Fueled by data, ML models are the mathematical engines of AI, expressions of algorithms that find patterns and make predictions faster than a human can.
Fueled by data, ML models are the mathematical engines of AI, expressions of algorithms that find patterns and make predictions faster than a human can.
Quantum computers, still in their infancy, are influencing a new generation of simulations already running on classical computers, and now accelerated with the…
Quantum computers, still in their infancy, are influencing a new generation of simulations already running on classical computers, and now accelerated with the NVIDIA cuQuantum SDK.
Smart hospitals — which utilize data and AI insights to facilitate decision-making at each stage of the patient experience — can provide medical professionals with insights that enable better and faster care. A smart hospital uses data and technology to accelerate and enhance the work healthcare professionals and hospital management are already doing, such as Read article >
Are you interested in getting started with edge AI and robotics but not sure where to begin? Look at the relaunched NVIDIA Jetson Nano Developer Kit…
Are you interested in getting started with edge AI and robotics but not sure where to begin?
Look at the relaunched NVIDIA Jetson Nano Developer Kit available for purchase from partners starting November 25, 2022 in the US and worldwide in December.
Introduced 3 years ago, the NVIDIA Jetson Nano is a low-cost, entry-level AI computer for the embedded and edge AI market. With a familiar Linux environment, easy-to-follow tutorials, and ready-to-build open-source projects created by an active developer community, it’s the perfect tool for learning by doing.
This small, powerful computer lets you run multiple neural networks in parallel for applications like image classification, object detection, segmentation, and speech processing. All this is packed into an easy-to-use platform that runs in as little as five watts.
Jetson Nano in action
Last year, researchers from the University of Minnesota developed a neuroprosthetic hand that uses AI models based on recurrent neural networks (RNN) to read and decode an amputee’s intent of moving individual fingers from peripheral nerve activities. The AI models are deployed using an NVIDIA Jetson Nano as a portable, self-contained unit.
Video 1. Researchers trained an AI neural decoder able running on an NVIDIA Jetson Nano to translate 46-year-old Shawn Findley’s thoughts into individual finger motions
Video 2. Using Jetson Nano’s computational power to control a drone with human gestures
Using the Jetson Nano Developer Kit, AI has become accessible to everyone. From projects predicting bus arrival times to real-time chess game analytics and from AI-based music synthesizers to automated vision-based warning systems for lab equipment, Jetson developers are discovering the diverse capabilities of AI using the Jetson Nano Developer Kit.
The same software stack supports all NVIDIA Jetson modules and provides Jetson Linux, developer tools, CUDA-X accelerated libraries, and other NVIDIA technologies.
NVIDIA is continuing to enhance the Jetson family and set a new standard for entry-level AI with the Jetson Orin Nano series announced at GTC Fall 2022.
The Jetson Orin Nano series delivers 80x the AI performance of the Jetson Nano. You can get started on your next-generation application today with the full software emulation support provided by the Jetson AGX Orin Developer Kit.
Learn more about developing for all the Jetson modules using emulation mode.
Get started
The NVIDIA Deep Learning Institute offers a variety of online courses to help you begin your journey with Jetson:
DLI also offers a complete teaching kit for use by college and university courses.
Video 3. Jetson AI Ambassador Sungsook Jang shares her work in South Korea teaching AI to students using the NVIDIA Jetson
Need other inspiration to get started with your first AI or robotics application? For tips, ideas, and answers to your development questions, visit the Jetson developer forums.
Today’s leading-edge high performance computing (HPC) systems contain tens of thousands of GPUs. In NVIDIA systems, GPUs are connected on nodes through the…
Today’s leading-edge high performance computing (HPC) systems contain tens of thousands of GPUs. In NVIDIA systems, GPUs are connected on nodes through the NVLink scale-up interconnect, and across nodes through a scale-out network like InfiniBand. The software libraries that GPUs use to communicate, share work, and efficiently operate in parallel are collectively called NVIDIA Magnum IO, the architecture for parallel, asynchronous, and intelligent data center IO.
For many applications, scaling to such large systems requires high efficiency for fine-grain communication between GPUs. This is especially critical for workloads targeting strong scaling, where computing resources are added to reduce the time to solve a given problem.
NVIDIA Magnum IO NVSHMEM is a communication library that is based on the OpenSHMEM specification and provides a partitioned global address space (PGAS) data access model to the memory of all GPUs in an HPC system.
This library is an especially suitable and efficient tool for workloads targeting strong scaling because of its support for GPU-integrated communication. In this model, data is accessed through one-sided read, write, and atomic update communication routines.
This communication model achieves a high efficiency for fine-grain data access through NVLink because of the tight integration with the GPU architecture. However, high efficiency for internode data access has remained a challenge because of the need for the host CPU to manage communication operations.
This post introduces a new communication methodology in NVSHMEM called InfiniBand GPUDirect Async (IBGDA) built on top of the GPUDirect Async family of technologies. IBGDA was introduced in NVSHMEM 2.6.0 and significantly improved upon in NVSHMEM 2.7.0 and 2.8.0. It enables the GPU to bypass the CPU when issuing internode NVSHMEM communication without any changes to existing applications. As we show, this leads to significant improvements in throughput and scaling for applications using NVSHMEM.
Proxy-initiated communication
Figure 1. GPU communications using the CPU proxy to initiate NIC communications causes communication bottlenecks
Using NVLink for intranode communication can be achieved through GPU streaming multiprocessor (SM)–initiated load and store instructions. However, internode communication involves submitting a work request to a network interface controller (NIC) to perform an asynchronous data transfer operation.
Before the introduction of IBGDA, the NVSHMEM InfiniBand Reliable Connection (IBRC) transport used a proxy thread on the CPU to manage communication (Figure 1). When using a proxy thread, NVSHMEM performs the following sequence of operations:
The application launches a CUDA kernel that produces data in GPU memory.
The application calls an NVSHMEM operation (such as nvshmem_put) to communicate with another processing element (PE). This operation can be called from within a CUDA kernel when performing fine-grain or overlapped communication. The NVSHMEM operation writes a work descriptor to the proxy buffer, which is in the host memory.
The NVSHMEM proxy thread detects the work descriptor and initiates the corresponding network operation.
The following steps describe the sequence of operations performed by the proxy thread when interacting with an NVIDIA InfiniBand host channel adapter (HCA), such as the ConnectX-6 HCA:
The CPU creates a work descriptor and enqueues it on the work queue (WQ) buffer, which resides in the host memory.
This descriptor indicates the requested operation such as an RDMA write, and contains the source address, destination address, size, and other necessary network information.
