
 Extract-transform-load (ETL) operations with GPUs using the NVIDIA RAPIDS Accelerator for Apache Spark running on large-scale data can produce both cost savings…
Extract-transform-load (ETL) operations with GPUs using the NVIDIA RAPIDS Accelerator for Apache Spark running on large-scale data can produce both cost savings…
Extract-transform-load (ETL) operations with GPUs using the NVIDIA RAPIDS Accelerator for Apache Spark running on large-scale data can produce both cost savings and performance gains. We demonstrated this in our previous post, GPUs for ETL? Run Faster, Less Costly Workloads with NVIDIA RAPIDS Accelerator for Apache Spark and Databricks. In this post, we dive deeper to identify precisely which Apache Spark SQL operations are accelerated for a given processing architecture.
This post is part of a series on GPUs and extract-transform-load (ETL) operations.
Migrating ETL to GPUs
Should all ETL be migrated to GPUs? Or is there an advantage to evaluating which processing architecture is best suited to specific Spark SQL operations?
CPUs are optimized for sequential processing with significantly fewer yet faster individual cores. There are clear computational advantages for memory management, handling I/O operations, running operating systems, and so on.
GPUs are optimized for parallel processing with significantly more yet slower cores. GPUs excel at rendering graphics, training, machine learning and deep learning models, performing matrix calculations, and other operations that benefit from parallelization.
Experimental design
We created three large, complex datasets modeled after real client retail sales data using computationally expensive ETL operations:
- Aggregation (SUM + GROUP BY)
- CROSS JOIN
- UNION
Each dataset was specifically curated to test the limits and value of specific Spark SQL operations. All three datasets were modeled based on a transactional sales dataset from a global retailer. The row size, column count, and type were selected to balance experimental processing costs while performing tests that would demonstrate and evaluate the benefits of both CPU and GPU architectures under specific operating conditions. See Table 1 for data profiles.
| Operation | Rows | # COLUMNS: Structured data | # COLUMNS: Unstructured data | Size (MB) |
| Aggregation (SUM + GROUP BY) | 94.4 million | 2 | 0 | 3,200 |
| CROSS JOIN | 63 billion | 6 | 1 | 983 |
| UNION | 447 million | 10 | 2 | 721 |
The following computational configurations were evaluated for this experiment:
- Worker and driver type
- Workers [minimum and maximum]
- RAPIDS or Photon deployment
- Maximal hourly limits on Databricks units (DBUs)—a proprietary measure of Databricks compute cost
| Worker and driver type | Workers [min/max] | RAPIDS Accelerator / PHOTON | Max DBUs / hour |
| Standard_NC4as_T4_v3 | 1/1 | RAPIDS Accelerator | 2 |
| Standard_NC4as_T4_v3 | 2/8 | RAPIDS Accelerator | 9 |
| Standard_NC8as_T4_v3 | 2/2 | RAPIDS Accelerator | 4.5 |
| Standard_NC8as_T4_v3 | 2/8 | RAPIDS Accelerator | 14 |
| Standard_NC16as_T4_v3 | 2/2 | RAPIDS Accelerator | 7.5 |
| Standard_NC16as_T4_v3 | 2/8 | RAPIDS Accelerator | 23 |
| Standard_E16_v3 | 2/2 | Photon | 24 |
| Standard_E16_v3 | 2/8 | Photon | 72 |
Other experimental considerations
In addition to building industry-representative test datasets, other experimental factors are listed below.
- Datasets are run using several different worker and driver configurations on pay-as-you-go instances–as opposed to spot instances–as their inherent availability establishes pricing consistency across experiments.
- For GPU testing, we leveraged RAPIDS Accelerator on T4 GPUs, which are optimized for analytics-heavy loads, and carry a substantially lower cost per DBU.
- The CPU worker type is an in-memory optimized architecture which uses Intel Xeon Platinum 8370C (Ice Lake) CPUs.
- We also leveraged Databricks Photon, a native CPU accelerator solution and accelerated version of their traditional Java runtime, rewritten in C++.
