NVIDIA announced its latest update to the HPL-AI Benchmark version 2.0.0, which will reside in the HPC-Benchmarks container version 21.4.
NVIDIA announced its latest update to the HPL-AI Benchmark version 2.0.0, which will reside in the HPC-Benchmarks container version 21.4. The HPL-AI (High Performance Linpack – Artificial Intelligence) benchmark helps evaluate the convergence of HPC and data-driven AI workloads.
Historically, HPC workloads are benchmarked at double-precision, representing the accuracy requirements in computational astrophysics, computational fluid dynamics, nuclear engineering, and quantum computing. AI workloads on the other hand can deliver acceptable results using much lower precision for training and inference. This distinctive characteristic led to the development of technology such as the Tensor Cores. Tensor Cores provide substantial speedups in mixed-precision workloads by accelerating precisions such as TF32, BF16, FP16, INT8, and INT4.
Many vendors provide specially tuned versions of HPL for their hardware. NVIDIA is releasing the NVIDIA HPC-Benchmarks container on NGC. This container includes three different versions of the HPL benchmark for double precision arithmetic; HPL-AI, applied to mixed precision workloads, and HPCG, which performs a fixed number of multigrid preconditioned conjugate gradient (PCG) iterations at double precision.
With this latest release, the HPL-AI benchmark deliveries double the performance over the initial container released in Fall 2020. This is largely due to major improvements to load balancing at the communication layers. Multi-node communications are usually handled by the CPU, which can lead to performance bottlenecks if GPU become idle. MPI-aware communication between GPUs allows the CPU to be bypassed and keep the GPU busy. When possible data transfers are sent at a lower precision reducing the time GPUs are waiting for data. After minimizing communication, GPUs can process larger datasets to provide maximum compute efficiency. Lastly, the latest version of the NVIDIA Math Libraries are used to deliver optimal performance on an A100.
The plot below shows that with 128 DGX A100s, or 1024 NVIDIA A100 GPUs, the latest release of HPL-AI performs 2.6 times faster.
To checkout these improvements, download the latest NVIDIA HPC-Benchmark container, version 21.4, from NGC. The HPC-Benchmark landing page includes detailed instructions and additional resources. If you have any questions or issues, please send email to HPCBenchmarks@nvidia.com.
Today, NVIDIA is announcing the availability of cuTENSOR version 1.3.0. This software can be downloaded now free for members of the NVIDIA Developer Program.
Today, NVIDIA is announcing the availability of cuTENSOR version 1.3.0. This software can be downloaded now free for members of the NVIDIA Developer Program.
Torch is not just for deep learning. Its L-BFGS optimizer, complete with Strong-Wolfe line search, is a powerful tool in unconstrained as well as constrained optimization.
Recommender systems (RecSys) have become a key component in many online services, such as e-commerce, social media, news service, or online video streaming. However with the growth in importance, the growth in scale of industry datasets, and more sophisticated models, the bar has been raised for computational resources required for recommendation systems. To meet the … Continued
Recommender systems (RecSys) have become a key component in many online services, such as e-commerce, social media, news service, or online video streaming. However with the growth in importance, the growth in scale of industry datasets, and more sophisticated models, the bar has been raised for computational resources required for recommendation systems.
To meet the computational demands for large-scale DL recommender systems, NVIDIA introduced Merlin – a Framework for Deep Recommender Systems. Now NVIDIA teams have won two consecutive RecSys competitions in a row: the ACM RecSys Challenge 2020, and more recently the WSDM WebTour 21 Challenge organized by Booking.com. The Booking.com challenge focused on predicting the last city destination for a traveler’s trip given their previous booking history within the trip. NVIDIA’s interdisciplinary team included colleagues from NVIDIA’s KGMON (Kaggle Grandmasters), NVIDIA’s RAPIDS (Data Science), and NVIDIA’s Merlin (Recommender Systems) who collaborated on the winning solution.
This post is the second of a three-part series that gives an overview of the NVIDIA team’s first place solution for the booking.com challenge. The first post gives an overview of recommender system concepts. This second post discusses deep learning for recommender systems. The third post will discuss the winning solution, the steps involved, and also what made a difference in the outcome.
Deep Learning for Recommendation
As the growth in the volume of data available to power recommender systems accelerates rapidly, data scientists are increasingly turning from more traditional machine learning methods to highly expressive deep learning models to improve the quality of their recommendations.
Broadly, the life-cycle of deep learning for recommendation can be split into two phases: training and inference. In the training phase, the model is trained to predict user-item interaction probabilities (calculate a preference score) by presenting it with examples of interactions (or non-interactions) between users and items from the past.
Figure 1: Deep learning for recommendation training.
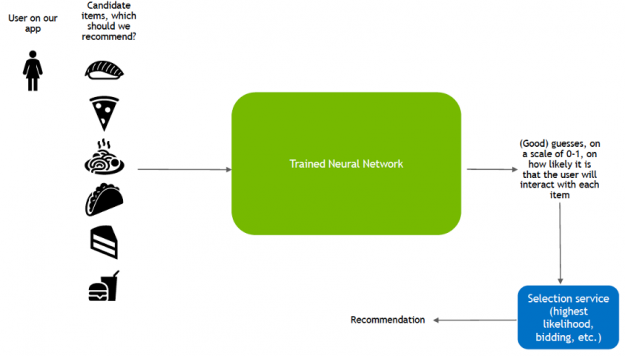
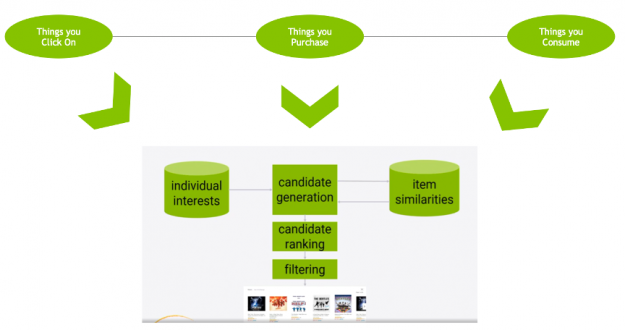
Once it has learned to make predictions with a sufficient level of accuracy, the model is deployed as a service to infer the likelihood of new interactions.
Figure 2: Deep learning for recommendation inference.
This inference stage utilizes a different pattern of data consumption than during training:
Candidate generation: pair a user with hundreds or thousands of candidate items based on learned user-item similarity.
Candidate ranking: rank the likelihood that the user enjoys each item.
