E-commerce sales have skyrocketed as more people shop remotely, spurred by the pandemic. But this surge has also led fraudsters to use the opportunity to scam retailers and customers, according to David Sutton, director of analytical technology at fintech company Featurespace. The company, headquartered in the U.K., has developed AI-powered technology to increase the speed Read article >
Some weeks, GFN Thursday reveals new or unique features. Other weeks, it’s a cool reward. And every week, it offers its members new games. This week, it’s all of the above. First, Saints Row marches into GeForce NOW. Be your own boss in the new reboot of the classic open-world criminal adventure series, now available Read article >
Quarterly revenue of $6.70 billion, up 3% from a year agoData Center revenue of $3.81 billion, up 61% from a year agoQuarterly return to shareholders of $3.44 billion SANTA CLARA, Calif., Aug. …
Posted by Aparna Taneja, Software Engineer, and Milind Tambe, Principal Scientist, Google Research, India Research Lab
The widespread availability of mobile phones has enabled non-profits to deliver critical health information to their beneficiaries in a timely manner. While advanced applications on smartphones allow for richer multimedia content and two-way communication between beneficiaries and health coaches, simpler text and voice messaging services can be effective in disseminating information to large communities, particularly those that are underserved with limited access to information and smartphones. ARMMAN1, one non-profit doing just this, is based in India with the mission of improving maternal and child health outcomes in underserved communities.
Overview of ARMMAN
One of the programs run by them is mMitra, which employs automated voice messaging to deliver timely preventive care information to expecting and new mothers during pregnancy and until one year after birth. These messages are tailored according to the gestational age of the beneficiary. Regular listenership to these messages has been shown to have a high correlation with improved behavioral and health outcomes, such as a 17% increase in infants with tripled birth weight at end of year and a 36% increase in women knowing the importance of taking iron tablets.
However, a key challenge ARMMAN faced was that about 40% of women gradually stopped engaging with the program. While it’s possible to mitigate this with live service calls to women to explain the advantage of listening to the messages, it is infeasible to call all the low listeners in the program because of limited support staff — this highlights the importance of effectively prioritizing who receives such service calls.
In “Field Study in Deploying Restless Multi-Armed Bandits: Assisting Non-Profits in Improving Maternal and Child Health”, published in AAAI 2022, we describe an ML-based solution that uses historical data from the NGO to predict which beneficiaries will benefit most from service calls. We address the challenges that come with a large-scale real world deployment of such a system and show the usefulness of deploying this model in a real study involving over 23,000 participants. The model showed an increase in listenership of 30% compared to the current standard of care group.
Background We model this resource optimization problem using restless multi-armed bandits (RMABs), which have been well studied for application to such problems in a myriad of domains, including healthcare. An RMAB consists of n arms where each arm (representing a beneficiary) is associated with a two-state Markov decision process (MDP). Each MDP is modeled as a two-state (good or bad state, where the good state corresponds to high listenership in the previous week), two-action (corresponding to whether the beneficiary was chosen to receive a service call or not) problem. Further, each MDP has an associated reward function (i.e., the reward accumulated at a given state and action) and a transition function indicating the probability of moving from one state to the next under a given action, under the Markov condition that the next state depends only on the previous state and the action taken on that arm in that time step. The term restless indicates that all arms can change state irrespective of the action.
State of a beneficiary may transition from good (high engagement) to bad (low engagement) with example passive and active transition probabilities shown in the transition matrix.
Model Development Finally, the RMAB problem is modeled such that at any time step, given n total arms, which k arms should be acted on (i.e., chosen to receive a service call), to maximize reward (engagement with the program).
The probability of transitioning from one state to another with (active probability) or without (passive probability) receiving a service call are therefore the underlying model parameters that are critical to solving the above optimization. To estimate these parameters, we use the demographic data of the beneficiaries collected at time of enrolment by the NGO, such as age, income, education, number of children, etc., as well as past listenership data, all in-line with the NGO’s data privacy standards (more below).
However, the limited volume of service calls limits the data corresponding to receiving a service call. To mitigate this, we use clustering techniques to learn from the collective observations of beneficiaries within a cluster and enable overcoming the challenge of limited samples per individual beneficiary.
In particular, we perform clustering on listenership behaviors, and then compute a mapping from the demographic features to each cluster.
Clustering on past listenership data reveals clusters with beneficiaries that behave similarly. We then infer a mapping from demographic features to clusters.
This mapping is useful because when a new beneficiary is enrolled, we only have access to their demographic information and have no knowledge of their listenership patterns, since they haven’t had a chance to listen yet. Using the mapping, we can infer transition probabilities for any new beneficiary that enrolls into the system.
We used several qualitative and quantitative metrics to infer the optimal set of of clusters and explored different combinations of training data (demographic features only, features plus passive probabilities, features plus all probabilities, passive probabilities only) to achieve the most meaningful clusters, that are representative of the underlying data distribution and have a low variance in individual cluster sizes.
Comparison of passive transition probabilities obtained from different clustering methods with number of clusters s = 20 (red dots) and 40 (green dots), using ground truth passive transition probabilities (blue dots). Clustering based on features+passive probabilities (PPF) captures more distinct beneficiary behaviors across the probability space.
Clustering has the added advantage of reducing computational cost for resource-limited NGOs, as the optimization needs to be solved at a cluster level rather than an individual level. Finally, solving RMAB’s is known to be P-space hard, so we choose to solve the optimization using the popular Whittle index approach, which ultimately provides a ranking of beneficiaries based on their likely benefit of receiving a service call.
Results We evaluated the model in a real world study consisting of approximately 23,000 beneficiaries who were divided into three groups: the current standard of care (CSOC) group, the “round robin” (RR) group, and the RMAB group. The beneficiaries in the CSOC group follow the original standard of care, where there are no NGO initiated service calls. The RR group represents the scenario where the NGO often conducts service calls using some systematic set order — the idea here is to have an easily executable policy that services enough of a cross-section of beneficiaries and can be scaled up or down per week based on available resources (this is the approach used by the NGO in this particular case, but the approach may vary for different NGOs). The RMAB group receives service calls as predicted by the RMAB model. All the beneficiaries across the three groups continue to receive the automated voice messages independent of the service calls.
Distributions of clusters picked for service calls by RMAB and RR in week 1 (left) and 2 (right) are significantly different. RMAB is very strategic in picking only a few clusters with a promising probability of success (blue is high and red is low), RR displays no such strategic selection.
At the end of seven weeks, RMAB-based service calls resulted in the highest (and statistically significant) reduction in cumulative engagement drops (32%) compared to the CSOC group.
The plot shows cumulative engagement drops prevented compared to the control group.
Ethical Considerations An ethics board at the NGO reviewed the study. We took significant measures to ensure participant consent is understood and recorded in a language of the community’s choice at each stage of the program. Data stewardship resides in the hands of the NGO, and only the NGO is allowed to share data. The code will soon be available publicly. The pipeline only uses anonymized data and no personally identifiable information (PII) is made available to the models. Sensitive data, such as caste, religion, etc., are not collected by ARMMAN for mMitra. Therefore, in pursuit of ensuring fairness of the model, we worked with public health and field experts to ensure other indicators of socioeconomic status were measured and adequately evaluated as shown below.
Distribution of highest education received (top) and monthly family income in Indian Rupees (bottom) across a cohort that received service calls compared to the whole population.
The proportion of beneficiaries that received a live service call within each income bracket reasonably matches the proportion in the overall population. However, differences are observed in lower income categories, where the RMAB model favors beneficiaries with lower income and beneficiaries with no formal education. Lastly, domain experts at ARMMAN have been deeply involved in the development and testing of this system and have provided continuous input and oversight in data interpretation, data consumption, and model design.
Conclusions After thorough testing, the NGO has currently deployed this system for scheduling of service calls on a weekly basis. We are hopeful that this will pave the way for more deployments of ML algorithms for social impact in partnerships with non-profits in service of populations that have so far benefited less from ML. This work was also featured in Google for India 2021.
1ARMMAN runs multiple programs to provide preventive care information to women through pregnancy and infancy enabling them to seek care, as well as programs to train and support health workers for timely detection and management of high-risk conditions. ↩
NVIDIA Grace CPU is the first data center CPU developed by NVIDIA. It has been built from the ground up to create the world’s first superchips. Designed…
Designed to deliver excellent performance and energy efficiency to meet the demands of modern data center workloads powering digital twins, cloud gaming and graphics, AI, and high-performance computing (HPC), NVIDIA Grace CPU features 72 Armv9 CPU cores that implement Arm Scalable Vector Extensions version two (SVE2) instruction set. The cores also incorporate virtualization extensions with nested virtualization capability and S-EL2 support.
NVIDIA Grace CPU is also compliant with the following Arm specifications:
RAS v1.1 Generic Interrupt Controller (GIC) v4.1
Memory Partitioning and Monitoring (MPAM)
System Memory Management Unit (SMMU) v3.1
Grace CPU was built to pair with either the NVIDIA Hopper GPU to create the NVIDIA Grace CPU Superchip for large-scale AI training, inference, and HPC, or with another Grace CPU to build a high-performance CPU to meet the needs of HPC and cloud computing workloads.
Read on to learn about the key features of Grace CPU.
High-speed chip-to-chip interconnect with NVLink-C2C
Both the Grace Hopper and Grace Superchips are enabled by the NVIDIA NVLink-C2C high-speed chip-to-chip interconnect, which serves as the backbone for the superchip communication.
NVLink-C2C extends NVIDIA NVLink used to connect multiple GPUs in a server and, with NVLink Switch System, multiple GPU nodes.
With 900 GB/s of raw bidirectional bandwidth between dies on the package, NVLink-C2C provides 7x the bandwidth of a PCIe Gen 5 x16 link (the same bandwidth that is available between NVIDIA Hopper GPUs when using NVLink) and with lower latency. NVLink-C2C also requires just 1.3 picojoules/bit transferred, which is more than 5x the energy efficiency of PCIe Gen 5.
NVLink-C2C is also a coherent interconnect, which enables coherency when programming both a standard coherent CPU platform using the Grace CPU Superchip, as well as a heterogeneous programming model with the Grace Hopper Superchip.
Standards-compliant platforms with NVIDIA Grace CPU
NVIDIA Grace CPU Superchip is built to provide software developers with a standards-compliant platform. Arm provides a set of specifications as part of its System Ready initiative, which aims to bring standardization to the Arm ecosystem.
Grace CPU targets the Arm system standards to offer compatibility with off-the-shelf operating systems and software applications, and Grace CPU will take advantage of the NVIDIA Arm software stack from the start.
Grace CPU also complies with the Arm Server Base System Architecture (SBSA) to enable standards-compliant hardware and software interfaces. In addition, to enable standard boot flows on Grace CPU-based systems, Grace CPU has been designed to support Arm Server Base Boot Requirements (SBBR).
For cache and bandwidth partitioning, as well as bandwidth monitoring, Grace CPU also supports Arm Memory Partitioning and Monitoring (MPAM).
Grace CPU also includes Arm Performance Monitoring Units, allowing for the performance monitoring of the CPU cores as well as other subsystems in the system-on-a-chip (SoC) architecture. This enables standard tools, such as Linux perf, to be used for performance investigations.
Unified Memory with Grace Hopper Superchip
Combining a Grace CPU with a Hopper GPU, the NVIDIA Grace Hopper Superchip expands upon the CUDA Unified Memory programming model that was first introduced in CUDA 8.0.
NVIDIA Grace Hopper Superchip introduces Unified Memory with shared page tables, allowing the Grace CPU and Hopper GPU to share an address space and even page tables with a CUDA application.
