
 There is an increasing demand for manufacturers to achieve high-quality control standards in their production processes. Traditionally, manufacturers have relied on manual inspection to guarantee product quality. However, manual inspection is expensive, often only covers a small sample of production, and ultimately results in production bottlenecks, lowered productivity, and reduced efficiency. By automating defect inspection … Continued
There is an increasing demand for manufacturers to achieve high-quality control standards in their production processes. Traditionally, manufacturers have relied on manual inspection to guarantee product quality. However, manual inspection is expensive, often only covers a small sample of production, and ultimately results in production bottlenecks, lowered productivity, and reduced efficiency. By automating defect inspection … Continued
There is an increasing demand for manufacturers to achieve high-quality control standards in their production processes. Traditionally, manufacturers have relied on manual inspection to guarantee product quality. However, manual inspection is expensive, often only covers a small sample of production, and ultimately results in production bottlenecks, lowered productivity, and reduced efficiency.
By automating defect inspection with AI and computer vision, manufacturers can revolutionize their quality control processes. However, one major obstacle stands between manufacturers and full automation. Building an AI system and production-ready application is hard and typically requires a skilled AI team to train and fine-tune the model. The average manufacturer does not employ this expertise and resorts to using manual inspection.
The goal of this project was to show how the NVIDIA Transfer Learning Toolkit (TLT) and a pretrained model can be used to quickly build more accurate quality control in the manufacturing process. This project was done without an army of AI specialists or data scientists. To see how effective the NVIDIA TLT is in training an AI system for commercial quality-control purposes, a publicly available dataset on the steel welding process was used to retrain a pretrained ResNet-18 model, from the NGC catalog, a GPU-optimized hub of AI and HPC software, using TLT. We compared the effort and resulting model’s accuracy to a model built from scratch on the dataset in a previously published work by a team of AI researchers.
NVIDIA TLT is user-friendly and fast, and can be easily used by engineers who do not have AI expertise. We observed that NVIDIA TLT was faster to set up and produced more accurate results, posting a macro average F1 score of 97% compared to 78% from previously published “built from scratch” work on the dataset.
This post explores how NVIDIA TLT can quickly and accurately train AI models, showing how AI and transfer learning can transform how image and video analysis and industrial processes are deployed.
Workflow with NVIDIA TLT
NVIDIA TLT, a core component of the NVIDIA Train, Adapt, and Optimize (TAO) platform, follows the zero-coding paradigm tofast-track AI development. TLT comes with a set of ready-to-use Jupyter notebooks, Python scripts, and configuration specifications with default parameter values that enable you to start training and fine-tuning your datasets quickly and easily.
To get started with the NVIDIA TLT, we followed these Quick Start Guide instructions.
- We downloaded a Docker container and TLT Jupyter notebook.
- We mapped our dataset onto the Docker container.
- We started our first training, having adjusted the default training parameters, such as the network structure, network size, optimizer, and so on, until we were satisfied with the results.
For more information about the configuration options for training, see Model Config in the NVIDIA TLT User Guide.
Dataset
The dataset used in this project was created by researchers at the University of Birmingham for their paper, Automated defect classification of SS304 TIG welding process using visible spectrum camera and machine learning.
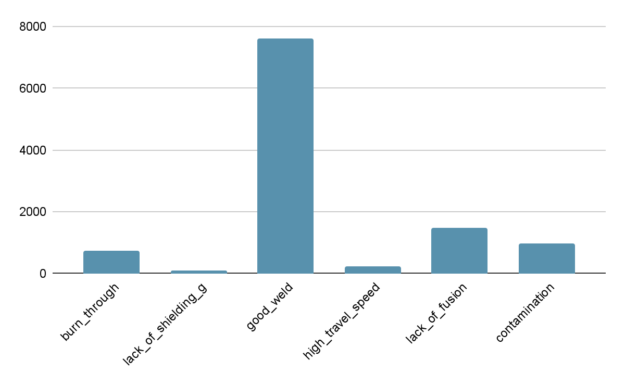
The dataset consists of over 45K grayscale welding images, which can be obtained through Kaggle. The dataset describes one class of proper execution: good_weld. It has five classes of defects that can occur during a tungsten inert gas (TIG) welding process: burn_through, contamination, lack_of_fusion, lack_of_shielding_gas, and high_travel_speed.

| burn_through | contamination | good_weld | high_travel_speed | lack_of_fusion | lack_of_shielding | Total | |
| train | 977 | 1613 | 15752 | 630 | 5036 | 196 | 24204 |
| valid | 646 | 339 | 6700 | 346 | 1561 | 102 | 9694 |
| test | 731 | 960 | 7628 | 249 | 1490 | 102 | 11160 |
Like many industrial datasets, this dataset is quite imbalanced as it can be difficult to collect data on defects that occur with a low likelihood. Table 1 shows the class distribution for the train, validation, and test datasets.