Filter: show the user the item they are rated most likely to enjoy.
Figure 3: Deep learning for recommendation inference: candidate generation, ranking and filtering.
Deep Neural Network Models for Recommendation
Deep learning (DL) recommender models build upon existing techniques such as factorization to model the interactions between variables and embeddings to handle categorical variables. An embedding is a learned vector of numbers representing entity features so that similar entities (users or items) have similar distances in the vector space. For example, a deep learning approach to collaborative filtering learns the user and item embeddings (latent feature vectors) based on user and item interactions with a neural network.
Figure 4: A deep learning approach to collaborative filtering learns the user and item embeddings based on user and item interactions.
DL techniques also tap into the vast and rapidly growing novel network architectures and optimization algorithms to train on large amounts of data, use the power of deep learning for feature extraction, and build more expressive models. DL–based models build upon the different variations of artificial neural networks (ANNs), such as the following:
Multilayer perceptrons (MLPs) are a type of feedforward ANN consisting of at least three layers of nodes: an input layer, a hidden layer, and an output layer. MLPs are flexible networks that can be applied to a variety of scenarios.
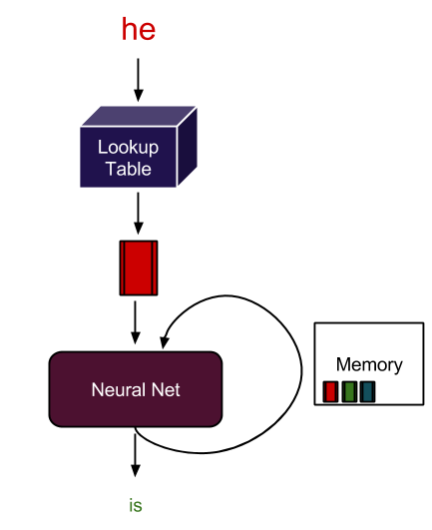
Recurrent neural networks are the mathematical engines to parse language patterns and sequenced data.
GPUs, with their massively parallel architecture, are driving the advancement of deep learning (DL) and RecSys DL in the past several years. With GPUs, you can exploit data parallelism through columnar data processing instead of traditional row-based reading designed initially for CPUs. This provides higher performance and cost savings. Current DL–based models for recommender systems like DLRM, Wide and Deep (W&D), Neural Collaborative Filtering (NCF), Variational AutoEncoder (VAE) are part of the NVIDIA GPU-accelerated DL model portfolio that covers a wide range of network architectures and applications in many different domains beyond recommender systems, including image, text and speech analysis.
Neutral Collaborative Filtering
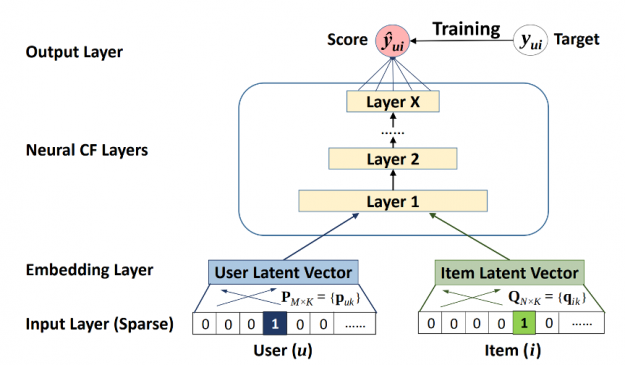
The Neural Collaborative Filtering (NCF) model is a neural network that provides collaborative filtering based on user and item interactions. The NCF model treats matrix factorization from a non-linearity perspective. NCF TensorFlow takes in a sequence of (user ID, item ID) pairs as inputs, then feeds them separately into a matrix factorization step (where the embeddings are multiplied) and into a multilayer perceptron (MLP) network.
The outputs of the matrix factorization and the MLP network are then combined and fed into a single dense layer which predicts whether the input user is likely to interact with the input item.
Figure 5: NCF model.
Variational Autoencoder for Collaborative Filtering
An autoencoder neural network reconstructs the input layer at the output layer by using the representation obtained in the hidden layer. An autoencoder for collaborative filtering learns a non-linear representation of a user-item matrix and reconstructs it by determining missing values.
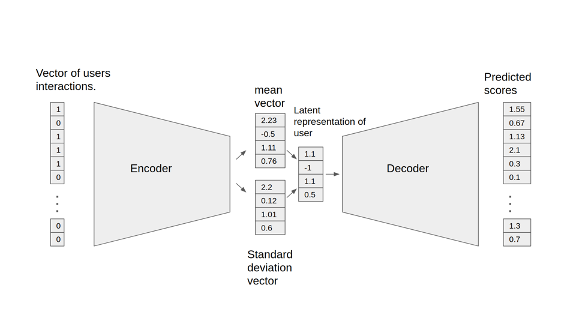
The NVIDIA GPU-accelerated Variational Autoencoder for Collaborative Filtering (VAE-CF) is an optimized implementation of the architecture first described in Variational Autoencoders for Collaborative Filtering. VAE-CF is a neural network that provides collaborative filtering based on user and item interactions. The training data for this model consists of pairs of user-item IDs for each interaction between a user and an item.
The model consists of two parts: the encoder and the decoder. The encoder is a feedforward, fully connected neural network that transforms the input vector, containing the interactions for a specific user, into an n-dimensional variational distribution. This variational distribution is used to obtain a latent feature representation of a user (or embedding). This latent representation is then fed into the decoder, which is also a feedforward network with a similar structure to the encoder. The result is a vector of item interaction probabilities for a particular user.
Figure 6: VAE-CF model.