The Grace Hopper GPU can also access pageable memory allocations. Grace Hopper Superchip allows programmers to use system allocators to allocate GPU memory, including the ability to exchange pointers to malloc memory with the GPU.
NVLink-C2C enables native atomic support between the Grace CPU and the Hopper GPU, unlocking the full potential for C++ atomics that were first introduced in CUDA 10.2.
NVIDIA Scalable Coherency Fabric
Grace CPU introduces the NVIDIA Scalable Coherency Fabric (SCF). Designed by NVIDIA, SCF is a mesh fabric and distributed cache designed to scale to the needs of the data center. SCF provides 3.2 TB/s of bisection bandwidth to ensure the flow of data traffic between NVLink-C2C, CPU cores, memory, and system IOs.
Figure 1. Diagram of NVIDIA Scalable Coherency Fabric, introduced with the Grace CPU
A single Grace CPU incorporates 72 CPU cores and 117 MB of cache, but SCF is designed for scalability beyond this configuration. When two Grace CPUs are combined to form a Grace Superchip, these figures double to 144 CPU cores and 234 MB of L3 cache, respectively.
The CPU cores and SCF Cache partitions (SCCs) are distributed throughout the mesh. Cache Switch Nodes (CSNs) route data through the fabric and serve as interfaces between the CPU cores, cache memory and the rest of the system, enabling high-bandwidth throughout.
Memory partitioning and monitoring
Grace CPU incorporates support for Memory System Resource Partitioning and Monitoring (MPAM) capability, which is the Arm standard for partitioning both system cache and memory resources.
MPAM works by assigning partition IDs (PARTIDs) to requestors within the system. This design allows resources such as cache capacity and memory bandwidth to be partitioned or monitored based on their respective PARTIDs.
The SCF Cache in Grace CPU supports both the partitioning of cache capacity as well as memory bandwidth using MPAM. Additionally, Performance Monitor Groups (PMGs) can be used to monitor resource usage.
Boosting bandwidth and energy efficiency with memory subsystem
To deliver excellent bandwidth and energy efficiency, Grace CPU implements a 32-channel LPDDR5X memory interface. This provides memory capacity of up to 512 GB and memory bandwidth of up to 546 GB/s.
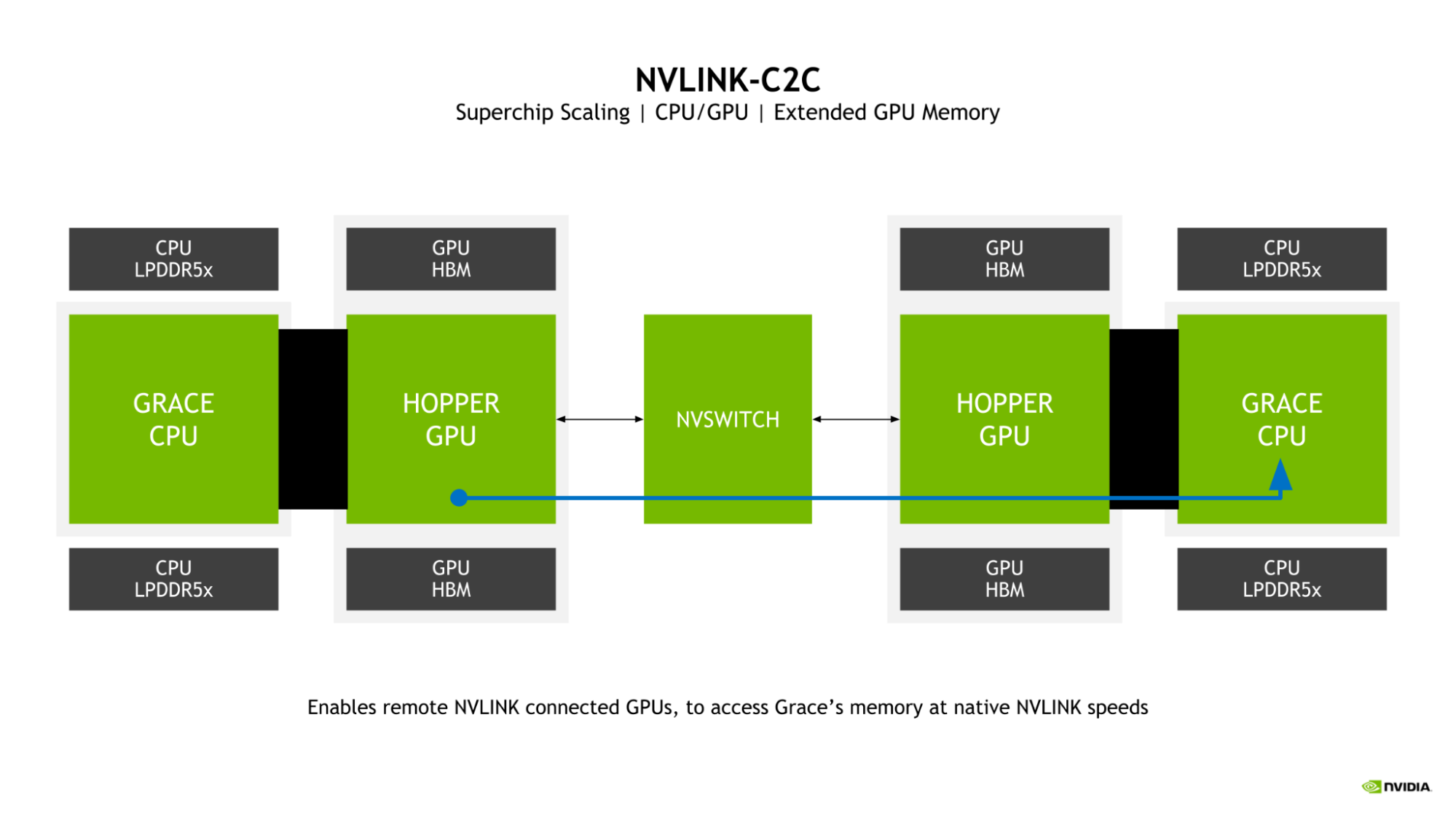
Extended GPU Memory
A key feature of the Grace Hopper Superchip is the introduction of Extended GPU Memory (EGM). By allowing any Hopper GPU connected from a larger NVLink network to access the LPDDR5X memory connected to the Grace CPU in the Grace Hopper Superchip, the memory pool available to the GPU is greatly expanded.
Figure 2. Hopper GPU can access the memory of a remote Grace CPU using NVLink-C2C
The GPU-to-GPU NVLink and NVLink-C2C bidirectional bandwidths are matched in a superchip, which enables the Hopper GPUs to access the Grace CPU memory at NVLink native speeds.
Balancing bandwidth and energy efficiency with LPDDR5X
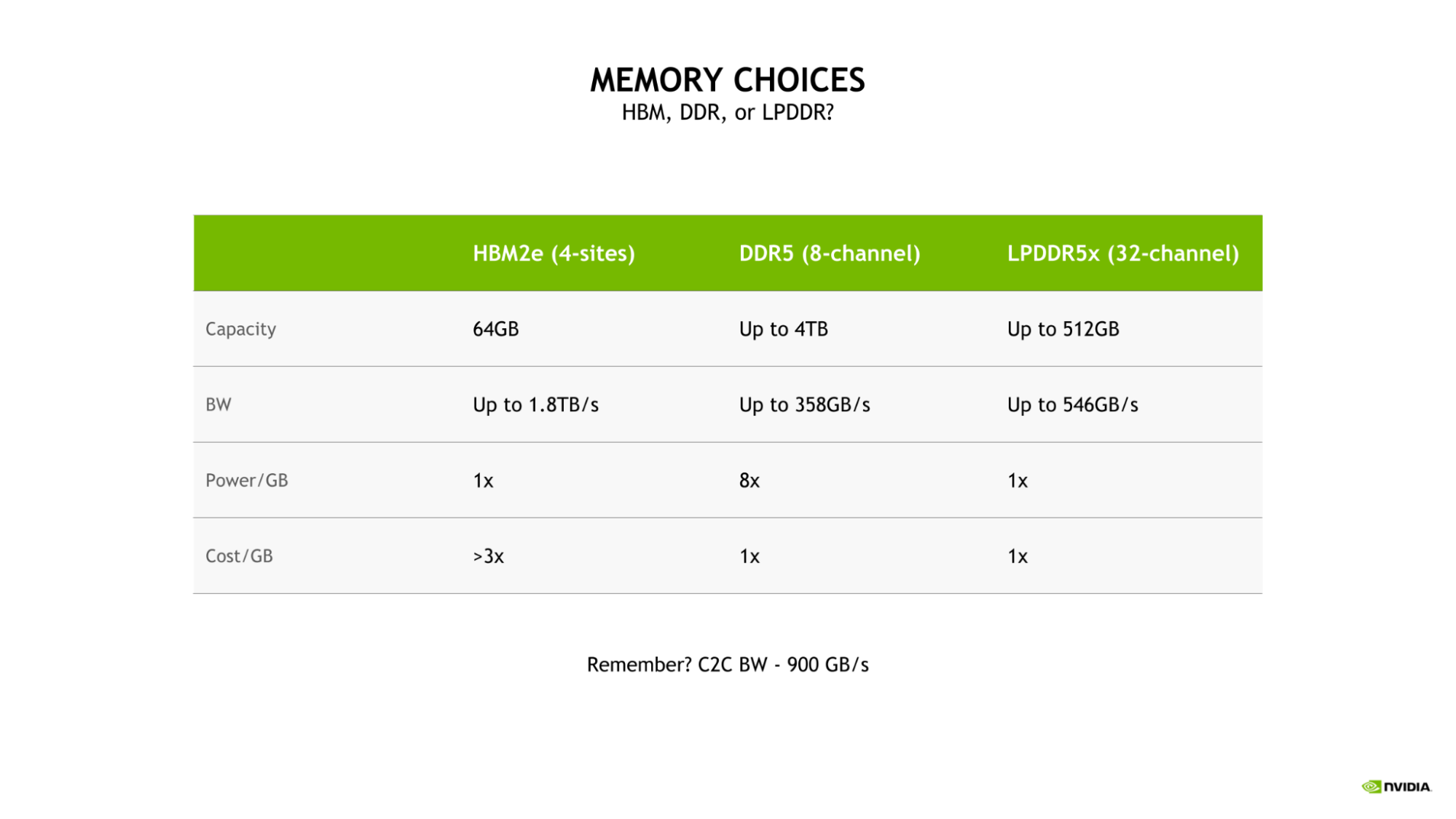
The selection of LPDDR5X for Grace CPU was driven by the need to strike the optimal balance of bandwidth, energy efficiency, capacity, and cost for large-scale AI and HPC workloads.
While a four-site HBM2e memory subsystem would have provided substantial memory bandwidth and good energy efficiency, it would do so at more than 3x the cost-per-gigabyte of either DDR5 or LPDDR5X.
Additionally, such a configuration would be limited to a capacity of only 64 GB, which is one-eighth the maximum capacity available to the Grace CPU with LPDDR5X.
Compared to a more traditional eight-channel DDR5 design, the Grace CPU LPDDR5X memory subsystem provides up to 53% more bandwidth and is substantially more power efficient, requiring just an eighth of the power per gigabyte.
Figure 3. Capacity, bandwidth, power, and cost comparison of HBM2e (4-sites), DDR5 (8-channel), and LPDDR5x (32-channel) memory options
The excellent power efficiency of LPDDR5X enables allocating more of the total power budget to compute resources, such as the CPU cores or GPU streaming multiprocessors (SMs).