The CPU updates the doorbell record (DBR) buffer in the host memory. This buffer is used in the recovery path in case the NIC drops the write to its doorbell (DB).
The CPU notifies the NIC by writing to its DB, which is a register in the NIC hardware.
The NIC reads the work descriptor from the WQ buffer.
The NIC directly copies the data from the GPU memory using GPUDirect RDMA.
The NIC transfers the data to the remote node.
The NIC indicates that the network operation is completed by writing an event to the completion queue (CQ) buffer on the host memory.
The CPU polls on the CQ buffer to detect completion of the network operation.
The CPU notifies the GPU that the operation has completed. If GDRCopy is present, it writes a notification flag to the GPU memory directly. Otherwise, it writes that flag to the proxy buffer. The GPU polls on the corresponding memory for the status of the work request.
While this approach is portable and can provide high bandwidth for bulk data transfers, it has two major drawbacks:
CPU cycles are continuously consumed by the proxy thread.
You cannot reach the peak NIC throughput for fine-grain transfers because of a bottleneck at the proxy thread. Modern NICs can process hundreds of millions of communication requests per second. While the GPU can generate requests at this rate, the CPU proxy’s processing rate is orders of magnitude lower, creating a bottleneck for fine-grain communication patterns.
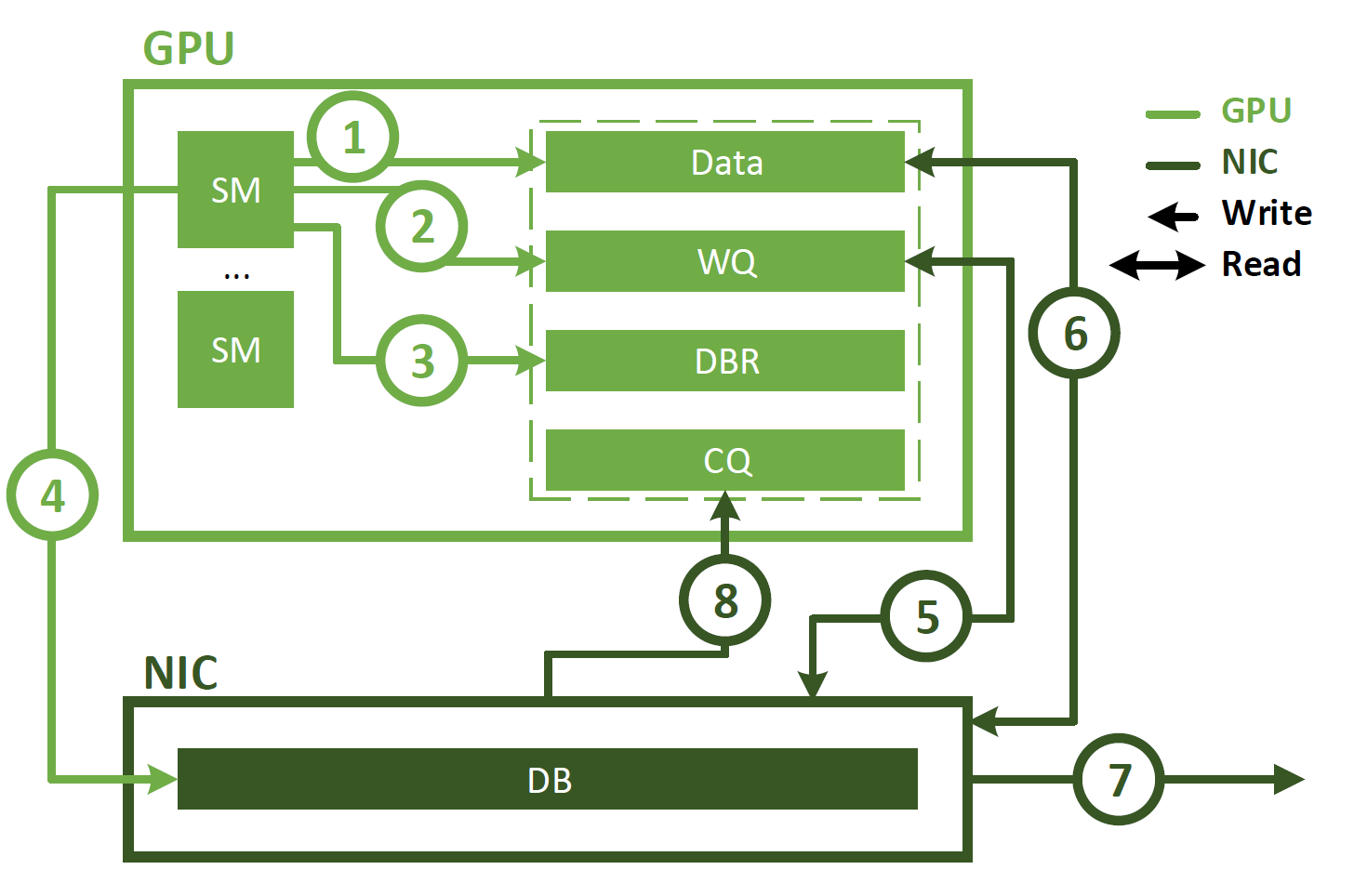
InfiniBand GPUDirect Async
Figure 2. GPU communications using IBGDA enables a direct control path from GPU SM to NIC and removes the CPU from the critical path
In contrast with proxy-initiated communication, IBGDA uses GPUDirect Async–Kernel-Initiated (GPUDirect Async–KI) to enable the GPU SM to interact directly with NIC. This is shown in Figure 2 and involves the following steps.
The application launches a CUDA kernel that produces data in the GPU memory.
The application calls an NVSHMEM operation (such as nvshmem_put) to communicate with another PE. The NVSHMEM operation uses an SM to create a NIC work descriptor and writes it directly to the WQ buffer. Unlike the CPU Proxy method, this WQ buffer resides in the GPU memory.
The SM updates the DBR buffer, which is also located in the GPU memory.
The SM notifies the NIC by writing to the NIC’s DB register.
The NIC reads the work descriptor in the WQ buffer using GPUDirect RDMA.
The NIC reads the data in the GPU memory using GPUDirect RDMA.
The NIC transfers the data to the remote node.
The NIC notifies the GPU that the network operation is completed by writing to the CQ buffer using GPUDirect RDMA.
As shown, IBGDA eliminates the CPU from the communication control path. When using IBGDA, GPU and NIC directly exchange information necessary for communication. The WQ and DBR buffers are also moved to the GPU memory to improve efficiency when accessed by the SM, while preserving access by the NIC through GPUDirect RDMA.