These parameters were chosen to ensure experimental repeatability and applicability to common use cases.
Results
To evaluate experimental results in a consistent fashion, we developed a composite metric named adjusted DBUs per minute (ADBUs). ADBUs are based on DBUs and computed as follows:

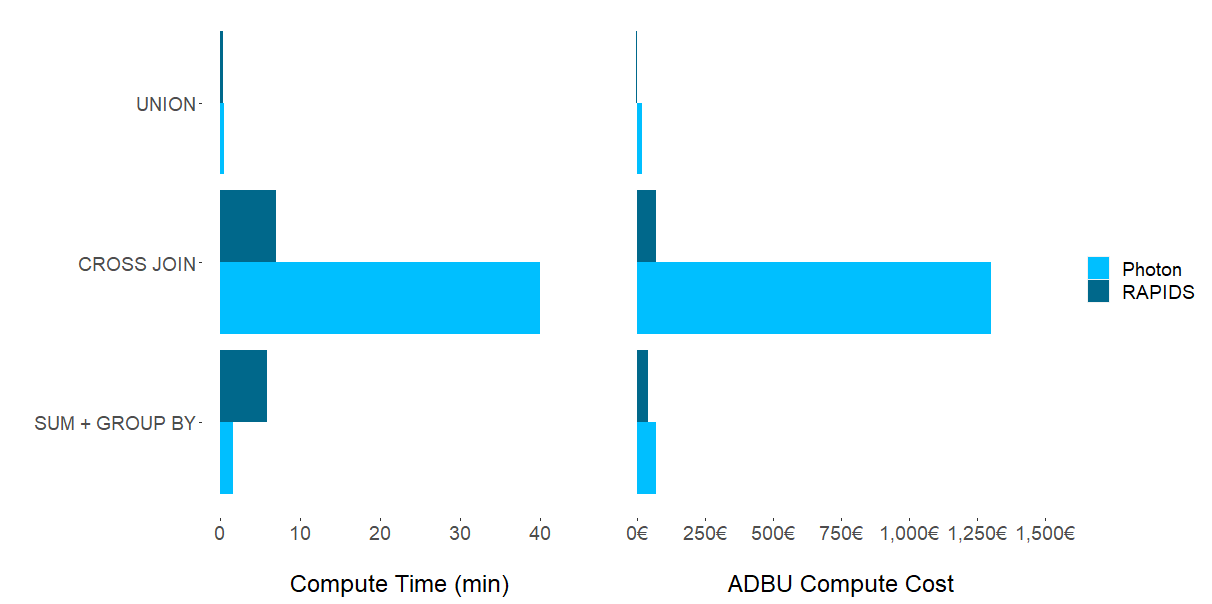
Experimental results demonstrate that there is no computational Spark SQL task in which one chipset–GPU or CPU–dominates. As Figure 1 shows, dataset characteristics and the suitability of a cluster configuration have the strongest impact on which framework to choose for a specific task. Although unsurprising, the question remains: which ETL processes should be migrated to GPUs?
UNION operations
Although RAPIDS Accelerator on T4 GPUs generate results having both lower costs and execution times with UNION operations, the difference when compared with CPUs is negligible. Moving an existing ETL pipeline from CPUs to GPUs seems unwarranted for this combination of dataset and Spark SQL operation. It is likely–albeit untested by this research–that a larger dataset may generate results that warrant a move to GPUs.
CROSS JOIN operations
For the compute-heavy CROSS JOIN operation, we observed an order of magnitude of both time and cost savings by employing RAPIDS Accelerator (GPUs) over Photon (CPUs).
One possible explanation for these performance gains is that the CROSS JOIN is a Cartesian product that involves an unstructured data column being multiplied with itself. This leads to exponentially increasing complexity. The performance gains of GPUs are well suited for this type of large-scale parallelizable operation.
The main driver of cost differences is that the CPU clusters we experimented with had a much higher DBU rating than the chosen GPU clusters.