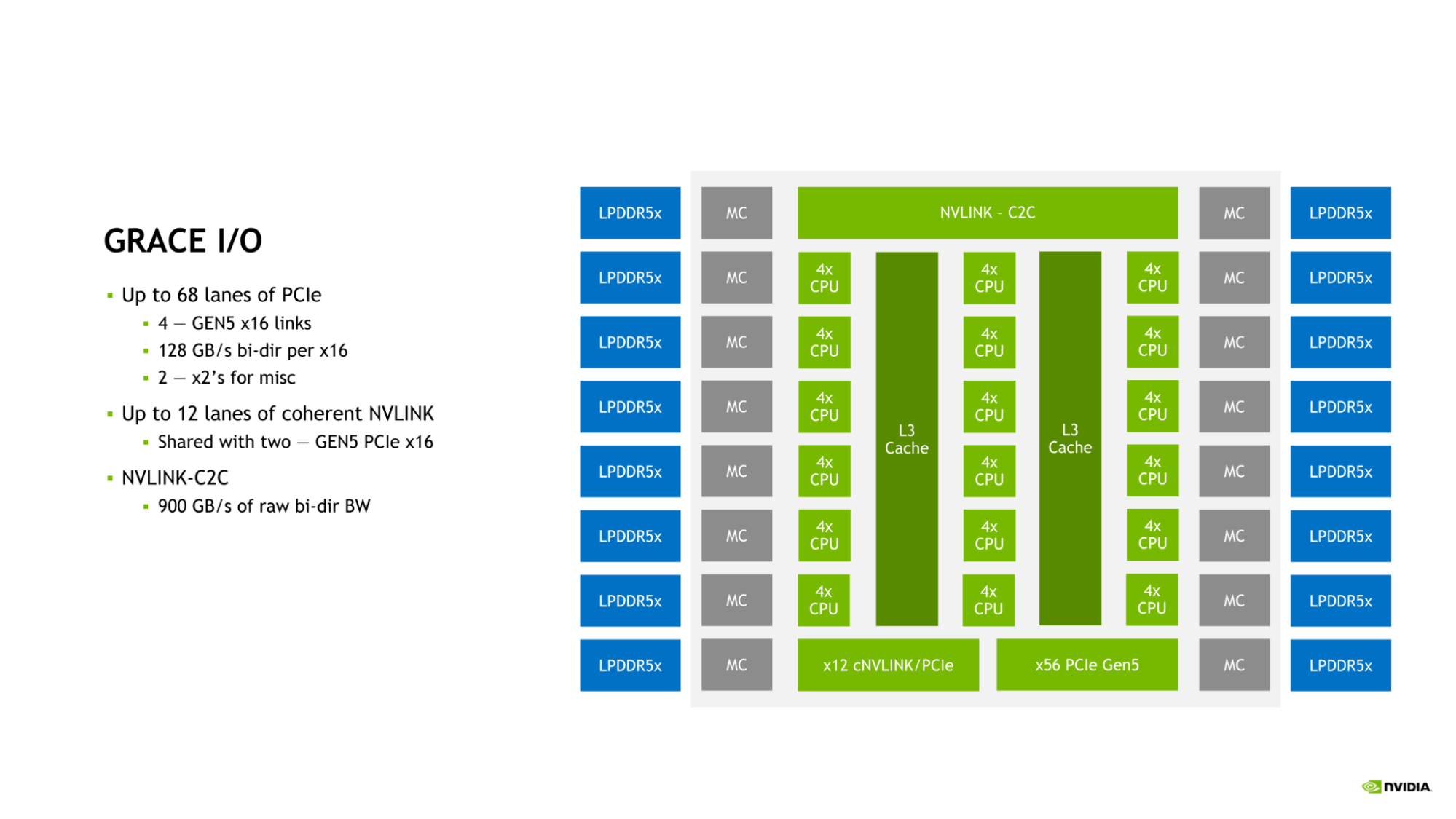
NVIDIA Grace CPU I/O
Grace CPU incorporates a complement of high-speed I/O to serve the needs of the modern data center. The Grace CPU SoC provides up to 68 lanes of PCIe connectivity and up to four PCIe Gen 5 x16 links. Each PCIe Gen 5 x16 link offers up to 128 GB/s of bidirectional bandwidth and can be further bifurcated into two PCIe Gen 5 x8 links for additional connectivity.
Figure 4. Grace I/O features up to 68 lanes of PCIe, 12 lanes of coherent NVLINK, and NVLINK-C2C
This connectivity is in addition to the on-die NVLink-C2C link that can be used to connect Grace CPU to either another Grace CPU or to an NVIDIA Hopper GPU.
The combination of NVLink, NVLink-C2C, and PCIe Gen 5 provides the Grace CPU with the rich suite of connectivity options and ample bandwidth needed to scale performance in the modern data center.
NVIDIA Grace CPU performance
NVIDIA Grace CPU is designed to deliver excellent compute performance in both single-chip as well as Grace Superchip configurations, with estimated SPECrate2017_int_base scores of 370 and 740, respectively. These pre-silicon estimates are based on use of the GNU Compiler Collection (GCC).
Figure 5. The SPEC rate estimates of a single Grace CPU (left) and Grace Superchip (right). Source: Pre-silicon estimated performance (subject to change).
Memory bandwidth is critical to the workloads for which the Grace CPU was designed, and in the Stream Benchmark, a single Grace CPU is expected to deliver up to 536 GB/s of realized bandwidth, representing more than 98% of the chip’s peak theoretical bandwidth.
Figure 6. Grace CPU memory benchmark results of MemRead, MemSet, MemCopy, and MemTriad (left to right)
And, finally, the bandwidth between the Hopper GPU and the Grace CPU is critical to maximizing the performance of the Grace Hopper Superchip. GPU-to-CPU memory reads and writes are expected to be 429 GB/s and 407 GB/s, respectively, representing more than 95% and more than 90% of the peak theoretical unidirectional transfer rates of NVLink-C2C.
Combined read and write performance is expected to be 506 GB/s, representing over 92% of the peak theoretical memory bandwidth available to a single NVIDIA Grace CPU SoC.
Figure 7. Hopper GPU to Grace memory benchmark results
Benefits of the NVIDIA Grace CPU Superchip
With 144 cores and 1 TB/s of memory bandwidth, the NVIDIA Grace CPU Superchip will provide unprecedented performance for CPU-based high performance computing applications. HPC applications are compute-intensive, demanding the highest-performing cores, highest-memory bandwidth, and the right memory capacity per core to speed outcomes.
NVIDIA is working with leading HPC, supercomputing, hyperscale, and cloud customers for the Grace CPU Superchip. Grace CPU Superchip and Grace Hopper Superchip are expected to be available in the first half of 2023.
For more information about the NVIDIA Grace Hopper Superchip and NVIDIA Grace CPU Superchip, visit NVIDIA Grace CPU.
Increasing demands in AI and high-performance computing (HPC) are driving a need for faster, more scalable interconnects with high-speed communication between…
Increasing demands in AI and high-performance computing (HPC) are driving a need for faster, more scalable interconnects with high-speed communication between every GPU.
The third-generation NVIDIA NVSwitch is designed to satisfy this communication need. This latest NVSwitch and the H100 Tensor Core GPU use the fourth-generation NVLink, the newest high-speed, point-to-point interconnect by NVIDIA.
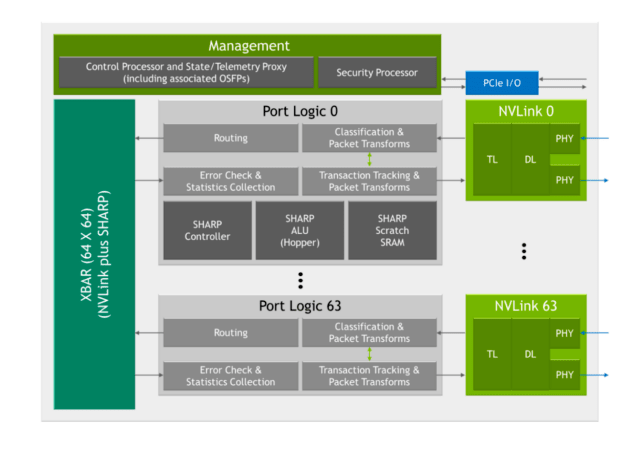
The third-generation NVIDIA NVSwitch is designed to provide connectivity within a node or to GPUs external to the node for the NVLink Switch System. It also incorporates hardware acceleration for collective operations with multicast and NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) in-network reductions.
NVIDIA NVSwitch is also a critical enabler of the NVLink Switch networking appliance, which enables the creation of clusters with up to 256 connected NVIDIA H100 Tensor Core GPUs and 57.6 TB/s of all-to-all bandwidth. The appliance delivers 9x more bisection bandwidth than was possible with HDR InfiniBand on NVIDIA Ampere Architecture GPUs.
High bandwidth and GPU-compatible operation
The performance needs of AI and HPC workloads continue to grow rapidly and require scaling to multi-node, multi-GPU systems.
Delivering excellent performance at scale requires high-bandwidth communication between every GPU, and the NVIDIA NVLink specification is designed for synergistic operation with NVIDIA GPUs to enable the required performance and scalability.
For instance, the thread-block execution structure of NVIDIA GPUs efficiently feeds the parallelized NVLink architecture. NVLink-Port interfaces have also been designed to match the data exchange semantics of GPU L2 caches as closely as possible.
Faster than PCIe
A key benefit of NVLink is that it offers substantially greater bandwidth than PCIe. Fourth-generation NVLink is capable of 100 Gbps per lane, more than tripling the 32 Gbps bandwidth of PCIe Gen5. Multiple NVLinks can be combined to provide even higher aggregate lane counts, yielding higher throughput.
Lower overhead than traditional networks
NVLink has been designed specifically as a high-speed, point-to-point link to interconnect GPUs, yielding lower overhead than would be present in traditional networks.
This enables many of the complex networking features found in traditional networks—such as end-to-end retry, adaptive routing, and packet reordering—to be traded off for increased port counts.
The greater simplicity of the network interface allows for application–, presentation–, and session-layer functionality to be embedded directly into CUDA itself, further reducing communication overhead.
NVLink generations
First introduced with the NVIDIA P100 GPU, NVLink has continued to advance in lockstep with NVIDIA GPU architectures, with each new architecture accompanied by a new generation of NVLink.
Figure 1. NVLink generations with the evolution in-step with GPUs
Fourth-generation NVLink provides 900 GB/s of bidirectional bandwidth per GPU—1.5x greater than the prior generation and more than 5.6x higher than first-generation NVLink.
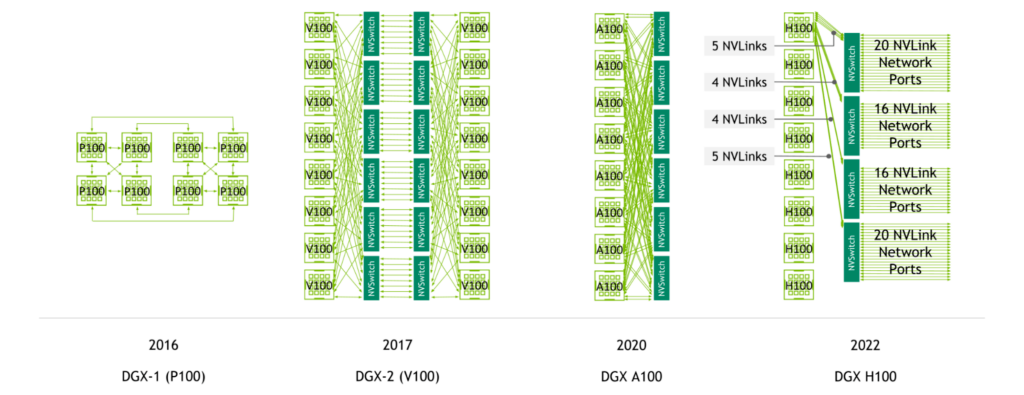
NVLink-enabled server generations
NVIDIA NVSwitch was first introduced with the NVIDIA V100 Tensor Core GPU and second-generation NVLink, enabling high-bandwidth, any-to-any connectivity between all GPUs in a server.