Magnum IO NVSHMEM evaluation
We compared the performance of the NVSHMEM IBGDA transport with the NVSHMEM IBRC transport, which uses a proxy thread to manage communication. Both transports are part of the standard NVSHMEM distribution. All benchmarks and the case study were run on four DGX-A100 servers connected through NVIDIA ConnectX-6 200 Gb/s InfiniBand networking and an NVIDIA Quantum HDR switch.
To highlight the effect of IBGDA, we disabled communication through NVLink. This forces all transfers to be performed through the InfiniBand network even when PEs are located on the same node.
One-sided put bandwidth
We first ran the shmem_put_bw benchmark, which is included in the NVSHMEM performance test suite and uses nvshmem_double_put_nbi_block to issue data transfers. This test measures the bandwidth achieved when using one-sided write operations to transfer a fixed amount of total data over a range of communication parameters.
For internode transfers, this operation uses one thread in the thread block when performing network communication, regardless of how many threads are in the thread block. This is known and also referred to as a cooperative thread array (CTA). Two PEs were launched on different DGX-A100 nodes. This was set with one thread per thread block and one QP (NIC queue pair, containing the WQ and CQ) per thread block.
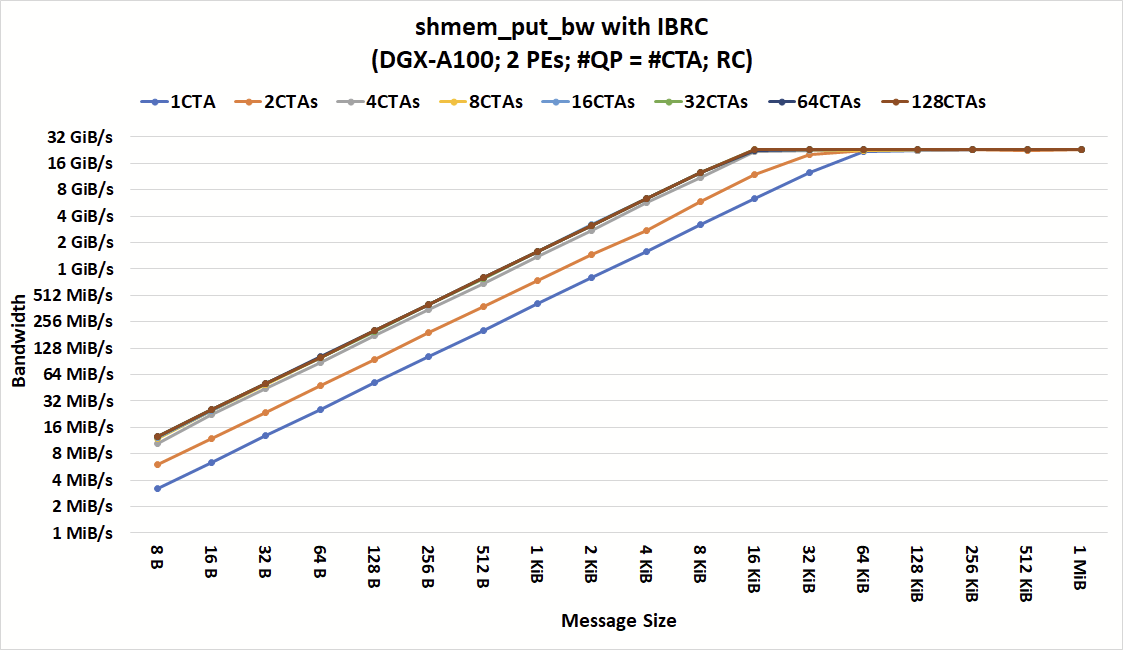
Figure 3. The bandwidth of shmem_put_bw with IBRC shows the bandwidth cap caused by CPU Proxy for small message sizes as you scale to more QPs and CTAs
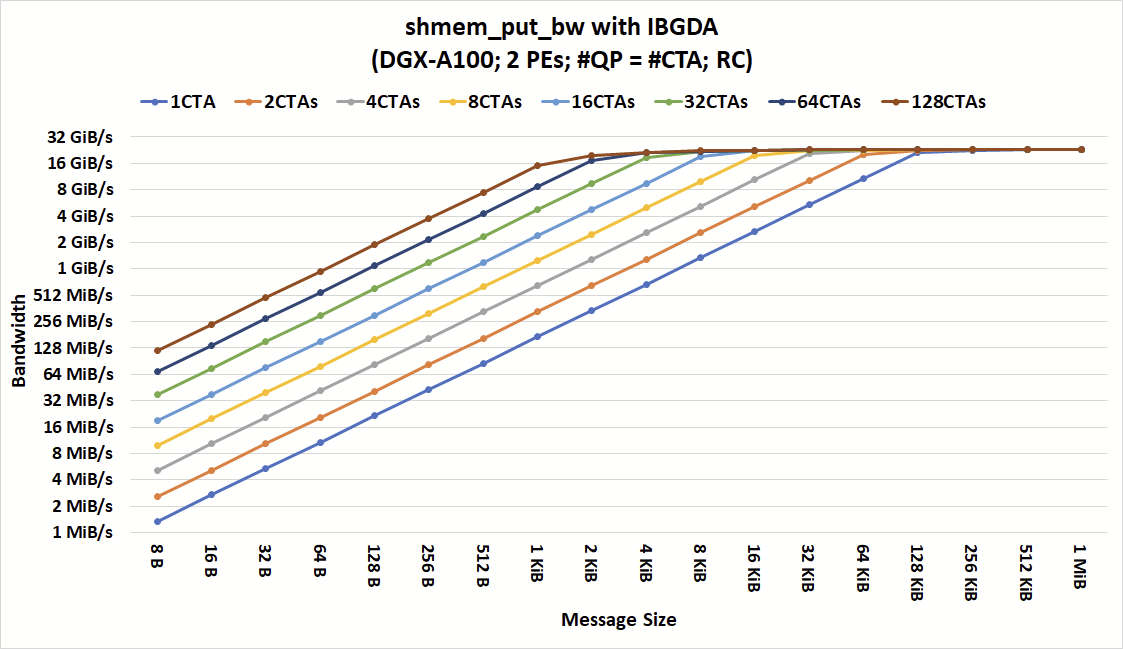
Figure 4. The bandwidth of shmem_put_bw with IBGDA demonstrates that the bandwidth of small message sizes can scale as the number of CTAs and QPs increases
Figures 3 and 4 show the bandwidth of shmem_put_bw with IBRC and IBGDA at various numbers of CTAs and message sizes. As shown, for coarse-grain communication with large messages, both IBGDA and IBRC can reach peak bandwidth. IBRC can saturate the network with messages as small as 16 KiB when the application issues communication from at least four CTAs.
