, with respect to a parameterized state preparation circuit by relying on the variational principle from quantum mechanics.
You execute the state preparation circuit for a given set of gate rotational parameters and perform a set of measurements dictated by the structure of the quantum mechanical operator to compute the expectation value at those concrete parameters. A user-specified classical optimizer is then used to iteratively search for the minimal expectation value by varying these parameters.
You can see what a general VQE-like algorithm looks like with the QODA programming model:
// Define your state prep ansatz…
auto ansatz = [](std::vector thetas) __qpu__ {
… Use C++ control flow and quantum intrinsic ops …
};
// Define the Hamiltonian
qoda::spin_op H = … use x, y, z to build up Hamiltonian … ;
// Create a specific function optimization strategy
int n_params = …;
qoda::nlopt::lbfgs optimizer;
optimizer.initial_parameters = qoda::random_vector(-1, 1, n_params);
// Run the VQE algorithm with QODA
auto [opt_val, opt_params] =
qoda::vqe(ansatz, H, optimizer, n_params);
printf("Optimal = %lfn", opt_val);
The main components required are the parameterized ansatz QODA kernel expression, shown in the code example as a lambda taking a std::vector.
The actual body of this lambda is dependent on the problem at hand, but you are free to build up this function with standard C++ control flow, in-scope quantum kernel invocations, and the logical set of quantum intrinsic operations.
The next component required is the operator whose expectation value you need for calculating. QODA represents these as the built-in spin_op type, and you can build these up programmatically with Pauli x(int), y(int), and z(int) function calls.
Next, you need a classical function optimizer, which is a general concept within the QODA language specification meant for subclassing to specific optimization strategies, either gradient-based or gradient-free.
Finally, the language exposes a standard library function for invoking the entire VQE workflow. It is parameterized on the QODA kernel instance modeling the state preparation ansatz, the operator for which you need the following values:
The minimal eigenvalue
The classical optimization instance
The total number of variational parameters
You are then returned a structured binding that encodes the optimal eigenvalue and the corresponding optimal parameters for the state preparation circuit.
The preceding workflow is extremely general and lends itself to the development of variational algorithms that are ultimately generic with respect to quantum kernel expressions, spin operators of interest, and classical optimization routines.
But it also demonstrates the underlying philosophy of the QODA programming model: To provide core concepts to describe quantum code expressions, and then promote the utility of a standard library of generic functions enabling hybrid quantum-classical algorithmic composability.
QODA Early Interest program
Quantum computers hold great promise to help us solve some of our most important problems. We’re opening up quantum computing to scientists and experts in domains where HPC and AI already play a critical role, as well as enabling easy integration of today’s best existing software with quantum software. This will dramatically accelerate quantum computers realizing their potential.
QODA provides an open platform to do just that, and NVIDIA is excited to work with the entire quantum community to make useful quantum computing a reality. Apply to the QODA Early Interest program to stay up-to-date on NVIDIA quantum computing developments.
Posted by Qihang Yu, Student Researcher, and Liang-Chieh Chen, Research Scientist, Google Research
Panoptic segmentation is a computer vision problem that serves as a core task for many real-world applications. Due to its complexity, previous work often divides panoptic segmentation into semantic segmentation (assigning semantic labels, such as “person” and “sky”, to every pixel in an image) and instance segmentation (identifying and segmenting only countable objects, such as “pedestrians” and “cars”, in an image), and further divides it into several sub-tasks. Each sub-task is processed individually, and extra modules are applied to merge the results from each sub-task stage. This process is not only complex, but it also introduces many hand-designed priors when processing sub-tasks and when combining the results from different sub-task stages.
Recently, inspired by Transformer and DETR, an end-to-end solution for panoptic segmentation with mask transformers (an extension of the Transformer architecture that is used to generate segmentation masks) was proposed in MaX-DeepLab. This solution adopts a pixel path (consisting of either convolutional neural networks or vision transformers) to extract pixel features, a memory path (consisting of transformer decoder modules) to extract memory features, and a dual-path transformer for interaction between pixel features and memory features. However, the dual-path transformer, which utilizes cross-attention, was originally designed for language tasks, where the input sequence consists of dozens or hundreds of words. Nonetheless, when it comes to vision tasks, specifically segmentation problems, the input sequence consists of tens of thousands of pixels, which not only indicates a much larger magnitude of input scale, but also represents a lower-level embedding compared to language words.
