
 Reducing the amount of carbon released to the atmosphere is a political priority. The current U.S. administration plans to achieve net-zero carbon emissions…
Reducing the amount of carbon released to the atmosphere is a political priority. The current U.S. administration plans to achieve net-zero carbon emissions…
Reducing the amount of carbon released to the atmosphere is a political priority. The current U.S. administration plans to achieve net-zero carbon emissions from the power grid by 2035, and industry-wide by 2050.
To achieve this goal, a variety of techniques are being developed that capitalize on the efficiency of AI to fight against climate change. For power plants, developing techniques to reduce carbon emissions, carbon capture, and storage processes requires a detailed understanding of the associated fluid mechanics and chemical processes throughout the facility. This requires scientifically accurate simulations of fluid mechanics, heat transfer, chemical reactions, and their degree of interaction.
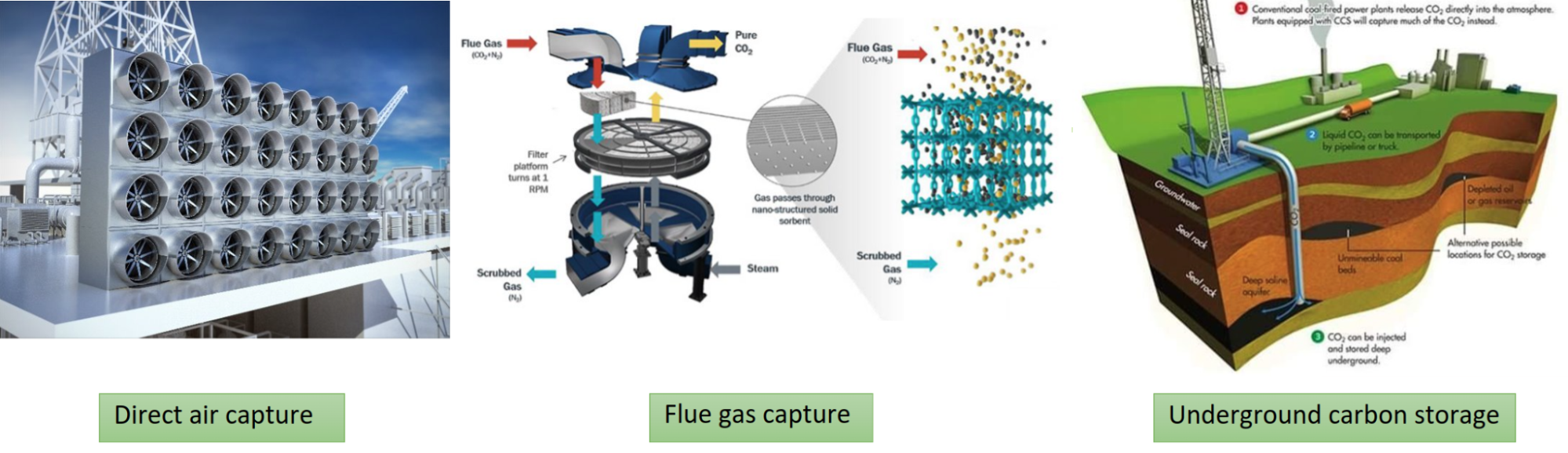
One important focus for industrial use cases is the development of more efficient fuel conversion devices. The goal is to create devices that are more flexible so that the equipment can integrate with renewable resources in a more reliable way.
It is crucial to have better design optimization, uncertainty quantification, and accurate digital twins so that design and control of energy conversion devices can be handled adequately without causing billions of dollars in damage. AI is a natural choice to be used for developing such digital twins that can provide near real-time predictions without compromising the accuracy.
This post explains how the physics-informed machine learning (ML) framework, NVIDIA Modulus, is being used to bypass the conventional methods to enable large-scale scientific modeling, and to develop power plant digital twins that can help move towards net-zero carbon emissions.