Increasing the number of CTAs further does not reduce the minimum message size at which we observed peak bandwidth. The bottleneck limiting bandwidth for smaller messages is in the CPU Proxy thread. Although not shown here, we also tried increasing the number of CPU proxy threads and observed similar behavior.
By removing the proxy bottleneck, IBGDA achieved the peak bandwidth with messages as small as 2 KiB when 64 CTAs issue communication. This result highlights IBGDA’s ability to support a higher level of communication parallelism and the resulting performance improvement.
For IBRC and IBGDA, only one thread in each CTA participates in the network operations. In other words, only 64 threads (not 1,024×64 threads) are required to achieve peak bandwidth at 2 KiB message size.
It is also shown that IBGDA bandwidth continues to scale with the number of CTAs performing communication, whereas the IBRC proxy reaches its scaling limit at four CTAs. As a result, IBGDA provides up to 9.5x higher throughput for NVSHMEM block-put operations with message sizes less than 1 KiB.
Boosting throughput for small messages
The shmem_p_bw benchmark uses the scalar nvshmem_double_p operation to send data directly from a GPU register to the remote PE. This operation is thread-scoped, which means that each thread that calls this operation transfers an 8-byte data word.
In the following experiment, we launched 1,024 threads per CTA and increased the number of CTAs while keeping the number of QPs equal to the number of CTAs.
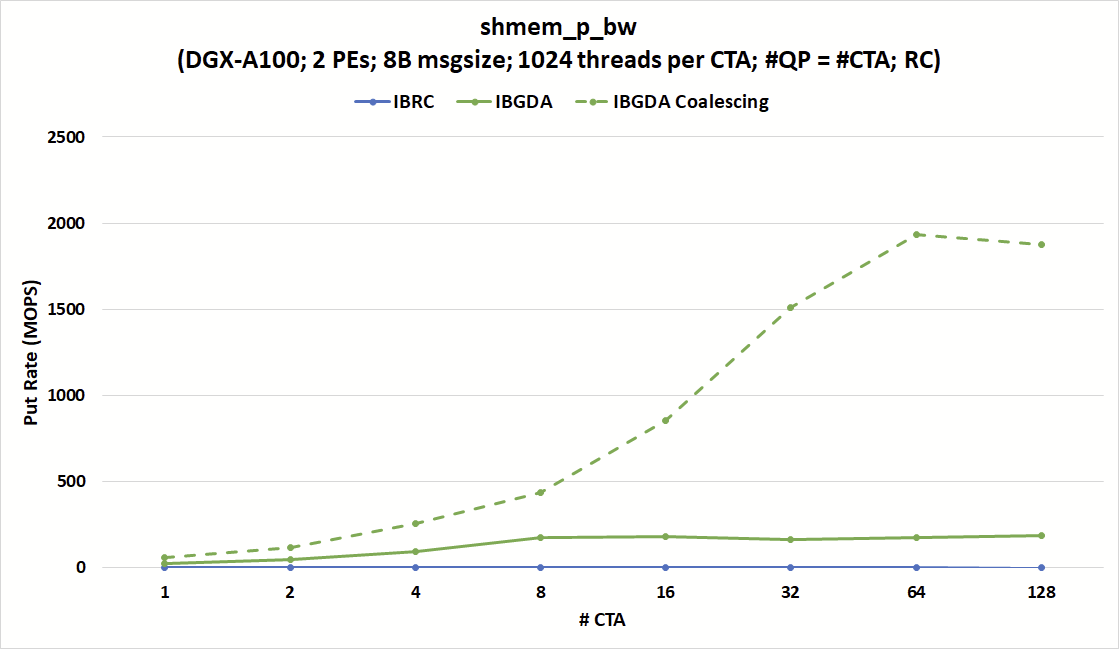
Figure 5. The put rate comparison between IBRC and IBGDA of shmem_p_bw shows the performance advantage of IBGDA on sending millions of small messages per second
On the other hand, the put rate of IBGDA could reach up to 180 MOPS, approaching the peak NIC message rate limit at 215 MOPS. The graph also shows that IBGDA could reach almost 2000 MOPS if the coalescing conditions are satisfied.
Figure 5 shows that the put rate, in million operations per second (MOPS), of IBRC is capped at around 1.7 MOPS regardless of the number of CTAs and QPs. On the other hand, the message rate of IBGDA increases with the number of CTAs, approaching the 215 MOPS hardware limit of the NVIDIA ConnectX-6 InfiniBand NIC with just eight CTAs.
In this configuration, IBGDA issues one work request to the NIC per nvshmem_double_p operation. This highlights an advantage of IBGDA for fine-grain communication involving large numbers of small messages.
IBGDA also provides automatic data coalescing when the destination addresses are contiguous within the same warp. This feature enables sending one large message instead of 32 small messages. It is useful for applications that want to transfer scattered data directly from GPU registers to a contiguous buffer at the destination.
Figure 5 shows that the put rate could reach beyond the NIC peak message rate when the data coalescing conditions are satisfied.
Jacobi method case study
The performance of the NVSHMEM Jacobi benchmark was analyzed to demonstrate the performance of IBGDA in real applications compared with IBRC. This repository includes two NVSHMEM implementations of the Jacobi solver.
In the first implementation, each thread uses the scalar nvshmem_p operation to send data as soon as it becomes available. This implementation is known to work well with NVLink but not with IBRC.
The second implementation aggregates data into a contiguous GPU buffer before each CTA calls nvshmem_put_nbi_block to initiate the communication. This data aggregation technique works well with IBRC but adds overhead on NVLink, where nvshmem_p operations can directly store data from a register to the remote PE’s buffer. This mismatch highlights a challenge when optimizing a given code for both scaling up and scaling out.
