Learn the fundamental tools and techniques for accelerating C/C++ applications to run on massively parallel GPUs with CUDA in this instructor-led workshop.
Learn the fundamental tools and techniques for accelerating C/C++ applications to run on massively parallel GPUs with CUDA in this instructor-led workshop.
Data is one of the most valuable assets that a business can possess. It sits at the core of data science and data analysis: without data, they’re both…
Data is one of the most valuable assets that a business can possess. It sits at the core of data science and data analysis: without data, they’re both obsolete. Businesses that actively collect data may have a competitive advantage over those that do not. With sufficient data, organizations can better determine the cause of problems and make informed decisions.
There are scenarios where an organization may lack sufficient data to draw necessary insights. For example, a start-up almost always begins with no data. Instead of moping about their deficiencies, a better solution is to employ data acquisition techniques to help build a custom database.
This post covers a popular data acquisition technique called web scraping. You can follow along using the code in the kurtispykes/web-scraping-real-estate-data GitHub repository.
What is data acquisition?
Data acquisition (also referred to as DAQ) may be as simple as a technician logging the temperature of your oven. You can define DAQ as the process of sampling signals that measure real-world physical phenomena and converting the resulting samples into digital numerical values that a computer can interpret.
In an ideal world, we would have all data handed to us, ready for use, whenever we wanted. However, the world is far from ideal. Data acquisition techniques exist because some problems require specific data that you may not have access to at a particular time. Before any data analysis can be conducted, the data team must have sufficient data available. One technique to acquire data is web scraping.
What is web scraping?
Web scraping is a popular data acquisition technique that has become a hot topic of discussion among those with rising demands for big data. Essentially, it’s the process of extracting information from the Internet and formatting it to be easily usable in data analytics and data science pipelines.
In the past, web scraping was a manual process. The process was tedious and time-consuming, and humans are prone to error. The most common solution is to automate. Automation of web scraping enables you to speed up the process while saving money and reducing the likelihood of human error.
However, web scraping has its challenges.
Challenges of web scraping
Building your own web scraper has challenges outside of knowing how to program and understanding HTML. It is beneficial to know in advance the various obstacles that you may encounter while data scraping. Here are a few of the most common challenges that you’ll face when scraping data from the web.
robots.txt
Permissions for scraping data are usually held in a robots.txt file. This file is used to inform crawlers about the URLs that can be accessed on a website. It prevents the site from being overloaded with requests.
The first thing to check before you begin a web scraping project is whether the target website permits web scraping. Websites can decide whether to allow web scrapers on their website for web scraping purposes.
Some websites do not permit automated web scraping, typically to prevent competitors from gaining a competitive advantage and draining the server resources from the target site. It does affect the website’s performance.
You can check the robots.txt file of a website by appending /robots.txt to the domain name. For example, check Twitter’s robots.txt as follows: www.twitter.com/robots.txt.
Structural changes
UI and UX developers periodically add, remove, and undergo regular structural changes to a website to keep it up to date with the latest advancements. Web scrapers depend on the code elements of the web page at the time that the scraper is built. Thus, frequent changes to a website may result in data being lost. It’s always a good idea to keep tabs on the changes to a web page.
Also, consider that different web page designers may have different criteria for designing their pages. This means that if you plan on scraping multiple websites, you might have to build multiple scrapers, one for each website.
IP blockers, or getting banned
It is possible to be banned from a website. If your web scraper is sending an unnaturally high number of requests to a website, it’s possible for your IP address to get banned. Alternatively, the website may restrict its access to break down the scraping process.
There’s a thin line between what is considered ethical and unethical web scraping: crossing the line quickly leads to IP blocking.
CAPTCHAs
A CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) does exactly what it says in its name: distinguishes humans from bots. The problems posed by CAPTCHAs are typically logical and straightforward for a human to solve but challenging for a bot to accomplish the same feat, which prevents websites from being spammed.
There are ethical workarounds for scraping websites with CAPTCHAs. However, that discussion is beyond the scope of this post.
Honeypot traps
In a similar fashion to how you would set up devices or enclosures to catch pests that invade your home, website owners set up honeypot traps to catch scrapers. These traps are typically links that are not visible by humans but are visible to web scrapers.
The intention is to get information about the scraper, such as its IP address, so they can block the scraper’s access to the website.
