 Learn about the latest AI and data science breakthroughs from the world’s leading data science teams at GTC 2022.
Learn about the latest AI and data science breakthroughs from the world’s leading data science teams at GTC 2022.
Learn about the latest AI and data science breakthroughs from the world’s leading data science teams at GTC 2022.
 DataBloom
DataBloomLearn about the latest AI and data science breakthroughs from the world’s leading data science teams at GTC 2022.
Learn about the latest AI and data science breakthroughs from the world’s leading data science teams at GTC 2022.
Dell PowerEdge Servers Built With NVIDIA DPUs, NVIDIA GPUs and VMware vSphere 8 to Help Enterprises Boost AI Workload Performance and Build Foundation for Zero-Trust Security; Available to …
Vanessa Rosa’s art transcends time: it merges traditional and contemporary techniques, gives new life to ancient tales and imagines possible futures.
The post Meet the Omnivore: Artist Fires Up NVIDIA Omniverse to Glaze Animated Ceramics appeared first on NVIDIA Blog.
 Sign up for the latest Speech AI news from NVIDIA. Automatic speech recognition (ASR) is becoming part of everyday life, from interacting with digital…
Sign up for the latest Speech AI news from NVIDIA. Automatic speech recognition (ASR) is becoming part of everyday life, from interacting with digital…
Sign up for the latest Speech AI news from NVIDIA.
Automatic speech recognition (ASR) is becoming part of everyday life, from interacting with digital assistants to dictating text messages. ASR research continues to progress, thanks to recent advances in:
This post first introduces common ASR applications, and then features two startups exploring unique applications of ASR as a core product capability.
Automatic speech recognition, or speech recognition, is the capability of a computer system to decipher spoken words and phrases from audio and transcribe them into written text. Developers may also refer to ASR as speech-to-text, not to be confused with text-to-speech (TTS).
The text output of an ASR system may be the final product for a speech AI interface, or a conversational AI system may consume the text.
ASR has already become the gateway to novel interactive products and services. Even now you may be able to think of brand-name systems leveraging the use cases detailed below:
Live captioning and transcription are siblings. The main distinction between the two is that captioning produces subtitles live, as needed, for video programs like streaming movies. By contrast, transcription may take place live or in batch mode, where recorded audio cuts are transcribed orders of magnitude faster than in real time.
Virtual assistants and chatbots interact with people both to help and to entertain. They can receive text-based input from users typing or from an ASR system as it recognizes and outputs a user’s words.
Assistants and bots need to issue a response to the user quickly enough, so the processing delay is imperceptible. The response might be plain text, synthesized speech, or images.
Voice commands and dictation systems are common ASR applications used by social media platforms and in the healthcare industry.
To provide a social media example, before recording a video on a mobile device, a user might speak a voice command to activate beauty filters: “Give me purple hair.” This social networking application involves an ASR-enabled subsystem that receives a user’s words in the form of a command, while the application simultaneously processes camera input and applies filters for screen display.
Dictation systems store text from speech, expanding the vocabulary of the Speech AI system beyond commands. To provide an example from the healthcare industry, a doctor dictates voice notes packed with medical terminology and names. The accurate text output can be added to a visit summary in a patient’s electronic medical record.
Beyond these common use cases, researchers and entrepreneurs are exploring a variety of unique ASR applications. The two startups featured below are developing products that use the technology in novel ways.
Creative applications of ASR are beginning to appear in education materials, especially in the form of interactive learning, for both children and adults.
Tarteel.ai is a startup that has developed a mobile app using NVIDIA Riva to aid people in reciting and memorizing the Quran. (‘Tarteel’ is the term used to define the recitation of the Quran in Arabic using melodic, beautiful tones.) The app applies an ASR model fine-tuned by Tarteel to Quranic Arabic. To learn more, watch the demo video in the social media post below.
As the screenshot of the app shows, a user sees the properly recited text, presented from right to left, top to bottom. The script in green is the word just spoken by the user (the leading edge). If a mistake happens in the recitation, the incorrect or missed words are marked in red and a counter keeps track of the inaccuracies for improvement.
The user’s progress is summarized with a list of recitation errors, including links to similar passages that may help the user remember the text. Challenge modes propel the user’s studies forward.
While the app works smoothly now, Tarteel faced a tough set of initial challenges. To start, no suitable ASR model existed for Quranic Arabic, initially forcing Tarteel to try a general-purpose ASR model.
“We started with on-device speech AI frameworks, like for smartphones, but they were designed more for commands and short sentences than precise recitations,” co-founder and CEO of Tarteel Anas Abou Allaban said. “They also weren’t production-level tools—not even close.”
To overcome the challenge, Tarteel built a custom dataset to refine an existing ASR model to meet the app’s performance goals. Then, in their next prototype, the ASR model did perform with a lower word error rate (WER), but it still did not meet the app’s practical accuracy and latency requirements.
Allaban notes that he has seen 10-15% WER for some conference call transcripts, but it is another matter to see a high WER in Quranic studies. A processing latency longer than 300 milliseconds in the app “becomes very annoying,” he said.
Tarteel addressed these challenges by adjusting their ASR model in the NVIDIA NeMo framework and further optimizing its latency with TensorRT before deployment with Riva on Triton Inference Servers.
The startup Ex-human is creating hyper-realistic digital humans to interact with analog humans (you and me). Their current focus is developing a B2B digital human service for the entertainment niche, enabling the creation of chat bots or game characters with unique personalities, knowledge, and realistic speaking voices.
In the company’s Botify AI app, the AI entities include famous personalities to engage with users through verbal and graphical interactions, whether you’re typing in a smartphone chat window or using your voice. NVIDIA Riva Automatic Speech Recognition provides text input to the digital human’s natural language processing subsystems, comprised as part of a large language model (LLM).
Accurate and fast ASR is required to make virtual interactions believable. Because LLMs are compute-intensive and require ample processing resources, they could run too slowly for the interaction.
For example, Botify AI applies state-of-the-art TTS to produce a speech audio response which, in turn, drives facial animation using another AI model. The team has observed that a bot’s believable interactions with users are at their best when the turnaround time for a response is shorter than about a third of a second.
While Botify AI is working to bridge the gap between realistic videos of AI-generated humans and real humans, the Ex-human team was surprised by an analysis of their customers’ behavioral data. “They’re building their own novel anime characters,” said Artem Rodichev, founder and CEO of Ex-human.
