
 Unlocking the full potential of artificial intelligence (AI) in financial services is often hindered by the inability to ensure data privacy during machine…
Unlocking the full potential of artificial intelligence (AI) in financial services is often hindered by the inability to ensure data privacy during machine…
Unlocking the full potential of artificial intelligence (AI) in financial services is often hindered by the inability to ensure data privacy during machine learning (ML). For instance, traditional ML methods assume all data can be moved to a central repository.
This is an unrealistic assumption when dealing with data sovereignty and security considerations or sensitive data like personally identifiable information. More practically, it ignores data egress challenges and the considerable cost of creating large pooled datasets.
Massive internal datasets that would be valuable for training ML models remain unused. How can companies in the financial services industry leverage their own data while ensuring privacy and security?
This post introduces federated learning and explains its benefits for businesses handling sensitive datasets. We present three ways federated learning can be used in financial services and provide tips on getting started today.
What is federated learning
Federated learning is a ML technique that enables the extraction of insights from multiple isolated datasets—without needing to share or move that data into a central repository or server.
For example, assume you have multiple datasets you want to use to train an AI model. Today’s standard ML approach requires first gathering all the training data in one place. However, this approach is not feasible for much of the world’s data that is sensitive. This leaves many datasets and use-cases off-limits for applying AI techniques.
On the other hand, federated learning does not assume that one unified dataset can be created. The distributed training datasets are instead left where they are.
The approach involves creating multiple versions of the model and sending one to each server or device where the datasets live. Each site trains the model locally on its subset of the data, and then sends only the model parameters back to a central server. This is the key feature of federated learning: only the model updates or parameters are shared, not the training data itself. This preserves data privacy and sovereignty.
Finally, the central server collects all the updates from each site and intelligently aggregates the “mini-models” into one global model. This global model can capture the insights from the entire dataset, even when actual data cannot be combined.
Note that these local sites could be servers, edge devices like smartphones, or any machine that can train locally and send back the model updates to the central server.
Advantages of privacy-preserving technology
Large-scale collaborations in healthcare have demonstrated the real-world viability of using federated learning for multiple independent parties to jointly train an AI model. However, federated learning is not just about collaborating with external partners.
