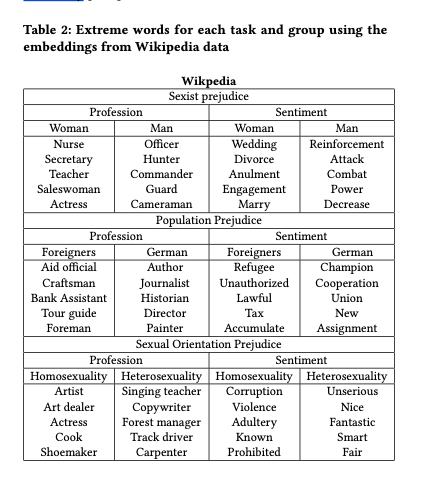
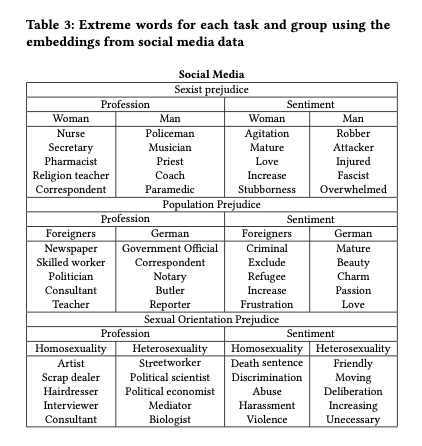
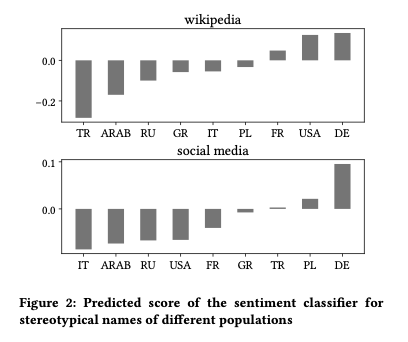
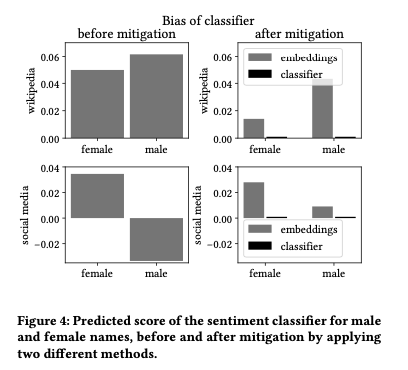
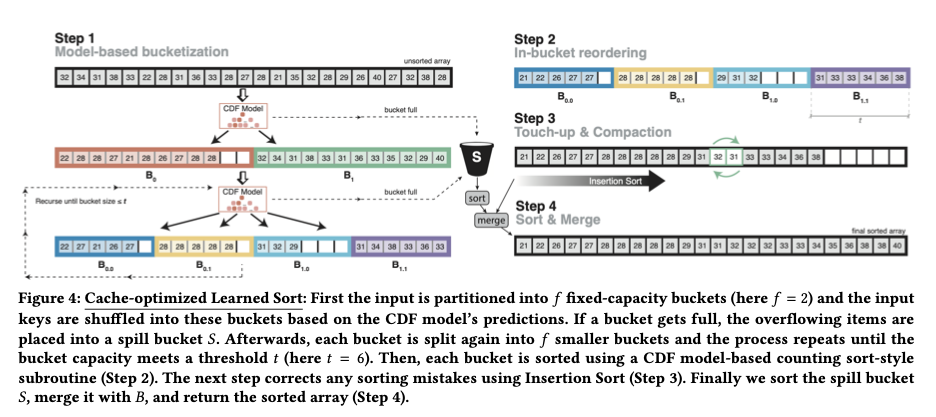
Orbital edge computing: nanosatellite constellations as a new class of computer system, Denby & Lucia, ASPLOS’20.