Employing ASR models fine-tuned for the Botify AI ecosystem, users may communicate with their favorite personalities or create their own. The surprising pattern of building novel anime characters emerged in the context of uploading custom faces to bring conversation to life with a custom persona. Rodichev explained that his team needed to quickly adapt their AI models to handle, for example, mouths that are stylistically just a dot or a line.
Rodichev and the team overcame many challenges in the architecture of Ex-human through the careful choice of tools and SDKs, as well as evaluating opportunities to parallelize processing. Rodichev cautions, “Because latency is so important, we optimized our ASR model and other models with NVIDIA TensorRT and rely on Triton Inference Server.”
Are Botify AI users ready to engage with digital humans more than with analog humans? Data reveals that users spend an average of 40 minutes a day with Botify AI digital humans, texting their favorites hundreds of messages during that time.
You can start including ASR capabilities in your own designs and projects, from hands-free voice commands to real-time transcription. Advanced SDKs such as Riva see high performance in world-class accuracy, speed, latency, and ease of integration—all aligned to enable your new idea.
Try NVIDIA Riva Automatic Speech Recognition on your web browser or download the Riva Skills Quick Start Guide.
 Doctors could soon evaluate Parkinson’s disease by having patients do one simple thing—sleep. A new study led by MIT researchers trains a neural network to…
Doctors could soon evaluate Parkinson’s disease by having patients do one simple thing—sleep. A new study led by MIT researchers trains a neural network to…
Doctors could soon evaluate Parkinson’s disease by having patients do one simple thing—sleep. A new study led by MIT researchers trains a neural network to analyze a person’s breathing patterns while sleeping and determine whether the subject has Parkinson’s. Recently published in Nature Medicine, the work could lead to earlier detection and treatment.
“Our goal was to create a method for detecting and assessing Parkinson’s disease in a reliable and convenient way. Inspired by the connections between Parkinson’s and breathing signals, which are high-dimensional and complex, a natural choice was to use the power of machine learning to diagnose and track the progression,” said lead author Yuzhe Yang, a PhD student at MIT’s Computer Science & Artificial Intelligence Laboratory.
While notoriously difficult to pinpoint, Parkinson’s has become the fastest-growing neurological disease globally. About one million people in the US and 10 million worldwide are living with it. Despite these numbers, there isn’t one specific test for a speedy or definitive diagnosis.
As a progressive disorder, Parkinson’s often begins with subtle symptoms such as a slight hand tremor. It affects the nervous system and eventually leads to uncontrollable movements, shaking, stiffness while walking, and balance issues. Over time speech can become slurred and facial expressions fade away.
Neurologists often review a patient’s symptoms and medical history and rely on ruling out other illnesses based on imaging and lab work before diagnosing Parkinson’s. But symptoms vary and mimic several other disorders, which can lead to misdiagnosis and a delay in medical treatment. Early detection could help patients receive medications that are more effective when administered during the onset of Parkinson’s.
According to the authors, a correlation between nocturnal breathing and Parkinson’s was noted in 1817 by James Parkinson. A British medical doctor, he was the first to describe six individuals with symptoms of the disease he called paralysis agitans, which was later renamed.
Other research also found that brain stem degeneration in areas controlling patient breath occurs years earlier than motor skills symptoms and could be an early indicator of the disease.
The researchers saw an opportunity to employ AI, a powerful tool for detecting patterns and helping with disease diagnosis. They trained a neural network to analyze breathing patterns and learn those indicative of Parkinson’s.
The study dataset sampled 757 Parkinson’s patients and 6,914 control subjects, totaling 120,000 hours of sleep over 11,964 nights. The team trained the neural network model on several NVIDIA TITAN Xp GPUs using the cuDDN-accelerated PyTorch deep learning framework.
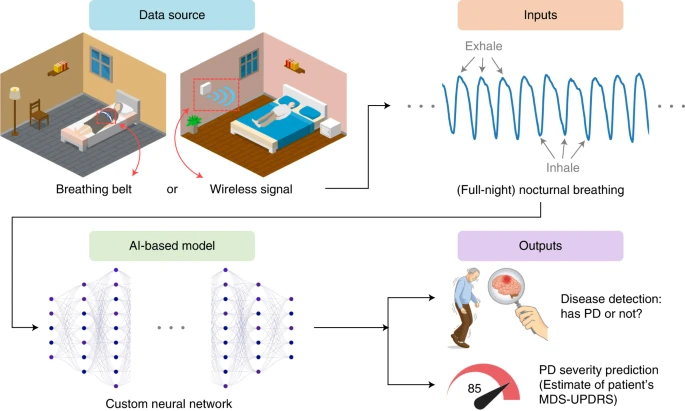
Figure 1. Overview of the AI model for Parkinson’s disease diagnosis and disease severity prediction from nocturnal breathing signals
A large amount of data came from a wireless radio transmitter the researchers developed. Similar in appearance to a Wi-Fi router the device emits radio waves and captures changes in the environment, which includes the rise and fall of a person’s chest. A neural network analyzes the patterns and determines whether Parkinson’s is present in the sample.
The AI model, deployed using NVIDIA TITAN Xp GPUs, is nearly 80% accurate in detecting Parkinson’s cases and 82% accurate in making a negative diagnosis. The algorithms can also determine the severity of Parkinson’s and track disease progression over time.
The work has the potential to speed up drug development with the newly found digital biomarkers for both diagnostics and tracking progression. Using AI models capable of detecting subtle patient changes and responses to new therapeutics could accelerate clinical trials, reduce costs, and inform more effective treatments.
It could also offer more accessible and equitable health care options to people beyond urban centers where specialists often practice medicine.
According to Yang, the team hopes to make the model more robust and accurate by collecting and testing data on more diverse populations and patients globally. They also envision use cases for the model to detect diseases beyond Parkinson’s.
“We believe there are chances to apply the method to detect other neurological diseases, for example, Alzheimer’s disease. The key problem is we need to collect a large and diverse dataset to carry out model training and evaluation for rigorous validation,” said Yang.
Contact pd-breathing@mit.edu for information about access to the code for noncommercial purposes.
Read the research Artificial intelligence-enabled detection and assessment of Parkinson’s disease using nocturnal breathing signals.