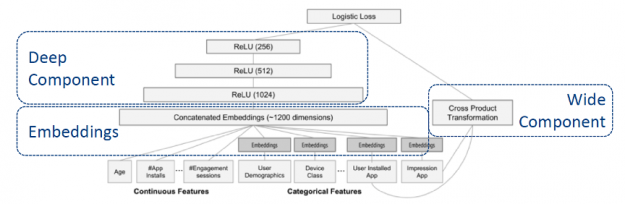
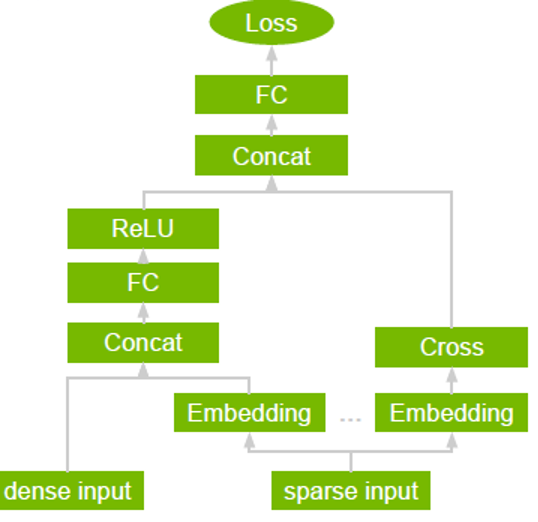
Wide and Deep
Wide & Deep refers to a class of networks that use the output of two parts working in parallel—wide model and deep model—whose outputs are summed to create an interaction probability. The wide model is a generalized linear model of features together with their transforms. The deep model is a Dense Neural Network (DNN), a series of hidden MLP layers, each beginning with a dense embedding of features. Categorical variables are embedded into continuous vector spaces before being fed to the DNN via learned or user-determined embeddings.
Figure 7: Wide and Deep model
What makes this model so successful for recommendation tasks is that it provides two avenues of learning patterns in the data, “deep” and “shallow”. The complex, nonlinear DNN is capable of learning rich representations of relationships in the data and generalizing to similar items via embeddings but needs to see many examples of these relationships in order to do so well. The linear piece, on the other hand, is capable of “memorizing” simple relationships that may only occur a handful of times in the training set.
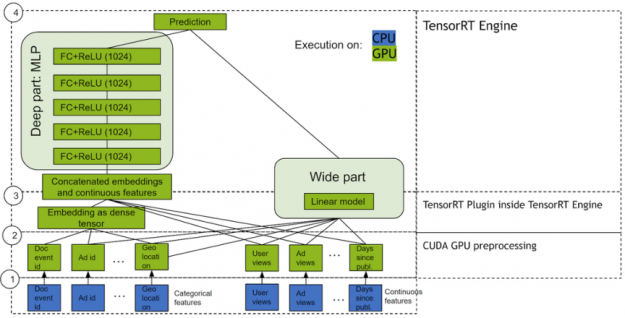
In combination, these two representation channels often end up providing more modeling power than either on its own. NVIDIA has worked with many industry partners who reported improvements in offline and online metrics by using Wide & Deep as a replacement for more traditional machine learning models.
Figure 8: Wide and Deep model with NVIDIA GPU-accelerated TensorRT.
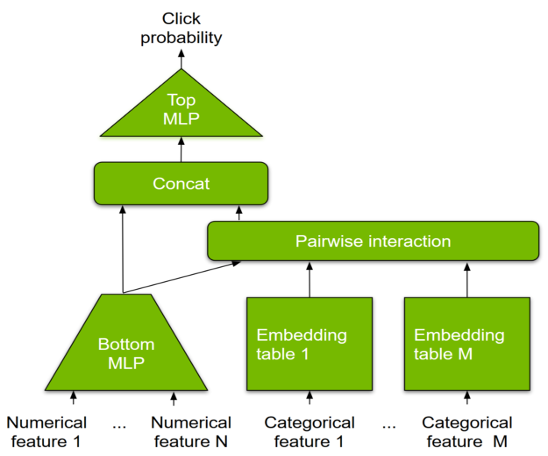
DLRM
DLRM is a DL-based model for recommendations introduced by Facebook research. It’s designed to make use of both categorical and numerical inputs that are usually present in recommender system training data. To handle categorical data, embedding layers map each category to a dense representation before being fed into multilayer perceptrons (MLP). Numerical features can be fed directly into an MLP.
At the next level, second-order interactions of different features are computed explicitly by taking the dot product between all pairs of embedding vectors and processed dense features. Those pairwise interactions are fed into a top-level MLP to compute the likelihood of interaction between a user and item pair.
Figure 9: DLRM model.
Compared to other DL-based approaches to recommendation, DLRM differs in two ways. First, it computes the feature interaction explicitly while limiting the order of interaction to pairwise interactions. Second, DLRM treats each embedded feature vector (corresponding to categorical features) as a single unit, whereas other methods (such as Deep and Cross) treat each element in the feature vector as a new unit that should yield different cross terms. These design choices help reduce computational/memory cost while maintaining competitive accuracy.
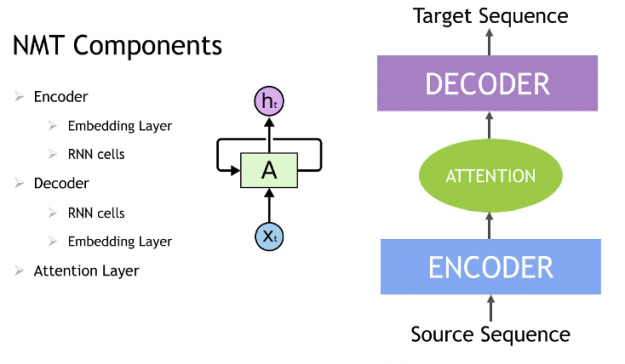
Contextual Sequence Learning
A Recurrent neural network (RNN) is a class of neural network that has memory or feedback loops that allow it to better recognize patterns in data. RNNs solve difficult tasks that deal with context and sequences, such as natural language processing, and are also used for contextual sequence recommendations. What distinguishes sequence learning from other tasks is the need to use models with an active data memory, such as LSTMs (Long Short-Term Memory) or GRU (Gated Recurrent Units) to learn temporal dependence in input data. This memory of past input is crucial for successful sequence learning. Transformer deep learning models, such as BERT (Bidirectional Encoder Representations from Transformers), are an alternative to RNNs that apply an attention technique—parsing a sentence by focusing attention on the most relevant words that come before and after it. Transformer-based deep learning models don’t require sequential data to be processed in order, allowing for much more parallelization and reduced training time on GPUs than RNNs.
Figure 10: Neutral machine translation Model.
In an NLP application, input text is converted into word vectors using techniques, such as word embedding. With word embedding, each word in the sentence is translated into a set of numbers before being fed into RNN variants, Transformer, or BERT to understand context. These numbers change over time while the neural net trains itself, encoding unique properties such as the semantics and contextual information for each word, so that similar words are close to each other in this number space, and dissimilar words are far apart. These DL models provide an appropriate output for a specific language task like next-word prediction and text summarization, which are used to produce an output sequence.
Figure 11: A recurrent neural network has memory of past experiences. The recurrent connection preserves these experiences and helps the network keep a notion of context.