Real-time data scraping
There are certain scenarios where you may need data to be scrapped in real time (for example, price comparisons). As changes can occur anytime, the scraper must constantly monitor the website and scrape data. Acquiring large amounts of data in real time is challenging.
Web scraping best practices
Now that you’re aware of the challenges you may face, it’s important to know the best practices to ensure that you are ethically scraping web data.
Respect robots.txt
One of the challenges that you’ll face when scraping web data is abiding by the terms of robots.txt. It is a best practice to follow the guides set by a website around what a web scrape can and cannot crawl.
If a website does not permit web scraping, it is unethical to scrape that website. It’s better to find another data source or contact the website owner directly and discuss a solution.
Be nice to servers
Web servers can only take so much. Exceeding a web server’s load results in the server crashing. Consider what may be an acceptable frequency of requests to make to a host’s server. Several requests in a short time span may result in server failure, which in turn disrupts the user experience for other visitors to the website.
Maintain a reasonable time lapse between requests and be considerate with the number of parallel requests.
Scrape during off-peak hours
Understand when a website may receive its most traffic and refrain from scraping during these hours. Your goal is not to hamper the user experience of other visitors. It’s your moral responsibility to scrape when a website receives less traffic. (This also works in your favor as it significantly improves the speed of your scraper.)
Scrapy tutorial
Web scraping in Python usually involves coding several menial tasks from scratch. However, Scrapy, an open-source web crawling framework, deals with several of the common start-up requirements by default. This means that you can focus on extracting the data that you need from the target websites.
To demonstrate the power of Scrapy, you develop a spider, which is a Scrapy class where you define the behavior of your web scraper. Use this spider to scrape all the listings from the Boston Realty Advisors website (Figure 1).
Figure 1. Boston Realty Advisors Listings
Inspecting the target website
Before starting any web scraping project, it is important to inspect the target website to scrape. The first thing that I like to check when examining a website is whether the pages are static or generated by JavaScript.
To bring up the developer toolbox, press F12. On the Network tab, make sure that Disable cache is checked.
To bring up the command palette, press CTRL + SHIFT + P (Windows Linux) or Command + SHIFT + P (Mac). Type Disable JavaScript, then press Enter and reload the target website.
Figure 2 shows how the Boston Realty Advisors website looks without JavaScript.
Figure 2. The new Listings page when JavaScript is disabled
The empty page tells you that the target web page is generated using JavaScript. You can’t scrape the page by trying to parse the HTML elements displayed in the Elements tab of the developer toolbox. Re-enable JavaScript in the developer tools and reload the page.
There’s more to examine.
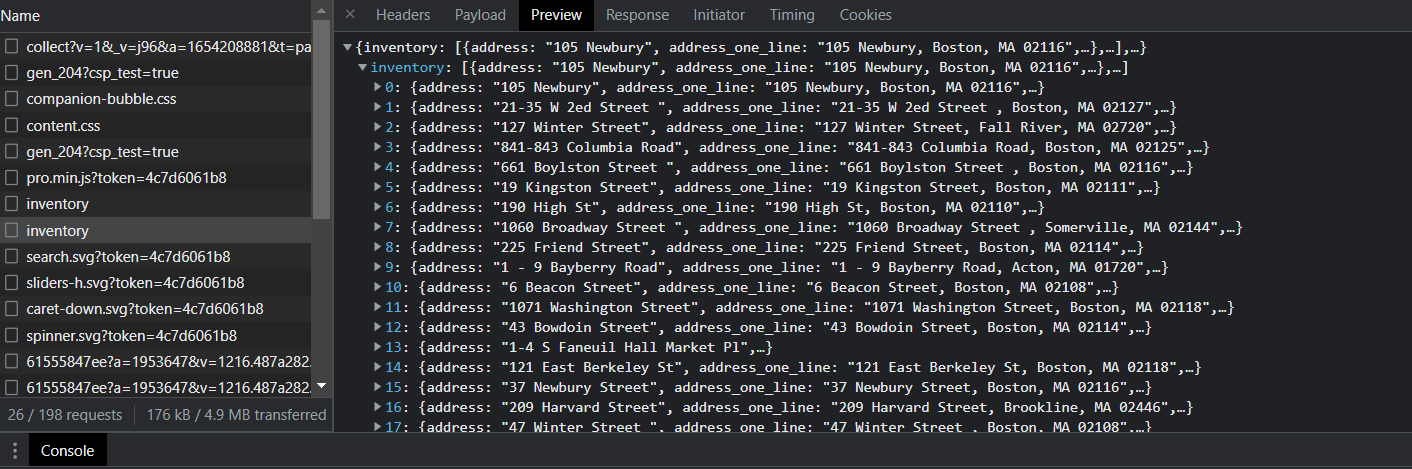
In the developer toolbox, choose the XHR (XML HTTP Request) tab. After browsing the requests sent to the server, I noticed something interesting. There are two requests called “inventory,” but in one, you have access to all the data on the first page in JSON.