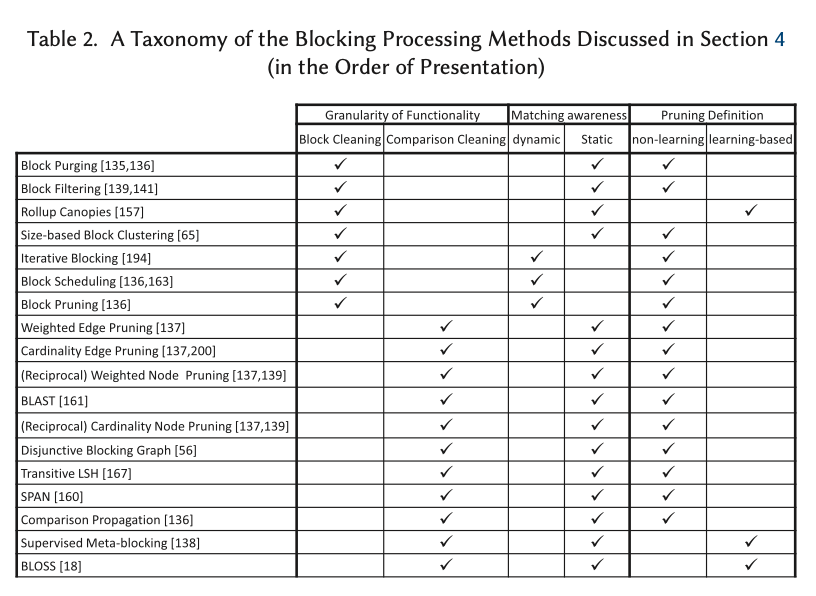
Last time out we looked at the real-world deployment of 5G networks and noted the affinity between 5G and edge computing. In true Crocodile Dundee style, Denby and Lucia are entitled to say “that’s not the edge, this is the edge!”. Today’s paper choice has it all: clusters of formation-flying autonomous nanosatellites working in tandem to overcome the physical limitations of space and the limited bandwidth to earth. The authors call this Orbital Edge Computing in contrast to the request-response style of satellite communications introduced with the previous generation of monolithic satellites. Only space system architects don’t call it request-response, they call it a ‘bent-pipe architecture.’
Momentum towards large constellations of nanosatellites requires a reimagining of space systems as distributed, edge-sensing and edge-computing systems.
Satellites are changing!
Satellites used to be large monolithic devices, e.g. the 500kg, $192M Earth Observing-1 (EO-1) satellite. Over the last couple of decades there’s been a big switch to /nanosatellite/ constellations. Nanosatellites are typically 10cm cubes (for the “CubeSat” standard), weigh just a few kilograms, and cost in the thousands of dollars.
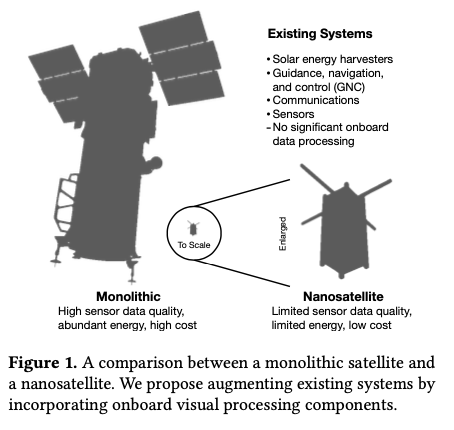
The CubeSat form-factor limits what can be packed into the device and how much power is available. Without higher-risk deployable solar arrays, a cubesat relies on surface-mounted solar panels to harvest energy. This results in peak available power of about 7.1W.
A constellation is a collection of nanosatellites (the space segment) and a collection of on-the-ground transceivers (the ground segment). Constellations today are in the hundreds of nanosatellites, and reconfiguring such a constellation from the ground can take months. Constellations with thousands of nanosatellites are on their way. And it seems we can add satellites to the growing list of things that get finer-grained over time:
Looking forward, we expect deployments of satellites that are even smaller than nanosatellites. Chip-scale or gram-scale satellites (“chipsats”) can be deployed even more numerously and at even lower cost.
The old ground-initiated command-and-control style systems aren’t going to work for these finer-grained systems. To see why, we need to look at some of the physical constraints of computation and communication in space.
Physical constraints
We’ve already seen that nanosatellites have about 7W of power to play with, which they harvest from the environment and store in batteries or supercapacitors. Beyond power, volume is the second key limiting factor, in particular restricting the amount you can pack onboard, and best focal length achievable with cameras.