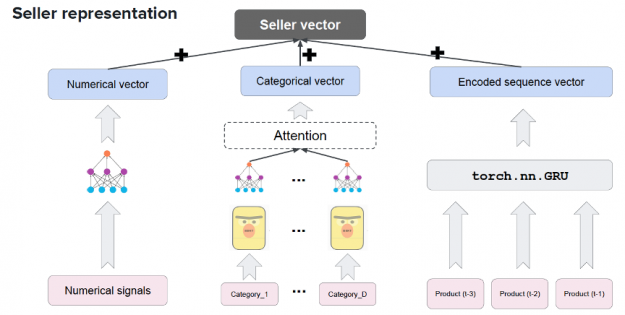
Session-based recommendations apply the advances in sequence modeling from deep learning and NLP to recommendations. RNN models train on the sequence of user events in a session (e.g. products clicked, date and time of interactions) in order to predict the probability of a user clicking the candidate or target item. User item interactions in a session are embedded similarly to words in a sentence before being fed into RNN variants such as LSTM, GRU, or Transformer to understand the context. For example, Square’s deep learning-based product recommendation system shown below leverages the transformer-based model BERT, GRUs, and NVIDIA GPUs to create a vector representation of their sellers.
Figure 12: Square’s model architecture leverages the transformer-based model BERT and GRUs to create the vector representation of their sellers.
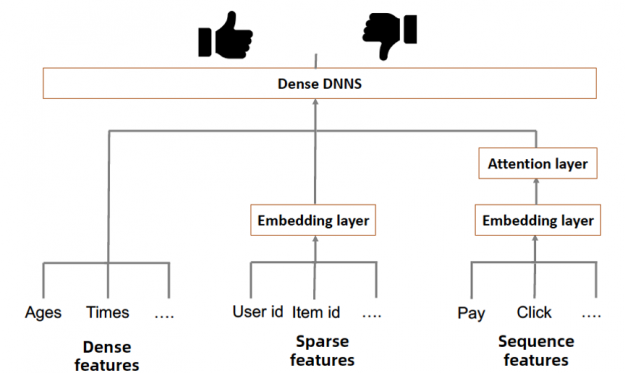
Figure 13: Alibaba’s recommender system model architecture.
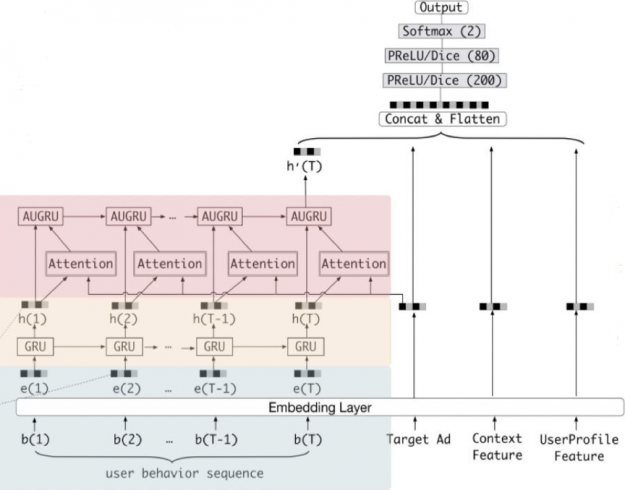
In the more detailed model diagram below, you can see that GRUs are added to learn and capture the relations among the items in the user behavior sequences in order to predict if a user will click on an advertised product.
Figure 14: Alibaba’s recommender system model architecture uses GRUs to capture user sequence behavior.
Alibaba is using thousands of T4 GPUs across its infrastructure with TensorRT to support the entire recommendation query AI pipeline on a real-time basis.
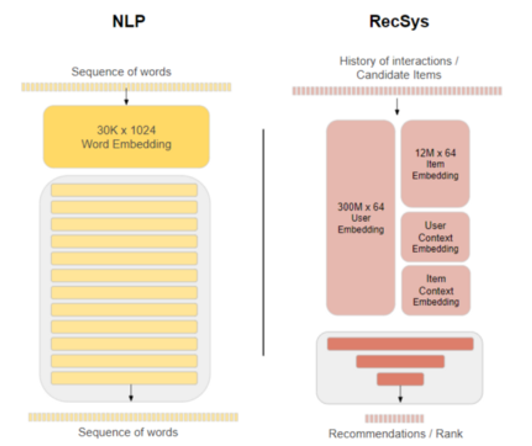
Figure 15: Model and embedding sizes between NLP and recommender systems vary significantly.
NVIDIA GPU Accelerated, End-to-End Data Science
NVIDIA developed RAPIDS—an open-source data analytics and machine learning acceleration platform—for executing end-to-end data science training pipelines completely in GPUs. It relies on NVIDIA® CUDA® primitives for low-level compute optimization, but exposes that GPU parallelism and high memory bandwidth through user-friendly Python interfaces.
Focusing on common data preparation tasks for analytics and data science, RAPIDS offers a GPU-accelerated DataFrame (cuDF) that mimics the pandas API and is built on Apache Arrow. It integrates with scikit-learn and a variety of machine learning algorithms to maximize interoperability and performance without paying typical serialization costs. This allows acceleration for end-to-end pipelines—from data prep to machine learning to deep learning. RAPIDS also includes support for multi-node, multi-GPU deployments, enabling vastly accelerated processing and training on much larger dataset sizes.
Compared to similar CPU-based implementations, RAPIDS delivers 50x performance improvements for classical data analytics and machine learning (ML) processes at scale which drastically reduces the total cost of ownership (TCO) for large data science operations.
Figure 16: End-to-End Data science pipeline with GPUs and RAPIDS.
NVIDIA Merlin
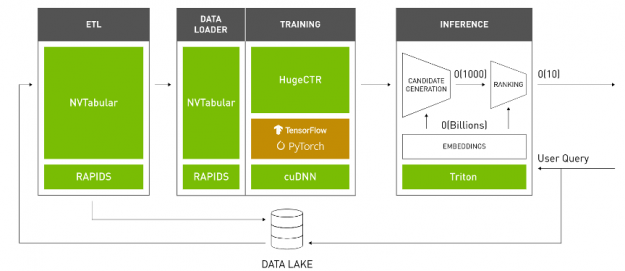
NVIDIA Merlin is an open-source application framework for building high-performance, DL–based recommender systems, built on NVIDIA RAPIDS, NVIDIA CUDA® Deep Neural Network library (cuDNN), and Triton. Merlin facilitates and accelerates recommender systems on GPU, speeding up common ETL tasks, training of models, and inference serving by ~10x over commonly used methods.