Figure 3. A preview of the inventory (request sent to the server)
This information is great because it means that you don’t have to visit the main listing page on the Boston Realty Advisors website to get access to the data you want.
Now you are ready to begin scraping. (I did more inspections to better understand how to mimic the requests being made to the server, but that is beyond the scope of this post.)
Creating the Scrapy project
To set up the Scrapy project, first install scrapy. I recommend doing this step in a virtual environment.
pip install scrapy
After the virtual environment is activated, enter the following command:
scrapy startproject bradvisors
This command creates a Scrapy project called bradvisors. Scrapy also automatically adds some files to the directory.
After running the command, the final directory structure looks like the following tree:
So far, you’ve inspected the elements of the website to scrape and created the Scrapy project.
Building the spider
The spider module must be built in the bradvisors/bradvisors/spiders directory. The name of my spider script is bradvisors_spider.py but you can use a custom name.
The following code extracts the data from this website. The code example only runs successfully when the items.py file is updated. For more information, see the explanation after the example.
import json
import scrapy from bradvisors.items import BradvisorsItem
classBradvisorsSpider(scrapy.Spider): name = "bradvisors" start_urls = ["https://bradvisors.com/listings/"]
defparse(self, response): url = "https://buildout.com/plugins/5339d012fdb9c122b1ab2f0ed59a55ac0327fd5f/inventory" # There are 5 pages on the website for i in range(5): # Change the page number in the payload payload = f"utf8=%E2%9C%93&polygon_geojson=&lat_min=&lat_max=&lng_min=&lng_max=&mobile_lat_min= &mobile_lat_max=&mobile_lng_min=&mobile_lng_max=&page={str(i)}&map_display_limit=500&map_type=roadmap &custom_map_marker_url=%2F%2Fs3.amazonaws.com%2Fbuildout-production%2Fbrandings%2F7242%2Fprofile_photo %2Fsmall.png%3F1607371909&use_marker_clusterer=true&placesAutoComplete=&q%5Btype_use_offset_eq_any%5D%5B%5D= &q%5Bsale_or_lease_eq%5D=&q%5Bbuilding_size_sf_gteq%5D=&q%5Bbuilding_size_sf_lteq%5D=&q%5B listings_data_max_space_available_on_market_gteq%5D=&q%5Blistings_data_min_space_available_on_market_lteq %5D=&q%5Bproperty_research_property_year_built_gteq%5D=&q%5Bproperty_research_property_year_built_lteq %5D=&q%5Bproperty_use_id_eq_any%5D%5B%5D=&q%5Bcompany_office_id_eq_any%5D%5B%5D=&q%5Bs%5D%5B%5D=" # Crawl the data, given the payload yield scrapy.Request(method="POST", body=payload, url=url, headers=self.headers, callback=self.parse_api)
defparse_api(self, response): # Response is json, use loads to convert it into Python dictionary data = json.loads(response.body)
# Our item object defined in items.py item = BradvisorsItem()
Specifies that the parse method is the automatic call back when the scraper is run.
Defines the parse method, where you iterate through the number of pages to scrape, pass the page number to the payload, and yield that request. This calls back the parse_api method on each iteration.
Defines the parse_api method and converts the valid JSON response into a Python dictionary.
Defines the BradvisorsItem class in items.py (next code example).
Loops through all the listings in the inventory and scrapes specific elements.
# items.py
import scrapy
class BradvisorsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
address = scrapy.Field()
city = scrapy.Field()
city_state = scrapy.Field()
zip = scrapy.Field()
description = scrapy.Field()
size_summary = scrapy.Field()
item_url = scrapy.Field()
property_sub_type_name = scrapy.Field()
sale = scrapy.Field()
Next, you must execute the scrape to parse the data.