The NVIDIA A100 Tensor Core GPU introduced third-generation NVLink and second-generation NVSwitch, doubling both per-GPU bandwidth as well as reduction bandwidth.
Figure 2. NVLink all-to-all connectivity across DGX server generations
With fourth-generation NVLink and third-generation NVSwitch, a system with eight NVIDIA H100 Tensor Core GPUs features 3.6 TB/s of bisection bandwidth and 450 GB/s of bandwidth for reduction operations. These are1.5x and 3x increases compared to the prior generation.
In addition, with fourth-generation NVLink and third-generation NVSwitch as well as the external NVIDIA NVLink Switch, multi-GPU communication across multiple servers at NVLink speeds is now possible.
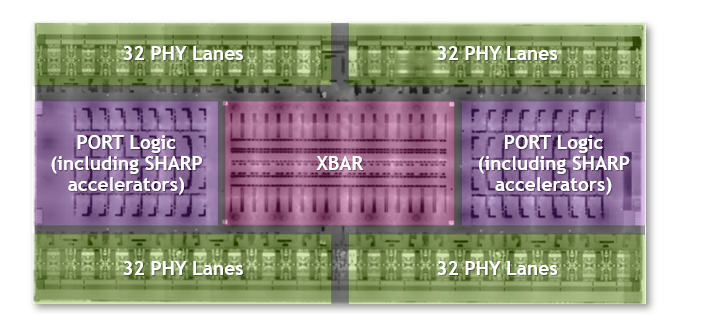
The largest and fastest switch chip to date
Third-generation NVSwitch is the largest NVSwitch to date. It is built using the TSMC 4N process customized for NVIDIA. The die incorporates 25.1 billion transistors—more transistors than the NVIDIA V100 Tensor Core GPU—in an area of 294 mm2. The package dimensions are 50 mm x 50 mm with a total of 2645 solder balls.
Figure 3. Third-generation NVSwitch chip characteristics include it being the largest NVSwitch with the highest bandwidth ever and 400 GFlops of FP32 SHARP
NVLink network support
Third-generation NVSwitch is a key enabler of the NVLink Switch System, which enables connectivity between GPUs across nodes at NVLink speeds.
It incorporates physical (PHY) electrical interfaces that are compatible with 400 Gbps Ethernet and InfiniBand connectivity. The included management controller now provides support for attached Octal Small Formfactor Pluggable (OSFP) modules with four NVLinks per cage. With custom firmware, active cables can be supported.
Additional forward error correction (FEC) modes have also been added to enhance NVLink Network performance and reliability.
A security processor has also been added to protect data and chip configuration from attacks. The chip provides partitioning features that can isolate subsets of ports into separate NVLink Networks. Expanded telemetry features also enable InfiniBand-style monitoring.
Double the bandwidth
Third-generation NVSwitch is our highest-bandwidth NVSwitch yet.
With 100 Gbps of bandwidth per differential pair using 50 Gbaud PAM4 signaling, third-generation NVSwitch provides 3.2 TB/s of full-duplex bandwidth across 64 NVLink ports (x2 per NVLink). It delivers more bandwidth in a system while also requiring fewer NVSwitch chips compared to the prior generation. All ports on third-generation NVSwitch are NVLink Network–capable.
SHARP collectives and multicast support
Third-generation NVSwitch includes a host of new hardware blocks for SHARP acceleration:
The embedded ALUs offer up to 400 FLOPS of FP32 throughput and have been added to perform reduction operations directly in NVSwitch, rather than by the GPUs in the system.
These ALUs support a wide variety of operators, such as logical, min/max, and add. They also support data formats such as signed/unsigned integers, FP16, FP32, FP64, and BF16.
Third-generation NVSwitch also includes a SHARP controller that can manage up to 128 SHARP groups in parallel. The crossbar bandwidth in the chip has been increased to carry additional SHARP-related exchanges.
all-reduce operation compatibility
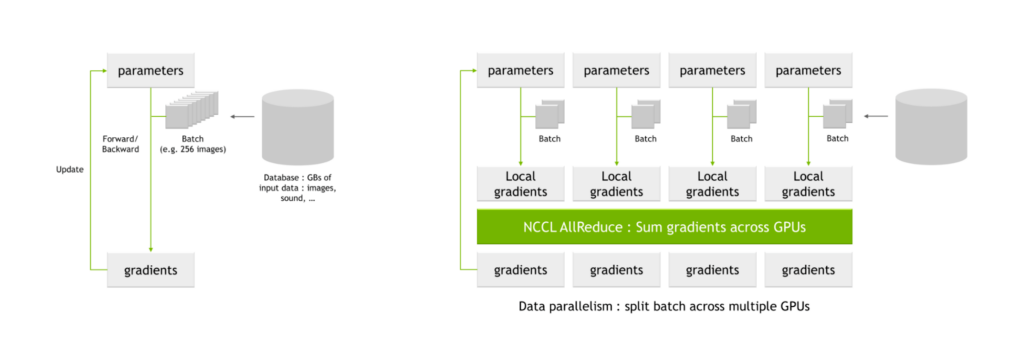
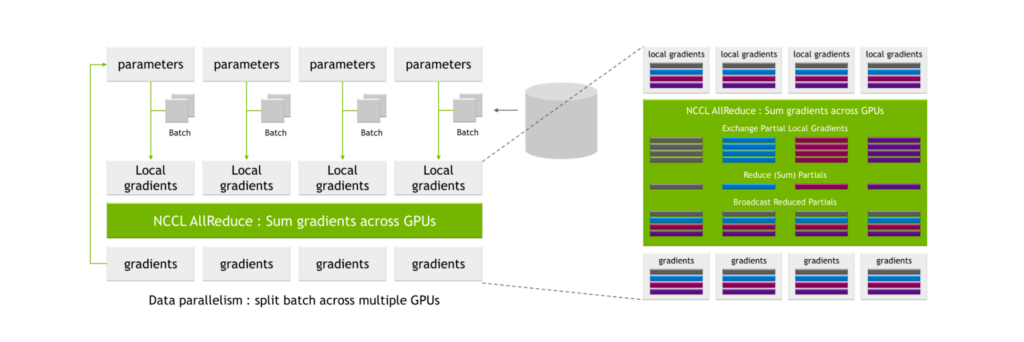
A key use case for NVIDIA SHARP is for all-reduce operations that are common in AI training. When training networks using multiple GPUs, batches are split into smaller subbatches, which are then assigned to each individual GPU.
Each GPU processes their individual subbatches through the network parameters, yielding possible changes to the parameters, also known as local gradients. These local gradients are combined and reconciled to produce global gradients, which each GPU applies to their parameter tables. This averaging process is also known as an all-reduce operation.
Figure 5. NCCL AllReduce in AI training with critical communication-intensive operation
NVIDIA Magnum IO is the architecture for data center IO to accelerate multi-GPU and multi-node communications. It enables HPC, AI, and scientific applications to scale performance on new large GPU clusters scaled using NVLink and NVSwitch.
Magnum IO includes the NVIDIA Collective Communication Library (NCCL), which implements a wealth of multi-GPU and multi-node collective primitives, including all-reduce.
NCCL AllReduce takes as input the local gradients, partitions them into subsets, collects all subsets of a certain level and assigns it to a single GPU. The GPU then performs the reconciliation process for that subset, such as summing across local gradient values from all GPUs.
Following this process, a global set of gradients is produced and then distributed to all other GPUs.
Figure 6. Traditional all-reduce calculation with data-exchange and parallel calculation
These processes are highly communication-intensive and the associated communication overhead can substantially lengthen the overall time to train.
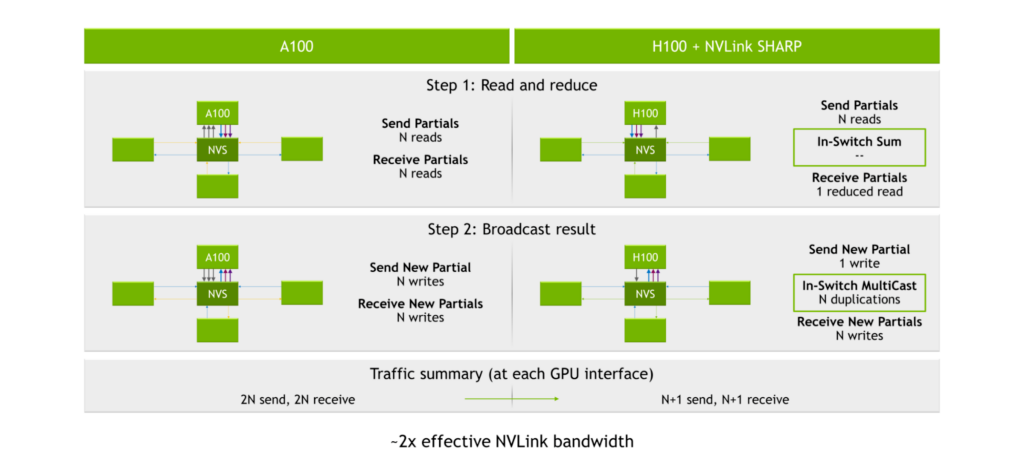
With the NVIDIA A100 Tensor Core GPU, third-generation NVLink, and second-generation NVSwitch, the process of sending and receiving partials yields 2N reads (where N is the number of GPUs). The process of broadcasting results yields 2N writes for 2N reads and 2N writes at each GPU interface, or 4N total operations.
Figure 7. NVLink SHARP acceleration
The SHARP engines are inside of third-generation NVSwitch. Instead of distributing the data to each GPU and having the GPUs perform the calculations, the GPUs send their data into third-generation NVSwitch chips. The chips then perform the calculations and then send the results back. This results in a total of 2N+2 operations, or approximately halving the number of read/write operations needed to perform the all-reduce calculation.
Boosting performance for large-scale models
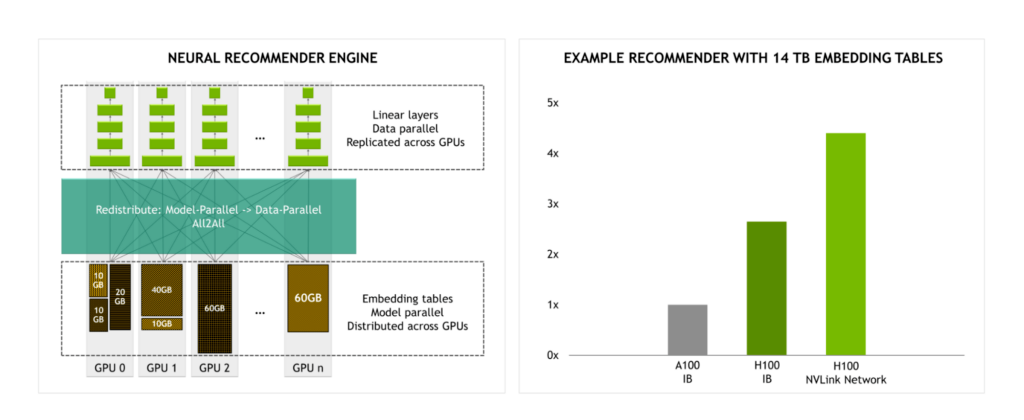
With the NVLink Switch System providing 4.5x more bandwidth than InfiniBand, large-scale model training becomes more practical.