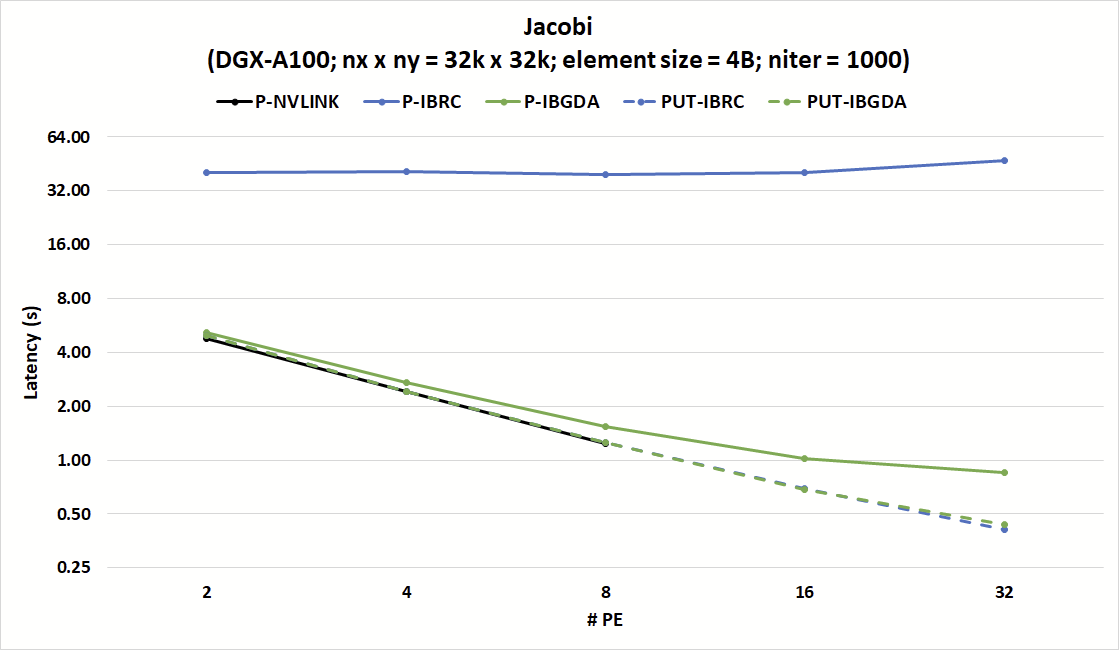
Figure 6. Latency comparison of Jacobi implementations using P and PUT with IBRC and IBGDA
Figure 6 shows that IBGDA’s improvements to small message communication efficiency can help address these challenges. This chart shows the latency of 1,000 iterations of the Jacobi kernel for a strong scaling experiment where the number of PEs is increased while maintaining a fixed matrix size. With IBRC, the nvshmem_p version of Jacobi has more than 8x the latency of the nvshmem_put version.
On the other hand, both the nvshmem_p and nvshmem_put versions scale with IBGDA and match the efficiency of nvshmem_p on NVLink. The IBGDA nvshmem_p version matches the latency of nvshmem_put with IBRC.
Results show that nvshmem_p with IBGDA has a slightly higher latency compared with nvshmem_put. This is because sending one large message incurs lower network overhead compared with sending many small messages.
While such overheads are fundamental to networking, IBGDA can enable applications to hide them by submitting many small message transfer requests to the NIC in parallel.
All-to-all latency case study
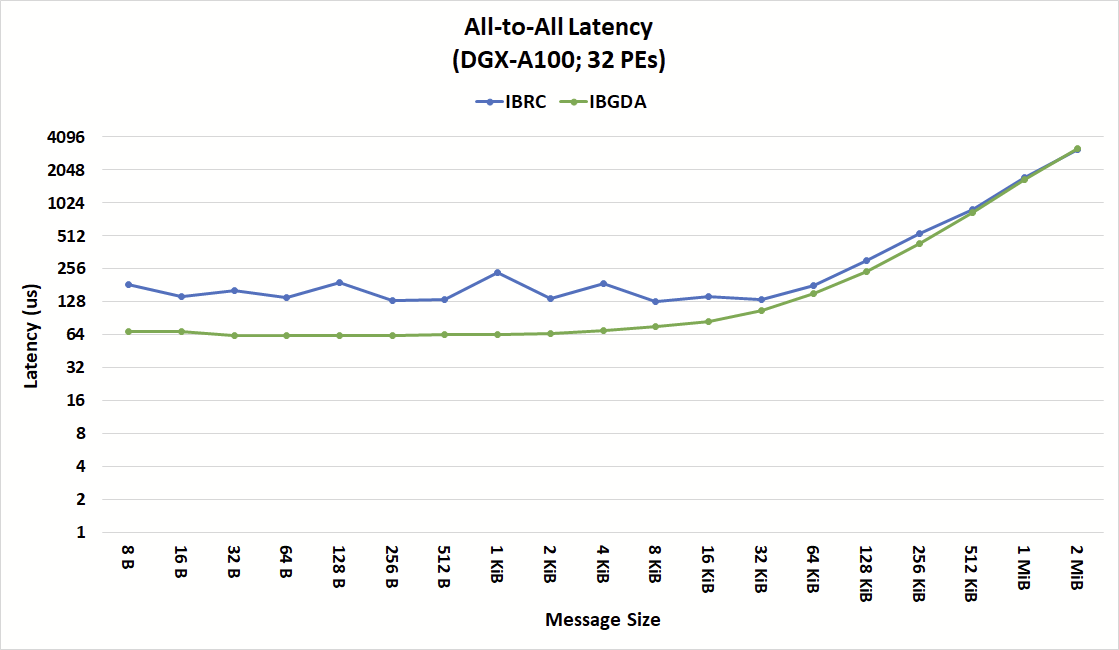
Figure 7. Latency comparison of 32 PE All-to-All transfer between IBRC and IBGDA
Figure 7 shows the latency of the NVSHMEM all-to-all collective operation for IBRC and IBGDA, highlighting the small message performance benefits of IBGDA.
With IBRC, the proxy thread is a serialization point for all operations coming from the device. The proxy thread processes requests in batches to reduce overheads. However, depending on when operations are submitted to the device, there is a possibility that operations submitted at nearly the same time on the device will be processed by a separate loop of the proxy thread.
The serialization of operations by the proxy creates additional latency and masks the internal parallelism of both the NIC and GPU. The IBGDA results show an overall latency that is more consistent, especially for message sizes lower than 16 KiB.
Magnum IO NVSHMEM improves network performance
In this blog, we’ve shown how Magnum IO improves small message network performance, especially for large applications deployed across hundreds or thousands of nodes in HPC data centers. NVSHMEM 2.6.0 introduced InfiniBand GPUDirect Async, which enables the GPU’s SM to submit communication requests directly to the NIC, bypassing the CPU for network communication on NVIDIA InfiniBand networks.
In comparison with the proxy method for managing communication, IBGDA can sustain significantly higher throughput rates at much smaller message sizes. These performance improvements are especially critical to applications that require strong scaling and tend to have message sizes that shrink as the workload is scaled to larger numbers of GPUs.
IBGDA also closes the small message throughput gap between NVLink and network communication, making it easier for you to optimize code to both scale-up and scale-out on today’s GPU-accelerated HPC systems.
In the NVIDIA Studio artists have sparked the imagination of and inspired countless creators to exceed their creative ambitions and do their best work.
