NVIDIA Modulus is a framework for building, training, and fine-tuning deep learning models for physical systems, otherwise known as physics-informed machine…
NVIDIA Modulus is a framework for building, training, and fine-tuning deep learning models for physical systems, otherwise known as physics-informed machine…
NVIDIA Modulus is a framework for building, training, and fine-tuning deep learning models for physical systems, otherwise known as physics-informed machine learning (physics-ML) models. Modulus is available as OSS (Apache 2.0 license) to support the growing physics-ML community.
The latest Modulus software update, version 23.05, brings together new capabilities, empowering the research community and industries to develop research into enterprise-grade solutions through open-source collaboration.
Two major components of this update are 1) supporting new network architectures that include graph neural networks (GNNs) and recurrent neural networks (RNNs), and 2) improving the ease of use for AI practitioners.
Graph neural network support
GNNs are transforming how researchers are addressing challenges involving intricate graph structures, such as those encountered in physics, biology, and social networks. By leveraging the structure of graphs, GNNs are capable of learning and making predictions based on the relationships among nodes in a graph.
Through the application of GNNs, researchers can model systems to be represented as graphs or meshes. This capability is useful in applications such as computational fluid dynamics, molecular dynamics simulations, and material science.
Using GNNs, researchers can better understand the behavior of complex systems with complex geometries, and generate more accurate predictions based on the learned patterns and interactions within the data.
The latest version of NVIDIA Modulus includes support for GNNs. This enables you to develop your own GNN-based models for specific use cases. Modulus includes recipes that use the MeshGraphNet architecture based on the work presented in Learning Mesh-Based Simulation with Graph Networks. Such architectures can now be trained in Modulus, which includes a MeshGraphNet model pretrained on a parameterized vortex shedding dataset. This pretrained model is available through NVIDIA NGC.
Modulus also includes the GraphCast architecture proposed in GraphCast: Learning Skillful Medium-Range Global Weather Forecasting. GraphCast is a novel GNN-based architecture for global weather forecasting. It significantly improves on some existing models by effectively capturing spatio-temporal relationships in weather data. The weather data is modeled as a graph, where nodes represent Earth grid cells. This graph-based representation enables the model to capture both local and non-local dependencies in the data.
The architecture of GraphCast consists of four main components: embedder, encoder, processor, and decoder. The embedder component embeds the input features into a latent representation. The encoder maps the local regions of the grid’s latent features into nodes of a multi-mesh graph representation. The processor updates each multi-mesh node using learned message-passing.
Finally, the decoder maps the processed multi-mesh features back onto the grid representation. The multi-mesh is a set of icosahedral meshes with increasing resolution, providing uniform resolution across the globe. A recipe for training GraphCast on the ERA-5 dataset with support for data parallelism is provided in Modulus-Launch. Figure 1 shows the out-of-sample prediction for the 2-meter temperature using a GraphCast model trained in Modulus on a 34-variable subset of the ERA-5 dataset.
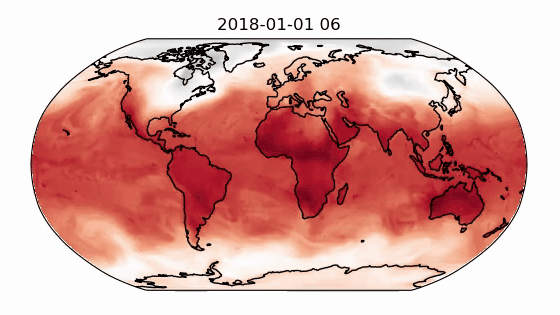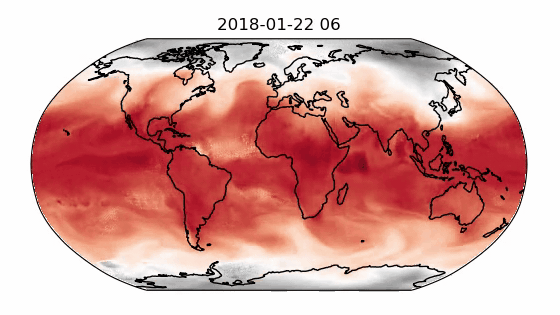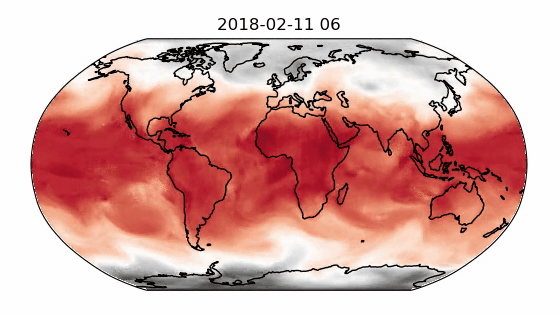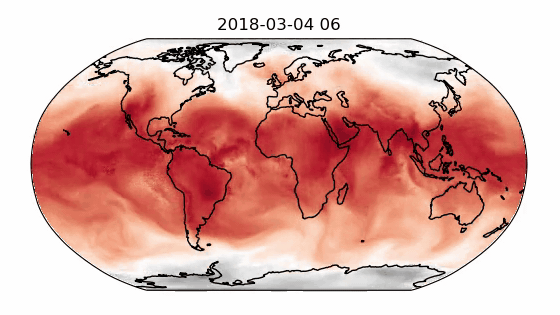
The GraphCast implementation supports gradient checkpointing for reducing the memory overhead. It also provides several optimizations including CuGraphOps support, fused layer norm and Adam optimizer using Apex, efficient edge feature updates, and more.