Figure 17: NVIDIA Merlin Open Beta Recommender System Framework.
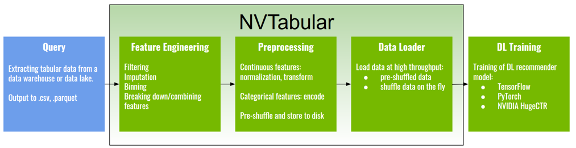
NVTabular is a feature engineering and preprocessing library for recommender systems. It provides a high-level abstraction to simplify code and accelerates computation on the GPU using the RAPIDS GPU-accelerated DataFrame cuDF library.
Figure18:Recommender system training pipeline with NVTabular.
Figure 19:An example model expressible by HugeCTR: A hybrid model with two embeddings and two different types of inputs.
NVIDIA Triton Inference Server and NVIDIA® TensorRT accelerate production inference on GPUs for feature transforms and neural network execution.
Beyond providing better performance, these libraries are also designed to be easy to use and integrate with existing recommendation pipelines.
Conclusion
In this blog, we gave an overview of deep learning models for recommender systems. Part three will discuss the NVIDIA teams’ winning solution for the ACM WSDM WebTour 21 Challenge organized by Booking.com.
Google Cloud and NVIDIA collaborated to make MLOps simple, powerful, and cost-effective by bringing together the solution elements to build, serve and dynamically scale your end-to-end ML pipelines with the right-sized GPU acceleration in one place.
Building, deploying, and managing end-to-end ML pipelines in production, particularly for applications like recommender systems is challenging. Operationalizing ML models, within enterprise applications, to deliver business value involves a lot more than developing the machine learning algorithms and models themselves – it’s a continuous process of data collection and preparation, model building, training or retraining with newer data, model validation, inference serving, and monitoring model performance to ensure the relevance of the results.
In addition to the challenge of developing the pipeline, you also need to secure and manage the right compute infrastructure to accelerate these steps for a guaranteed quality-of-service (QoS) for your customers. And, each step in the pipeline is unique too so your compute requirements for data preparation and training might be completely different from what’s required to service multiple disparate inference requests. This is both a development and infrastructure management challenge also commonly referred to as the MLOps challenge.
Google Cloud and NVIDIA have collaborated to make MLOps simple, powerful, and cost-effective by bringing together the solution elements to build, serve and dynamically scale your end-to-end ML pipelines with the right-sized GPU acceleration in one place. You can focus on delivering the best value for your end customers while maximizing infrastructure utilization and minimizing operational costs for deploying your AI-enabled services.
GKE + MIG = Portability, Scalability & Productivity for MLOps
Google Kubernetes Engine (GKE) is a managed environment for deploying, scaling and managing containerized ML applications in a secure Google infrastructure. GKE facilitates easy cluster creation, load balancing, autoscaling compute requirements based on demand among other things. Most importantly GKE frees up users from having to manage their own workstations, servers, and VMs while building and deploying ML pipelines – you can focus on the most important value-add tasks of building and training your ML models for your business use-case.
The Google Kubernetes Engine (GKE) now supports the Multi-Instance GPU (MIG) feature enabling each NVIDIA A100 Tensor Core GPU in the new A2 VM instance to be partitioned into as many as seven independent GPU instances, each with its own high-bandwidth memory, cache, and compute cores. GKE can then provision GPU resources for your workloads with greater granularity, share a single GPU for multi-user, multi-model use-cases and automatically scale up or down based on changing needs of your ML pipelines.
Figure 2. Multiple AI inference requests on a single NVIDIA A100 GPU with NVIDIA Triton Inference Server and GKE
For example, GKE can provision multiple A100 GPU MIG instances to process inference requests for multiple models to be simultaneously executed on the independent MIG partitions within a single A100 GPU to maximize utilization. As the compute required for your deployed ML pipelines increase (e.g. a sudden surge in inference requests to service), GKE can automatically scale to additional node-pools with MIG partitions. In addition, the NVIDIA Collective Communication Library (NCCL) further optimizes multi-GPU, multi-node communications within the GKE cluster to ensure high bandwidth, high throughput, and low latency.
To develop ML application pipelines that are scalable and are optimized to leverage the full benefits of the MIG capabilities for GPU utilization on Google Cloud, NVIDIA offers several GPU-accelerated end-to-end application-specific frameworks – NVIDIA Merlin for end-to-end recommendation systems, NVIDIA Jarvis for multimodal conversational AI services, and NVIDIA RAPIDS for data analytics pipelines. All NVIDIA optimized frameworks, SDKs, pre-trained models, and performance-optimized libraries can be accessed from NGC Catalog, a hub for GPU-accelerated software.
Deploying the ML pipelines into production at scale on a GKE managed cluster is further simplified with NVIDIA Triton Inference Server software. This open-source inference serving software lets teams deploy trained AI models from any framework (TensorFlow, TensorRT, PyTorch, ONNX Runtime, or a custom framework), from local storage or Google Cloud’s managed storage products on any GPU- or CPU-based infrastructure. Triton Inference Server software is now directly available on the GCP Marketplace to seamlessly deploy, serve, monitor performance and dynamically scale multiple AI inference requests on MIG-enabled GKE clusters.
Bringing it All Together
GKE’s managed Kubernetes services combined with the flexibility of the A100 MIG feature and NVIDIA’s GPU-optimized solution stack for accelerating ML pipelines helps address both the development and infrastructure management challenges of productizing end-to-end ML pipelines.
Recommender systems (RecSys) have become a key component in many online services, such as e-commerce, social media, news service, or online video streaming. However with their growth in importance, the growth in scale of industry datasets, and more sophisticated models, the bar has been raised for computational resources required for recommendation systems. After NVIDIA introduced Merlin … Continued
Recommender systems (RecSys) have become a key component in many online services, such as e-commerce, social media, news service, or online video streaming. However with their growth in importance, the growth in scale of industry datasets, and more sophisticated models, the bar has been raised for computational resources required for recommendation systems.
After NVIDIA introduced Merlin – a Framework for Deep Recommender Systems – to meet the computational demands for large-scale DL recommender systems, and a NVIDIA team won the ACM RecSys Challenge 2020, now a NVIDIA team has won the WSDM WebTour 21 Challenge organized by Booking.com. The Booking.com challenge focused on predicting the last city destination for a traveler’s trip given their previous booking history within the trip. NVIDIA’s interdisciplinary team included colleagues from NVIDIA’s KGMON (Kaggle Grandmasters), NVIDIA’s RAPIDS (Data Science), and NVIDIA’s Merlin (Recommender Systems) who collaborated on the winning solution.