Running the scraper
Navigate to the project’s root directory from the command line (in this case, that is bradvisors). Run the following command:
scrapy crawl bradvisors -o data.csv
This command scrapes the Boston Realty Advisors website and saves the extracted data in a data.csv file in the project’s root directory.
Great, you have now acquired real estate data!
What’s next?
As the demand for big data grows, equipping yourself with the ability to acquire data with a web scraping tool is an extremely valuable skill set. Scraping data from the Internet can present several challenges. As well as acquiring the data that you require, your goal should be to treat websites respectfully and scrape them ethically.
Did you find this Scrapy tutorial helpful? Leave your feedback in the comments or connect with me:
No, web scraping is legal, given that the data you are scraping is public. Search engines such as Google scrape web data daily to curate search results for their users.
Is web scraping free?
You can pay for web scraping services to simplify the web scraping process. You could also learn a programming language and do it yourself for free.
Software teams comprise a broad range of professionals, from software engineers and data scientists to project managers and technical writers. Sharing code with…
Software teams comprise a broad range of professionals, from software engineers and data scientists to project managers and technical writers. Sharing code with other team members is common when working on a project, and it is important to track all changes. This is where pull requests come in.
In software development, a pull request is used to push local changes into a shared repository (Figure 1). It is a way for you to request code review from other collaborators before pushing an approved update to the central server. This helps maintain version control.
Figure 1. A pull request is used to push local changes into a shared repository
This post discusses the benefits of pull requests and shares tips for creating and handling pull requests when working on software projects. Using this information, you will be better equipped to work with many collaborators on major projects.
The steps of a pull request
To create a pull request, follow the steps outlined below.
Create a new git branch to work locally using the following command: git -b BRANCH_NAME
Implement changes and push them frequently (so that they do not get lost) using the following command: git add NAME_OF_THE_FILE git commit -m "DESCRIBE YOUR RECENT CHANGES"
After you have finished the implementation and committed your changes locally, you should get the latest changes from the shared repository to ensure there are no conflicting changes. You can get the latest changes using the following command: git pull origin BRANCH_NAME
Push your changes to the remote repository using the following command: git push --set-upstream-to origin REMOTE_BRANCH_NAME
Navigate to the user interface of the platform where your shared repository is located (GitLab, GitHub, BitBucket). There you are asked to write the name of the pull request and a short description. You also have the option to assign it to someone from your team to review it.
Whether you are working on the frontend or backend of a project, pull requests can help with the code review process when working with a team. This section details the key benefits of using pull requests in your work.
Facilitate collaboration
When it comes to collaboration, there are a few things that can make or break a team. One of those things is the ability to work together, even if members are responsible for different parts of the project.
Using pull requests, changes can be made without impacting the work of others. They are a great way to gather tips or code improvements from team members.
If you are unsure about a code change, submit a pull request for feedback. Other team members may have suggestions that you had not considered, and this can help you make better decisions about your code.
In any project, it is important to have experienced engineers review and accept or reject changes since you may miss some things that they can see from a fresh perspective.
However, it is equally important to avoid bottlenecks when multiple team members are submitting changes to the project codebase. For those working on pull requests, it is critical to set expectations for expected review times. This ensures the project continues to move forward.
Build features faster
Pull requests are a powerful tool that can help teams build features faster. Because pull requests can be reviewed with comments added, they provide an excellent way to communicate code changes.
First, they enable developers to submit changes to a project without having to wait for the project maintainer to merge the changes. This enables team members to work on code changes in parallel, which can speed up development.
Second, pull requests can be reviewed and comments can be added. Developers reviewing pull requests may need to ask questions or clarify potential errors. You can also use comments to share resources.
Third, pull requests can be merged, so that changes can be integrated into the project quickly and easily when building new features.
Reduce risks associated with adding new code
There is no doubt that programming code comes with a degree of risk. After all, every time you add something new to your codebase, you are potentially introducing new bugs and vulnerabilities that affect the end user.
Before a pull request is merged into the main codebase, other team members have the opportunity to review the changes to ensure compliance with the team’s coding standards. Bugs and errors can be addressed before they cause any problems in the live code.
With pull requests, you can always roll back to a previous version in case things go wrong. Pull requests become your safety net.