Simulating industrial power plants with physics-ML
Flow field predictions for new operating conditions, such as changes in input conditions or geometrical configuration of the boiler components, require new computational fluid dynamics simulations. This can become very expensive and time consuming if simulations cover large parameters of space, such as those used for uncertainty quantification studies. Also, in most cases, the entirety of a flow field is not of interest. A neural network, once trained, can predict the flow field at the required points in the affected area in a fraction of a second.
Together with the National Energy Technology Laboratory (NETL), NVIDIA Modulus researchers are developing a digital twin of a power plant boiler capable of modeling turbulent reacting flows. The digital twin will use machine learning to replicate the flow conditions inside a boiler with a high level of fidelity, and be capable of providing near-instantaneous flow predictions for the operating conditions of interest.
Understanding of the internal velocity, temperature, and species fields is crucial for taking steps towards mitigating emission of greenhouse gasses and pollutants. Physics-informed ML, otherwise known as physics-ML, can be used to model predictive control to help plant operators optimize boiler operating conditions for efficiency and performance.
While not part of this study, it should be noted that digital twins can also be deployed for cybersecurity purposes to act as digital ghosts to distract intruders from the intended targets. These digital ghosts provide copies of the operating conditions with synthetic variations in the state of the system to the control room. If an intruder accesses control room data, they will not be able to distinguish between the real operational data and these copies. This framework can be extended to model other power plant components with moderate effort.
Enhancing proxy models with real-time feedback
The proxy model can also be coupled with the live feedback from sensors attached to the boiler to constantly improve itself with the assimilation of field data.
A typical power plant boiler includes dozens of concentration sensors, hundreds of temperature sensors, and thousands of sensors that measure the flow data. The placement of these sensors should be optimized so that the harsh boiler operating conditions, where temperatures can exceed 1,000℃, do not melt or damage these sensors. These sensors can provide a stream of data to the proxy model to constantly update the model through data assimilation and online learning to improve the model’s accuracy and reliability.
Additionally, a lot of uncertainty surrounds the parameters of physical models, such as reaction kinetics and viscosity. Using sensor data can reduce these uncertainties by assimilating field data into the proxy model. Failure to account for these uncertainties can cause significant monetary damages and power outages for days or even months.
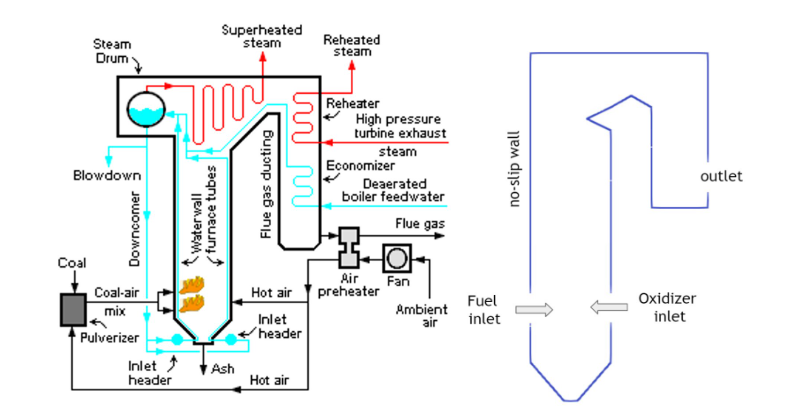