 Every AI application needs a strong inference engine. Whether you’re deploying an image recognition service, intelligent virtual assistant, or a fraud…
Every AI application needs a strong inference engine. Whether you’re deploying an image recognition service, intelligent virtual assistant, or a fraud…
Every AI application needs a strong inference engine. Whether you’re deploying an image recognition service, intelligent virtual assistant, or a fraud detection application, a reliable inference server delivers fast, accurate, and scalable predictions with low latency (low response time to a single query) and strong throughput (large number of queries processed in a given time interval). Yet, checking all these boxes can be difficult and expensive to achieve.
Teams need to consider deploying applications that can leverage:
These requirements can make AI inference an extremely challenging task, which can be simplified with NVIDIA Triton Inference Server.
This post provides a step-by-step tutorial for boosting your AI inference performance on Azure Machine Learning using NVIDIA Triton Model Analyzer and ONNX Runtime OLive, as shown in Figure 1.
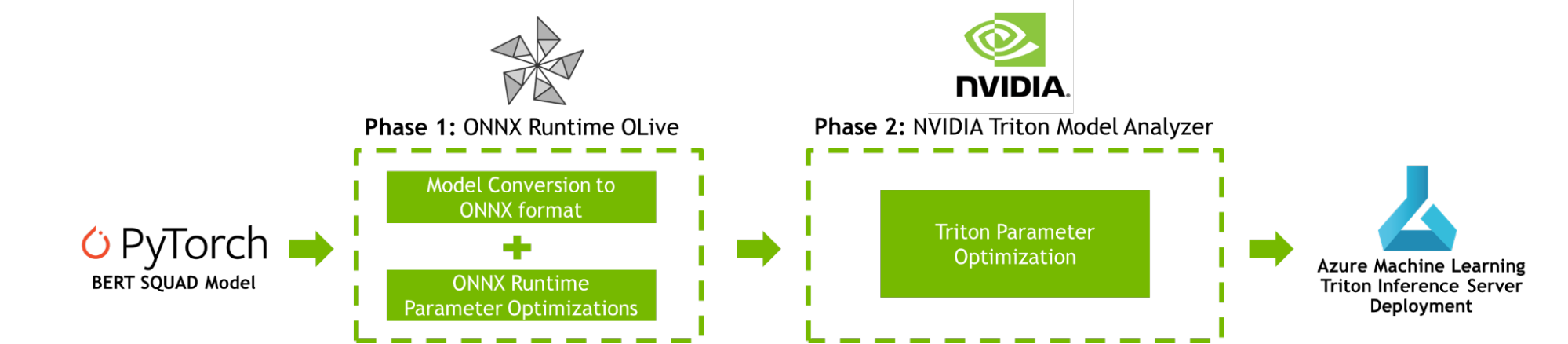
To improve AI inference performance, both ONNX Runtime OLive and Triton Model Analyzer automate the parameter optimization steps prior to model deployment. These parameters define how the underlying inference engine will perform. You can use these tools to optimize the ONNX Runtime parameters (execution provider, session options, and precision parameters), and the Triton parameters (dynamic batching and model concurrency parameters).
If Azure Machine Learning is where you deploy AI applications, you may be familiar with ONNX Runtime. ONNX Runtime is Microsoft’s high-performance inference engine to run AI models across platforms. It can deploy models across numerous configuration settings and is now supported in Triton. Fine-tuning these configuration settings requires dedicated time and domain expertise.
OLive (ONNX Runtime Go Live) is a Python package that speeds up this process by automating the work of accelerating models with ONNX Runtime. It offers two capabilities: converting models to ONNX format and auto-tuning ONNX Runtime parameters to maximize inference performance. Running OLive will isolate and recommend ONNX Runtime configuration settings for the optimal core AI inference results.
You can optimize an ONNX Runtime BERT SQuAD model with OLive using the following ONNX Runtime parameters:
inter_op_num_threads, intra_op_num_threads, execution_mode, and graph_optimization_level.float32 and float16, and returns the optimal precision configuration.After running through the optimizations, you still may be leaving some performance on the table at application level. The end-to-end throughput and latency can be further improved using the Triton Model Analyzer, which is capable of supporting optimized ONNX Runtime models.
NVIDIA Triton Inference Server is an open-source inference serving software that helps standardize model deployment and execution and delivers fast and scalable AI inferencing in production. Figure 2 shows how the Triton Inference Server manages client requests when integrated with client applications and multiple AI models.
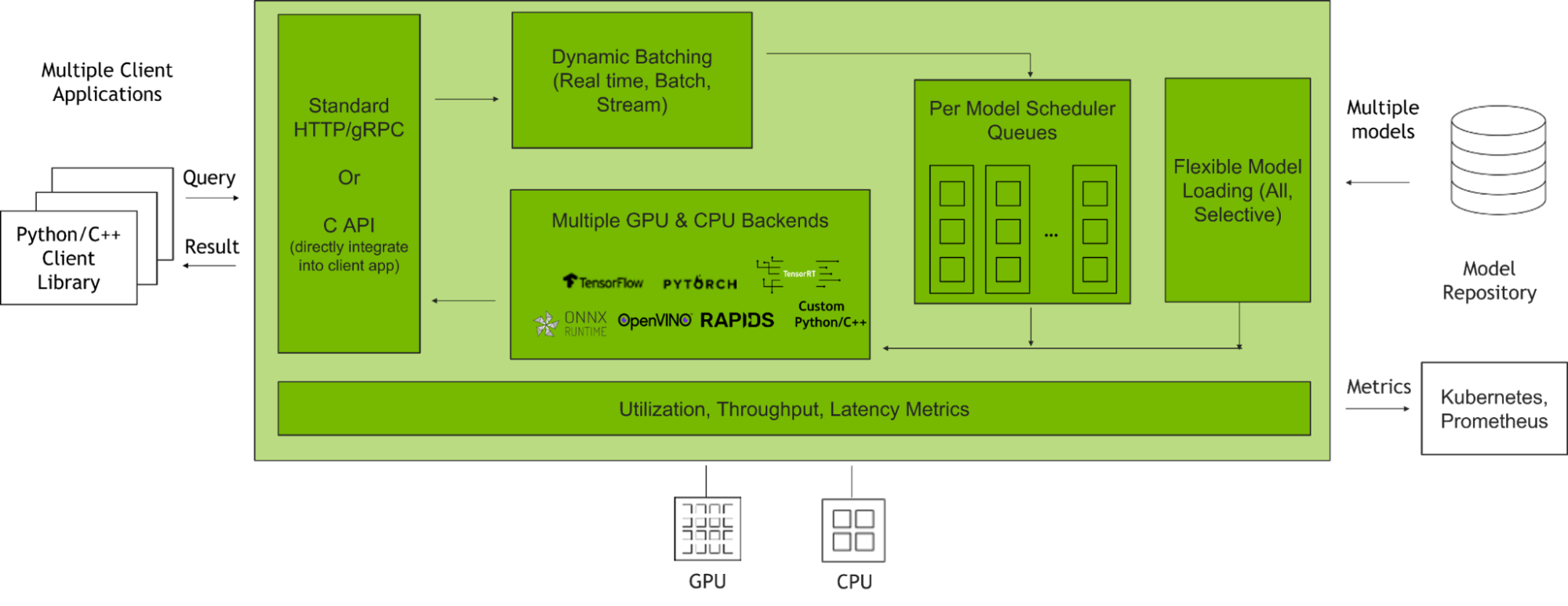
This post will focus on optimizing two major Triton features with Triton Model Analyzer:
These features are extremely powerful when deployed at optimal levels. When deployed with suboptimal configurations, performance is compromised, leaving end applications vulnerable to current demanding quality-of-service standards (latency, throughput, and memory requirements).