SUM + GROUP BY operations
For aggregation operations (SUM + GROUP BY), we observed mixed results. Photon (CPUs) delivered notably faster compute times, whereas RAPIDS Accelerator (GPUs) provided lower overall costs. Looking at individual experimental runs, we observed that the higher Photon costs result in higher DBUs, whereas the costs associated with T4s are significantly lower.
This explains the lower overall cost using RAPIDS Accelerator in this part of the experiment. In summary, if speed is the objective, Photon is the clear winner. More price-conscious users may prefer the longer compute times of RAPIDS Accelerator for notable cost savings.
Deciding which architecture to use
The CPU cluster gained performance in execution time in the commonly used aggregation (SUM + GROUP BY) experiment. However, this came at the price of higher associated cluster costs. For CROSS JOINs, a less common high-compute and highly-parallelizable operation, GPUs dominated both in higher speed and lower costs. UNIONs showed negligible comparative differences in compute time and cost.
Where GPUs (and by association RAPIDS Accelerator) will excel depends largely on the data structure, the scale of the data, the ETL operation(s) performed, and the user’s technical depth.
GPUs for ETL
In general, GPUs are well suited to large, complex datasets and Spark SQL operations that are highly parallelizable. The experimental results suggest using GPUs for CROSS JOIN situations, as they are amenable to parallelization, and can also scale easily as data grows in size and complexity.
It is important to note the scale of data is less important than the complexity of the data and the selected operation, as shown in the SUM + GROUP BY experiment. (This experiment involved more data, but less computational complexity compared to CROSS JOINs.) You can work with NVIDIA free of charge to estimate expected GPU acceleration gains based on analyses of Spark log files.
CPUs for ETL
Based on the experiments, certain Spark SQL operations such as UNIONs showed a negligible difference in cost and compute time. A shift to GPUs may not be warranted in this case. Moreover, for aggregations (SUM + GROUP BY), a conscious choice of speed over cost can be made based on situational requirements, where CPUs will execute faster, but at a higher cost.
In cases where in-memory calculations are straightforward, staying with an established CPU ETL architecture may be ideal.
Discussion and future considerations
This experiment explored one-step Spark SQL operations. For example, a singular CROSS JOIN, or a singular UNION, omitting more complex ETL jobs that involve multiple steps. An interesting future experiment might include optimizing ETL processing at a granular level, sending individual SparkSQL operations to CPUs or GPUs in a single job or script, and optimizing for both time and compute cost.
A savvy Spark user might try to focus on implementing scripting strategies to make the most of the default runtime, rather than implementing a more efficient paradigm. Examples include:
- Spark SQL join strategies (broadcast join, shuffle merge, hash join, and so on)
- High-performing data structures (storing data in parquet files that are highly performant in a cloud architecture as compared to text files, for example)
- Strategic data caching for reuse
The results of our experiment indicate that leveraging GPUs for ETL can supply additional performance sufficient to warrant the effort to implement a GPU architecture.
Although supported, RAPIDS Accelerator for Apache Spark is not available by default on Azure Databricks. This requires the installation of .jar files that may necessitate some debugging. This tech debt was largely paid going forward, as subsequent uses of RAPIDS Accelerator were seamless and straightforward. NVIDIA support was always readily available to help if and when necessary.
Finally, we opted to keep all created clusters under 100 DBUs per hour to manage experimental costs. We tried only one size of Photon cluster. Experimental results may change by varying the cluster size, number of workers, and other experimental parameters. We feel these results are sufficiently robust and relevant for many typical use cases in organizations running ETL jobs.
Conclusion
NVIDIA T4 GPUs, designed specifically for analytics workloads, accomplish a leap in the price/performance ratio associated with leveraging GPU-based compute. NVIDIA RAPIDS Accelerator for Apache Spark, especially when run on NVIDIA T4 GPUs, has the potential to significantly reduce costs and execution times for certain common ETL SparkSQL operations, particularly those that are highly parallelizable.
To implement this solution on your own Apache Spark workload with no code changes, visit the NVIDIA/spark-rapids-examples GitHub repo or the Apache Spark tool page for sample code and applications that showcase the performance and benefits of using RAPIDS Accelerator in your data processing or machine learning pipelines.