For example, when training a recommendation engine with 14 TB embedding tables, we expect a significant performance uplift in performance for H100 using the NVLink Switch System compared to H100 using InfiniBand.
Figure 8. NVLink Switch System features 4.5x more bandwidth than maximum InfiniBand
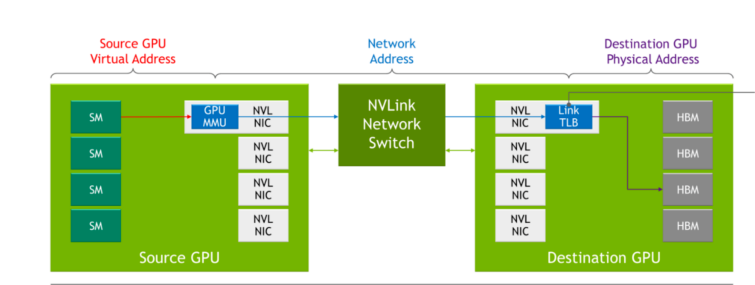
NVLink Network
In prior generations of NVLink, each server had its own local address space used by GPUs within a server when communicating to each other over NVLink. With the NVLink Network, each server has its own address space, which is used when GPUs send data across the network, providing isolation and improved security when sharing data. This capability leverages functionality built into the latest NVIDIA Hopper GPU Architecture.
While NVLink performs connection setup during the system boot process, the NVLink Network connection setup is performed through a runtime API call by software. This enables the network to be reconfigured on the fly as different servers come online and as users enter and exit.
Figure 9. NVLink Switch System changes compared to NVLink
Table 1 shows how traditional networking concepts map to their counterparts in NVLink Network.
Concept
Traditional Example
NVLink Network
Physical Layer
400G electrical/optical media
Custom-FW OSFP
Data Link Layer
Ethernet
NVLink custom on-chip HW and FW
Network Layer
IP
New NVLink Network Addressing and Management Protocols
Transport Layer
TCP
NVLink custom on-chip HW and FW
Session Layer
Sockets
SHARP groupsCUDA export of Network addresses of data-structures
Presentation Layer
TSL/SSL
Library abstractions (e.g., NCCL, NVSHMEM)
Application Layer
HTTP/FTP
AI Frameworks or User Apps
NIC
PCIe NIC (card or chip)
Functions embedded in GPU and NVSwitch
RDMA Off-Load
NIC Off-Load Engine
GPU-internal Copy Engine
Collectives Off-Load
NIC/Switch Off-Load Engine
NVSwitch-internal SHARP Engines
Security Off-Load
NIC Security Features
GPU-internal Encryption and “TLB” Firewalls
Media Control
NIC Cable Adaptation
NVSwitch-internal OSFP-cable controllers
Table 1. Traditional networking concepts mapped to their counterparts with the NVLink Switch System
DGX H100
NVIDIA DGX H100 is the latest iteration of the DGX family of systems based on the latest NVIDIA H100 Tensor Core GPU and incorporates:
8x NVIDIA H100 Tensor Core GPUs with 640GB of aggregate GPU memory
4x third-generation NVIDIA NVSwitch chips
18x NVLink Network OSFPs
3.6 TB/s of full-duplex NVLink Network bandwidth provided by 72 NVLinks
8x NVIDIA ConnectX-7 Ethernet/InfiniBand ports
2x dual-port BlueField-3 DPUs
Dual Sapphire Rapids CPUs
Support for PCIe Gen 5
Full bandwidth intra-server NVLink
Within a DGX H100, each of the eight H100 Tensor Core GPUs within the system is connected to all four third-generation NVSwitch chips. Traffic is sent across four different switch planes, enabling the aggregation of the links to achieve full all-to-all bandwidth between GPUs in the system.
Half-bandwidth NVLink Network
With NVLink Network, all eight NVIDIA H100 Tensor Core GPUs within a server can half-subscribe 18 NVLinks to H100 Tensor Core GPUs in other servers.
Alternatively, four H100 Tensor Core GPUs in a server can fully subscribe 18 NVLinks to H100 Tensor Core GPUs in other servers. This 2:1 taper is a trade-off made to balance bandwidth with server complexity and cost for this instantiation of the technology.
With SHARP, the bandwidth delivered is equivalent to a full-bandwidth AllReduce.
Multi-rail Ethernet
Within a server, all eight GPUs independently support RDMA from their own dedicated 400 GB NICs. 800 GB/s of aggregate full-duplex bandwidth is possible to non-NVLink Network devices.
DGX H100 SuperPOD
DGX H100 is the building block of the DGX H100 SuperPOD.
Built from eight compute racks, each with four DGX H100 servers.
Features a total of 32 DGX H100 nodes, incorporating 256 NVIDIA H100 Tensor Core GPUs.
Delivers up to a peak of one exaflop of peak AI compute.
The NVLink Network provides 57.6 TB/s bisection bandwidth spanning the entire 256 GPUs. Additionally, the ConnectX-7s across all 32 DGXs and associated InfiniBand switches provide 25.6 TB/s of full duplex bandwidth for use within the pod or for scaling out the multiple SuperPODs.
NVLink Switch
A key enabler of DGX H100 SuperPOD is the new NVLink Switch based on the third-generation NVSwitch chips. DGX H100 SuperPOD includes 18 NVLink Switches.
The NVLink Switch fits in a standard 1U 19-inch form factor, significantly leveraging InfiniBand switch design, and includes 32 OSFP cages. Each switch incorporates two third-generation NVSwitch chips, providing 128 fourth-generation NVLink ports for an aggregate 6.4 TB/s full-duplex bandwidth.
NVLink Switch supports out-of-band management communication and a range of cabling options such as passive copper. With custom firmware, active copper and optical OSFP cables are also supported.
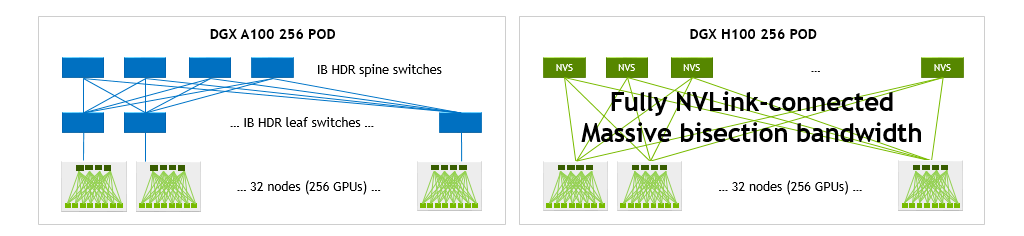
Scale up with NVLink Network
H100 SuperPOD with NVLink Network enables significant increases in bisection and reduce operation bandwidth compared to a DGX A100 SuperPOD with 256 DGX A100
GPUs.
A single DGX H100 delivers 1.5x the bisection and 3x the bandwidth for reduction operations of a single DGX A100. Those speedups grow to 9x and 4.5x in 32 DGX system configurations, each with a total of 256 GPUs.
Figure 10. DGX A100 POD and DGX H100 POD network topologies
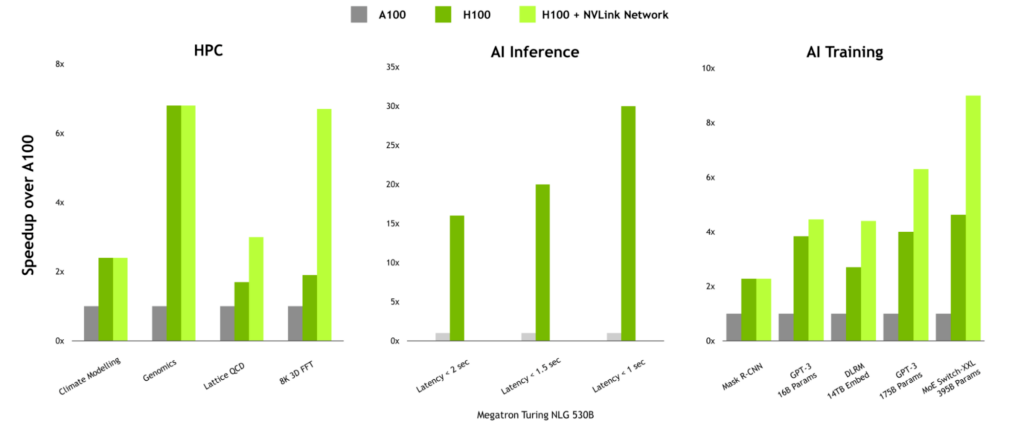
Performance benefits for communication-intensive workloads
For workloads with high communication intensity, the performance benefits of NVLink Network can be significant. In HPC, workloads such as Lattice QCD and 8K 3D FFT see substantial benefits because multi-node scaling has been designed into the communication libraries within the HPC SDK and Magnum IO.
NVLink Network can also provide a significant boost when training large language models or recommenders with large embedding tables.
Figure 11. NVLink Switch system benefits dependent on communication intensity
Delivering performance at scale
Delivering the highest performance for AI and HPC requires full-stack, data-center scale innovation. High-bandwidth, low-latency interconnect technologies are key enablers of performance at scale.
Third-generation NVSwitch delivers the next big leap for high-bandwidth, low-latency communication between GPUs both within a server, as well as bringing all-to-all GPU communication at full NVLink speed between server nodes.
Magnum IO works integrally with CUDA, HPC SDK, and nearly all deep learning frameworks. It enables AI software—such as large language models, recommender systems, and scientific applications like 3D FFT—to scale across multiple GPUs across multiple nodes using NVLink Switch System right out of the box.
Ever since its introduction in CUDA 10, CUDA Graphs has been used in a variety of applications. A graph groups a set of CUDA kernels and other CUDA operations…
Ever since its introduction in CUDA 10, CUDA Graphs has been used in a variety of applications. A graph groups a set of CUDA kernels and other CUDA operations together and executes them with a specified dependency tree. It speeds up the workflow by combining the driver activities associated with CUDA kernel launches and CUDA API calls. It also enforces the dependencies with hardware accelerations, instead of relying solely on CUDA streams and events, when possible.
There are two main ways to construct a CUDA graph: explicit API calls and stream capture.
Construct a CUDA graph with explicit API calls
With this way of constructing a CUDA graph, nodes of the graph, formed by the CUDA kernel and CUDA memory operations, are added to the graph by calling the cudaGraphAdd*Node APIs, where * is replaced with the node type. Dependencies between the nodes are set explicitly with APIs.
The upside of constructing CUDA graphs with explicit APIs is that the cudaGraphAdd*Node APIs return node handles (cudaGraphNode_t) that can be used as references for future node updates. Kernel launch configurations and kernel function parameters of a kernel node in an instantiated graph, for example, can be updated with minimal cost with cudaGraphExecKernelNodeSetParams.
The downside is that in scenarios where CUDA graph is used to speed up existing code, constructing CUDA graphs with explicit API calls typically requires a significant number of code changes, especially changes regarding the control flow and function calling structure of the code.
Construct a CUDA graph with stream capture
With this way of constructing a CUDA graph, cudaStreamBeginCapture and cudaStreamEndCapture are placed before and after a code block. All device activities launched by the code block are recorded, captured, and grouped into a CUDA graph. The dependencies among the nodes are inferred from the CUDA stream or event API calls within the stream capture region.
The upside of constructing CUDA graphs with stream capture is that for existing code, fewer code changes are needed. The original code structure can be mostly untouched and graph construction is performed in an automatic way.
There are also downsides to this way of constructing CUDA graphs. Within the stream capture region, all kernel launch configurations and kernel function parameters, as well as the CUDA API call parameters are recorded by value. Whenever any of the configurations and parameters change, the captured and then instantiated graph becomes out-of-date.