As a result, optimizing batch size and model concurrency levels based on expected user traffic is critical to unlock the full potential of Triton. These optimized model configuration settings will generate improved throughput under strict latency constraints, boosting GPU utilization when the application is deployed. This process can be automated using the Triton Model Analyzer.
Given a set of constraints including latency, throughput targets, or memory footprints, Triton Model Analyzer searches for and selects the best model configuration that maximizes inference performance based on different levels for batch size, model concurrency, or other Triton model configuration settings. When these features are deployed and optimized, you can expect to see incredible results.
Four steps are required to deploy optimized machine learning models with ONNX Runtime OLive and Triton Model Analyzer on Azure Machine Learning:
To work through this tutorial, ensure you have an Azure account with access to NVIDIA GPU-powered virtual machines. For example, use Azure ND A100 v4-series VMs for NVIDIA A100 GPUs, NCasT4 v3-series for NVIDIA T4 GPUs, or NCv3-series for NVIDIA V100 GPUs. While the ND A100 v4-series is recommended for maximum performance at scale, this tutorial uses a standard NC6s_v3 virtual machine using a single NVIDIA V100 GPU.
This tutorial uses the NVIDIA GPU-optimized VMI available on the Azure Marketplace. It is preconfigured with NVIDIA GPU drivers, CUDA, Docker toolkit, Runtime, and other dependencies. Additionally, it provides a standardized stack for developers to build their AI applications.
To maximize performance, this VMI is validated and updated quarterly by NVIDIA with the newest drivers, security patches, and support for the latest GPUs.
For more details on how to launch and connect to the NVIDIA GPU-optimized VMI on your Azure VM, refer to the NGC on Azure Virtual Machines documentation.
Once you have connected to your Azure VM using SSH with the NVIDIA GPU-optimized VMI loaded, you are ready to begin executing ONNX Runtime OLive and Triton Model Analyzer optimizations.
First, clone the GitHub Repository and navigate to the content root directory by running the following commands:
git clone https://github.com/microsoft/OLive.gitcd OLive/olive-model_analyzer-azureMLNext, load the Triton Server container. Note that this tutorial uses the version number 22.06.
docker run --gpus=1 --rm -it -v “$(pwd)”:/models nvcr.io/nvidia/tritonserver:22.06-py3 /bin/bashOnce loaded, navigate to the /models folder where the GitHub material is mounted:
cd /models Download the OLive and ONNX Runtime packages, along with the model you want to optimize. Then, specify the location of the model you want to optimize by setting up the following environmental variables:
You may adjust the location and file name provided above with a model of your choice. For optimal performance, download certified pretrained models directly from the NGC catalog. These models are trained to high accuracy and are available with high-level credentials and code samples.
Next, run the following script:
bash download.sh $model_location $export model_filenameThe script will download three files onto your machine:
onnxruntime_olive-0.3.0-py3-none-any.whlonnxruntime_gpu_tensorrt-1.9.0-cp38-cp38-linux_x86_64.whlbert-base-cased-squad.pthBefore running the pipeline in Figure 1, first specify its input parameters by setting up environmental variables:
model_name=bertsquadmodel_type=pytorchin_names=input_names,input_mask,segment_idsin_shapes=[[-1,256],[-1,256],[-1,256]]in_types=int64,int64,int64out_names=start,endThe parameters in_names, in_shapes, and in_types refer to the names, shapes and types of the expected inputs for the model. In this case, inputs are sequences of length 256, however they are specified as [-1,256] to allow the batching of inputs. You can change the parameters values that correspond to your model and its expected inputs and outputs.
Now, you’re ready to run the pipeline by executing the following command:
bash optimize.sh $model_filename $model_name $model_type $in_names $in_shapes $in_types $out_namesThis command first installs all necessary libraries and dependencies, and calls on OLive to convert the original model into an ONNX format.
Next, Triton Model Analyzer is called to automatically generate the model’s configuration file with the model’s metadata. The configuration file is then passed back into OLive to optimize via the ONNX Runtime parameters discussed earlier (execution provider, session options, and precision).