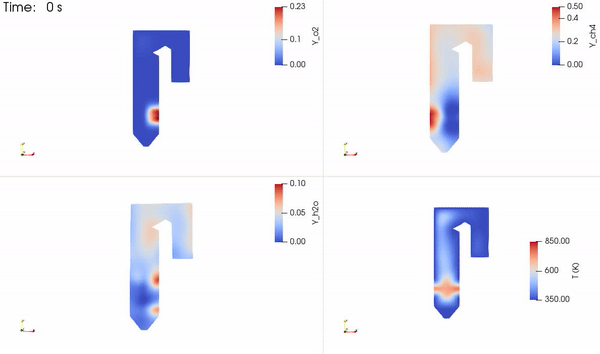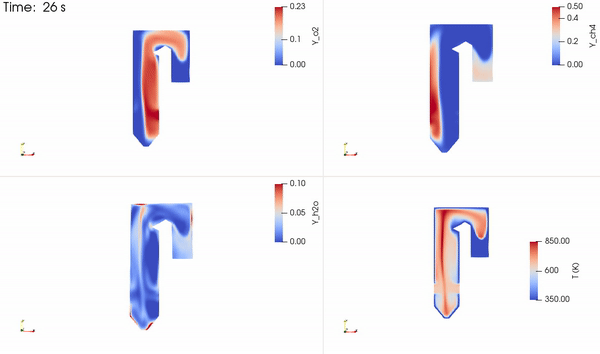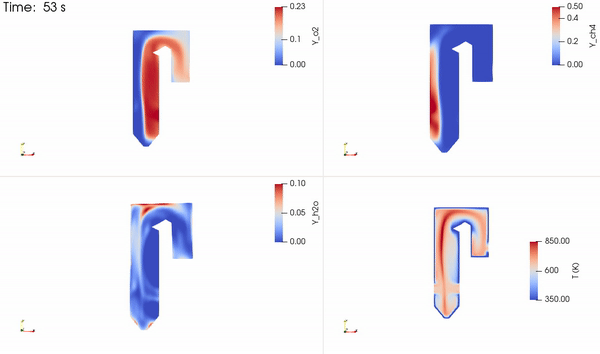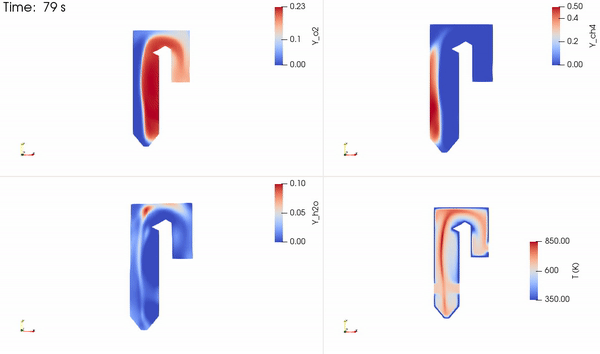
Figure 2 illustrates the simplified boiler used in this study to solve for the flow field, temperature, and species mass concentration where methane and oxygen react to form carbon dioxide and water. The water flowing through the boiler tubes is heated and converted to vapor that is directed through the turbines for power generation. The reaction products, CO2 and H2O, are released into the air. If captured, they can be injected underground.
The oxidizer inlet velocity directly controls the flow conditions within the boiler, and subsequently its efficiency and performance. Changes in the oxidizer input velocity influences the combustion processes within the boiler which in turn, affects the temperature and species distributions throughout the system.
It is important to control the temperature inside the boiler as it directly influences the temperature and state of the working fluid, which in this study is water. This is so critical that the thermal constraints for different components outside of the boiler itself, including the water tubes and turbines, must be met.
Additionally, the oxidizer inlet velocity controls the amount of air that enters the reactor per unit time which directly affects the residence time of the species and the overall mixing behavior. If the residence time is too short, the reactions may not take place properly within the boiler and if it is too long, additional reactions leading to excessive pollutant emissions, such as CO, NOx, and CO2 may take place. Therefore, the inlet velocity is a key variable for optimizing the combustion processes and power generation.
| Equation Name | Equation |
| Continuity |  |
| Species Mass Fraction |  |
| Momentum |  |
| Temperature |  |
| Kinetics-Controlled Single Step Irreversible Reaction |  |
| Species Source/Sink Terms | 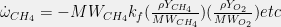 |
| Temperature Source Term | 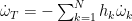 |
How to build a boiler digital twin using physics-informed ML
NVIDIA Modulus offers a collection of models that can be trained purely based on physics or data, or a combination of data and physics. By parameterizing these models, and leveraging the optimized inference pipeline, NVIDIA Modulus is capable of predicting the system behavior under varying operational and environmental conditions as a post-processing step.
As previously outlined, NVIDIA Modulus was used to develop a parameterized model trained on the governing laws of physics for a generic boiler. Once trained, this model provides near-instantaneous predictions of the temperature inside the boiler, species mass concentration, and flow velocity, and pressure for any given inlet velocity for species. No training data is used, and the loss function is formulated solely on how well the neural network solution satisfies the governing equations and the boundary conditions.