Improve code quality and performance
When you create a pull request, you are essentially asking for someone else to review your code and give feedback. By engaging a colleague, you can improve the quality of your code based on that feedback.
You can help reviewers understand your changes by writing descriptive commit messages and explanations in the description section of the pull request.
You can also avoid potential problems if you make a change that someone else does not agree with. They can simply raise an issue with your pull request. This gives you the opportunity to fix the problem before it becomes a bigger issue. This is a powerful way to improve the quality of your code.
Takeaways
Maintaining version control through pull requests is important for software teams. This approach enables team members to collaborate while tracking and managing changes to software systems. By using pull requests, teams can work on different parts of a system at the same time and then easily merge their changes together. This boosts team efficiency and prevents conflicts.
When used correctly, pull requests provide a clear and concise way to view changes that have been made to the code or file, facilitating discussion and feedback.
The importance of pull requests cannot be overstated. They are an essential part of the software development process, helping to ensure that relevant parties review code changes before they are merged into the main codebase. This helps to avoid bugs and other problems that could potentially cause serious issues.
Learn to train an end-to-end TTS system and track experiments in this live workshop on December 8. Set up the environment, review code blocks, test the model,…
Learn to train an end-to-end TTS system and track experiments in this live workshop on December 8. Set up the environment, review code blocks, test the model, and more.
Posted by Corey Lynch, Research Scientist, and Ayzaan Wahid, Research Engineer, Robotics at Google
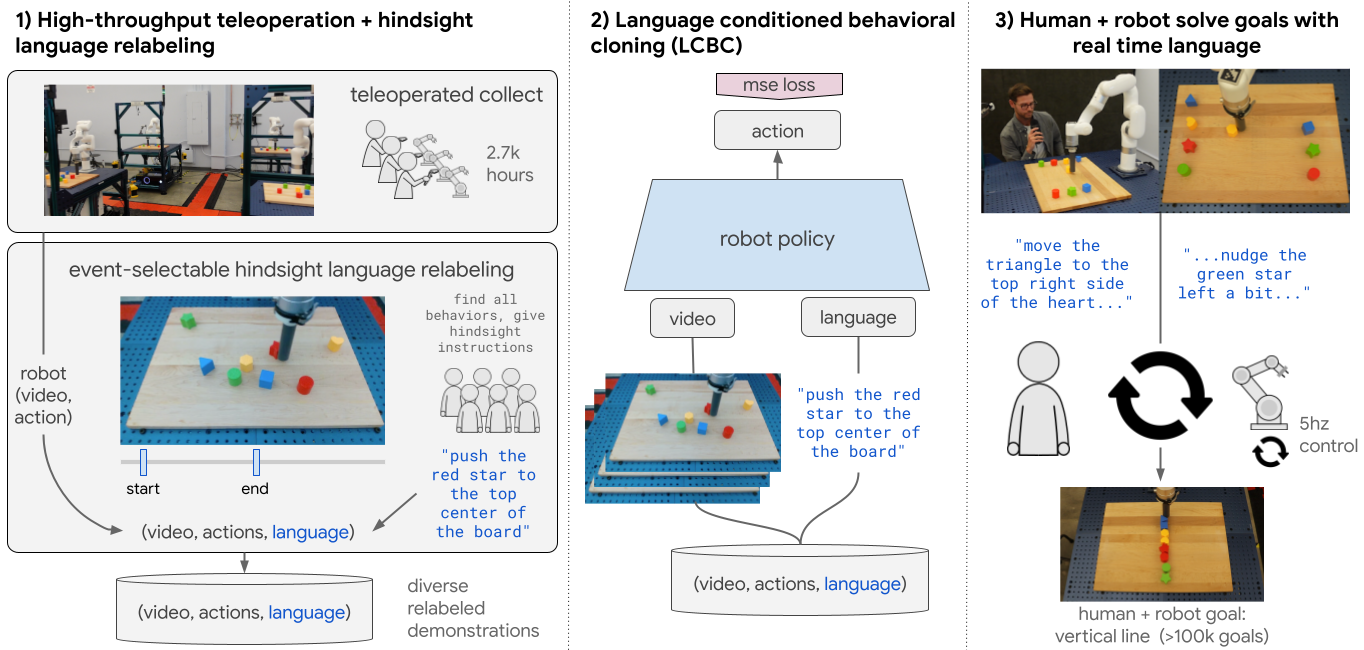
A grand vision in robot learning, going back to the SHRDLU experiments in the late 1960s, is that of helpful robots that inhabit human spaces and follow a wide variety of natural language commands. Over the last few years, there have been significant advances in the application of machine learning (ML) for instruction following, both insimulation and in real world systems. Recent Palm-SayCan work has produced robots that leverage language models to plan long-horizon behaviors and reason about abstract goals. Code as Policies has shown that code-generating language models combined with pre-trained perception systems can produce language conditioned policies for zero shot robot manipulation. Despite this progress, an important missing property of current “language in, actions out” robot learning systems is real time interaction with humans.