Minerva CQ, a startup based in the San Francisco Bay Area, is making customer service calls quicker and more efficient for both agents and customers, with a focus on those in the energy sector. The NVIDIA Inception member’s name is a mashup of the Roman goddess of wisdom and knowledge — and collaborative intelligence (CQ), Read article >
Posted by Mohammad Saleh, Software Engineer, Google Research, Brain Team, and Yinan Wang, Software Engineer, Google Workspace
Information overload is a significant challenge for many organizations and individuals today. It can be overwhelming to keep up with incoming chat messages and documents that arrive at our inbox everyday. This has been exacerbated by the increase in virtual work and remains a challenge as many teams transition to a hybrid work environment with a mix of those working both virtually and in an office. One solution that can address information overload is summarization — for example, to help users improve their productivity and better manage so much information, we recently introduced auto-generated summaries in Google Docs.
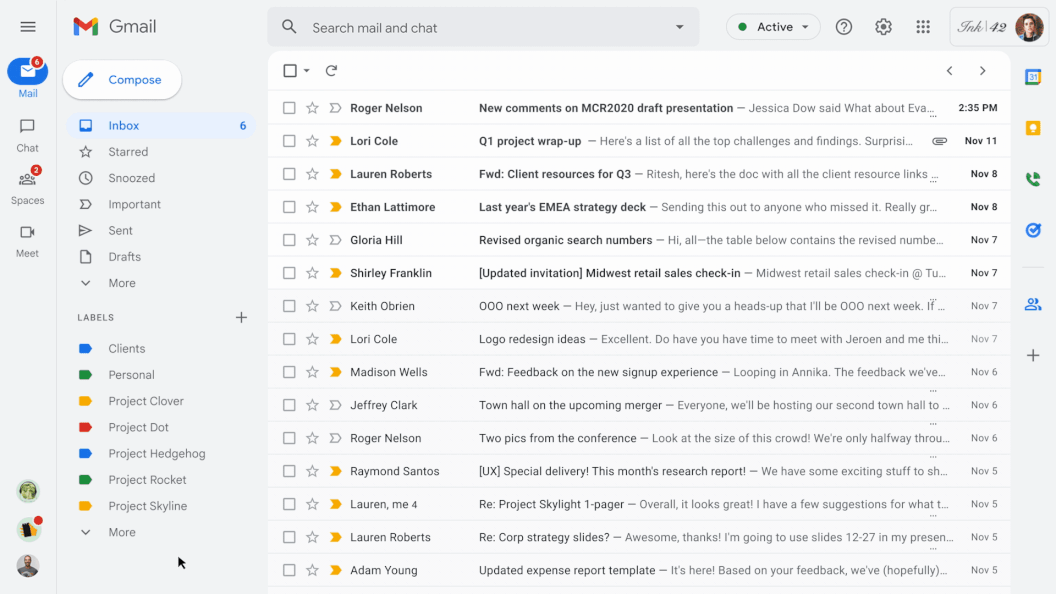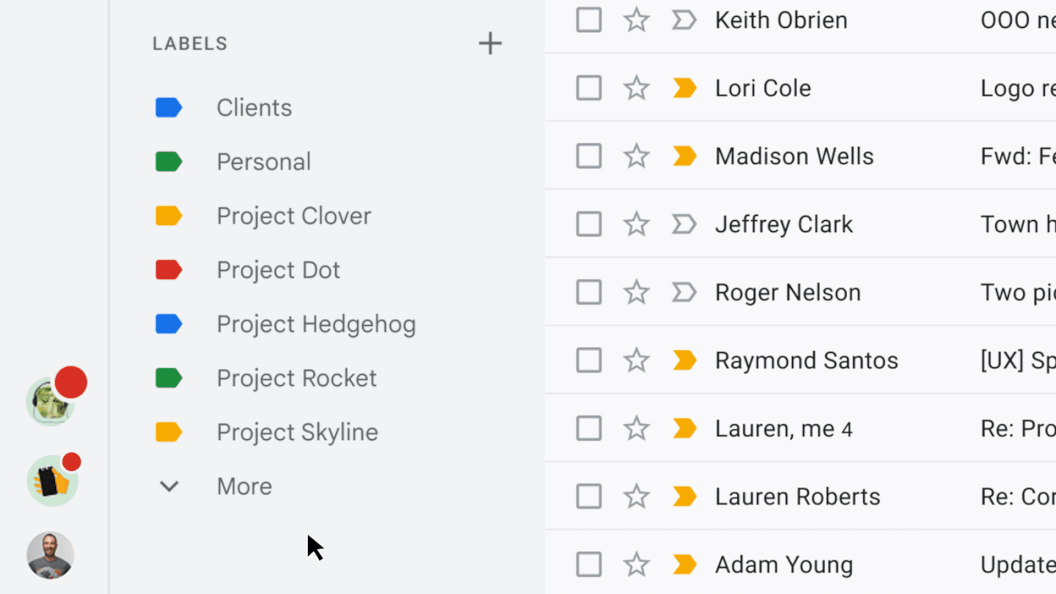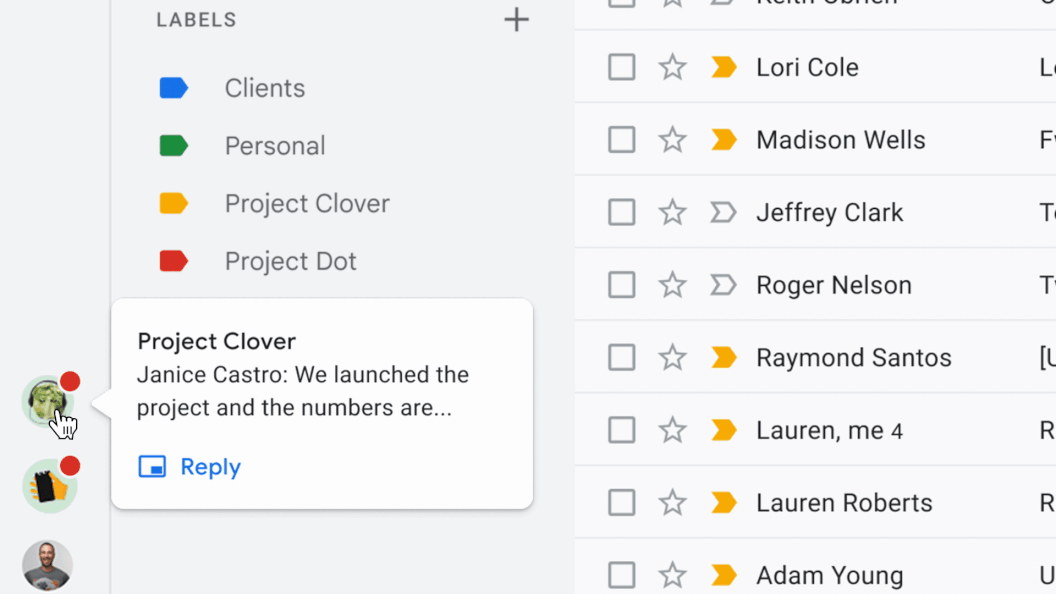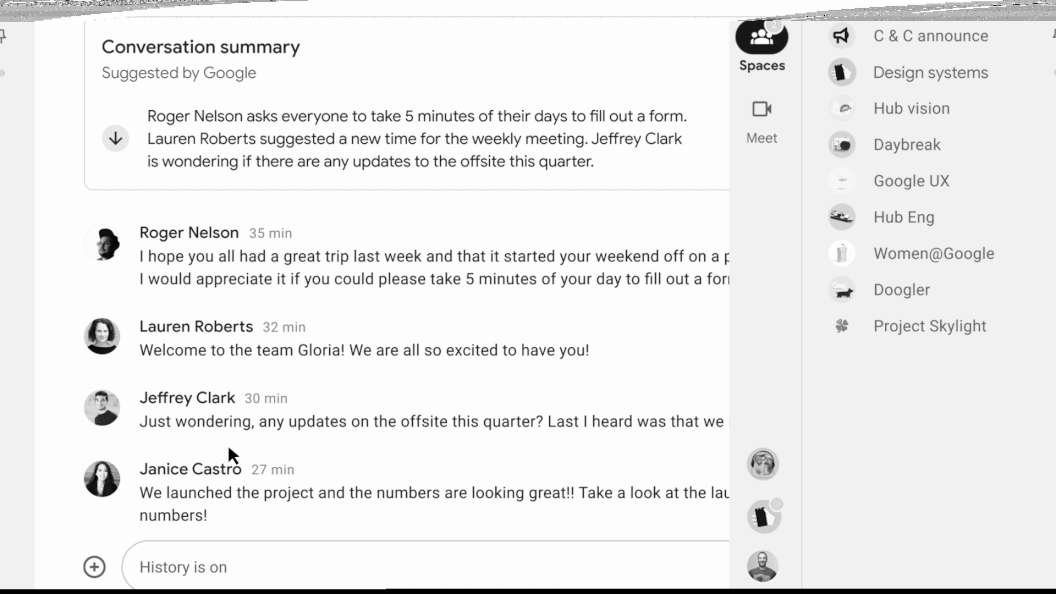
Today, we are excited to introduce conversation summaries in Google Chat for messages in Spaces. When these summaries are available, a card with automatically generated summaries is shown as users enter Spaces with unread messages. The card includes a list of summaries for the different topics discussed in Spaces. This feature is enabled by our state-of-the-art abstractive summarization model, Pegasus, which generates useful and concise summaries for chat conversations, and is currently available to selected premium Google Workspace business customers.
Conversation summaries provide a helpful digest of conversations in Spaces, allowing users to quickly catch-up on unread messages and navigate to the most relevant threads.
Conversation Summarization Modeling
The goal of text summarization is to provide helpful and concise summaries for different types of text, such as documents, articles, or spoken conversations. A good summary covers the key points succinctly, and is fluent and grammatically correct. One approach to summarization is to extract key parts from the text and concatenate them together into a summary (i.e., extractive summarization). Another approach is to use natural language generation (NLG) techniques to summarize using novel words and phrases not necessarily present in the original text. This is referred to as abstractive summarization and is considered closer to how a person would generally summarize text. A main challenge with abstractive summarization, however, is that it sometimes struggles to generate accurate and grammatically correct summaries, especially in real world applications.
ForumSum Dataset
The majority of abstractive summarization datasets and research focuses on single-speaker text documents, like news and scientific articles, mainly due to the abundance of human-written summaries for such documents. On the other hand, datasets of human-written summaries for other types of text, like chat or multi-speaker conversations, are very limited.
To address this we created ForumSum, a diverse and high-quality conversation summarization dataset with human-written summaries. The conversations in the dataset are collected from a wide variety of public internet forums, and are cleaned up and filtered to ensure high quality and safe content (more details in the paper).
An example from the ForumSum dataset.