The workflow is recaptured. A reinstantiation isn’t needed when the recaptured graph has the same node topology as the instantiated graph, and a whole-graph update can be performed with cudaGraphExecUpdate.
Cache CUDA graphs with the set of configurations and parameters as the key. Each set of configurations and parameters is associated with a distinct CUDA graph within the cache. When running the workflow, the set of configurations and parameters are first abstracted into a key. Then the corresponding graph, if it already exists, is found in the cache and launched.
There are, however, workflows where neither solution works well. The recapture-then-update approach works well on paper, but in some cases the recapture and update themselves are expensive. There are also cases where it is simply not possible to associate each set of parameters with a CUDA graph. For example, cases with floating-point number parameters are difficult to cache as there are huge numbers of possible floating-point numbers.
CUDA Graphs constructed with explicit APIs are easy to update but the approach can be too cumbersome and is less flexible. CUDA Graphs can be constructed flexibly with stream capture but the resulting graphs are difficult and expensive to update.
Combined approach
In this post, I provide an approach of constructing CUDA graphs with both the explicit API and stream capture methods, thus achieving the upsides of both and avoiding the downsides of either.
As an example, in a workflow where three kernels are launched sequentially, the first two kernels have static launch configurations and parameters, but the last kernel has a dynamic launch configuration and parameters.
Use stream capture to record the launches of the first two kernels and call explicit APIs to add the last kernel node to the capturing graph. The node handle returned by the explicit APIs is then used to update the instantiated graph with the dynamic configurations and parameters every time before the graph is launched.
The following code example shows the idea:
cudaStream_t stream;
std::vector _node_list;
cudaGraphExec_t _graph_exec;
if (not using_graph) {
first_static_kernel>>(static_parameters);
second_static_kernel>>(static_parameters);
dynamic_kernel>>(dynamic_parameters);
} else {
if (capturing_graph) {
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
first_static_kernel>>(static_parameters);
second_static_kernel>>(static_parameters);
// Get the current stream capturing graph
cudaGraph_t _capturing_graph;
cudaStreamCaptureStatus _capture_status;
const cudaGraphNode_t *_deps;
size_t _dep_count;
cudaStreamGetCaptureInfo_v2(stream, &_capture_status, nullptr &_capturing_graph, &_deps, &_dep_count);
// Manually add a new kernel node
cudaGraphNode_t new_node;
cudakernelNodeParams _dynamic_params_cuda;
cudaGraphAddKernelNode(&new_node, _capturing_graph, _deps, _dep_count, &_dynamic_params_cuda);
// ... and store the new node for future references
_node_list.push_back(new_node);
// Update the stream dependencies
cudaStreamUpdateCaptureDependencies(stream, &new_node, 1, 1);
// End the capture and instantiate the graph
cudaGraph_t _captured_graph;
cudaStreamEndCapture(stream, &_captured_graph);
cudaGraphInstantiate(&_graph_exec, _captured_graph, nullptr, nullptr, 0);
} else if (updating_graph) {
cudakernelNodeParams _dynamic_params_updated_cuda;
cudaGraphExecKernelNodeSetParams(_graph_exec, _node_list[0], &_dynamic_params_updated_cuda);
}
} cudaStream_t stream;
std::vector _node_list;
cudaGraphExec_t _graph_exec;
if (not using_graph) {
first_static_kernel>>(static_parameters);
second_static_kernel>>(static_parameters);
dynamic_kernel>>(dynamic_parameters);
} else {
if (capturing_graph) {
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
first_static_kernel>>(static_parameters);
second_static_kernel>>(static_parameters);
// Get the current stream capturing graph
cudaGraph_t _capturing_graph;
cudaStreamCaptureStatus _capture_status;
const cudaGraphNode_t *_deps;
size_t _dep_count;
cudaStreamGetCaptureInfo_v2(stream, &_capture_status, nullptr &_capturing_graph, &_deps, &_dep_count);
// Manually add a new kernel node
cudaGraphNode_t new_node;
cudakernelNodeParams _dynamic_params_cuda;
cudaGraphAddKernelNode(&new_node, _capturing_graph, _deps, _dep_count, &_dynamic_params_cuda);
// ... and store the new node for future references
_node_list.push_back(new_node);
// Update the stream dependencies
cudaStreamUpdateCaptureDependencies(stream, &new_node, 1, 1);
// End the capture and instantiate the graph
cudaGraph_t _captured_graph;
cudaStreamEndCapture(stream, &_captured_graph);
cudaGraphInstantiate(&_graph_exec, _captured_graph, nullptr, nullptr, 0);
} else if (updating_graph) {
cudakernelNodeParams _dynamic_params_updated_cuda;
cudaGraphExecKernelNodeSetParams(_graph_exec, _node_list[0], &_dynamic_params_updated_cuda);
}
}
cudaStream_t stream;
std::vector _node_list;
cudaGraphExec_t _graph_exec;
if (not using_graph) {
first_static_kernel>>(static_parameters);
second_static_kernel>>(static_parameters);
dynamic_kernel>>(dynamic_parameters);
} else {
if (capturing_graph) {
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
first_static_kernel>>(static_parameters);
second_static_kernel>>(static_parameters);
// Get the current stream capturing graph
cudaGraph_t _capturing_graph;
cudaStreamCaptureStatus _capture_status;
const cudaGraphNode_t *_deps;
size_t _dep_count;
cudaStreamGetCaptureInfo_v2(stream, &_capture_status, nullptr &_capturing_graph, &_deps, &_dep_count);
// Manually add a new kernel node
cudaGraphNode_t new_node;
cudakernelNodeParams _dynamic_params_cuda;
cudaGraphAddKernelNode(&new_node, _capturing_graph, _deps, _dep_count, &_dynamic_params_cuda);
// ... and store the new node for future references
_node_list.push_back(new_node);
// Update the stream dependencies
cudaStreamUpdateCaptureDependencies(stream, &new_node, 1, 1);
// End the capture and instantiate the graph
cudaGraph_t _captured_graph;
cudaStreamEndCapture(stream, &_captured_graph);
cudaGraphInstantiate(&_graph_exec, _captured_graph, nullptr, nullptr, 0);
} else if (updating_graph) {
cudakernelNodeParams _dynamic_params_updated_cuda;
cudaGraphExecKernelNodeSetParams(_graph_exec, _node_list[0], &_dynamic_params_updated_cuda);
}
}
In this example, cudaStreamGetCaptureInfo_v2 extracts the CUDA graph that is currently being recorded and captured into. A kernel node is added to this graph with the node handle (new_node) returned and stored, before cudaStreamUpdateCaptureDependencies is called to update the dependency tree of the current capturing stream. The last step is necessary to ensure that any other activities captured afterward have their dependencies set on these manually added nodes correctly.
With this approach, the same instantiated graph (cudaGraphExec_t object) can be reused directly with a lightweight cudaGraphExecKernelNodeSetParams call, even though the parameters are dynamic. The first image in this post shows this usage.
Furthermore, the capture and update code paths can be combined into one piece of code that lives next to the original code that launches the last two kernels. This inflicts a minimal number of code changes and does not break the original control flow and function call structure.
The new approach is shown in detail in the hummingtree/cuda-graph-with-dynamic-parameters standalone code example. cudaStreamGetCaptureInfo_v2 and cudaStreamUpdateCaptureDependencies are new CUDA runtime APIs introduced in CUDA 11.3.
Performance results
Using the hummingtree/cuda-graph-with-dynamic-parameters standalone code example, I measured the performance of running the same dynamic workflow that is bound by kernel launch overhead with three different approaches:
Running without CUDA graph acceleration
Running CUDA graph with the recapture-then-update approach
Running CUDA graph with the combined approach introduced in this post
Table 1 shows the results. The speedup from the approaches mentioned in this post strongly depends on the underlying workflow.
Approach
Time
Speedup over no graph
Combined
433 ms
1.63
Recapture-then-update
580 ms
1.22
No CUDA Graph
706 ms
1.00
Table 1. Performance results of running on an A100-40GB GPU and Intel Xeon Silver 4110 CPU at 2.10GHz
Conclusion
In this post, I introduced an approach to constructing CUDA graphs that combines both the explicit API and stream capture methods. It provides a way to reuse instantiated graphs for workflows with dynamic parameters at minimal cost.
In addition to the CUDA technical posts mentioned earlier, the CUDA Graph section of the CUDA Programming Guide provides a comprehensive introduction to CUDA Graphs and its usages. For useful tips on employing CUDA Graphs in various applications, see the Nearly Effortless CUDA Graphs GTC session.
Posted by Yilin Wang, Staff Software Engineer, YouTube and Feng Yang, Senior Staff Software Engineer, Google Research
Online video sharing platforms, like YouTube, need to understand perceptual video quality (i.e., a user’s subjective perception of video quality) in order to better optimize and improve user experience. Video quality assessment (VQA) attempts to build a bridge between video signals and perceptual quality by using objective mathematical models to approximate the subjective opinions of users. Traditional video quality metrics, like peak signal-to-noise ratio (PSNR) and Video Multi-Method Assessment Fusion (VMAF), are reference-based and focus on the relative difference between the target and reference videos. Such metrics, which work best on professionally generated content (e.g., movies), assume the reference video is of pristine quality and that one can induce the target video’s absolute quality from the relative difference.
However, the majority of the videos that are uploaded on YouTube are user-generated content (UGC), which bring new challenges due to their remarkably high variability in video content and original quality. Most UGC uploads are non-pristine and the same amount of relative difference could imply very different perceptual quality impacts. For example, people tend to be less sensitive to the distortions of poor quality uploads than of high quality uploads. Thus, reference-based quality scores become inaccurate and inconsistent when used for UGC cases. Additionally, despite the high volume of UGC, there are currently limited UGC video quality assessment (UGC-VQA) datasets with quality labels. Existing UGC-VQA datasets are either small in size (e.g., LIVE-Qualcomm has 208 samples captured from 54 unique scenes), compared with datasets with millions of samples for classification and recognition (e.g., ImageNet and YouTube-8M), or don’t have enough content variability (sampling without considering content information, like LIVE-VQC and KoNViD-1k).
In “Rich Features for Perceptual Quality Assessment of UGC Videos“, published at CVPR 2021, we describe how we attempt to solve the UGC quality assessment problem by building a Universal Video Quality (UVQ) model that resembles a subjective quality assessment. The UVQ model uses subnetworks to analyze UGC quality from high-level semantic information to low-level pixel distortions, and provides a reliable quality score with rationale (leveraging comprehensive and interpretable quality labels). Moreover, to advance UGC-VQA and compression research, we enhance the open-sourced YouTube-UGC dataset, which contains 1.5K representative UGC samples from millions of UGC videos (distributed under the Creative Commons license) on YouTube. The updated dataset contains ground-truth labels for both original videos and corresponding transcoded versions, enabling us to better understand the relationship between video content and its perceptual quality.
Subjective Video Quality Assessment To understand perceptual video quality, we leverage an internal crowd-sourcing platform to collect mean opinion scores (MOS) with a scale of 1–5, where 1 is the lowest quality and 5 is the highest quality, for no-reference use cases. We collect ground-truth labels from the YouTube-UGC dataset and categorize UGC factors that affect quality perception into three high-level categories: (1) content, (2) distortions, and (3) compression. For example, a video with no meaningful content won’t receive a high quality MOS. Also, distortions introduced during the video production phase and video compression artifacts introduced by third-party platforms, e.g., transcoding or transmission, will degrade the overall quality.
MOS= 2.052
MOS= 4.457
Left: A video with no meaningful content won’t receive a high quality MOS. Right: A video displaying intense sports shows a higher MOS.