This post is the first of a three-part series that gives an overview of the NVIDIA team’s first place solution for the booking.com challenge. This first post gives an overview of recommender system concepts. The second post will discuss deep learning for recommender systems. The third post will discuss the winning solution, the steps involved, and also what made a difference in the outcome.
What is a Recommendation System?
Recommender systems are trained to understand the preferences, previous decisions, and characteristics of people and products, using data gathered about their interactions, which include impressions, clicks, likes, and purchases. Recommender systems help solve information overload by helping users find relevant products from a wide range of selections by providing personalized content. Because of their capability to predict consumer interests and desires on a highly personalized level, recommender systems are a favorite with content and product providers because they drive consumers to just about any product or service that interests them, from books to videos to health classes to clothing.
Figure 1 A recommendation system filters items and only shows those most likely to induce an interaction.
Types of Recommendation Systems
Traditionally, recommender systems approaches could be divided into these broad categories: collaborative filtering, content filtering, and hybrid recommenders systems. More recently, some variations have been proposed to leverage explicitly the user context (context-aware recommendation), the sequence of user interactions (sequential recommendation) and the interactions of the current user session for next-click prediction (session-based recommendation).
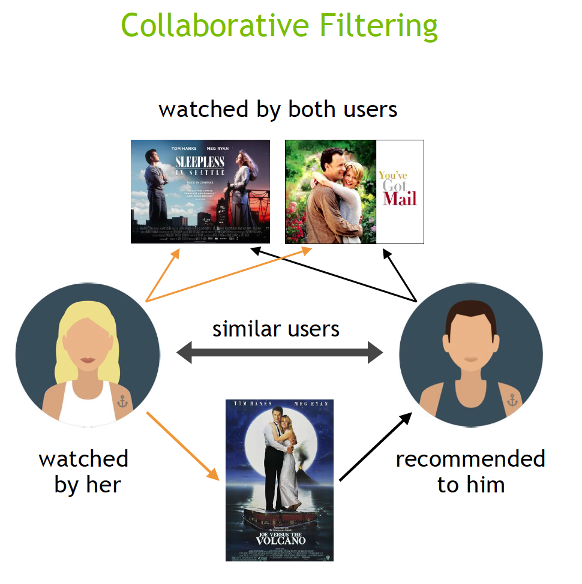
Collaborative filtering algorithms recommend items (this is the filtering part) based on preference information from many users (this is the collaborative part). This approach uses similarity of user preference behavior, given previous interactions between users and items, recommender algorithms learn to predict future interaction. These recommender systems build a model from a user’s past behavior, such as items purchased previously or ratings given to those items and similar decisions by other users. The idea is that if some people have made similar decisions and purchases in the past, like a movie choice, then there is a high probability they will agree on additional future selections. For example, if a collaborative filtering recommender knows you and another user share similar tastes in movies, it might recommend a movie to you that it knows this other user already likes.
Figure 2: collaborative filtering recommends items based on how similar users liked the item.
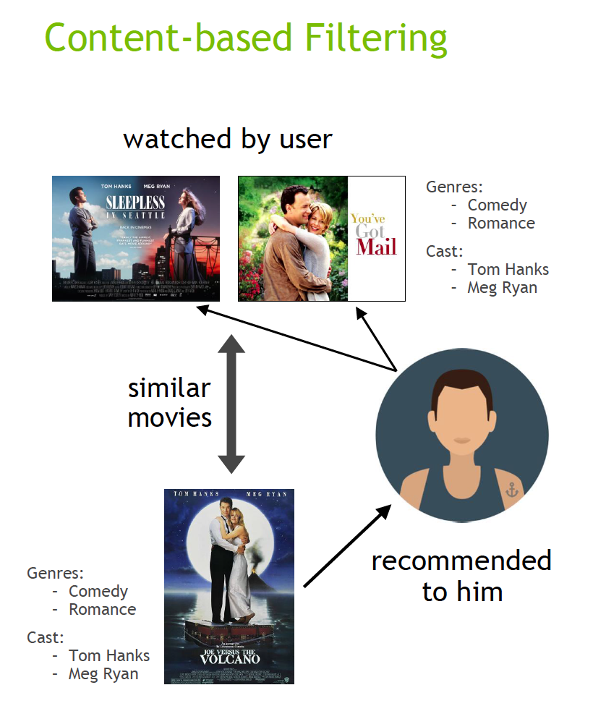
Content filtering, by contrast, uses the attributes or features of an item (this is the content part) to recommend other items similar to the user’s preferences. This approach is based on similarity of items and user features, given information about a user and items they have interacted with, (e.g. a user’s demographics, like age or gender, the category of a restaurant’s cuisine, the average review for a movie), model the likelihood of a new interaction. For example, if a content filtering recommender sees you liked the movies “You’ve Got Mail” and “Sleepless in Seattle,” it might recommend another movie to you with the same genres and/or cast, such as “Joe Versus the Volcano.”
Figure 3: Content filtering recommends items with features similar to the users’ preferences.
Collaborative filtering is straightforward to apply, as it only requires as input the user id and item id for each interaction. However, it requires a minimum number of interactions by user and by item before starting to provide meaningful recommendations, which is characterized as the cold-start problem. On the other hand, as content-based filtering only leverages the interactions of each user, it deals nicely with the user cold-start problem. But it tends to create a filter bubble, recommending only items very similar to those the user has interacted with before.
Hybrid recommender systems combine the advantages of the types above to create a more comprehensive recommending system.
Session or sequence-based recommender systems use the sequence of user item interactions within a session in the recommendation process. Examples include predicting the next item in an online shopping cart, the next video to watch, or in the booking.com example, the next travel destination of a traveler.
Netflix spoke at NVIDIA GTC about making better recommendations by framing a recommendation as a contextual sequence prediction. Their approach uses a sequence of user actions, plus the current context, to predict the probability of the next action. In the Netflix example, given one sequence for each user—the country, device, date, and time when they watched a movie—they trained a model to predict what to watch next.
Figure 4: Netflix uses a sequence of contextual user actions, plus the current context, to predict the probability of the next movie a user will want to watch.