Each utterance in the conversation starts on a new line, contains an author name and a message text that is separated with a colon. Human annotators are then given detailed instructions to write a 1-3 sentence summary of the conversation. These instructions went through multiple iterations to ensure annotators wrote high quality summaries. We have collected summaries for over six thousand conversations, with an average of more than 6 speakers and 10 utterances per conversation. ForumSum provides quality training data for the conversation summarization problem: it has a variety of topics, number of speakers, and number of utterances commonly encountered in a chat application.
Conversation Summarization Model Design
As we have written previously, the Transformer is a popular model architecture for sequence-to-sequence tasks, like abstractive summarization, where the inputs are the document words and the outputs are the summary words. Pegasus combined transformers with self-supervised pre-training customized for abstractive summarization, making it a great model choice for conversation summarization. First, we fine-tune Pegasus on the ForumSum dataset where the input is the conversation words and the output is the summary words. Second, we use knowledge distillation to distill the Pegasus model into a hybrid architecture of a transformer encoder and a recurrent neural network (RNN) decoder. The resulting model has lower latency and memory footprint while maintaining similar quality as the Pegasus model.
Quality and User Experience
A good summary captures the essence of the conversation while being fluent and grammatically correct. Based on human evaluation and user feedback, we learned that the summarization model generates useful and accurate summaries most of the time. But occasionally the model generates low quality summaries. After looking into issues reported by users, we found that there are two main types of low quality summaries. The first one is misattribution, when the model confuses which person or entity said or performed a certain action. The second one is misrepresentation, when the model’s generated summary misrepresents or contradicts the chat conversation.
To address low quality summaries and improve the user experience, we have made progress in several areas:
Improving ForumSum: While ForumSum provides a good representation of chat conversations, we noticed certain patterns and language styles in Google Chat conversations that differ from ForumSum, e.g., how users mention other users and the use of abbreviations and special symbols. After exploring examples reported by users, we concluded that these out-of-distribution language patterns contributed to low quality summaries. To address this, we first performed data formatting and clean-ups to reduce mismatches between chat and ForumSum conversations whenever possible. Second, we added more training data to ForumSum to better represent these style mismatches. Collectively, these changes resulted in reduction of low quality summaries.
Controlled triggering: To make sure summaries bring the most value to our users, we first need to make sure that the chat conversation is worthy of summarization. For example, we found that there is less value in generating a summary when the user is actively engaged in a conversation and does not have many unread messages, or when the conversation is too short.
Detecting low quality summaries: While the two methods above limited low quality and low value summaries, we still developed methods to detect and abstain from showing such summaries to the user when they are generated. These are a set of heuristics and models to measure the overall quality of summaries and whether they suffer from misattribution or misrepresentation issues.
