
 NVIDIA cuSPARSELt v0.2 now supports ReLu and GeLu activation functions, bias vector, and batched Sparse GEMM.
NVIDIA cuSPARSELt v0.2 now supports ReLu and GeLu activation functions, bias vector, and batched Sparse GEMM.
Today, NVIDIA is announcing the availability of cuSPARSELt, version 0.2.0, which increases performance on activation functions, bias vectors, and Batched Sparse GEMM. This software can be downloaded now free of charge.
Download the cuSPARSELt software.
What’s New?
- Support for activation functions and bias vector:
- ReLU + upper bound and threshold setting for all kernels.
- GeLU for
INT8I/O,INT32Tensor Core compute kernels.
- Support for Batched Sparse GEMM:
- Single sparse matrix / Multiple dense matrices (Broadcast).
- Multiple sparse and dense matrices.
- Batched bias vector.
- Compatibility notes:
- cuSPARSELt does not require the nvrtc library anymore.
- Support for Ubuntu 16.04 (gcc-5) is now deprecated and it will be removed in future releases.
For more technical information, see the cuSPARSELt Release Notes.
About cuSPARSELt
NVIDIA cuSPARSELt is a high-performance CUDA library dedicated to general matrix-matrix operations in which at least one operand is a sparse matrix:
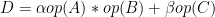
In this equation, 

The cuSPARSELt APIs provide flexibility in the algorithm/operation selection, epilogue, and matrix characteristics, including memory layout, alignment, and data types.
Key Features
- NVIDIA Sparse MMA Tensor Core support.
- Mixed-precision computation support:
FP16I/O,FP32Tensor Core accumulate.BFLOAT16I/O,FP32Tensor Core accumulate.INT8I/O,INT32Tensor Core compute.FP32I/O,TF32Tensor Core compute.TF32I/O,TF32Tensor Core compute.
- Matrix pruning and compression functionalities.
- Auto-tuning functionality (see cusparseLtMatmulSearch()).
Learn more
- For more about Math Libraries, see Recent Developments in NVIDIA Math Libraries (GTC 2021 #S31754).
- To get the latest on HPC software, see A Deep Dive into the latest HPC software (GTC 2021 #S31286).
- Catch up on Tensor Core-Accelerated Math Libraries for Dense and Sparse Linear Algebra in AI and HPC (GTC 2021 #CWES1098).
- Read technical details in our cuSPARSELt Product Documentation.
Recent Developer posts
- For advanced matrix multiply techniques, read Accelerating Matrix Multiplication with Block Sparse Format and NVIDIA Tensor Cores.
- To leverage NVIDIA Ampere architecture performance, read Exploiting NVIDIA Ampere Structured Sparsity with cuSPARSELt.
- To benefit from A100 acceleration, read Getting Immediate Speedups with NVIDIA A100 TF32.
- To gain AI training benefits, see Accelerating AI Training with NVIDIA TF32 Tensor Cores.