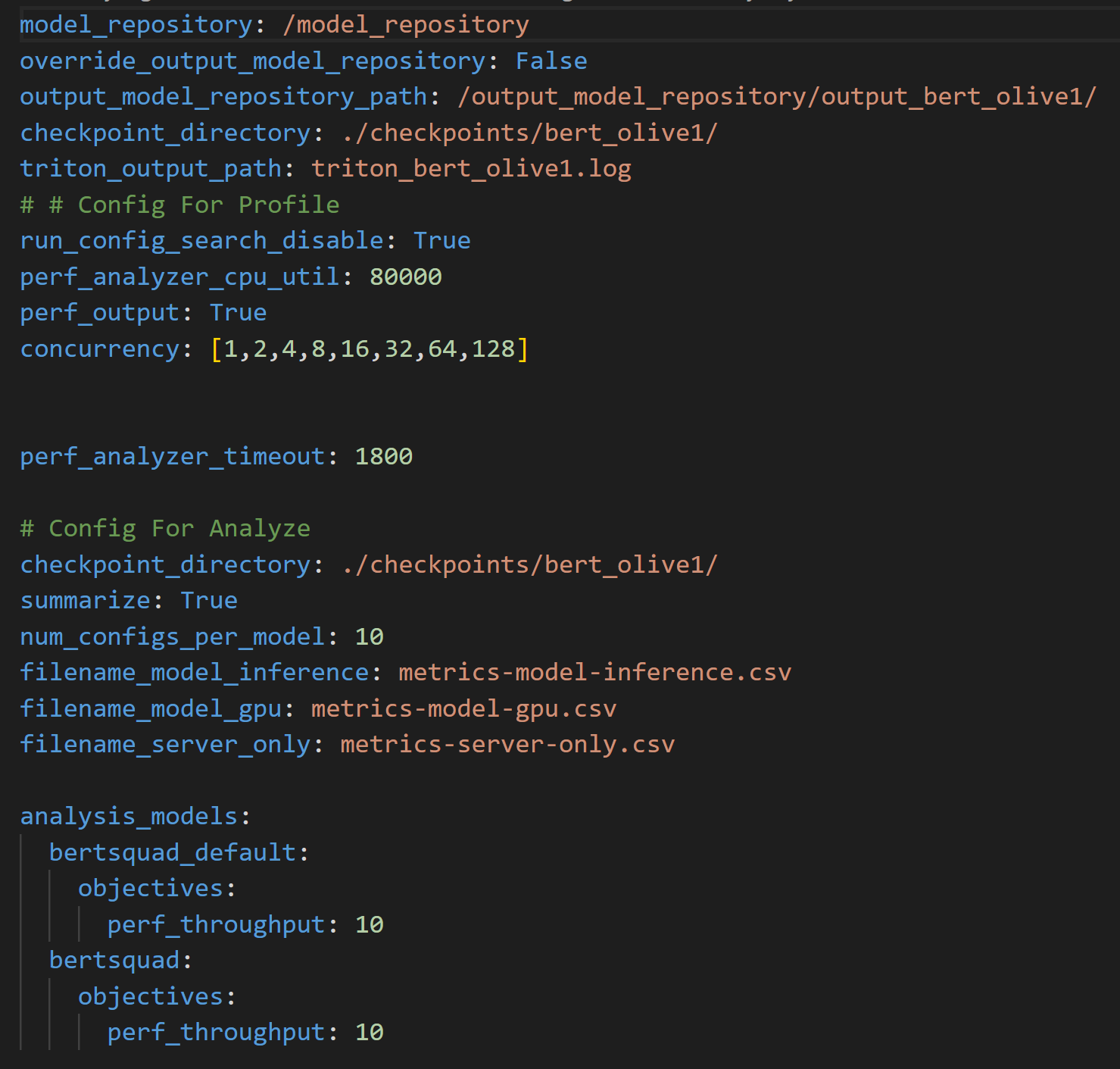
To further boost throughput and latency, the ONNX Runtime-optimized model configuration file is then passed into the Triton model repository for use by the Triton Model Analyzer tool. Triton Model Analyzer then runs the profile command, which sets up the optimization search space and specifies the location of the Triton Model repository using a .yaml configuration file (see Figure 3).
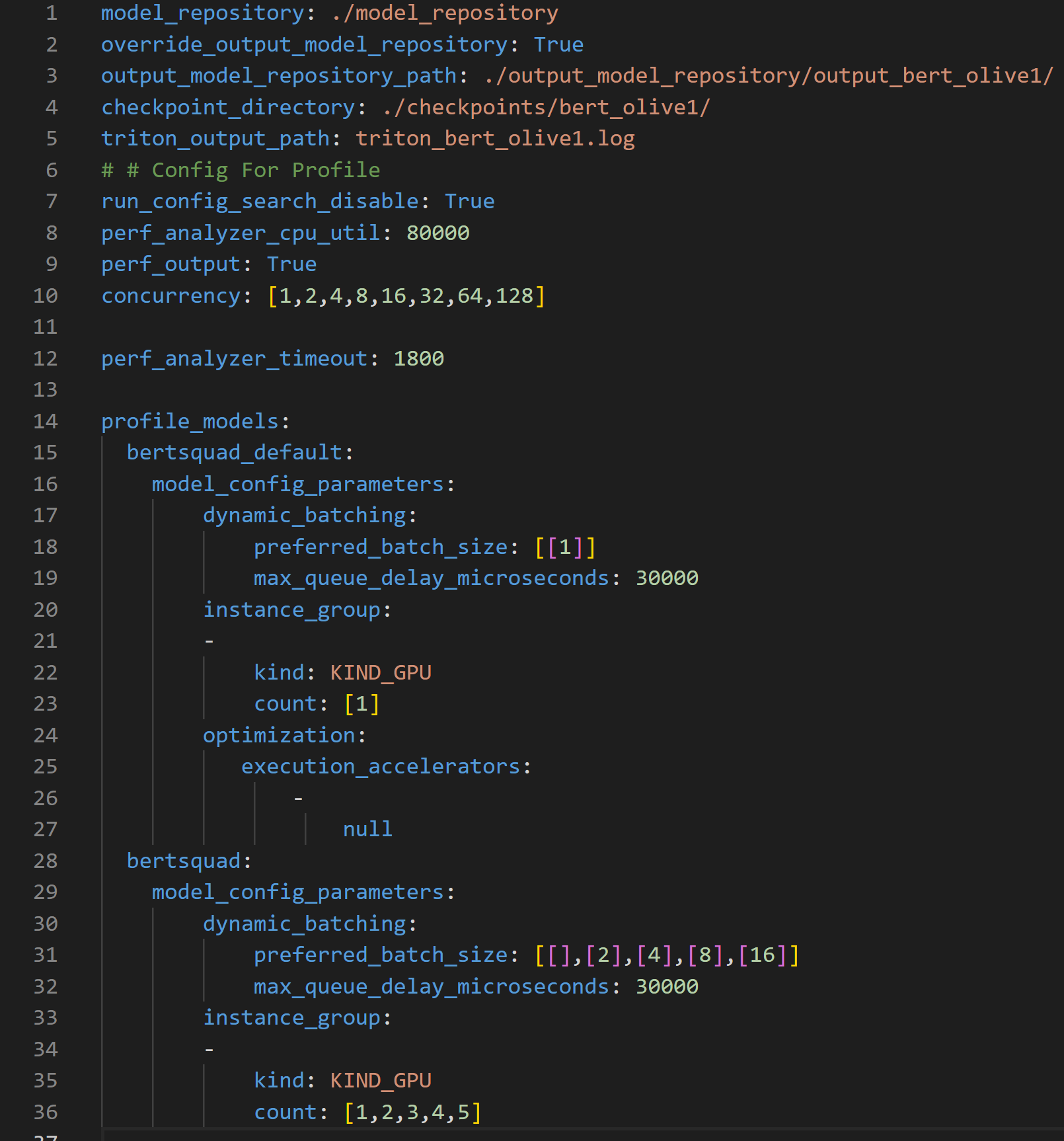
The configuration file above can be used to customize the search space for Triton Model Analyzer in a number of ways. The file requires the location of the Model Repository, parameters to optimize, and their ranges to create the search space used by Triton Model Analyzer to find the optimal configuration settings.