How Recommenders Work
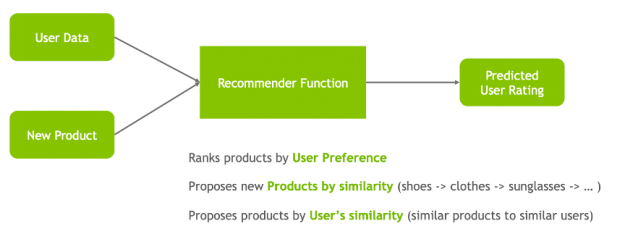
Recommender systems are trained using data gathered about the users, items, and their interactions, which include impressions, clicks, likes, mentions, and so on. How a recommender model makes recommendations will depend on the type of data you have. If you only have data about which interactions have occurred in the past, you’ll probably be interested in collaborative filtering. If you have data describing the user and items they have interacted with (e.g. a user’s age, the category of a restaurant’s cuisine, the average review for a movie), you can model the likelihood of a new interaction given these properties at the current moment by adding content and context filtering.
Figure 5: Recommenders use data gathered about the users, items, and their interactions to rank products by user preference, and then propose new products by product similarity and or to propose products by user’s similarity.
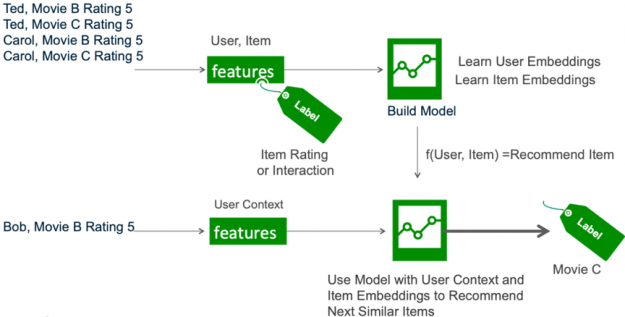
Matrix Factorization for Recommendation
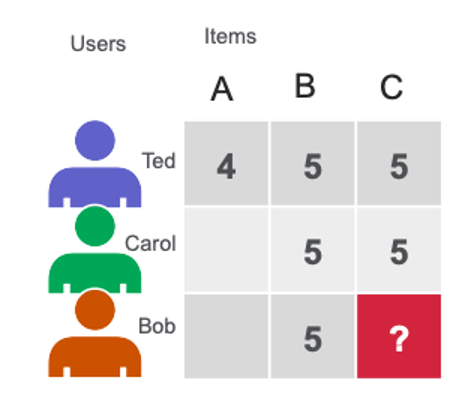
Matrix factorization (MF) techniques are the core of many popular algorithms, including word embedding and topic modeling, and have become a dominant methodology within the collaborative-filtering-based recommendations. MF can be used to calculate the similarity in user’s ratings or interactions to provide recommendations. In the simple user-item matrix below, Ted and Carol like movies B and C. Bob likes movie B. To recommend a movie to Bob, matrix factorization calculates that users who liked B also liked C, so C is a possible recommendation for Bob.
Figure 6: A user-item matrix with users as rows, Items as columns, and a user rating for an item as the cell value.
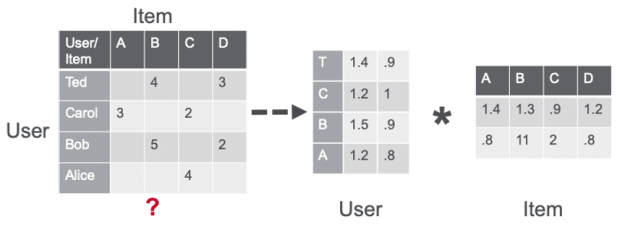
Matrix factorization using the alternating least squares (ALS) algorithm approximates the sparse user item rating matrix u-by-i as the product of two dense matrices, user and item factor matrices of size u × f and f × i (where u is the number of users, i the number of items and f the number of latent features) . The factor matrices represent latent or hidden features which the algorithm tries to discover. One matrix tries to describe the latent or hidden features of each user, and one tries to describe latent properties of each movie. For each user and for each item, the ALS algorithm iteratively learns (f) numeric “factors” that represent the user or item. In each iteration, the algorithm alternatively holds one factor matrix fixed and optimizes for the other by minimizing the loss function with respect to the other. This process continues until it converges.
Figure 7: Matrix factorization factors a sparse ratings matrix R (u-by-i) into a u-by-f matrix (U) and an f-by-i matrix (I ).
Conclusion
In this blog, we gave an overview of recommender system concepts and matrix factorization. In part two we will go over deep learning models for recommender systems and in part three we will go over the booking.com winning solution. To learn more, be sure to:
A recent National Poetry Month feature in The Washington Post presented AI-generated artwork alongside five original poems reflecting on seasons of the past year.
A recent National Poetry Month feature in The Washington Postpresented AI-generated artwork alongside five original poems reflecting on seasons of the past year.
Created by the Lede Lab — an experimental news team at The Post dedicated to exploring emerging technologies and new storytelling techniques — the artwork combined the output of machine learning models including NVIDIA StyleGAN2. Developed by NVIDIA Research, StyleGAN is a popular AI for high-res image generation that’s been adopted for art exhibits, manga illustrations and reimagined historical portraits.
Running on NVIDIA GPUs in the cloud, StyleGAN2 was trained on scanned images of brush strokes and palette knife textures painted by the group’s designer, Shikha Subramaniam.
The team also used the open-source AttnGAN model to create generative art that responded line by line to each of the five commissioned poems in the piece. Combined, the outputs from both models created a series of abstract videos to accompany the text.
As readers scroll through the interactive feature, the dynamic AI-generated artwork morphs to reflect each line of the poems — in one case shifting from colorful to monochrome and back again.
“Anxiously watching the coronavirus spread across the globe, we missed sharing so much with others, including the four seasons with their shifts in color and temperature,” wrote Suzette Moyer, senior design editor at The Post. The poems — authored by Mary Szybist, Dorianne Laux, Ada Limón, Kazim Ali and Willie Perdomo — are “hopeful works about the seasons we missed and the days we can look forward to.”

 NVIDIA announced its latest update to the HPL-AI Benchmark version 2.0.0, which will reside in the HPC-Benchmarks container version 21.4.