Recurrent neural network support
Time-series prediction is a key task in many domains. The application of deep learning architectures—particularly RNNs, long short-term memory networks (LSTMs), and similar networks—has significantly enhanced the predictive capabilities.
These models are unique in their ability to capture temporal dependencies and learn complex patterns over time, making them well suited for forecasting time varying relationships. In physics-ML, these models are critical in predicting dynamic physical systems’ evolution, enabling better simulations, understanding of complex natural phenomena, and aiding in discoveries.
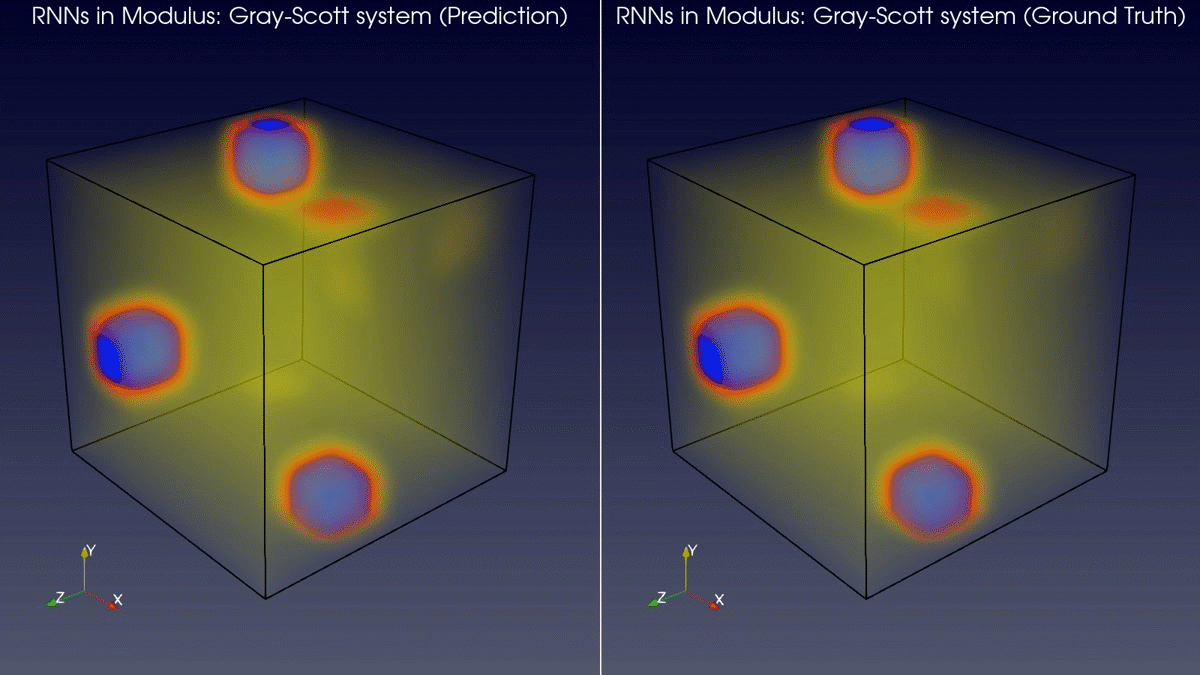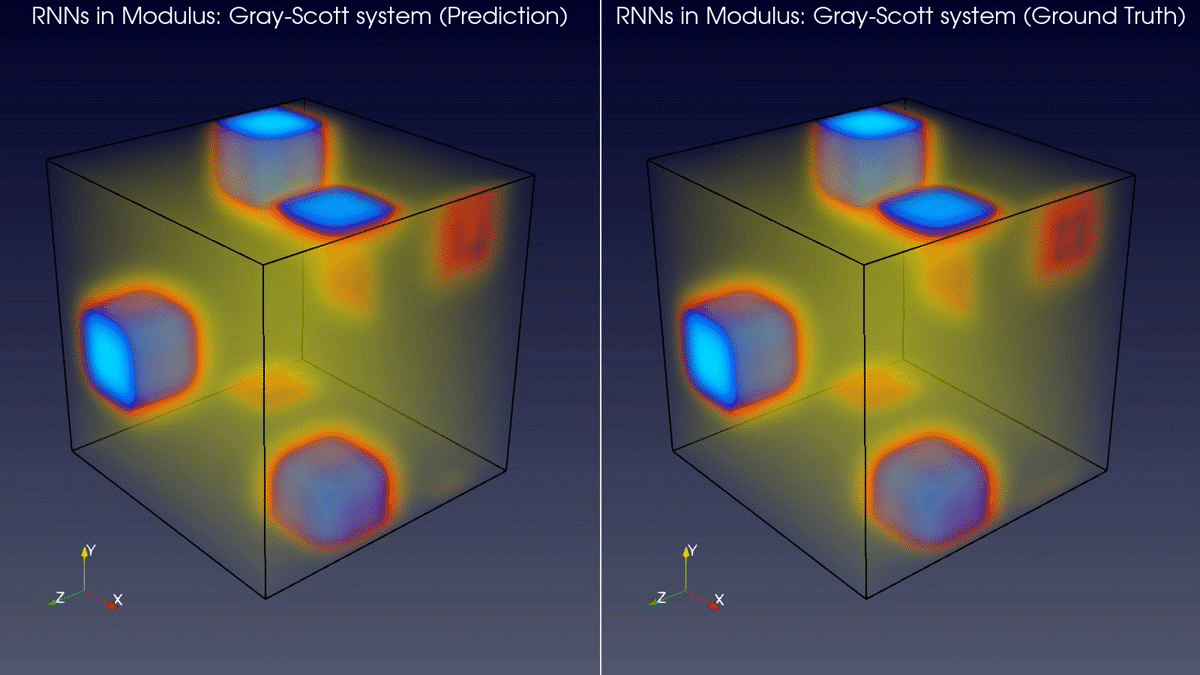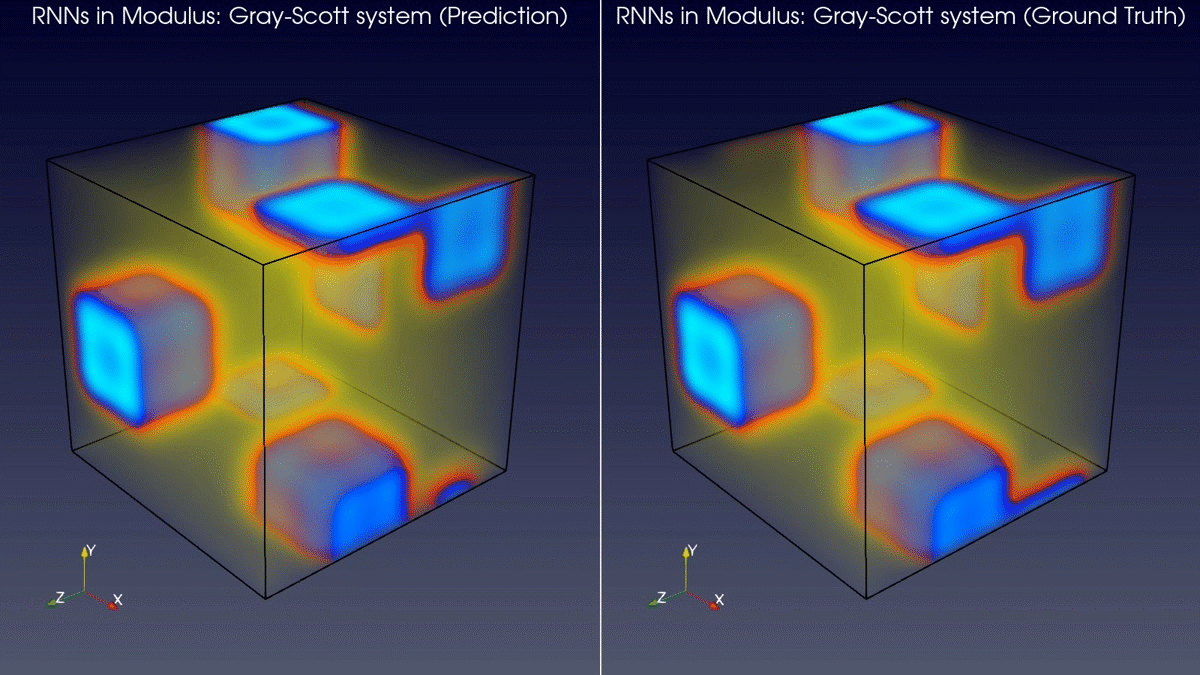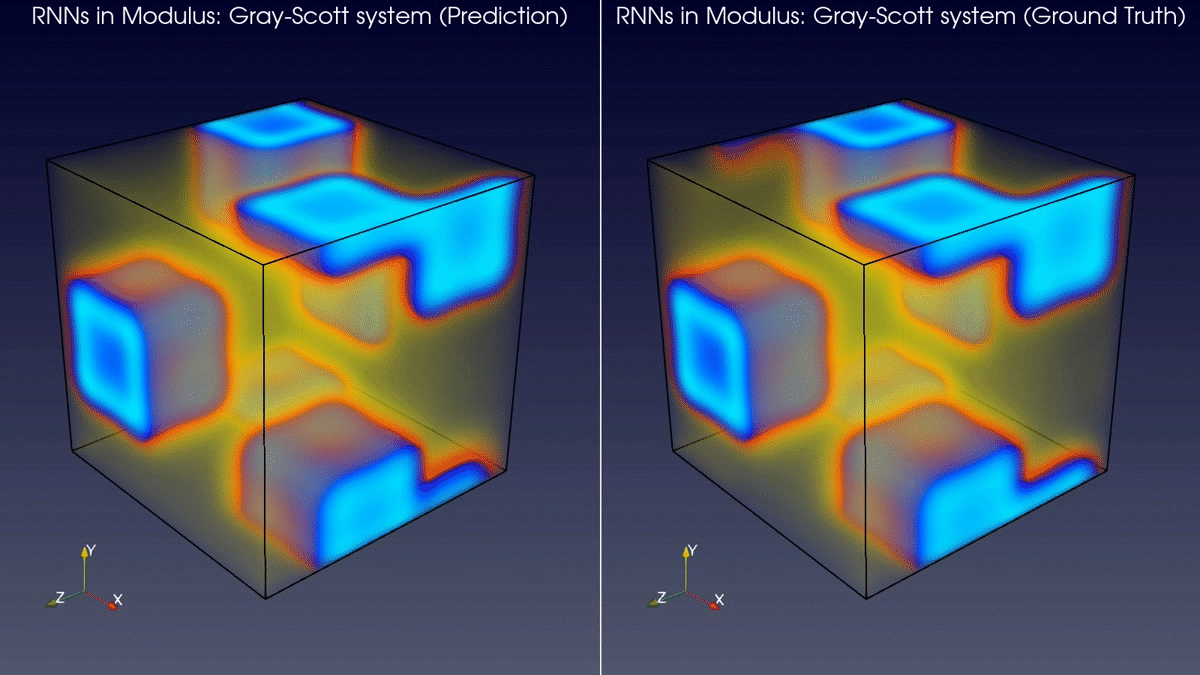
The latest version of Modulus has added support for RNN type layers and models. This enables you to use RNNs for 2D spatial domains and 3D spatial domains in model prediction workflows. Figure 2 shows a comparison between the predictions of a RNN model in Modulus and the ground truth for a Gray-Scott system.
Modules for ease of use
The Modulus codebase has been re-architected into modules to facilitate ease of use. This is in line with PyTorch, which has become one of the most popular deep learning frameworks for researchers over the past few years, given the ease of use.