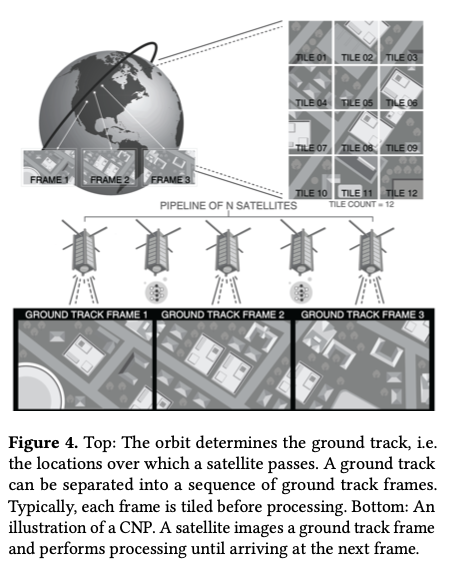
The Ground Sample Distance (GSD) is the distance on the ground between one pixel and the next in a camera image. It’s a function of orbit altitude, camera focal length, and pixel sensor size. Nanosatellite systems have a GSD of around 3.0m/px. When it comes to GSD, lower is better.
The satellite takes images of a path on the ground called the /ground track/. As it moves around the ground track, the ideal frequency at which to take images is one where each frame is perfectly adjacent to the one before, with no overlapping pixels. This is called the Ground Track Frame Rate (GTFR).
In order to achieve sufficient coverage of a ground track, a satellite or constellation must capture images individually or in aggregate at the GTFR.
In the bent pipe architecture a satellite gathers and stores data until it is near a ground station, and then transmits whatever it has. This results in delays of up to 5.5 hours from capture to receipt of data. A ground station with a 200 Mbit/s downlink datarate can retrieve up to to 15GB of data during a ten minute session. Even under ideal conditions, such a ground station can only support 9 satellites per revolution. It would take 112 ideally positioned stations to support a 1000-node constellation.
Downlink bandwidth increases with receiver gain, which increases with dish diameter on ground stations. Cubesats can’t increase receiver gain in this way due to their limited device size. So uplink data volume is on the order of kilobytes per pass.
That’s not enough bandwidth to download data from thousands of nano-satellites, nor enough to efficiently reconfigure a cluster via the uplink. Satellites are going to have to take responsibility for more decisions on their own, without waiting for commands from a ground station, and they’re going to have to do more onboard processing of data to make better use of the limited downlink bandwidth.
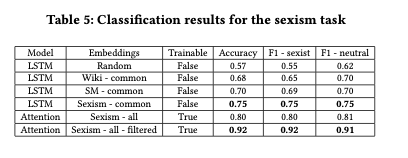
Introducing Orbital Edge Computing (OEC)
Orbital Edge Computing (OEC) is designed to do just that. Coverage of a ground track and processing of image tiles is divided up between members of a constellation in a computational nanosatellite pipeline (CNP).
A CNP leverages existing formation flying techniques to orbit in a fixed configuration, parallelizing data collection and processing across a constellation.
With onboard image processing to identify interesting data, it might be possible to reduce 15GB of raw data down to about 0.75GB that needs to be sent to the ground station. This would take just 30s at 200 Mbit/s. Rather than servicing only 9 satellites per revolution, a ground station could then service 185. The particular form of local processing depends on the application, but it could include for example CNN-based image classification, object detection, segmentation, or even federated machine learning. The general scheme of only sending the interesting parts of the data is known as intelligent early discard.
OEC nanosatellites also run local software for autonomous control, modelling the satellite’s position in time and space, and achievable bitrate, to determine when to communicate and what to communicate (raw data or processed images). This removes the dependence on command-and-control structures initiated at the ground station and sent over the precious uplink bandwidth.
The unique characteristics of OEC systems stem from the astrodynamics that govern them, giving rise to fundamental differences compared to terrestrial edge computing systems.
