NVIDIA announces the winners from the second global DPU Hackathon.
NVIDIA announces the winners from the second global DPU Hackathon.
The second global NVIDIA DPU Hackathon brought together 11 teams with the goal of creating new and exciting data processing unit (DPU) innovations. Spanning 24 hours from December 8 to 9, the second in a series of global NVIDIA DPU Hackathons received over 50 team applications from various universities and enterprises.
As a new class of programmable processors, a DPU ignites unprecedented innovation for modern data centers. By offloading, accelerating, and isolating a broad range of advanced networking, storage, and security services, NVIDIA BlueField DPUs provide a secure and accelerated infrastructure for any workload in any environment. The NVIDIA DOCA software framework brings together APIs, drivers, libraries, sample code, documentation, services, and prepackaged containers so developers can speed application development and deployment on BlueField DPUs. They span several use cases, including security, automation, AI, HPC, and telemetry.
“We love hackathons, they create the right environment to perform a step function in the development. We put the DOCA developers in the center, offering them training, mentorship, preconfigured setups, documentation, a working environment, and visibility. Moving forward hackathons will play a significant role in establishing a strong DOCA developer community,” said Dror Goldenberg, the SVP of Software Architecture at NVIDIA.

DPU Hackathon winners
First Place – Team Rutgers University
Team Rutgers University focused on developing a unique, high-performance, DPU accelerated and scalable L4 Load Balancer. Using DOCA FLOW APIs to configure the embedded switch, Team Rutgers was able to build an application that delivers hardware acceleration for offloading the load-balancing algorithm and handle flow tracking in hardware. The final design is a testament to the unique value that can be achieved with DOCA.
Second Place – Team Equinix Metal
Team Equinix Metal focused on innovative development on DPU service orchestration with gRPC APIs. They were clearly excited to try the DPU in a bare-metal cloud use case, to improve their existing synchronous method. By using gRPC to configure the bare-metal host network in an asynchronous way, they ensured networking commands were handled even if the network was disrupted. This enabled them to use gRPC commands to the DPU to allow asynchronous configuration with OVS running on the BlueField and deliver the BlueField service orchestration.
Third Place – Team BlueJazz from Versa Networks
Team BlueJazz created a DPU accelerated and secure access service by running traffic inspection and inference service on the DPU with 100G links. With their innovation, they offload any datapath with subfunctions and accelerate processing by virtualizing the DPU as an engine for security. Team BlueJazz used DOCA Deep Packet Inspection APIs to offload the pattern-matching logic and leveraged DOCA reference applications for URL filtering and application recognition.
Congratulations to our winners and thank you to all of the teams that participated, making this round of our NVIDIA DPU Hackathon a success!
Join the DOCA community
NVIDIA is building a broad community of DOCA developers to create innovative applications and services on top of BlueField DPUs to secure and accelerate modern, efficient data centers. To learn more about joining the community, visit the DOCA developer web page or register to download DOCA today.
Up next is the NVIDIA DPU Hackathon in China. Check the corporate calendar to stay informed for future events, and take part in our journey to reshape the data center of tomorrow.
Resources
- Take the introduction to NVIDIA DOCA for BlueField DPUs DLI course
- Learn how to utilize the BlueField DPU as a platform for zero trust security with DOCA 1.2
- Build a foundation for zero trust security with DOCA 1.2
- Start a discussion on our forums
- Read about DPU-Based hardware acceleration
- Get access to cutting edge technology through NVIDIA Inception for startups


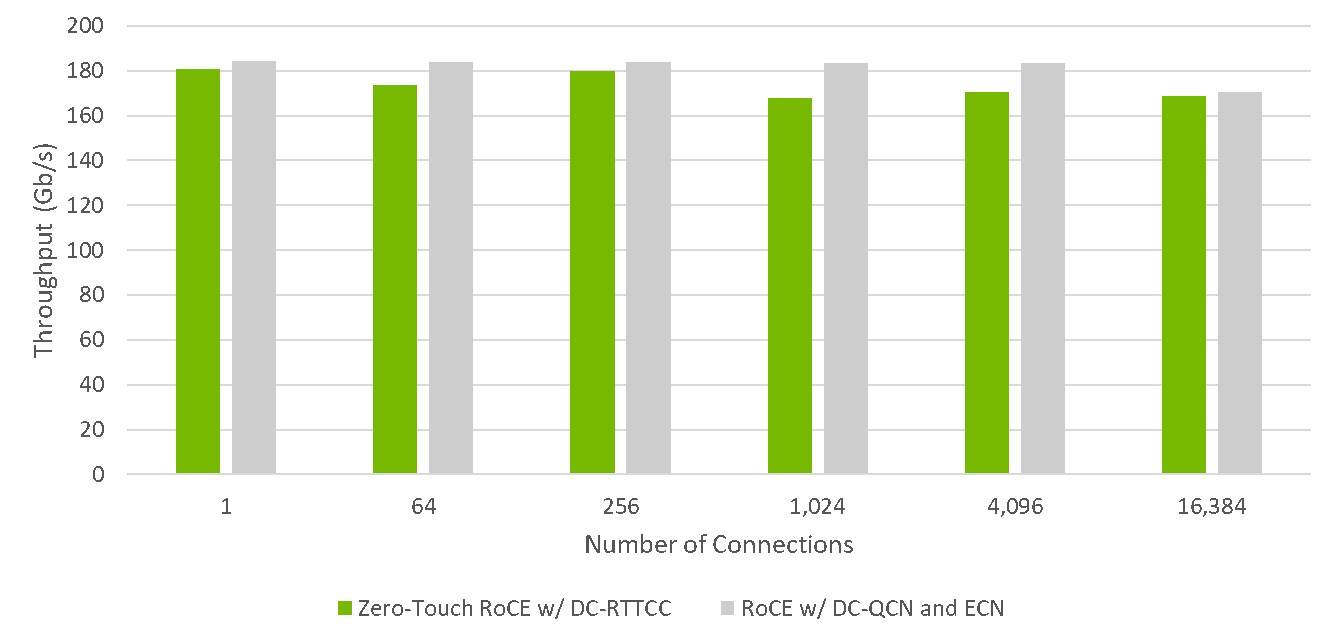
 The new NVIDIA RTTCC congestion control algorithm for ZTR delivers RoCE performance at scale, without special switch infrastructure configuration.
The new NVIDIA RTTCC congestion control algorithm for ZTR delivers RoCE performance at scale, without special switch infrastructure configuration.