MOS= 1.242
MOS= 4.522
Left: A blurry gaming video gets a very low quality MOS. Right: A video with professional rendering (high contrast and sharp edges, usually introduced in the video production phase) shows a high quality MOS.
MOS= 2.372
MOS= 4.646
Left: A heavily compressed video receives a low quality MOS. Right: a video without compression artifacts shows a high quality MOS.
We demonstrate that the left gaming video in the second row of the figure above has the lowest MOS (1.2), even lower than the video with no meaningful content. A possible explanation is that viewers may have higher video quality expectations for videos that have a clear narrative structure, like gaming videos, and the blur artifacts significantly reduce the perceptual quality of the video.
UVQ Model Framework A common method for evaluating video quality is to design sophisticated features, and then map these features to a MOS. However, designing useful handcrafted features is difficult and time-consuming, even for domain experts. Also, the most useful existing handcrafted features were summarized from limited samples, which may not perform well on broader UGC cases. In contrast, machine learning is becoming more prominent in UGC-VQA because it can automatically learn features from large-scale samples.
A straightforward approach is to train a model from scratch on existing UGC quality datasets. However, this may not be feasible as there are limited quality UGC datasets. To overcome this limitation, we apply a self-supervised learning step to the UVQ model during training. This self-supervised step enables us to learn comprehensive quality-related features, without ground-truth MOS, from millions of raw videos.
Following the quality-related categories summarized from the subjective VQA, we develop the UVQ model with four novel subnetworks. The first three subnetworks, which we call ContentNet, DistortionNet and CompressionNet, are used to extract quality features (i.e., content, distortion and compression), and the fourth subnetwork, called AggregationNet, maps the extracted features to generate a single quality score. ContentNet is trained in a supervised learning fashion with UGC-specific content labels that are generated by the YouTube-8M model. DistortionNet is trained to detect common distortions, e.g., Gaussian blur and white noise of the original frame. CompressionNet focuses on video compression artifacts, whose training data are videos compressed with different bitrates. CompressionNet is trained using two compressed variants of the same content that are fed into the model to predict corresponding compression levels (with a higher score for more noticeable compression artifacts), with the implicit assumption that the higher bitrate version has a lower compression level.
The ContentNet, DistortionNet and CompressionNet subnetworks are trained on large-scale samples without ground-truth quality scores. Since video resolution is also an important quality factor, the resolution-sensitive subnetworks (CompressionNet and DistortionNet) are patch-based (i.e., each input frame is divided into multiple disjointed patches that are processed separately), which makes it possible to capture all detail on native resolution without downscaling. The three subnetworks extract quality features that are then concatenated by the fourth subnetwork, AggregationNet, to predict quality scores with domain ground-truth MOS from YouTube-UGC.
The UVQ training framework.
Analyzing Video Quality with UVQ After building the UVQ model, we use it to analyze the video quality of samples pulled from YouTube-UGC and demonstrate that its subnetworks can provide a single quality score along with high-level quality indicators that can help us understand quality issues. For example, DistortionNet detects multiple visual artifacts, e.g., jitter and lens blur, for the middle video below, and CompressionNet detects that the bottom video has been heavily compressed.
ContentNet assigns content labels with corresponding probabilities in parentheses, i.e., car (0.58), vehicle (0.42), sports car (0.32), motorsports (0.18), racing (0.11).