In “CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation”, presented at CVPR 2022, and “kMaX-DeepLab: k-means Mask Transformer”, to be presented at ECCV 2022, we propose to reinterpret and redesign cross-attention from a clustering perspective (i.e., grouping pixels with the same semantic labels together), which better adapts to vision tasks. CMT-DeepLab is built upon the previous state-of-the-art method, MaX-DeepLab, and employs a pixel clustering approach to perform cross-attention, leading to a more dense and plausible attention map. kMaX-DeepLab further redesigns cross-attention to be more like a k-means clustering algorithm, with a simple change on the activation function. We demonstrate that CMT-DeepLab achieves significant performance improvements, while kMaX-DeepLab not only simplifies the modification but also further pushes the state-of-the-art by a large margin, without test-time augmentation. We are also excited to announce the open-source release of kMaX-DeepLab, our best performing segmentation model, in the DeepLab2 library.
Overview Instead of directly applying cross-attention to vision tasks without modifications, we propose to reinterpret it from a clustering perspective. Specifically, we note that the mask Transformer object query can be considered cluster centers (which aim to group pixels with the same semantic labels), and the process of cross-attention is similar to the k-means clustering algorithm, which adopts an iterative process of (1) assigning pixels to cluster centers, where multiple pixels can be assigned to a single cluster center, and some cluster centers may have no assigned pixels, and (2) updating the cluster centers by averaging pixels assigned to the same cluster center, the cluster centers will not be updated if no pixel is assigned to them).
In CMT-DeepLab and kMaX-DeepLab, we reformulate the cross-attention from the clustering perspective, which consists of iterative cluster-assignment and cluster-update steps.
Given the popularity of the k-means clustering algorithm, in CMT-DeepLab we redesign cross-attention so that the spatial-wise softmax operation (i.e., the softmax operation that is applied along the image spatial resolution) that in effect assigns cluster centers to pixels is instead applied along the cluster centers. In kMaX-DeepLab, we further simplify the spatial-wise softmax to cluster-wise argmax (i.e., applying the argmax operation along the cluster centers). We note that the argmax operation is the same as the hard assignment (i.e., a pixel is assigned to only one cluster) used in the k-means clustering algorithm.
Reformulating the cross-attention of the mask transformer from the clustering perspective significantly improves the segmentation performance and simplifies the complex mask transformer pipeline to be more interpretable. First, pixel features are extracted from the input image with an encoder-decoder structure. Then, a set of cluster centers are used to group pixels, which are further updated based on the clustering assignments. Finally, the clustering assignment and update steps are iteratively performed, with the last assignment directly serving as segmentation predictions.
To convert a typical mask Transformer decoder (consisting of cross-attention, multi-head self-attention, and a feed-forward network) into our proposed k-means cross-attention, we simply replace the spatial-wise softmax with cluster-wise argmax.
The meta architecture of our proposed kMaX-DeepLab consists of three components: pixel encoder, enhanced pixel decoder, and kMaX decoder. The pixel encoder is any network backbone, used to extract image features. The enhanced pixel decoder includes transformer encoders to enhance the pixel features, and upsampling layers to generate higher resolution features. The series of kMaX decoders transform cluster centers into (1) mask embedding vectors, which multiply with the pixel features to generate the predicted masks, and (2) class predictions for each mask.
The meta architecture of kMaX-DeepLab.
Results We evaluate the CMT-DeepLab and kMaX-DeepLab using the panoptic quality (PQ) metric on two of the most challenging panoptic segmentation datasets, COCO and Cityscapes, against MaX-DeepLab and other state-of-the-art methods. CMT-DeepLab achieves significant performance improvement, while kMaX-DeepLab not only simplifies the modification but also further pushes the state-of-the-art by a large margin, with 58.0% PQ on COCO val set, and 68.4% PQ, 44.0% mask Average Precision (mask AP), 83.5% mean Intersection-over-Union (mIoU) on Cityscapes val set, without test-time augmentation or using an external dataset.