NVIDIA announced its latest update to the HPL-AI Benchmark version 2.0.0, which will reside in the HPC-Benchmarks container version 21.4. 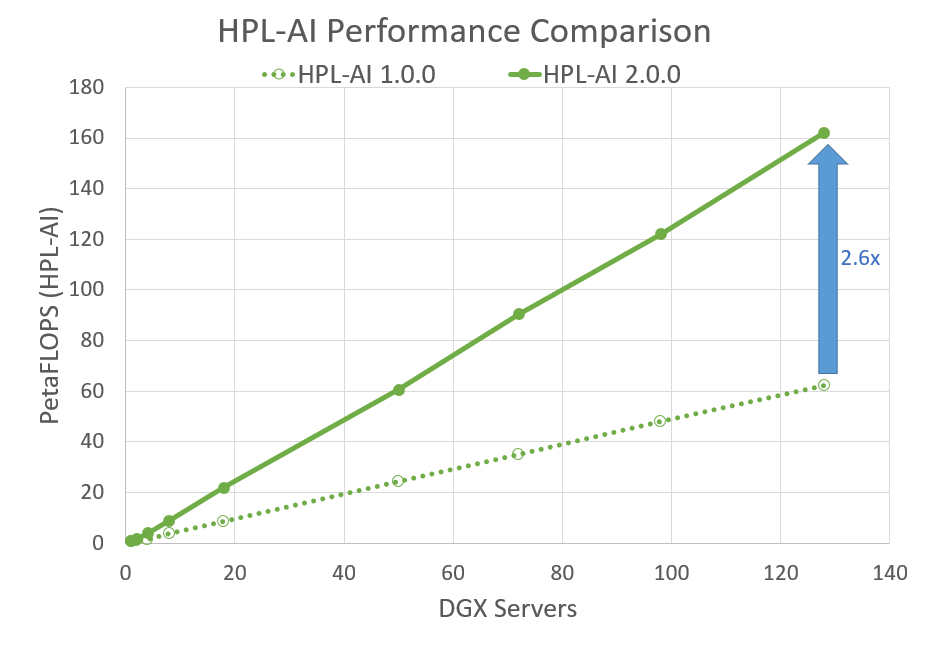
 Today, NVIDIA is announcing the availability of cuTENSOR version 1.3.0. This software can be downloaded now free for members of the NVIDIA Developer Program.
Today, NVIDIA is announcing the availability of cuTENSOR version 1.3.0. This software can be downloaded now free for members of the NVIDIA Developer Program.
 Recommender systems (RecSys) have become a key component in many online services, such as e-commerce, social media, news service, or online video streaming. However with the growth in importance, the growth in scale of industry datasets, and more sophisticated models, the bar has been raised for computational resources required for recommendation systems. To meet the …
Recommender systems (RecSys) have become a key component in many online services, such as e-commerce, social media, news service, or online video streaming. However with the growth in importance, the growth in scale of industry datasets, and more sophisticated models, the bar has been raised for computational resources required for recommendation systems. To meet the … 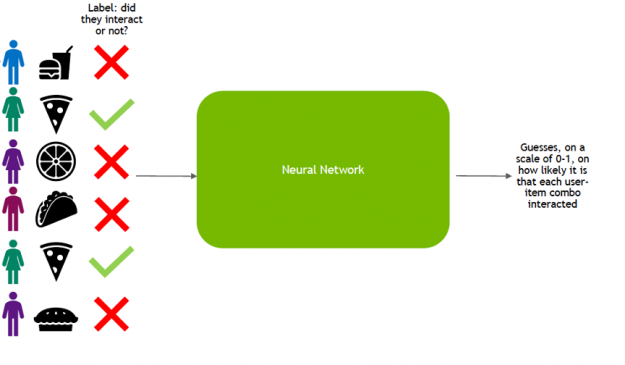
 —an open-source data analytics and machine learning acceleration platform—for executing end-to-end data science training pipelines completely in GPUs. It relies on NVIDIA® CUDA® primitives for low-level compute optimization, but exposes that GPU parallelism and high memory bandwidth through user-friendly Python interfaces.
—an open-source data analytics and machine learning acceleration platform—for executing end-to-end data science training pipelines completely in GPUs. It relies on NVIDIA® CUDA® primitives for low-level compute optimization, but exposes that GPU parallelism and high memory bandwidth through user-friendly Python interfaces.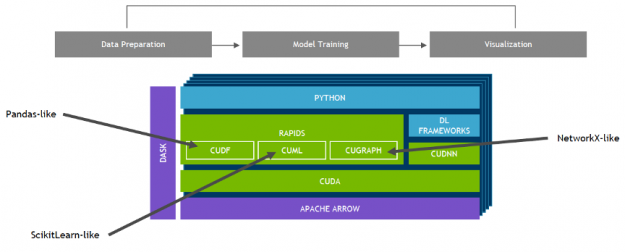
 Google Cloud and NVIDIA collaborated to make MLOps simple, powerful, and cost-effective by bringing together the solution elements to build, serve and dynamically scale your end-to-end ML pipelines with the right-sized GPU acceleration in one place.
Google Cloud and NVIDIA collaborated to make MLOps simple, powerful, and cost-effective by bringing together the solution elements to build, serve and dynamically scale your end-to-end ML pipelines with the right-sized GPU acceleration in one place. 



 Recommender systems (RecSys) have become a key component in many online services, such as e-commerce, social media, news service, or online video streaming. However with their growth in importance, the growth in scale of industry datasets, and more sophisticated models, the bar has been raised for computational resources required for recommendation systems. After NVIDIA introduced Merlin …
Recommender systems (RecSys) have become a key component in many online services, such as e-commerce, social media, news service, or online video streaming. However with their growth in importance, the growth in scale of industry datasets, and more sophisticated models, the bar has been raised for computational resources required for recommendation systems. After NVIDIA introduced Merlin … 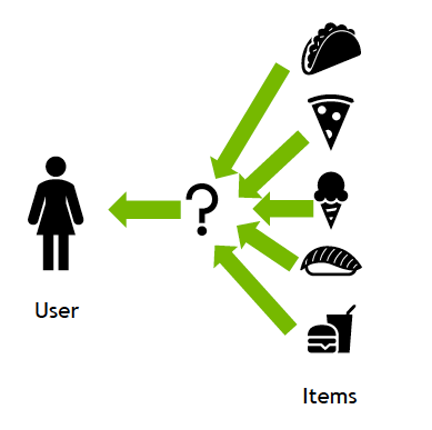

 A recent National Poetry Month feature in The Washington Post presented AI-generated artwork alongside five original poems reflecting on seasons of the past year.
A recent National Poetry Month feature in The Washington Post presented AI-generated artwork alongside five original poems reflecting on seasons of the past year.