Formation flying, and formation processing
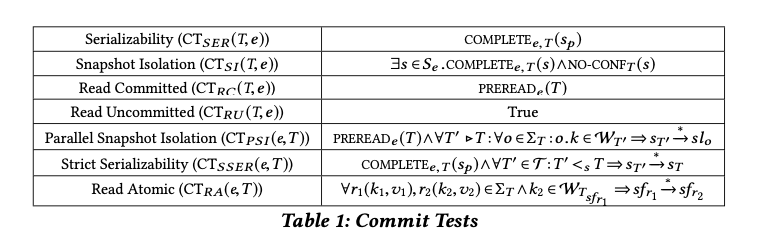
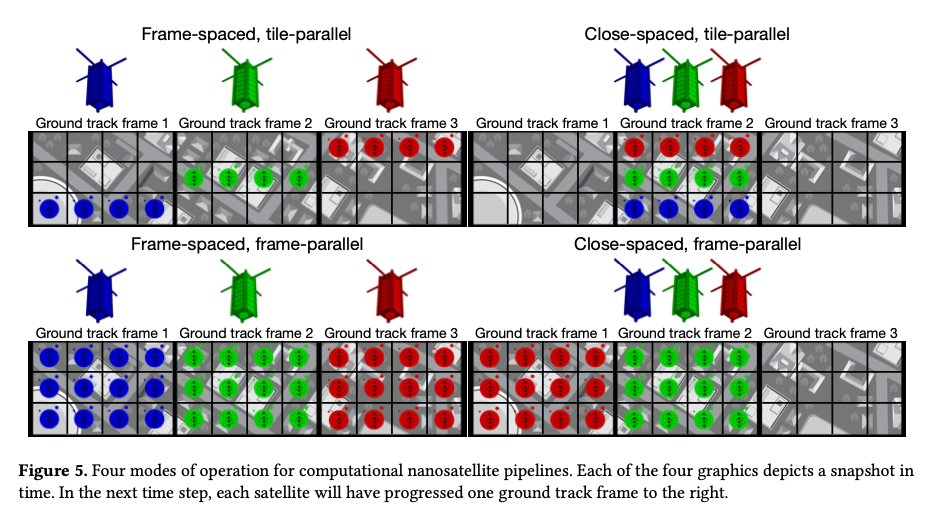
The authors explore two different options for nanosatellite formations with respect to ground track frames (GTFs), and two different options for parallel processing of images. Combined, this results in four different possible OEC configurations.
In a frame-spaced formation the nanosatellites are placed exactly one GTF apart in distance. (My mental model is a sliding window with an array of read heads, so that multiple GTFs can be read in parallel your mileage may vary!). An interesting variant of frame-spacing is orbit spacing which distributes satellites evenly across an orbit giving improved communication opportunities.
A close-spaced formation of nanosatellites packs the nanosatellites as close together as possible, such that the end-to-end pipeline distance between the satellites is less than the length of one GTF.
Whether frame-spaced or close-spaced, there are two options for how each satellite processes an image frame. Consider an image divided up into a set of tiles. With frame-parallel processing each nanosatellite processes all the tiles in each frame. With tile-parallel different tile segments are assigned to different satellites, which then process only their own tiles.
Computing on the edge with cote
These ideas are all packaged together in cote, “the first full-system model for orbital edge computing.” cote has two main components: a pre-mission simulation library, and an online autonomous control library ( cote-lib) to be included in nanosatellite software stacks.
cote-libruns continuously in the background on an OEC device, explicitly modeling ground station available… [it] enables an OEC satellite to adapt to changing orbit and power conditions in real-time; such fine-grained adaptation is impossible with high-latency bent-pipe terrestrial control.
cote tracks time using Universal Time (UT1), which measure the rotation of the earth relative to distant astronomical objects. It supports three different coordinate frames: Earth-centered inertial (ECI), latitude, longitude and height (LLH), and south, east, z (SEZ). It’s important to model the true oblate nature of the Earth as it matters when establishing communication links via ground satellites with narrow high-gain antenna beams.
Given time and position, cote can use orbital mechanics to model the state of a satellite relative to the rotating earth. The simplified general perturbation model (SGP4) is used as the orbital mechanics engine. SPG4 is the GPS of space!
Understanding where it is relative to the Earth enables cote to model the maximum achievable bitrate for downlink, crosslink, and uplink channels at any given point in time. This can be used to plan when and what to communicate back to earth.
Evaluation
I’m running out of space to cover the evaluation section in any depth, so here are the highlights:
- “Bent pipes are fundamentally unscalable using a constellation of 250 nanosatellites in a $97.3^o$ inclination orbit.”
- Frame-spaced and orbit-spaced constellations downlink the most data, due to the reduction in downlink contention from their spacing.
- Close-spaced constellation have much lower effective bandwidth, but also much lower latency. This is especially marked in the tile-parallel scheme, where the latency reduction for close-spacing is 617x!
- Enabling intelligent early discard can reduce the number of required ground stations by 24x.
We show that an OEC architecture can reduce ground infrastructure over 24x compared to a bent-pipe architecture, and we show that pipelines can reduce system edge processing latency over 617x.
There’s loads of good stuff in this paper that I didn’t have the space to cover here, so if you’re at all interested in this topic I highly recommend checking it out.