DistortionNet detects and categorizes multiple visual distortions with corresponding probabilities in parentheses, i.e., jitter (0.112), color quantization (0.111), lens blur (0.108), denoise (0.107).
CompressionNet detects a high compression level of 0.892 for the video above.
Additionally, UVQ can provide patch-based feedback to locate quality issues. Below, UVQ reports that the quality of the first patch (patch at time t = 1) is good with a low compression level. However, the model identifies heavy compression artifacts in the next patch (patch at time t = 2).
Patch at time t = 1
Patch at time t = 2
Compression level = 0.000
Compression level = 0.904
UVQ detects a sudden quality degradation (high compression level) for a local patch.
In practice, UVQ can generate a video diagnostic report that includes a content description (e.g., strategy video game), distortion analysis (e.g., the video is blurry or pixelated) and compression level (e.g., low or high compression). Below, UVQ reports that the content quality, looking at individual features, is good, but the compression and distortion quality is low. When combining all three features, the overall quality is medium-low. We see that these findings are close to the rationale summarized by internal user experts, demonstrating that UVQ can reason through quality assessments, while providing a single quality score.
UVQ diagnostic report. ContentNet (CT): Video game, strategy video game, World of Warcraft, etc. DistortionNet (DT): multiplicative noise, Gaussian blur, color saturation, pixelate, etc. CompressionNet (CP): 0.559 (medium-high compression). Predicted quality score in [1, 5]: (CT, DT, CP) = (3.901, 3.216, 3.151), (CT+DT+CP) = 3.149 (medium-low quality).
Conclusion We present the UVQ model, which generates a report with quality scores and insights that can be used to interpret UGC video perceptual quality. UVQ learns comprehensive quality related features from millions of UGC videos and provides a consistent view of quality interpretation for both no-reference and reference cases. To learn more, read our paper or visit our website to see YT-UGC videos and their subjective quality data. We also hope that the enhanced YouTube-UGC dataset enables more research in this space.
Acknowledgements This work was possible through a collaboration spanning several Google teams. Key contributors include: Balu Adsumilli, Neil Birkbeck, Joong Gon Yim from YouTube and Junjie Ke, Hossein Talebi, Peyman Milanfar from Google Research. Thanks to Ross Wolf, Jayaprasanna Jayaraman, Carena Church, and Jessie Lin for their contributions.

 Join NVIDIA at the 16th annual ACM Conference on Recommender Systems (RecSys 2022) to see how recommender systems are driving our future.
Join NVIDIA at the 16th annual ACM Conference on Recommender Systems (RecSys 2022) to see how recommender systems are driving our future.






 Learn about the latest RTX and neural rendering technologies and how they are accelerating game development.
Learn about the latest RTX and neural rendering technologies and how they are accelerating game development. NVIDIA Grace CPU is the first data center CPU developed by NVIDIA. It has been built from the ground up to create the world’s first superchips. Designed…
NVIDIA Grace CPU is the first data center CPU developed by NVIDIA. It has been built from the ground up to create the world’s first superchips. Designed…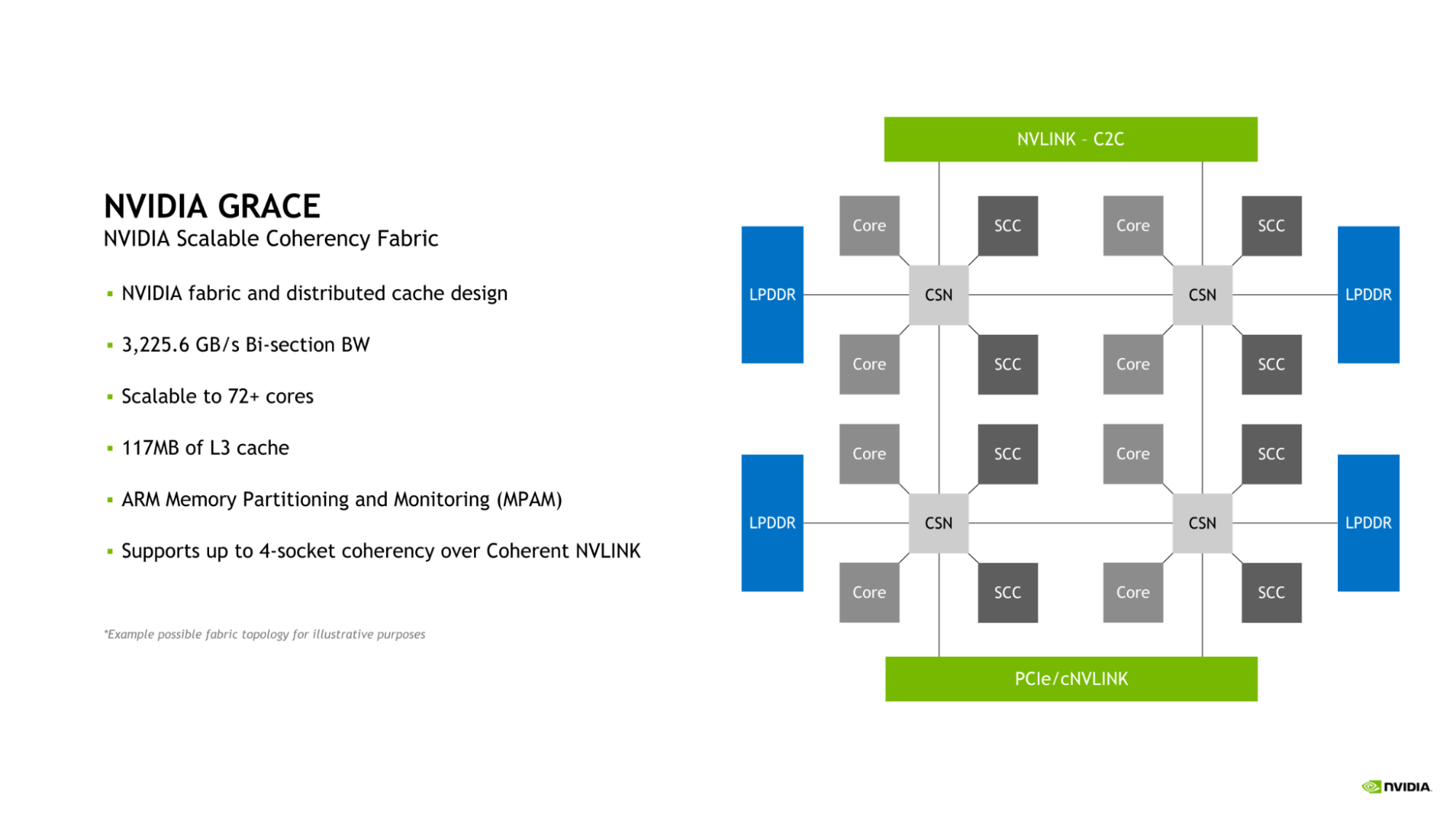
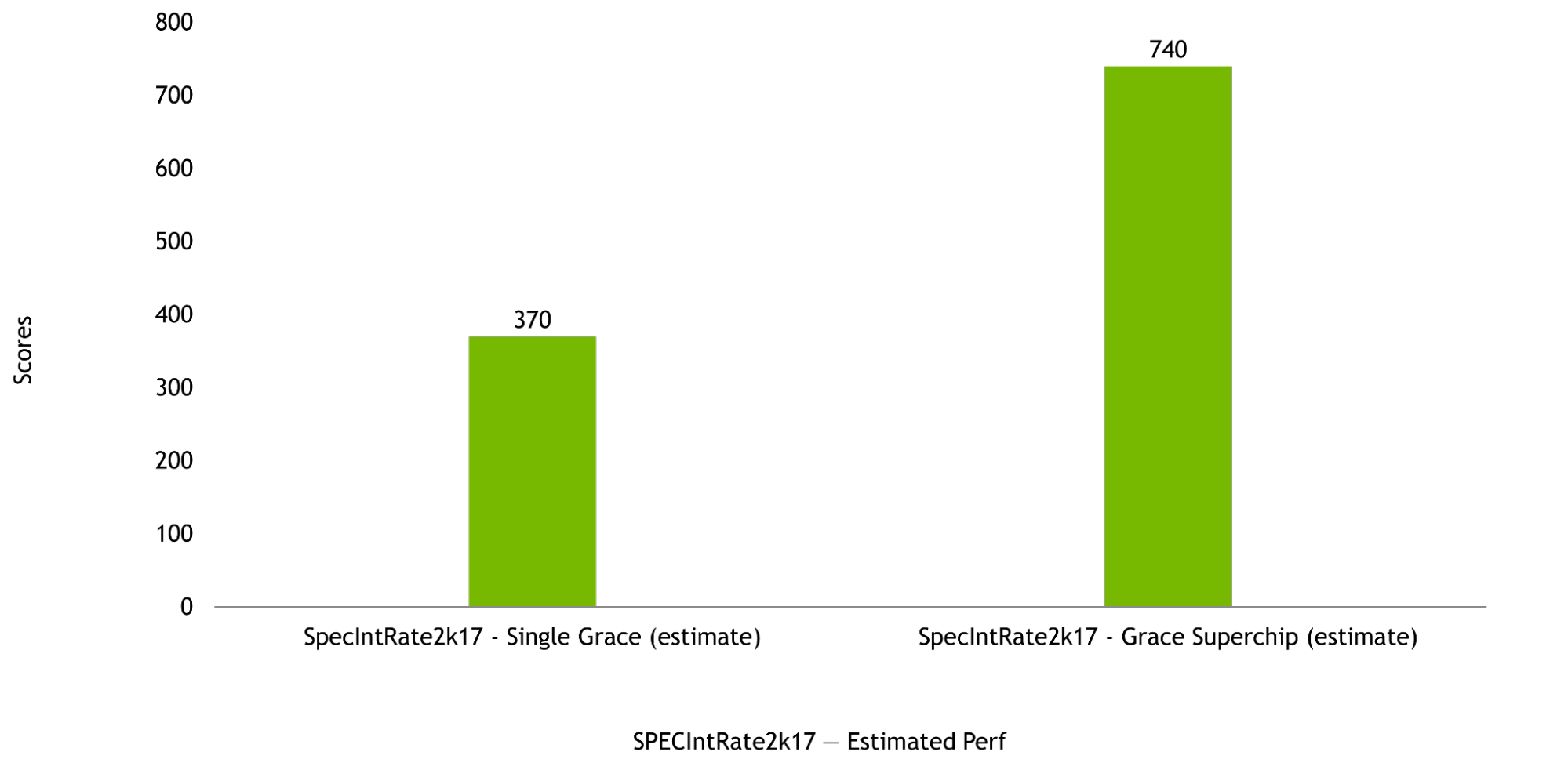
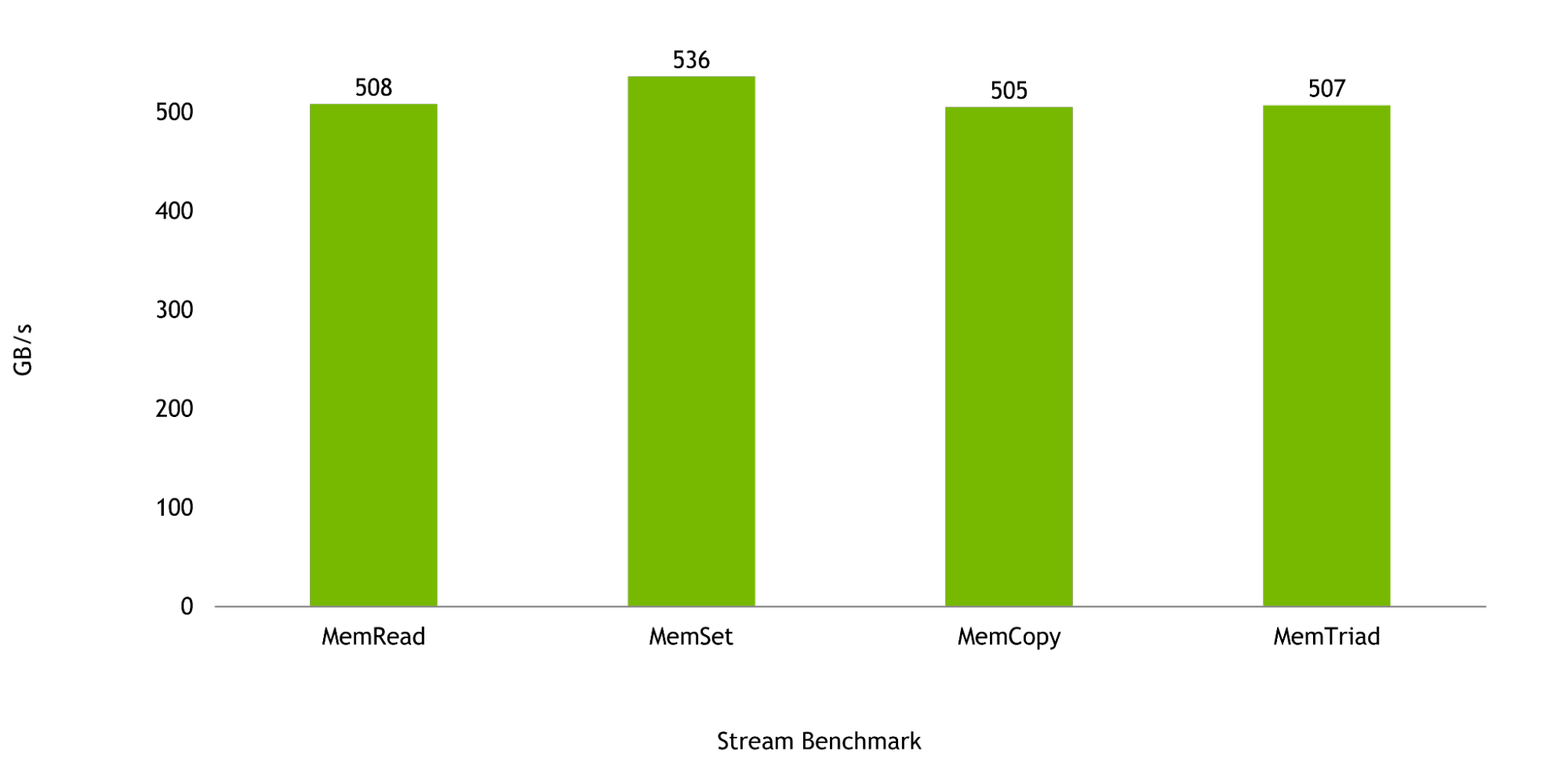
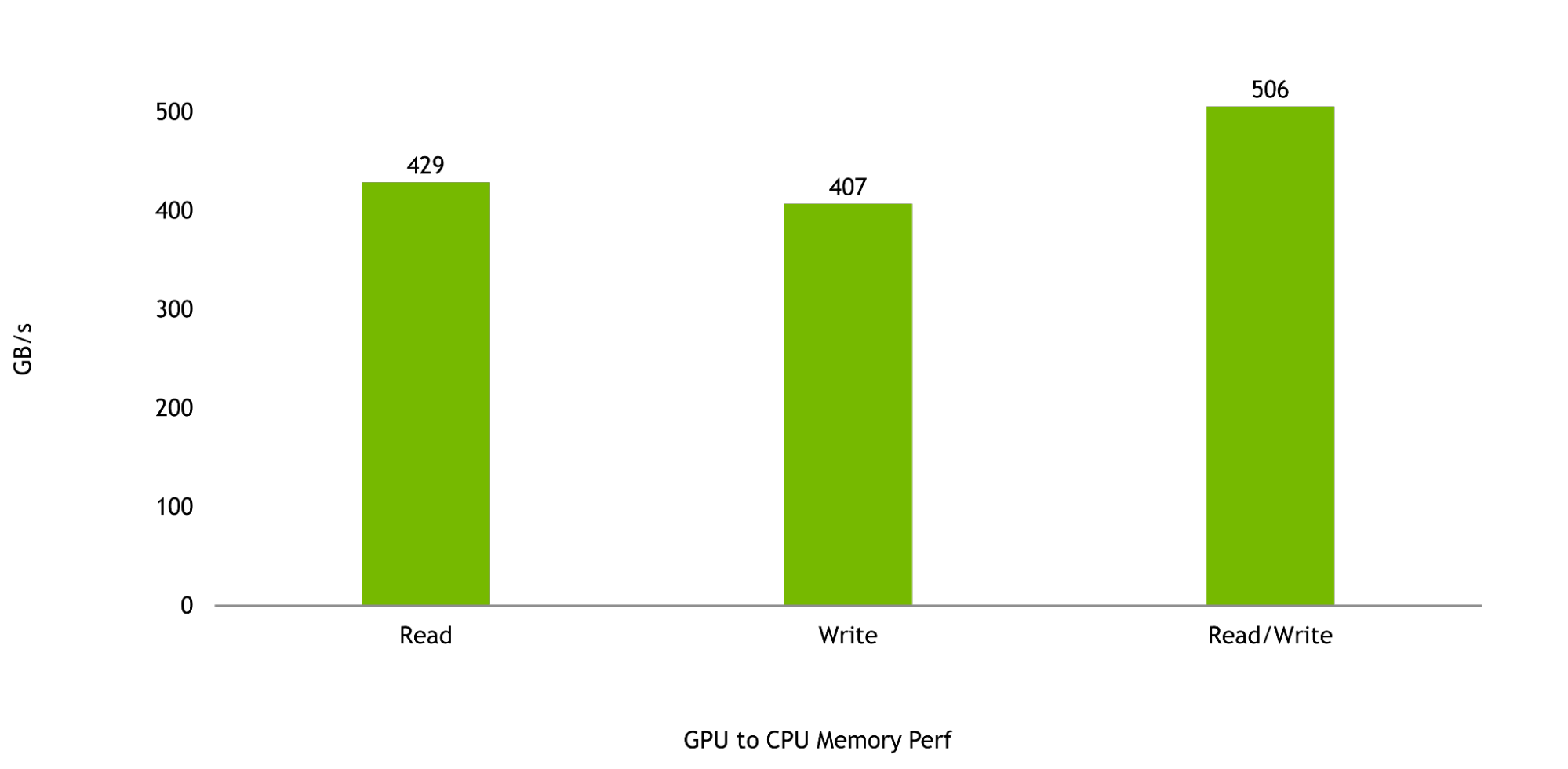
 Increasing demands in AI and high-performance computing (HPC) are driving a need for faster, more scalable interconnects with high-speed communication between…
Increasing demands in AI and high-performance computing (HPC) are driving a need for faster, more scalable interconnects with high-speed communication between…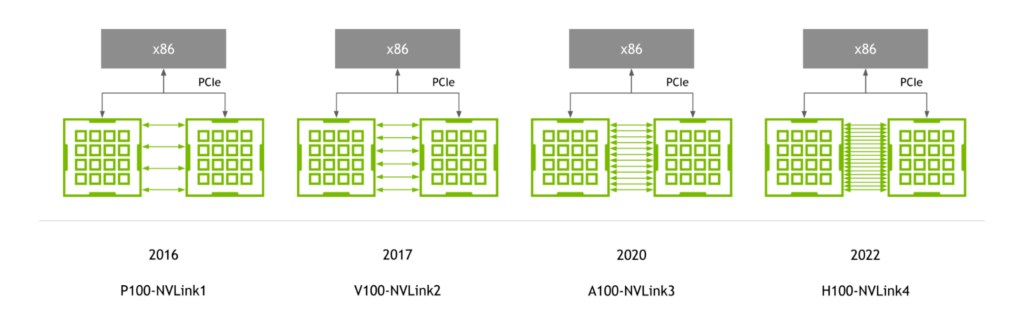
 Ever since its introduction in CUDA 10, CUDA Graphs has been used in a variety of applications. A graph groups a set of CUDA kernels and other CUDA operations…
Ever since its introduction in CUDA 10, CUDA Graphs has been used in a variety of applications. A graph groups a set of CUDA kernels and other CUDA operations…












