
Video is an ubiquitous source of media content that touches on many aspects of people’s day-to-day lives. Increasingly, real-world video applications, such as video captioning, video content analysis, and video question-answering (VideoQA), rely on models that can connect video content with text or natural language. VideoQA is particularly challenging, however, as it requires grasping both semantic information, such as objects in a scene, as well as temporal information, e.g., how things move and interact, both of which must be taken in the context of a natural-language question that holds specific intent. In addition, because videos have many frames, processing all of them to learn spatio-temporal information can be computationally expensive. Nonetheless, understanding all this information enables models to answer complex questions — for example, in the video below, a question about the second ingredient poured in the bowl requires identifying objects (the ingredients), actions (pouring), and temporal ordering (second).
 |
| An example input question for the VideoQA task “What is the second ingredient poured into the bowl?” which requires deeper understanding of both the visual and text inputs. The video is an example from the 50 Salads dataset, used under the Creative Commons license. |
To address this, in “Video Question Answering with Iterative Video-Text Co-Tokenization”, we introduce a new approach to video-text learning called iterative co-tokenization, which is able to efficiently fuse spatial, temporal and language information for VideoQA. This approach is multi-stream, processing different scale videos with independent backbone models for each to produce video representations that capture different features, e.g., those of high spatial resolution or long temporal durations. The model then applies the co-tokenization module to learn efficient representations from fusing the video streams with the text. This model is highly efficient, using only 67 giga-FLOPs (GFLOPs), which is at least 50% fewer than previous approaches, while giving better performance than alternative state-of-the-art models.
Video-Text Iterative Co-tokenization
The main goal of the model is to produce features from both videos and text (i.e., the user question), jointly allowing their corresponding inputs to interact. A second goal is to do so in an efficient manner, which is highly important for videos since they contain tens to hundreds of frames as input.
The model learns to tokenize the joint video-language inputs into a smaller set of tokens that jointly and efficiently represent both modalities. When tokenizing, we use both modalities to produce a joint compact representation, which is fed to a transformer layer to produce the next level representation. A challenge here, which is also typical in cross-modal learning, is that often the video frame does not correspond directly to the associated text. We address this by adding two learnable linear layers which unify the visual and text feature dimensions before tokenization. This way we enable both video and text to condition how video tokens are learned.
Moreover, a single tokenization step does not allow for further interaction between the two modalities. For that, we use this new feature representation to interact with the video input features and produce another set of tokenized features, which are then fed into the next transformer layer. This iterative process allows the creation of new features, or tokens, which represent a continual refinement of the joint representation from both modalities. At the last step the features are input to a decoder that generates the text output.
As customarily done for VideoQA, we pre-train the model before fine-tuning it on the individual VideoQA datasets. In this work we use the videos automatically annotated with text based on speech recognition, using the HowTo100M dataset instead of pre-training on a large VideoQA dataset. This weaker pre-training data still enables our model to learn video-text features.
 |
| Visualization of the video-text iterative co-tokenization approach. Multi-stream video inputs, which are versions of the same video input (e.g., a high resolution, low frame-rate video and a low resolution, high frame-rate video), are efficiently fused together with the text input to produce a text-based answer by the decoder. Instead of processing the inputs directly, the video-text iterative co-tokenization model learns a reduced number of useful tokens from the fused video-language inputs. This process is done iteratively, allowing the current feature tokenization to affect the selection of tokens at the next iteration, thus refining the selection. |
Efficient Video Question-Answering
We apply the video-language iterative co-tokenization algorithm to three main VideoQA benchmarks, MSRVTT-QA, MSVD-QA and IVQA, and demonstrate that this approach achieves better results than other state-of-the-art models, while having a modest size. Furthermore, iterative co-tokenization learning yields significant compute savings for video-text learning tasks. The method uses only 67 giga-FLOPs (GFLOPS), which is one sixth the 360 GFLOPS needed when using the popular 3D-ResNet video model jointly with text and is more than twice as efficient as the X3D model. This is all the while producing highly accurate results, outperforming state-of-the-art methods.
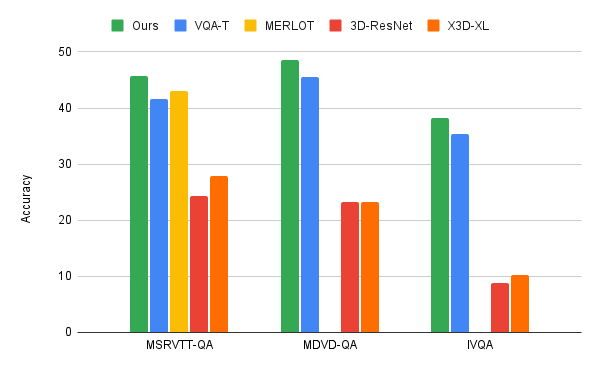 |
| Comparison of our iterative co-tokenization approach to previous methods such as MERLOT and VQA-T, as well as, baselines using single ResNet-3D or X3D-XL. |
Multi-stream Video Inputs
For VideoQA, or any of a number of other tasks that involve video inputs, we find that multi-stream input is important to more accurately answer questions about both spatial and temporal relationships. Our approach utilizes three video streams at different resolutions and frame-rates: a low-resolution high frame-rate, input video stream (with 32 frames-per-second and spatial resolution 64×64, which we denote as 32x64x64); a high-resolution, low frame-rate video (8x224x224); and one in-between (16x112x112). Despite the apparently more voluminous information to process with three streams, we obtain very efficient models due to the iterative co-tokenization approach. At the same time these additional streams allow extraction of the most pertinent information. For example, as shown in the figure below, questions related to a specific activity in time will produce higher activations in the smaller resolution but high frame-rate video input, whereas questions related to the general activity can be answered from the high resolution input with very few frames. Another benefit of this algorithm is that the tokenization changes depending on the questions asked.
 |
| Visualization of the attention maps learned per layer during the video-text co-tokenization. The attention maps differ depending on the question asked for the same video. For example, if the question is related to the general activity (e.g., surfing in the figure above), then the attention maps of the higher resolution low frame-rate inputs are more active and seem to consider more global information. Whereas if the question is more specific, e.g., asking about what happens after an event, the feature maps are more localized and tend to be active in the high frame-rate video input. Furthermore, we see that the low-resolution, high-frame rate video inputs provide more information related to activities in the video. |
Conclusion
We present a new approach to video-language learning that focuses on joint learning across video-text modalities. We address the important and challenging task of video question-answering. Our approach is both highly efficient and accurate, outperforming current state-of-the-art models, despite being more efficient. Our approach results in modest model sizes and can gain further improvements with larger models and data. We hope this work provokes more research in vision-language learning to enable more seamless interaction with vision-based media.
Acknowledgements
This work is conducted by AJ Pierviovanni, Kairo Morton, Weicheng Kuo, Michael Ryoo and Anelia Angelova. We thank our collaborators in this research, and Soravit Changpinyo for valuable comments and suggestions, and Claire Cui for suggestions and support. We also thank Tom Small for visualizations.