Designed from a clustering perspective, kMaX-DeepLab not only has a higher performance but also a more plausible visualization of the attention map to understand its working mechanism. In the example below, kMaX-DeepLab iteratively performs clustering assignments and updates, which gradually improves mask quality.
kMaX-DeepLab’s attention map can be directly visualized as a panoptic segmentation, which gives better plausibility for the model working mechanism (image credit: coco_url, and license).
Conclusions We have demonstrated a way to better design mask transformers for vision tasks. With simple modifications, CMT-DeepLab and kMaX-DeepLab reformulate cross-attention to be more like a clustering algorithm. As a result, the proposed models achieve state-of-the-art performance on the challenging COCO and Cityscapes datasets. We hope that the open-source release of kMaX-DeepLab in the DeepLab2 library will facilitate future research on designing vision-specific transformer architectures.
Acknowledgements We are thankful to the valuable discussion and support from Huiyu Wang, Dahun Kim, Siyuan Qiao, Maxwell Collins, Yukun Zhu, Florian Schroff, Hartwig Adam, and Alan Yuille.

 Join this digital conference from August 2-4 to learn how science is being advanced through the work done at Open Hackathons or accelerated using OpenACC.
Join this digital conference from August 2-4 to learn how science is being advanced through the work done at Open Hackathons or accelerated using OpenACC. A new approach to data The convergence of AI and IoT has shifted the center of gravity for data away from the cloud and to the edge of the network. In retail stores, factories,…
A new approach to data The convergence of AI and IoT has shifted the center of gravity for data away from the cloud and to the edge of the network. In retail stores, factories,…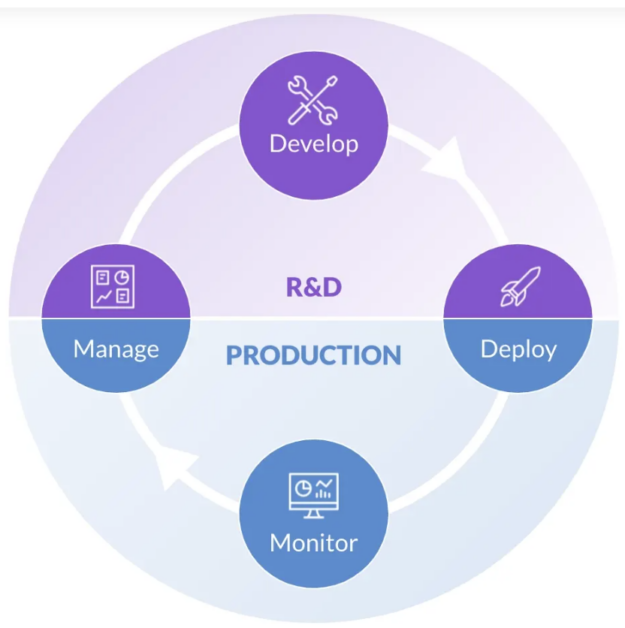
 Join this webinar and Metropolis meetup on July 20 and 21 to learn how NVIDIA Jetson Orin and NVIDIA Launchpad boost your go-to-market efforts for vision AI applications.
Join this webinar and Metropolis meetup on July 20 and 21 to learn how NVIDIA Jetson Orin and NVIDIA Launchpad boost your go-to-market efforts for vision AI applications. With the increasing demand for access to pretrained large language model (LLM) weights, the climate around LLM sharing is changing. Recently, Meta released Open Pretrained…
With the increasing demand for access to pretrained large language model (LLM) weights, the climate around LLM sharing is changing. Recently, Meta released Open Pretrained…


 Learn how to use NVIDIA developer tools, Nsight Systems, and Nsight Compute to optimize CUDA applications in this new course from DLI.
Learn how to use NVIDIA developer tools, Nsight Systems, and Nsight Compute to optimize CUDA applications in this new course from DLI. NVIDIA introduces QODA, a new platform for hybrid quantum-classical computing, enabling easy programming of integrated CPU, GPU, and QPU systems.
NVIDIA introduces QODA, a new platform for hybrid quantum-classical computing, enabling easy programming of integrated CPU, GPU, and QPU systems. 





{kind=link}