The core Modulus module consists of the core framework and algorithms for physics-ML models. The Modulus-Launch module consists of optimized training recipes for accelerating PyTorch-like workflows for training models. This module enables AI researchers to have a PyTorch-like experience. NVIDIA Modulus Sym is a module based on the symbolic partial differential equation (PDE) that domain experts can use to train PDE-based physics-ML models.
One key feature of modern deep learning frameworks is their interoperability. This Modulus release makes it easier for AI developers to bring PyTorch models into Modulus and vice versa. This helps to ensure that models can be shared and reused across different platforms and environments.
For more details about all the new features in Modulus 23.05, see the Modulus release notes.
Start using GNNs for physics-ML today
To learn more and get started with NVIDIA Modulus, see the NVIDIA Deep Learning Institute course, Introduction to Physics-Informed Machine Learning with Modulus. Kick-start your Modulus experience with the LaunchPad for Modulus free hands-on lab. With short-term access provided, there is no need to set up your own compute environment.
To try Modulus in your own environment, download the latest Modulus container or install the Modulus pip wheels. To customize and contribute to the Modulus open-source framework, visit the NVIDIA/modulus repo on GitHub.







 Voice-enabled technology is becoming ubiquitous. But many are being left behind by an anglocentric and demographically biased algorithmic world. Mozilla Common…
Voice-enabled technology is becoming ubiquitous. But many are being left behind by an anglocentric and demographically biased algorithmic world. Mozilla Common… CUDA kernel function parameters are passed to the device through constant memory and have been limited to 4,096 bytes. CUDA 12.1 increases this parameter limit…