In financial institutions, we see an incredible opportunity for federated learning to bridge internal data silos. Company-wide ROI can increase as businesses gather all viable data for new products, including recommender systems, fraud detection systems, and call center analytics.
Privacy concerns, however, aren’t limited to financial data. The wave of data privacy legislation being enacted worldwide today (starting with GDPR in Europe and CCPA in California, with many similar laws coming soon) will only accelerate the need for privacy-preserving ML techniques in all industries.
Expect federated learning to become an essential part of the AI toolset in the years ahead.
Practical business use cases
ML algorithms are hungry for data. Furthermore, the real-world performance of your ML model depends not only on the amount of data but also the relevance of the training data.
Many organizations could improve current AI models by incorporating new datasets that cannot be easily accessed without sacrificing privacy. This is where federated learning comes in.
Federated learning enables companies to leverage new data resources without requiring data sharing.
Broadly, three types of use cases are enabled by federated learning:
- Intra-company: Bridging internal data silos
- Inter-company: Facilitating collaboration between organizations
- Edge computing: Learning across thousands of edge devices
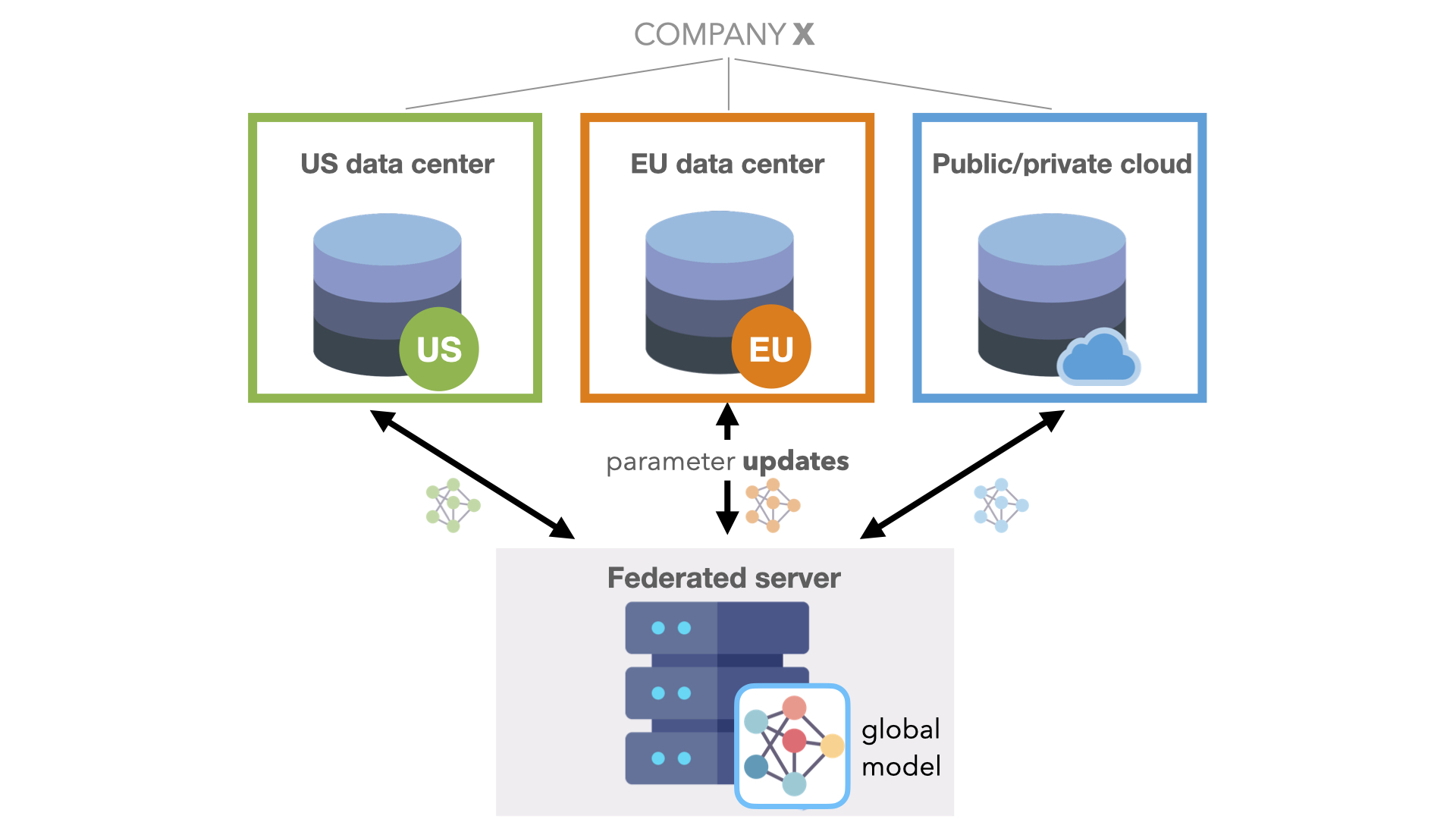
Intra-company use case: Leverage siloed internal data
There are many reasons a single company might rely on multiple data storage solutions. For example:
- Data governance rules such as GDPR may require that data be kept in specific geolocations and specify retention and privacy policies.
- Mergers and acquisitions come with new data from the partner company. Still, the arduous task of integrating that data into existing storage systems often leaves the data dispersed for long periods.
- Both on-premise and hybrid cloud storage solutions are used, and there is a high cost of moving large amounts of data.
Federated learning enables your company to leverage ML across isolated datasets in different business organizations, geographic regions, or data warehouses while preserving privacy and security.
Inter-company use case: Collaborate with external partners
Gathering enough quantitative data to build powerful AI models is difficult for a single company. Consider an insurance company building an effective fraud detection system. The company can only collect data from observed events such as customers filing a claim. Yet, this data may not be representative of the entire population and can therefore potentially contribute to AI model bias.
To build an effective fraud detection system, the company needs larger datasets with more diverse data points to train robust, generalizable models. Many organizations can benefit from pooling data with others. Practically, most organizations will not share their proprietary datasets on a common supercomputer or cloud server.