Figure 2 visualizes the imbalance in the test dataset. The test dataset contains 75x more images of good_weld than it does of lack_of_shielding.
Using NVIDIA TLT
The approach taken focuses on minimizing both development time and tuning time while ensuring that the accuracy is applicable for a production environment. TLT was used in combination with the standard configuration files shipped with the example notebooks. The setup, training, and tuning was done in under 8 hours.
We conducted parameter sweeps regarding network depth and the number of training epochs. We observed that changing the learning rate from its default did not improve the results, so we did not investigate this further and left it at the default. The best results were obtained with a pretrained ResNet-18 model obtained from the NGC catalog after 30 epochs of training with a learning rate of 0.006.
Check out the step-by-step approach in krygol/304SteelWeldingClassification GitHub repo.
| Metric | Precision | Recall | F1-score |
| burn_through | 0.98 | 0.86 | 0.92 |
| contamination | 0.99 | 0.93 | 0.96 |
| good_weld | 0.99 | 1.00 | 0.99 |
| high_travel_speed | 1.00 | 1.00 | 1.00 |
| lack_of_fusion | 0.95 | 1.00 | 0.98 |
| lack_of_shielding_gas | 1.00 | 0.99 | 1.00 |
| micro average | 0.98 | 0.98 | 0.98 |
| macro average | 0.98 | 0.96 | 0.97 |
The obtained results were comparably good across all classes. Some lack_of_fusion gas images got misclassified as burn_through and contamination images. This effect was also observed when training the deeper ResNet50, which was even more prone to misclassifying lack_of_fusion as another defective class.
Comparison to the original approach
The researchers at the University of Birmingham chose a different AI workflow. They manually prepared the dataset to lessen the imbalance by undersampling it. They also rescaled their images to different sizes and chose custom network structures.
They used a fully connected neural network (Fully-con6), neural network with two hidden layers. They also implemented a convolutional neural network (Conv6) with three convolutional layers each followed by a max pooling layer and a fully connected layer as the final hidden layer. They did not use skip connections as ResNet does.
The results obtained with TLT are even more impressive when compared to results of the custom implementation by the researchers at the University of Birmingham.
| Conv6 | Fully-con6 | TLT-ResNet-18 | |
| Metric | F1-score | F1-score | F1-score |
| good_weld | 0.99 | 0.97 | 0.99 |
| burn_through | 0.98 | 0.17 | 0.92 |
| contamination | 0.90 | 0.79 | 0.96 |
| lack_of_fusion | 0.94 | 0.94 | 0.97 |
| lack_of_shielding | 0.0 | 0.38 | 1.00 |
| high_travel_speed | 0.87 | 0.12 | 1.00 |
| Macro average | 0.78 | 0.56 | 0.97 |
Conv6 performed better on average with a macro average F1 of 0.78 but failed completely at recognizing lack_of_shielding gas defects. Fully-con6 performed worse on average, with a macro average F1 of 0.56. Fully-con6 could classify some of the lack_of_shielding gas images but had problems with burn_through and high_travel_speed images. Both Fully-con6 and Conv6 had distinct weaknesses that would prohibit them from being qualified as production-ready.
The best F1-scores for every class are marked in green in the table. As you can see, the ResNet-18 model trained by TLT provided better results with a macro average of 0.97.
Conclusion
We had a great experience with TLT, which in general was user-friendly and effective. It was fast to set up, easy to use, and produced results acceptable for production within a short computational time. Based on our experience, we believe that TLT provides a great advantage for engineers who are not AI experts but wish to use AI in their production environments. Using TLT in a manufacturing environment to automate quality control does not come at a performance cost and the application can often be used with the default settings and a few minor tweaks to outperform custom architectures.
This exploration of using NVIDIA TLT to quickly and accurately train AI models shows that there is great potential for AI in industrial processes.
Acknowledgments
Thanks and gratitude to the researchers—Daniel Bacioiu, Geoff Melton, Mayorkinos Papaelias, and Rob Shaw—for their paper, Automated defect classification of SS304 TIG welding process using visible spectrum camera and machine learning, and publishing their data on Kaggle. Thanks to Ekaterina Sirazitdinova for her help during the development process of this project.
 As an undergraduate student excited about AI for healthcare applications, I was thrilled to be joining the NVIDIA Clara Deploy team for an internship. It was the perfect combination: the opportunity to work at a leading technology company enabling the acceleration and adoption of AI while contributing to a team building the future (and the …
As an undergraduate student excited about AI for healthcare applications, I was thrilled to be joining the NVIDIA Clara Deploy team for an internship. It was the perfect combination: the opportunity to work at a leading technology company enabling the acceleration and adoption of AI while contributing to a team building the future (and the … 


 New research creates a deployable AI framework for detecting gravitational waves within massive amounts of data at several magnitudes faster than real time.
New research creates a deployable AI framework for detecting gravitational waves within massive amounts of data at several magnitudes faster than real time.