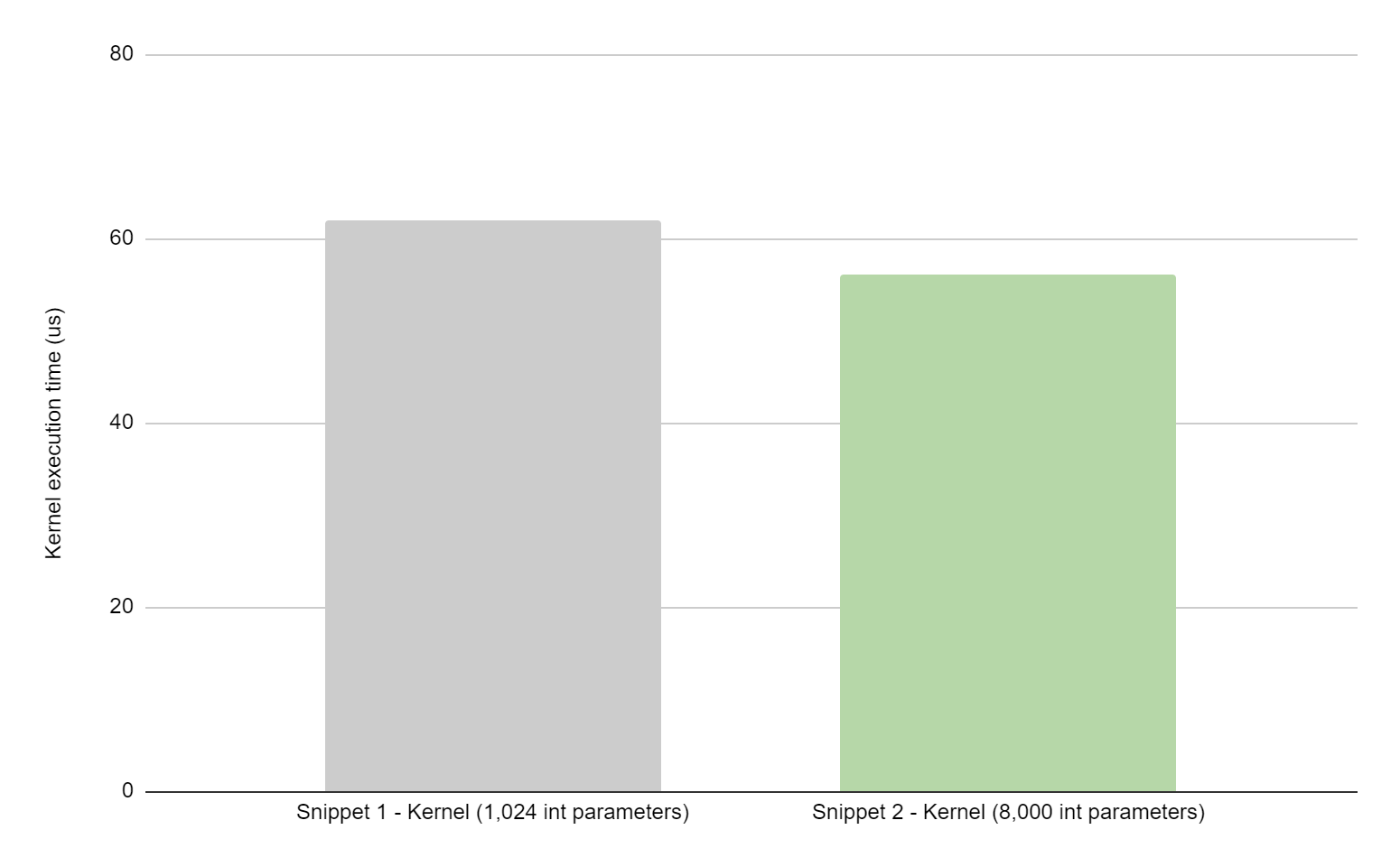
CUDA kernel function parameters are passed to the device through constant memory and have been limited to 4,096 bytes. CUDA 12.1 increases this parameter limit…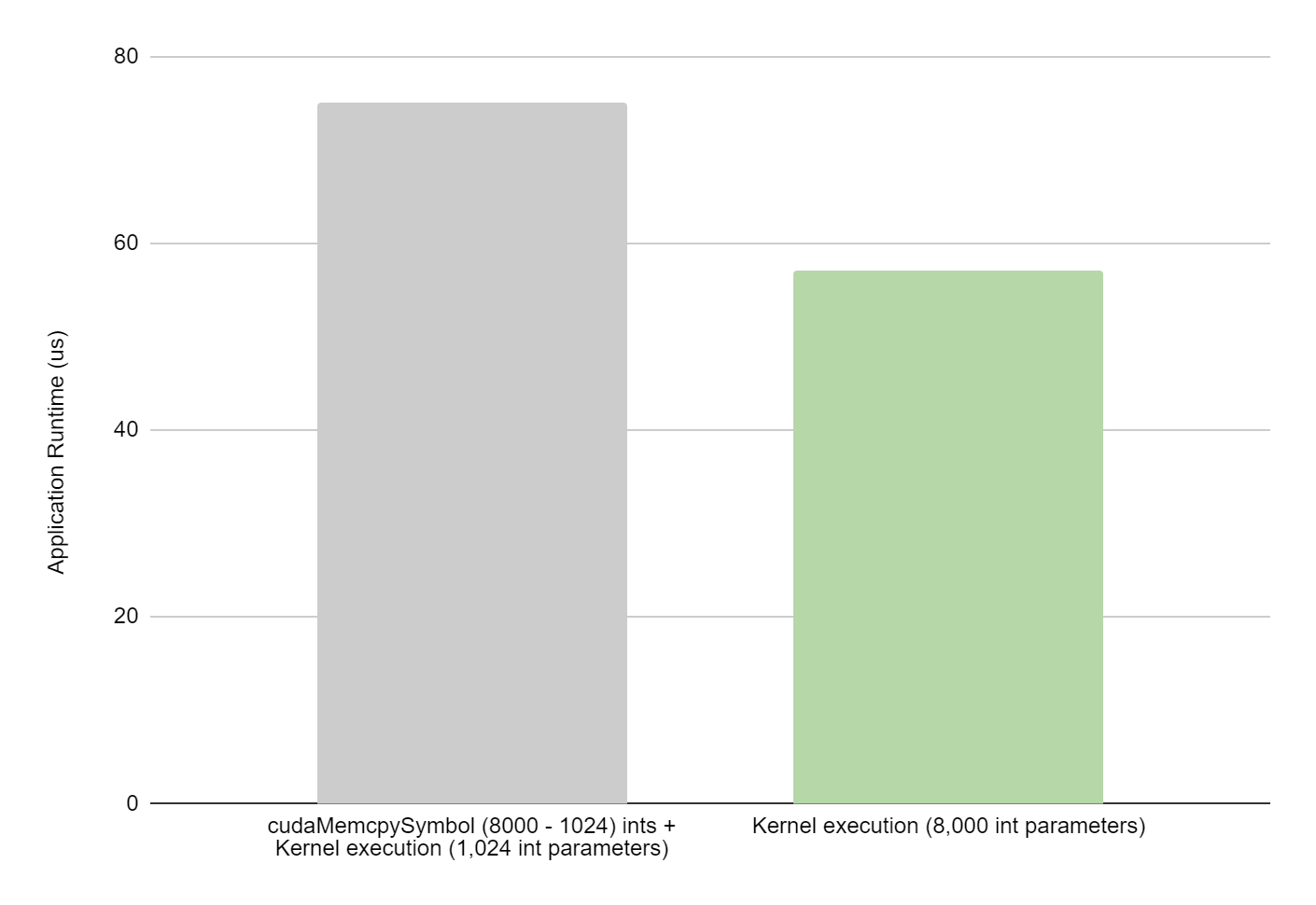
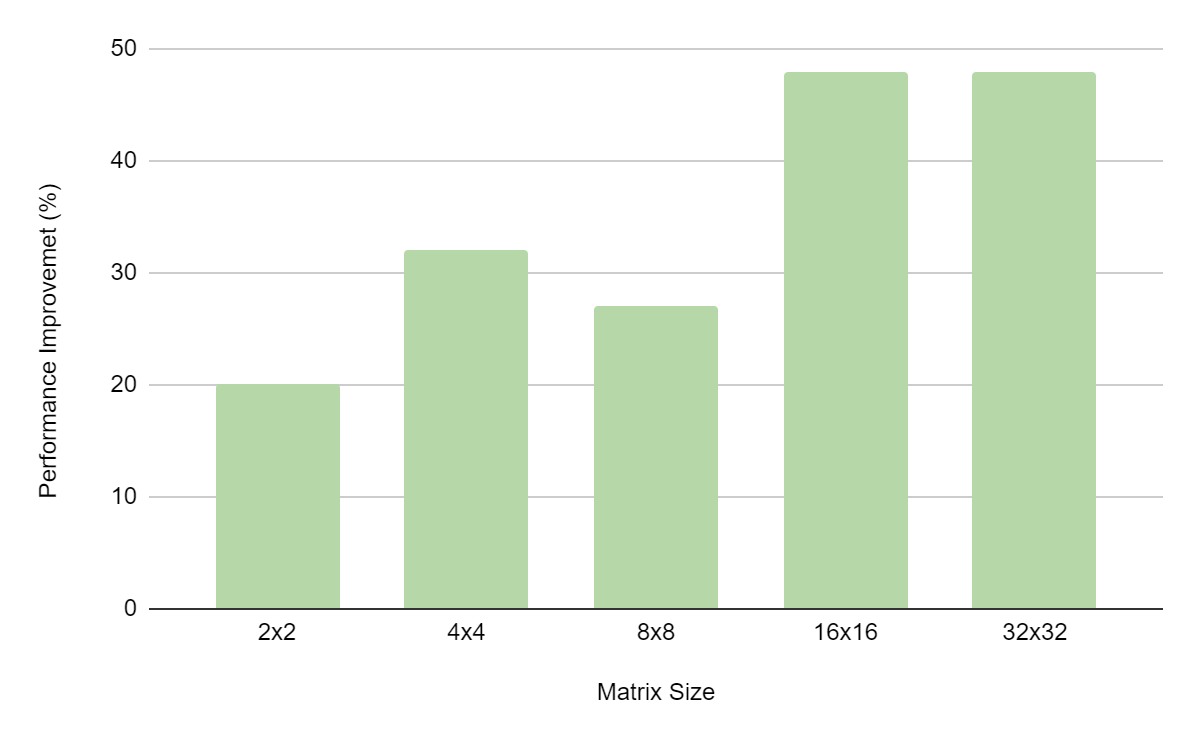
 The NVIDIA Jetson Orin Nano and Jetson AGX Orin Developer Kits are now available at a discount for qualified students, educators, and researchers.Since its…
The NVIDIA Jetson Orin Nano and Jetson AGX Orin Developer Kits are now available at a discount for qualified students, educators, and researchers.Since its…


 AI is transforming industries, automating processes, and opening new opportunities for innovation in the rapidly evolving technological landscape. As more…
AI is transforming industries, automating processes, and opening new opportunities for innovation in the rapidly evolving technological landscape. As more…