For this problem, the temperature at the inlets has been fixed at 650K, and the walls are at 350K.The parameter space for this simplified case is spanned by the varying oxidizer inlet velocity that ranges between 1 and 5 m/s.
A zero-equation formulation is used to model the turbulent Reynolds stresses. The Sinusoidal Representation Network (SiReN) in NVIDIA Modulus is used as the network architecture. A key component of this network architecture is the initialization scheme in which the weight matrices of the network are drawn from a uniform distribution. The input of each Sin activation has a normal distribution and the output of each Sin activation has an arcSin distribution. This preserves the distribution of activations allowing deep architectures to be constructed and trained effectively.
The first layer of the network is scaled by a factor to span multiple periods of the Sin function. This was empirically shown to give good performance and is in line with the benefits of the input encoding in the Fourier networks. Several NVIDIA Modulus features such as L2 to L1 loss decay and spatial loss weighting using Signed Distance Function (SDF) are used to improve accuracy. Time-to-convergence is minimized by utilizing NVIDIA Modulus performance upgrades such as Just-In-Time (JIT) compilation and CUDA graphs.
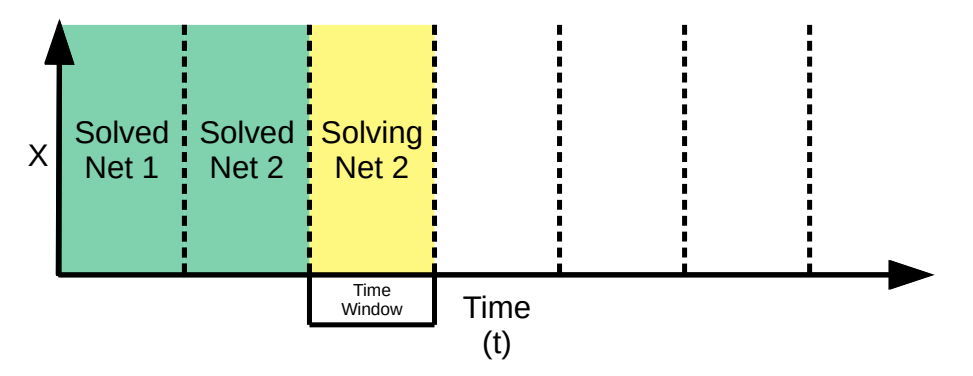
A moving-time window method developed by the NVIDIA Modulus team is used for transient flow modeling. Solving transient simulations with only the conventional continuous time method can be difficult for long time durations. The moving-time window method iteratively solves for small consecutive time windows. The continuous time method is used for solving inside a particular window, and the solution at the end of each time window is used as the initial condition for the next window.
Selective Equation Terms Suppression
For modeling combustion, a novel approach developed by NETL researchers, called Selective Equation Terms Suppression (SETS), is used to drastically improve the training convergence.
For several partial differential equations (PDEs), the terms in the physical equations have different scales in time and magnitude (sometimes also known as stiff PDEs). For such PDEs, the loss equation can appear to be minimized despite poor treatment of the smaller terms.
Using the SETS approach to tackle this, you can create multiple instances of the same PDE and freeze certain terms. During the optimization process, this forces the optimizer to use the value from the former iteration for the frozen terms. Thus, the optimizer minimizes each term in the PDE and efficiently reduces the equation residual.
This prevents any one term in the PDE dominating the loss gradients. Creating multiple instances with different frozen terms in each instance allows the overall representation of the physics to remain the same, while allowing the neural networks to better learn the dynamic balance between all the terms in the equations.
However, creating multiple instances of the same equation (with different frozen terms) also creates multiple loss terms, each of which can be weighted differently. Several other formulations were also developed to efficiently handle the stiff PDEs:
- Ramping up the source terms gradually during training to allow the neural networks to adjust better to the problem.
- Having better control over the coupling between the species equations and the temperature equation by adjusting the order in which they are trained and their relative number of training instances.