Finally, while the hybrid model provided significant performance improvements, the latency to generate summaries was still noticeable to users when they opened Spaces with unread messages. To address this issue, we instead generate and update summaries whenever there is a new message sent, edited or deleted. Then summaries are cached ephemerally to ensure they surface smoothly when users open Spaces with unread messages.
Conclusion and Future Work
We are excited to apply state-of-the-art abstractive summarization models to help our Workspace users improve their productivity in Spaces. While this is great progress, we believe there are many opportunities to further improve the experience and the overall quality of summaries. Future directions we are exploring include better modeling and summarizing entangled conversations that include multiple topics, and developing metrics that better measure the factual consistency between chat conversations and summaries.
Acknowledgements
The authors would like to thank the many people across Google that contributed to this work: Ahmed Chowdhury, Alejandro Elizondo, Anmol Tukrel, Benjamin Lee, Chao Wang, Chris Carroll, Don Kim, Jackie Tsay, Jennifer Chou, Jesse Sliter, John Sipple, Kate Montgomery, Maalika Manoharan, Mahdis Mahdieh, Mia Chen, Misha Khalman, Peter Liu, Robert Diersing, Sarah Read, Winnie Yeung, Yao Zhao, and Yonghui Wu.

 Fueled by data, ML models are the mathematical engines of AI, expressions of algorithms that find patterns and make predictions faster than a human can.
Fueled by data, ML models are the mathematical engines of AI, expressions of algorithms that find patterns and make predictions faster than a human can. Quantum computers, still in their infancy, are influencing a new generation of simulations already running on classical computers, and now accelerated with the…
Quantum computers, still in their infancy, are influencing a new generation of simulations already running on classical computers, and now accelerated with the… Learn about the NVIDIA Isaac ROS DNN Inference pipeline and how to use your own models with a YOLOv5 example in this December 1 webinar.
Learn about the NVIDIA Isaac ROS DNN Inference pipeline and how to use your own models with a YOLOv5 example in this December 1 webinar. Are you interested in getting started with edge AI and robotics but not sure where to begin? Look at the relaunched NVIDIA Jetson Nano Developer Kit…
Are you interested in getting started with edge AI and robotics but not sure where to begin? Look at the relaunched NVIDIA Jetson Nano Developer Kit… Today’s leading-edge high performance computing (HPC) systems contain tens of thousands of GPUs. In NVIDIA systems, GPUs are connected on nodes through the…
Today’s leading-edge high performance computing (HPC) systems contain tens of thousands of GPUs. In NVIDIA systems, GPUs are connected on nodes through the…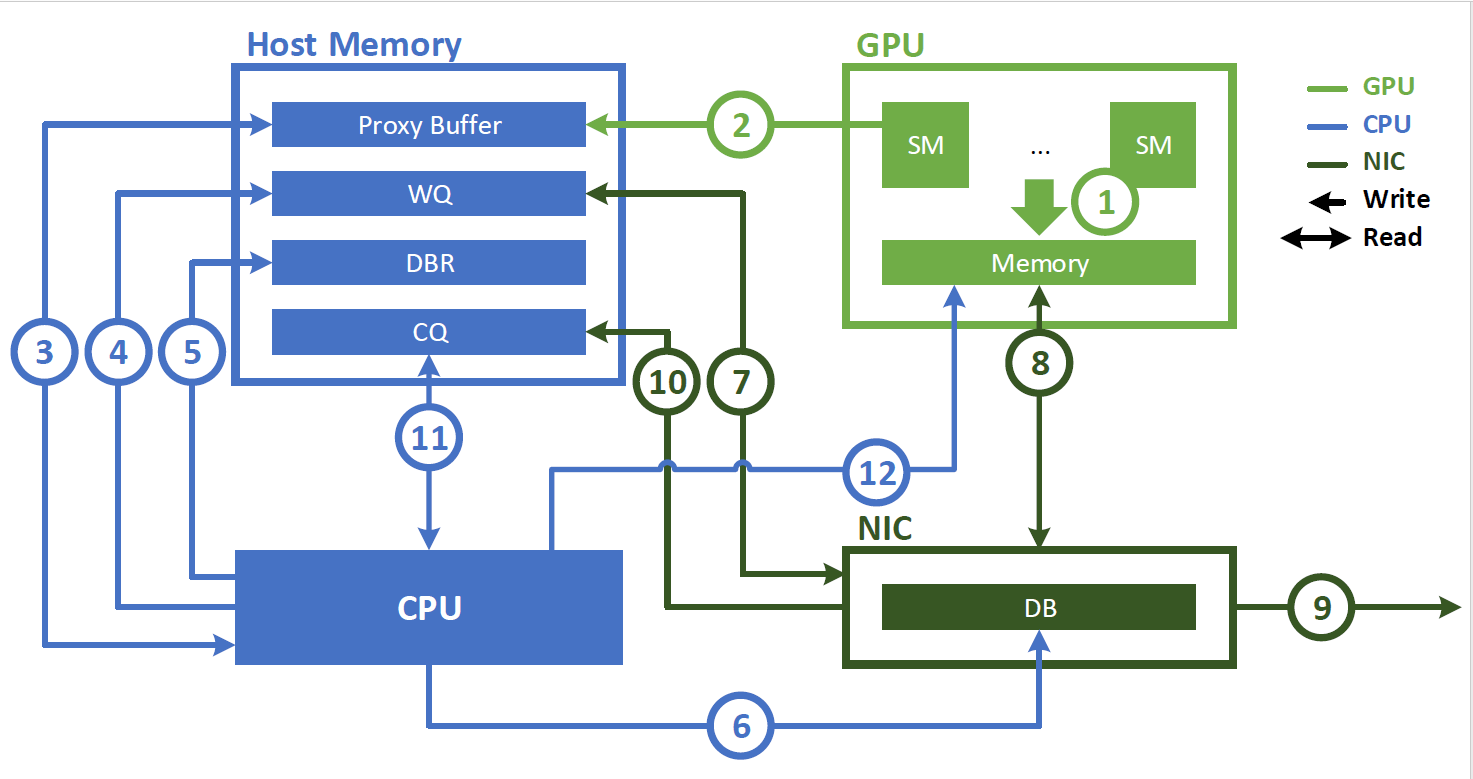
 The University of Cambridge, in the UK, and an NVIDIA DGX SuperPOD point way to the next generation of secure, efficient HPC clouds.
The University of Cambridge, in the UK, and an NVIDIA DGX SuperPOD point way to the next generation of secure, efficient HPC clouds.