bert_default model, which corresponds to the default model obtained from the PyTorch to ONNX conversion. This model is the baseline model and therefore uses non-optimized values for dynamic batching (line 17) and model concurrency (line 20) bertsquad model, which corresponds to the OLive optimized model. This one differs from the bert_default model because the dynamic batching parameter search space here is set to 1, 2, 4, 8 and 16, and the model concurrency parameter search space is set to 1, 2, 3, 4 and 5. The profile command records results across each concurrent inference request level, and for each concurrent inference request level, the results are recorded for 25 different parameters since the search space for both the dynamic batching and model concurrency parameters have five unique values each, equating to a total of 25 different parameters. Note that the time needed to run this will scale with the number of configurations provided in the search space within the profile configuration file in Figure 3.
The script then runs the Triton Model Analyzer analyze command to process the results using an additional configuration file shown in Figure 4. The file specifies the location of the output model repository where the results were generated from the profile command, along with the name of the CSV files where the performance results will be recorded.
analyze command and process the results from the profile commandWhile the profile and analyze commands may take a couple of hours to run, the optimized model configuration settings will ensure strong long-term inference performance for your deployed model. For shorter run times, adjust the model profile configuration file (Figure 3) with a smaller search space across the parameters you wish to optimize.
Once the demo completes running, there should be two files produced: Optimal_Results.png as shown in Figure 5, and Optimal_ConfigFile_Location.txt, which represents the location of the optimal config file to be deployed on Azure Machine Learning. A non-optimized baseline is established (blue line). The performance boost achieved through OLive optimizations is shown (light green line), along with OLive + Triton Model Analyzer optimizations (dark green line).
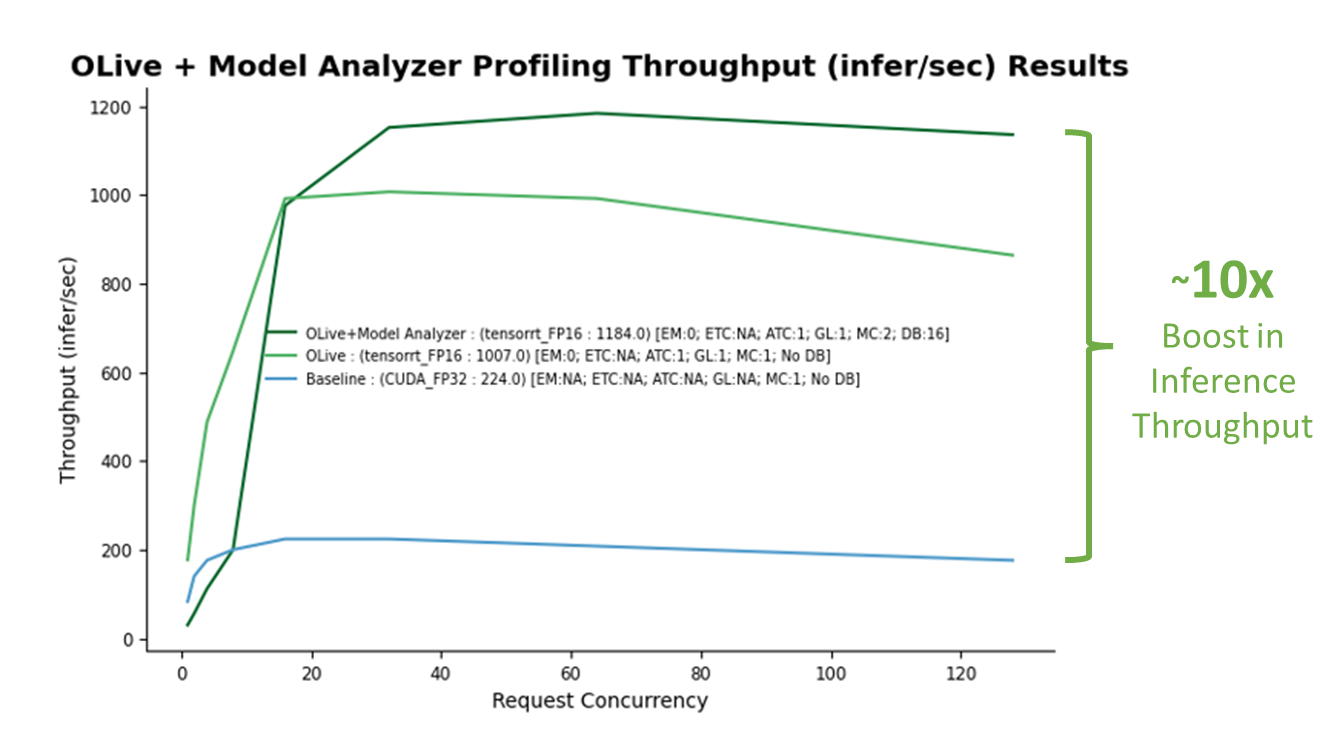
The baseline corresponds to a model with non-optimized ONNX Runtime parameters (CUDA backend with full precision) and non-optimized Triton parameters (no dynamic batching nor model concurrency). With the baseline established, it is clear there is a big boost in inference throughput performance (y-axis) obtained from both OLive and Triton Model Analyzer optimizations at various inference request concurrency levels (x-axis) emulated by Triton Perf Analyzer, a tool that mimics user traffic by generating inference requests.
OLive optimizations improved model performance (light green line) by tuning the execution provider to TensorRT with mixed precision, along with other ONNX Runtime parameters. However, this shows performance without Triton dynamic batching or model concurrency. Therefore, this model can be further optimized with Triton Model Analyzer.