Ideally, robots of the future would react in real time to any relevant task a user could describe in natural language. Particularly in open human environments, it may be important for end users to customize robot behavior as it is happening, offering quick corrections (“stop, move your arm up a bit”) or specifying constraints (“nudge that slowly to the right”). Furthermore, real-time language could make it easier for people and robots to collaborate on complex, long-horizon tasks, with people iteratively and interactively guiding robot manipulation with occasional language feedback.
The challenges of open-vocabulary language following. To be successfully guided through a long horizon task like “put all the blocks in a vertical line”, a robot must respond precisely to a wide variety of commands, including small corrective behaviors like “nudge the red circle right a bit”.
However, getting robots to follow open vocabulary language poses a significant challenge from a ML perspective. This is a setting with an inherently large number of tasks, including many small corrective behaviors. Existing multitasklearning setups make use of curated imitation learning datasets or complex reinforcement learning (RL) reward functions to drive the learning of each task, and this significant per-task effort is difficult to scale beyond a small predefined set. Thus, a critical open question in the open vocabulary setting is: how can we scale the collection of robot data to include not dozens, but hundreds of thousands of behaviors in an environment, and how can we connect all these behaviors to the natural language an end user might actually provide?
In Interactive Language, we present a large scale imitation learning framework for producing real-time, open vocabulary language-conditionable robots. After training with our approach, we find that an individual policy is capable of addressing over 87,000 unique instructions (an order of magnitude larger than prior works), with an estimated average success rate of 93.5%. We are also excited to announce the release of Language-Table, the largest available language-annotated robot dataset, which we hope will drive further research focused on real-time language-controllable robots.
Guiding robots with real time language.
Real Time Language-Controllable Robots
Key to our approach is a scalable recipe for creating large, diverse language-conditioned robot demonstration datasets. Unlike prior setups that define all the skills up front and then collect curated demonstrations for each skill, we continuously collect data across multiple robots without scene resets or any low-level skill segmentation. All data, including failure data (e.g., knocking blocks off a table), goes through a hindsight language relabeling process to be paired with text. Here, annotators watch long robot videos to identify as many behaviors as possible, marking when each began and ended, and use freeform natural language to describe each segment. Importantly, in contrast to prior instruction following setups, all skills used for training emerge bottom up from the data itself rather than being determined upfront by researchers.
Our learning approach and architecture are intentionally straightforward. Our robot policy is a cross-attention transformer, mapping 5hz video and text to 5hz robot actions, using a standard supervised learning behavioral cloning objective with no auxiliary losses. At test time, new spoken commands can be sent to the policy (via speech-to-text) at any time up to 5hz.
Interactive Language: an imitation learning system for producing real time language-controllable robots.
Open Source Release: Language-Table Dataset and Benchmark
This annotation process allowed us to collect the Language-Table dataset, which contains over 440k real and 180k simulated demonstrations of the robot performing a language command, along with the sequence of actions the robot took during the demonstration. This is the largest language-conditioned robot demonstration dataset of its kind, by an order of magnitude. Language-Table comes with a simulated imitation learning benchmark that we use to perform model selection, which can be used to evaluate new instruction following architectures or approaches.
Dataset
# Trajectories (k)
# Unique (k)
Physical Actions
Real
Available
Episodic Demonstrations
BC-Z
25
0.1
✓
✓
✓
SayCan
68
0.5
✓
✓
❌
Playhouse
1,097
779
❌
❌
❌
Hindsight Language Labeling
BLOCKS
30
n/a
❌
❌
✓
LangLFP
10
n/a
✓
❌
❌
LOREL
6
1.7
✓
✓
✓
CALVIN
20
0.4
✓
❌
✓
Language-Table (real + sim)
623 (442+181)
206 (127+79)
✓
✓
✓
We compare Language-Table to existing robot datasets, highlighting proportions of simulated (red) or real (blue) robot data, the number of trajectories collected, and the number of unique language describable tasks.