Residual Normalization
Another novel approach used for improving the training convergence is Residual Normalization or ResNorm. The predominant approach used in loss balancing of the neural network solvers is to multiply a parameter to each of the individual loss terms to balance out the contribution of each term to the overall loss. However, tuning these parameters manually is not straightforward, and also requires treating these parameters as constants. ResNorm minimizes an additional loss term that encourages the individual losses to take similar relative magnitudes. The loss weights are dynamically tuned throughout the training based on the relative training rates of the different constraints.
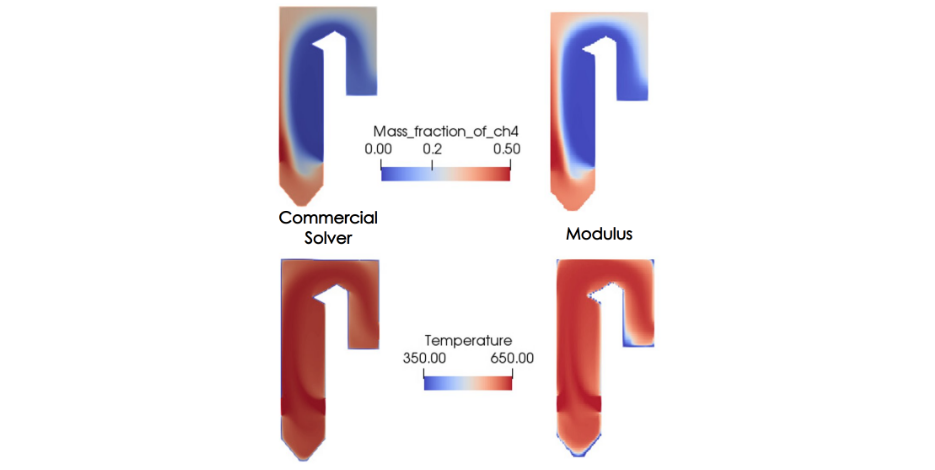
The distribution of the two reacting species, a product species and temperature, is shown in Figure 5. The reactants come into contact to form the thin reaction zone where products are formed. Energy is then released that increases the local temperature, which is advected and diffused throughout the domain.
3D design integration with NVIDIA Omniverse
NVIDIA Omniverse is an easily extensible platform for 3D design collaboration and scalable multi-GPU, real-time, true-to-reality simulation. The NVIDIA Omniverse extension for NVIDIA Modulus enables real-time, virtual-world simulation and full-design fidelity visualization. The built-in pipeline can be used for common visualizations such as streamlines and isosurfaces for the outputs of the NVIDIA Modulus model.
Another benefit from this integration is being able to visualize and analyze the high-fidelity simulation output in near real-time as the design parameters are varied. In the final part of the power plant boiler project, the NVIDIA Omniverse extension for NVIDIA Modulus will be used to develop a boiler digital twin that uses the final trained model to provide near-instantaneous prediction and visualization of the flow, temperature, pressure, and species mass concentration inside the boiler under varying operating conditions.

To learn more about the NVIDIA Modulus integration with NVIDIA Omniverse, see Visualizing Interactive Simulations with Omniverse Extension for NVIDIA Modulus.
For even more related learning, check out the self-paced online course, Introduction to Physics-informed Machine Learning with Modulus and the free NVIDIA On-Demand session, Journey Toward Zero-Carbon Emissions Leveraging AI for Scientific Digital Twins.
Disclaimer: This project was funded by the United States Department of Energy, National Energy Technology Laboratory, in part, through a site support contract. Neither the United States Government nor any agency thereof, nor any of their employees, nor the support contractor, nor any of their employees, makes any warranty, express or implied, or assumes any legal liability or responsibility for the accuracy, completeness, or usefulness of any information, apparatus, product, or process disclosed, or represents that its use would not infringe privately owned rights. Reference herein to any specific commercial product, process, or service by trade name, trademark, manufacturer, or otherwise does not necessarily constitute or imply its endorsement, recommendation, or favoring by the United States Government or any agency thereof. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States Government or any agency thereof.