Triton Model Analyzer further boosts inference performance by 20% (dark green line) after optimizing model concurrency and dynamic batching. The final optimal values selected by Triton Model Analyzer are a model concurrency of two (two copies of the BERT model will be saved on the GPU) and a maximum dynamic batching level of 16 (up to 16 inference requests will be batched together at one time).
Overall, the gain on inference performance using optimized parameters is more than 10x.
Additionally, if you are expecting certain levels of inference requests for your application, you may adjust the emulated user traffic by configuring the Triton perf_analyzer. You may also adjust the model configuration file to include additional parameters to optimize such as Delayed Batching.
You’re now ready to deploy your optimized model with Azure Machine Learning.
Deploying your optimized AI model for inference on Azure Machine Learning with Triton involves using a managed online endpoint with the Azure Machine Learning Studio no code interface.
Managed online endpoints help you deploy ML models in a turnkey manner. It takes care of serving, scaling, securing, and monitoring your models, freeing you from the overhead of setting up and managing the underlying infrastructure.
To continue, ensure you have downloaded the Azure CLI, and have at hand the YAML file shown in Figure 6.
First, register your model in Triton format using the above YAML file. Your registered model should look similar to Figure 7 as shown on the Models page of Azure Machine Learning Studio.
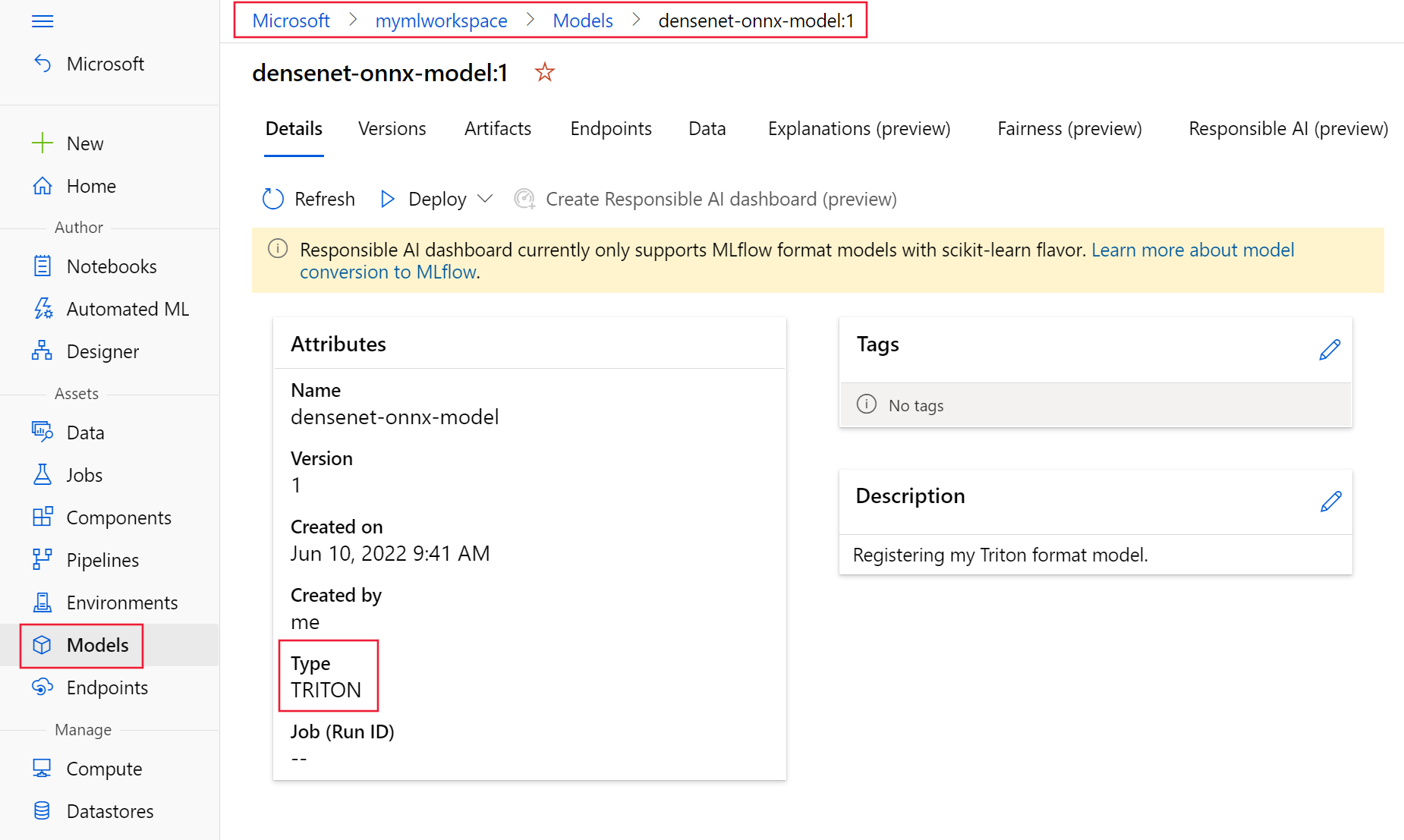
Next, select the Triton model, select ‘Deploy,’ and then ‘Deploy to real-time endpoint.’ Continue through the wizard to deploy the ONNX Runtime and Triton optimized model to the endpoint. Note that no scoring script is required when you deploy a Triton model to an Azure Machine Learning managed endpoint.
Congratulations! You have now deployed a BERT SQuAD model optimized for inference performance using ONNX Runtime and Triton parameters on Azure Machine Learning. By optimizing these parameters, you have unlocked a 10x increase in performance relative to the non-optimized baseline BERT SQuAD model.
Explore more resources about deploying AI applications with NVIDIA Triton, ONNX Runtime, and Azure Machine Learning below:
Learn how Siemens Energy and American Express have accelerated AI inference workflows with Triton. See how your company can get started with Triton using NVIDIA AI Enterprise and NVIDIA LaunchPad.
Find out how Microsoft Bing has improved BERT inference on NVIDIA GPUs for real-time service needs, serving more than one million BERT inferences per second.
") Discover the latest cybersecurity tools and trends with NVIDIA Deep Learning Institute workshops at GTC 2022.
Discover the latest cybersecurity tools and trends with NVIDIA Deep Learning Institute workshops at GTC 2022.
Discover the latest cybersecurity tools and trends with NVIDIA Deep Learning Institute workshops at GTC 2022.