Learned Real Time Language Behaviors
Examples of short horizon instructions the robot is capable of following, sampled randomly from the full set of over 87,000.
Short-Horizon Instruction
Success
(87,000 more…)
…
push the blue triangle to the top left corner
80.0%
separate the red star and red circle
100.0%
nudge the yellow heart a bit right
80.0%
place the red star above the blue cube
90.0%
point your arm at the blue triangle
100.0%
push the group of blocks left a bit
100.0%
Average over 87k, CI 95%
93.5% +- 3.42%
95% Confidence interval (CI) on the average success of an individual Interactive Language policy over 87,000 unique natural language instructions.
We find that interesting new capabilities arise when robots are able to follow real time language. We show that users can walk robots through complex long-horizon sequences using only natural language to solve for goals that require multiple minutes of precise, coordinated control (e.g., “make a smiley face out of the blocks with green eyes” or “place all the blocks in a vertical line”). Because the robot is trained to follow open vocabulary language, we see it can react to a diverse set of verbal corrections (e.g., “nudge the red star slightly right”) that might otherwise be difficult to enumerate up front.
Examples of long horizon goals reached under real time human language guidance.
Finally, we see that real time language allows for new modes of robot data collection. For example, a single human operator can control four robots simultaneously using only spoken language. This has the potential to scale up the collection of robot data in the future without requiring undivided human attention for each robot.
One operator controlling multiple robots at once with spoken language.
Conclusion
While currently limited to a tabletop with a fixed set of objects, Interactive Language shows initial evidence that large scale imitation learning can indeed produce real time interactable robots that follow freeform end user commands. We open source Language-Table, the largest language conditioned real-world robot demonstration dataset of its kind and an associated simulated benchmark, to spur progress in real time language control of physical robots. We believe the utility of this dataset may not only be limited to robot control, but may provide an interesting starting point for studying language- and action-conditioned video prediction, robot video-conditioned language modeling, or a host of other interesting active questions in the broader ML context. See our paper and GitHub page to learn more.
Acknowledgements
We would like to thank everyone who supported this research. This includes robot teleoperators: Alex Luong, Armando Reyes, Elio Prado, Eric Tran, Gavin Gonzalez, Jodexty Therlonge, Joel Magpantay, Rochelle Dela Cruz, Samuel Wan, Sarah Nguyen, Scott Lehrer, Norine Rosales, Tran Pham, Kyle Gajadhar, Reece Mungal, and Nikauleene Andrews; robot hardware support and teleoperation coordination: Sean Snyder, Spencer Goodrich, Cameron Burns, Jorge Aldaco, Jonathan Vela; data operations and infrastructure: Muqthar Mohammad, Mitta Kumar, Arnab Bose, Wayne Gramlich; and the many who helped provide language labeling of the datasets. We would also like to thank Pierre Sermanet, Debidatta Dwibedi, Michael Ryoo, Brian Ichter and Vincent Vanhoucke for their invaluable advice and support.

 Learn the fundamental tools and techniques for accelerating C/C++ applications to run on massively parallel GPUs with CUDA in this instructor-led workshop.