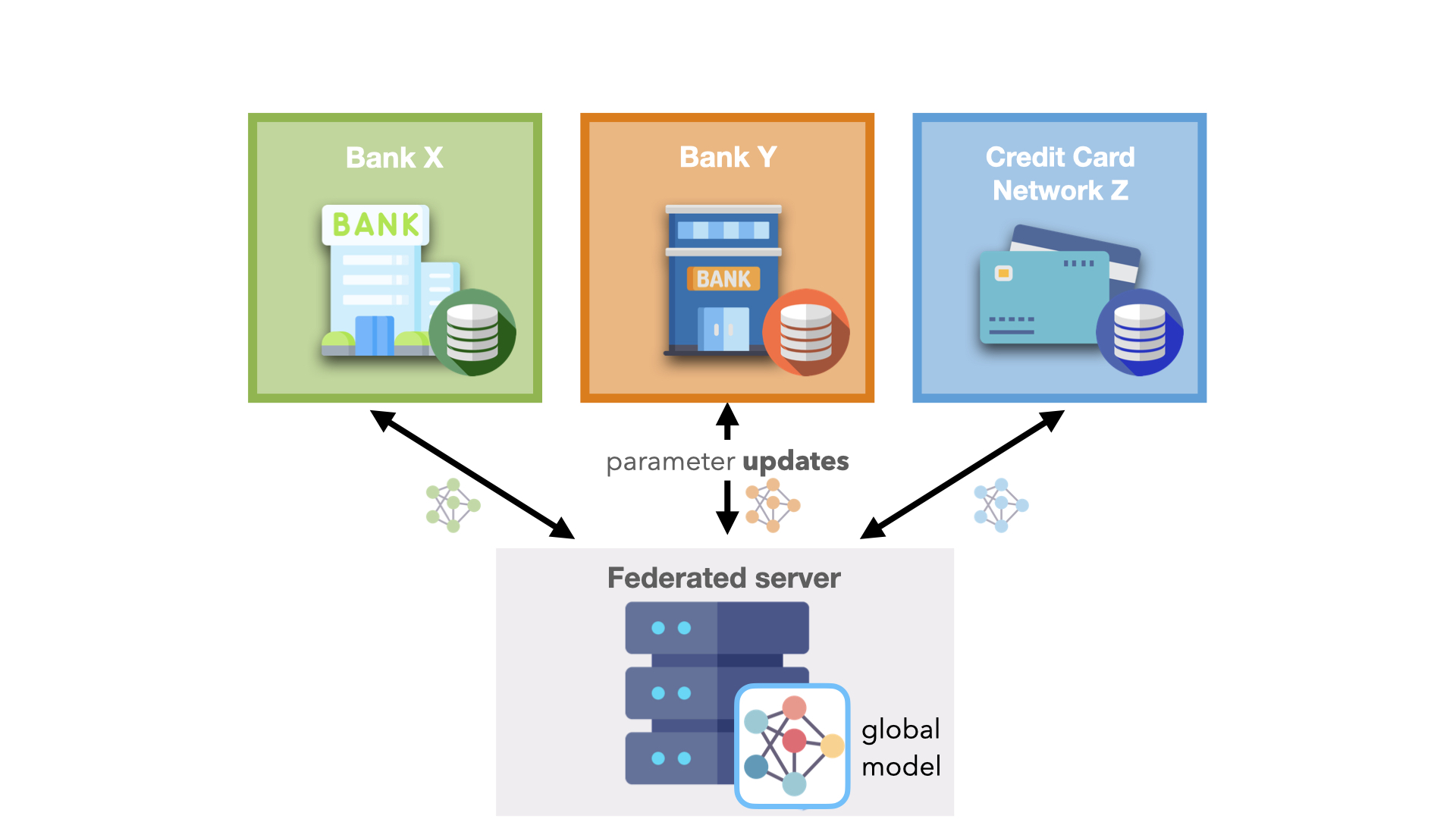
Enabling this type of collaboration for industry-wide challenges could bring massive benefits.
For example, in one of the largest real-world federated collaborations, we saw 20 independent hospitals across five continents train an AI model for predicting the oxygen needs of COVID-19 infected patients. On average, the hospitals saw a 38% improvement in generalizability and a 16% improvement in the model performance by participating in the federated system.
Likewise, there is a real opportunity to maintain customer privacy while credit card networks reduce fraudulent activity and banks employ anti-money laundering initiatives. Federated learning increases the data available to a single bank, which can help address issues such as money laundering activities in correspondent banking.
Edge computing: Smartphones and IoT
Google originally introduced federated learning in 2017 to train AI models on personal data distributed across billions of mobile devices. In 2022, many more devices are connected to the internet, including smartwatches, home assistants, alarm systems, thermostats, and even cars.
Federated learning is useful for all kinds of edge devices that are continuously collecting valuable data for ML models, but this data is often privacy sensitive, large in quantity, or both, which prevents logging to the data center.
How does federated learning fit into an existing workflow
It is important to note that federated learning is a general technique. Federated learning is not just about training neural networks; rather, it applies to data analysis, more traditional ML methods, or any other distributed workflow.
Very few assumptions are built into federated learning, and perhaps only two are worth mentioning: 1) local sites can connect to a central server, and 2) each site has the minimum computational resources to train locally.
Beyond that, you are free to design your own application with custom local and global aggregation behavior. You can decide how much trust to place in different parties and how much is shared with the central server. The federated system is configurable to your specific business needs.
For example, federated learning can be paired with other privacy-preserving techniques like differential privacy (to add noise) and homomorphic encryption (to encrypt model updates and obscure what the central server sees).
Get started with federated learning
We have developed a federated_learning code sample that shows you how to train a global fraud prediction model on two different splits of a credit card transactions dataset, corresponding to two different geographic regions.
Although federated learning by definition enables training across multiple machines, this example is designed to simulate an entire federated system on a single machine for you to get up and running in under an hour. The system is implemented with NVFLARE, an NVIDIA open-source framework to enable federated learning.
Acknowledgments
We would like to thank Patrick Hogan and Anita Weemaes for their contributions to this post.