In recent years video conferencing has played an increasingly important role in both work and personal communication for many users. Over the past two years, we have enhanced this experience in Google Meet by introducing privacy-preserving machine learning (ML) powered background features, also known as “virtual green screen”, which allows users to blur their backgrounds or replace them with other images. What is unique about this solution is that it runs directly in the browser without the need to install additional software.
So far, these ML-powered features have relied on CPU inference made possible by leveraging neural network sparsity, a common solution that works across devices, from entry level computers to high-end workstations. This enables our features to reach the widest audience. However, mid-tier and high-end devices often have powerful GPUs that remain untapped for ML inference, and existing functionality allows web browsers to access GPUs via shaders (WebGL).
With the latest update to Google Meet, we are now harnessing the power of GPUs to significantly improve the fidelity and performance of these background effects. As we detail in “Efficient Heterogeneous Video Segmentation at the Edge”, these advances are powered by two major components: 1) a novel real-time video segmentation model and 2) a new, highly efficient approach for in-browser ML acceleration using WebGL. We leverage this capability to develop fast ML inference via fragment shaders. This combination results in substantial gains in accuracy and latency, leading to crisper foreground boundaries.
 |
| CPU segmentation vs. HD segmentation in Meet. |
Moving Towards Higher Quality Video Segmentation Models
To predict finer details, our new segmentation model now operates on high definition (HD) input images, rather than lower-resolution images, effectively doubling the resolution over the previous model. To accommodate this, the model must be of higher capacity to extract features with sufficient detail. Roughly speaking, doubling the input resolution quadruples the computation cost during inference.
Inference of high-resolution models using the CPU is not feasible for many devices. The CPU may have a few high-performance cores that enable it to execute arbitrary complex code efficiently, but it is limited in its ability for the parallel computation required for HD segmentation. In contrast, GPUs have many, relatively low-performance cores coupled with a wide memory interface, making them uniquely suitable for high-resolution convolutional models. Therefore, for mid-tier and high-end devices, we adopt a significantly faster pure GPU pipeline, which is integrated using WebGL.
This change inspired us to revisit some of the prior design decisions for the model architecture.
 |
| HD segmentation model architecture. |
In aggregate, these changes substantially improve the mean Intersection over Union (IoU) metric by 3%, resulting in less uncertainty and crisper boundaries around hair and fingers.
We have also released the accompanying model card for this segmentation model, which details our fairness evaluations. Our analysis shows that the model is consistent in its performance across the various regions, skin-tones, and genders, with only small deviations in IoU metrics.
| Model | Resolution | Inference | IoU | Latency (ms) | ||||
| CPU segmenter | 256×144 | Wasm SIMD | 94.0% | 8.7 | ||||
| GPU segmenter | 512×288 | WebGL | 96.9% | 4.3 |
| Comparison of the previous segmentation model vs. the new HD segmentation model on a Macbook Pro (2018). |
Accelerating Web ML with WebGL
One common challenge for web-based inference is that web technologies can incur a performance penalty when compared to apps running natively on-device. For GPUs, this penalty is substantial, only achieving around 25% of native OpenGL performance. This is because WebGL, the current GPU standard for Web-based inference, was primarily designed for image rendering, not arbitrary ML workloads. In particular, WebGL does not include compute shaders, which allow for general purpose computation and enable ML workloads in mobile and native apps.
To overcome this challenge, we accelerated low-level neural network kernels with fragment shaders that typically compute the output properties of a pixel like color and depth, and then applied novel optimizations inspired by the graphics community. As ML workloads on GPUs are often bound by memory bandwidth rather than compute, we focused on rendering techniques that would improve the memory access, such as Multiple Render Targets (MRT).
MRT is a feature in modern GPUs that allows rendering images to multiple output textures (OpenGL objects that represent images) at once. While MRT was originally designed to support advanced graphics rendering such as deferred shading, we found that we could leverage this feature to drastically reduce the memory bandwidth usage of our fragment shader implementations for critical operations, like convolutions and fully connected layers. We do so by treating intermediate tensors as multiple OpenGL textures.
In the figure below, we show an example of intermediate tensors having four underlying GL textures each. With MRT, the number of GPU threads, and thus effectively the number of memory requests for weights, is reduced by a factor of four and saves memory bandwidth usage. Although this introduces considerable complexities in the code, it helps us reach over 90% of native OpenGL performance, closing the gap with native applications.
 |
| Left: A classic implementation of Conv2D with 1-to-1 correspondence of tensor and an OpenGL texture. Red, yellow, green, and blue boxes denote different locations in a single texture each for intermediate tensor A and B. Right: Our implementation of Conv2D with MRT where intermediate tensors A and B are realized with a set of 4 GL textures each, depicted as red, yellow, green, and blue boxes. Note that this reduces the request count for weights by 4x. |
Conclusion
We have made rapid strides in improving the quality of real-time segmentation models by leveraging the GPU on mid-tier and high-end devices for use with Google Meet. We look forward to the possibilities that will be enabled by upcoming technologies like WebGPU, which bring compute shaders to the web. Beyond GPU inference, we’re also working on improving the segmentation quality for lower powered devices with quantized inference via XNNPACK WebAssembly.
Acknowledgements
Special thanks to those on the Meet team and others who worked on this project, in particular Sebastian Jansson, Sami Kalliomäki, Rikard Lundmark, Stephan Reiter, Fabian Bergmark, Ben Wagner, Stefan Holmer, Dan Gunnarsson, Stéphane Hulaud, and to all our team members who made this possible: Siargey Pisarchyk, Raman Sarokin, Artsiom Ablavatski, Jamie Lin, Tyler Mullen, Gregory Karpiak, Andrei Kulik, Karthik Raveendran, Trent Tolley, and Matthias Grundmann.
Looking for a change of art? Try using AI — that’s what 3D artist Nikola Damjanov is doing. Based in Serbia, Damjanov has over 15 years of experience in the graphics industry, from making 3D models and animations to creating high-quality visual effects for music videos and movies. Now an artist at game developer company Read article >
The post 3D Artist Creates Blooming, Generative Sculptures With NVIDIA RTX and AI appeared first on NVIDIA Blog.
 Expert-led, hands-on conversational AI workshops at GTC 2022 are just $99 when you register by August 29 (standard price $500).
Expert-led, hands-on conversational AI workshops at GTC 2022 are just $99 when you register by August 29 (standard price $500).
Expert-led, hands-on conversational AI workshops at GTC 2022 are just $99 when you register by August 29 (standard price $500).