Learn the fundamental tools and techniques for accelerating C/C++ applications to run on massively parallel GPUs with CUDA in this instructor-led workshop. Data is one of the most valuable assets that a business can possess. It sits at the core of data science and data analysis: without data, they’re both…
Data is one of the most valuable assets that a business can possess. It sits at the core of data science and data analysis: without data, they’re both…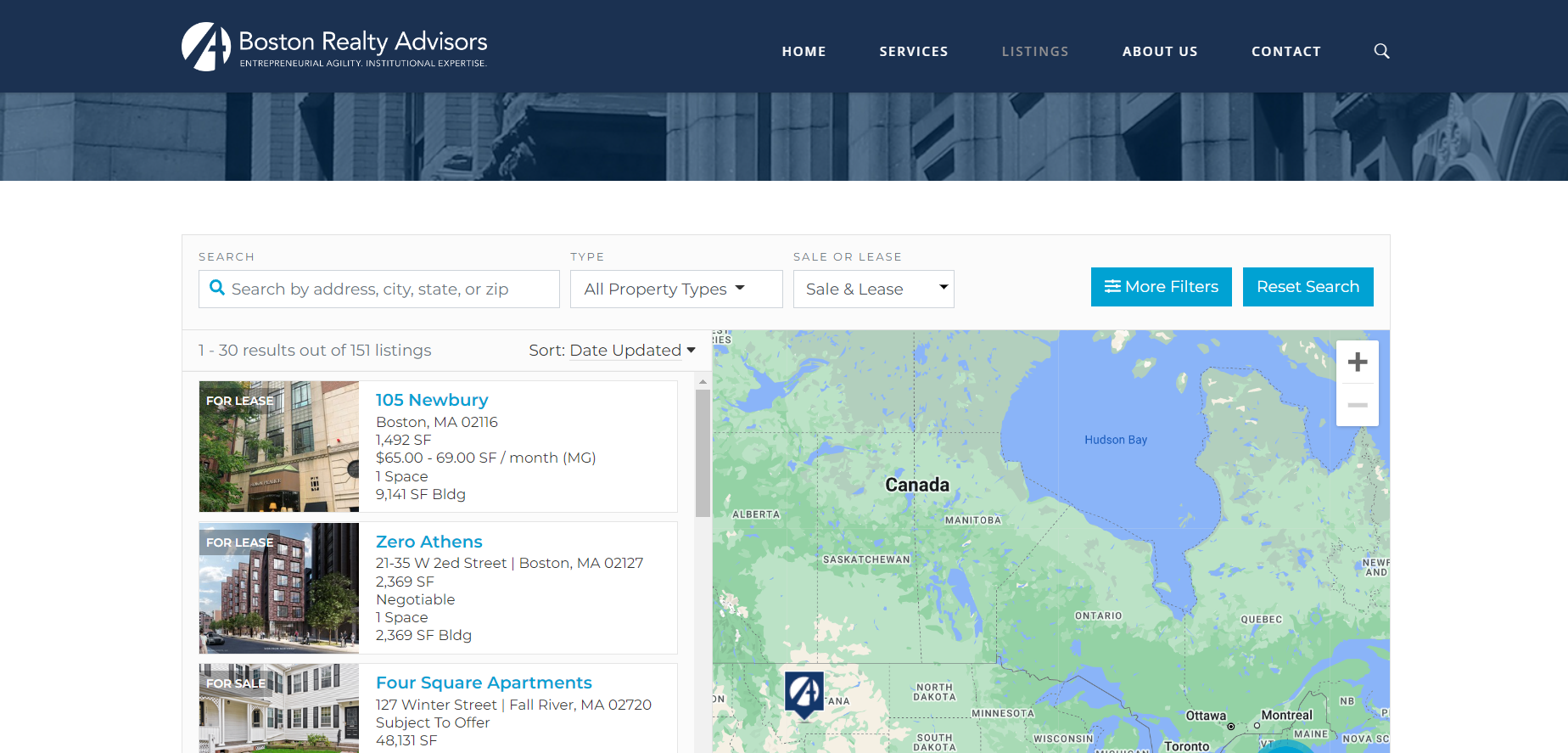
 A smart hospital relies on data-driven insights, including machine learning models and AI-powered medical devices, to facilitate decision-making.
A smart hospital relies on data-driven insights, including machine learning models and AI-powered medical devices, to facilitate decision-making. Software teams comprise a broad range of professionals, from software engineers and data scientists to project managers and technical writers. Sharing code with…
Software teams comprise a broad range of professionals, from software engineers and data scientists to project managers and technical writers. Sharing code with…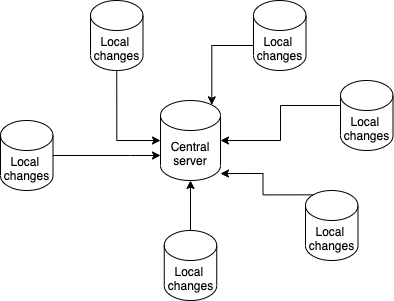
 Learn to train an end-to-end TTS system and track experiments in this live workshop on December 8. Set up the environment, review code blocks, test the model,…
Learn to train an end-to-end TTS system and track experiments in this live workshop on December 8. Set up the environment, review code blocks, test the model,…