I am trying to build a sentiment classification (hate speech) for German language using NLP + Deep Learning. Any code tutorial? I found lots of research papers but few code implementations.
submitted by /u/grid_world
[visit reddit] [comments]
 DataBloom
DataBloomI am trying to build a sentiment classification (hate speech) for German language using NLP + Deep Learning. Any code tutorial? I found lots of research papers but few code implementations.
submitted by /u/grid_world
[visit reddit] [comments]
 Read how the power of AI and edge computing is critical to driving operational efficiencies and productivity gains.
Read how the power of AI and edge computing is critical to driving operational efficiencies and productivity gains.
Automation and monitoring of industrial assets, systems, processes, and environments are increasingly important across manufacturing industries, including transportation, electronics, mining, and textiles. In order to implement safer and more productive practices, companies are automating their manufacturing processes with IoT sensors. IoT sensors generate vast amounts of data that, when combined with the power of AI, produce valuable insights that manufacturers can use to improve operational efficiency.
Edge computing allows sensor-enabled devices to collect and process data locally to deliver insights on the factory floor without having to communicate with the cloud. Edge AI enables any device or computer to process data and make AI-led decisions in real time, with minimal latency. This convenience gives rise to new use cases where fast, real-time insights are required, like when scanning for product defects on assembly lines, identifying workplace hazards, flagging machines that require maintenance, and more.
By bringing AI processing tasks closer to the source, edge computing provides many advantages to manufacturers, including:
Manufacturers globally have started to use AI at the edge to transform their manufacturing processes. The following use cases explore how edge computing is promoting enhanced efficiency and productivity in manufacturing.
Edge computing will continue to transform the manufacturing industry by bringing about AI-driven operational efficiencies and productivity gains. Download this free e-book to learn how edge computing is helping build smarter and safer spaces around the world.
Instance segmentation is the task of grouping pixels in an image into instances of individual things, and identifying those things with a class label (countable objects such as people, animals, cars, etc., and assigning unique identifiers to each, e.g., car_1 and car_2). As a core computer vision task, it is critical to many downstream applications, such as self-driving cars, robotics, medical imaging, and photo editing. In recent years, deep learning has made significant strides in solving the instance segmentation problem with architectures like Mask R-CNN. However, these methods rely on collecting a large labeled instance segmentation dataset. But unlike bounding box labels, which can be collected in 7 seconds per instance with methods like Extreme clicking, collecting instance segmentation labels (called “masks”) can take up to 80 seconds per instance, an effort that is costly and creates a high barrier to entry for this research. And a related task, pantopic segmentation, requires even more labeled data.
The partially supervised instance segmentation setting, where only a small set of classes are labeled with instance segmentation masks and the remaining (majority of) classes are labeled only with bounding boxes, is an approach that has the potential to reduce the dependence on manually-created mask labels, thereby significantly lowering the barriers to developing an instance segmentation model. However this partially supervised approach also requires a stronger form of model generalization to handle novel classes not seen at training time—e.g., training with only animal masks and then tasking the model to produce accurate instance segmentations for buildings or plants. Further, naïve approaches, such as training a class-agnostic Mask R-CNN, while ignoring mask losses for any instances that don’t have mask labels, have not worked well. For example, on the typical “VOC/Non-VOC” benchmark, where one trains on masks for a subset of 20 classes in COCO (called “seen classes”) and is tested on the remaining 60 classes (called “unseen classes”), a typical Mask R-CNN with Resnet-50 backbone gets to only ~18% mask mAP (mean Average Precision, higher is better) on unseen classes, whereas when fully supervised it can achieve a much higher >34% mask mAP on the same set.
In “The surprising impact of mask-head architecture on novel class segmentation”, to be presented at ICCV 2021, we identify the main culprits for Mask R-CNN’s poor performance on novel classes and propose two easy-to-implement fixes (one training protocol fix, one mask-head architecture fix) that work in tandem to close the gap to fully supervised performance. We show that our approach applies generally to crop-then-segment models, i.e., a Mask R-CNN or Mask R-CNN-like architecture that computes a feature representation of the entire image and then subsequently passes per-instance crops to a second-stage mask prediction network—also called a mask-head network. Putting our findings together, we propose a Mask R-CNN–based model that improves over the current state-of-the-art by a significant 4.7% mask mAP without requiring more complex auxiliary loss functions, offline trained priors, or weight transfer functions proposed by previous work. We have also open sourced the code bases for two versions of the model, called Deep-MAC and Deep-MARC, and published a colab to interactively produce masks like the video demo below.
| A demo of our model, DeepMAC, which learns to predict accurate masks, given user specified boxes, even on novel classes that were not seen at training time. Try it yourself in the colab. Image credits: Chris Briggs, Wikipedia and Europeana. |
Impact of Cropping Methodology in Partially Supervised Settings
An important step of crop-then-segment models is cropping—Mask R-CNN is trained by cropping a feature map as well as the ground truth mask to a bounding box corresponding to each instance. These cropped features are passed to another neural network (called a mask-head network) that computes a final mask prediction, which is then compared against the ground truth crop in the mask loss function. There are two choices for cropping: (1) cropping directly to the ground truth bounding box of an instance, or (2) cropping to bounding boxes predicted by the model (called, proposals). At test time, cropping is always performed with proposals as ground truth boxes are not assumed to be available.
 |
| Cropping to ground truth boxes vs. cropping to proposals predicted by a model during training. Standard Mask R-CNN implementations use both types of crops, but we show that cropping exclusively to ground truth boxes yields significantly stronger performance on novel categories. |
 |
| We consider a general family of Mask R-CNN–like architectures with one small, but critical difference from typical Mask R-CNN training setups: we crop using ground truth boxes (instead of proposal boxes) at training time. |
Typical Mask R-CNN implementations pass both types of crops to the mask head. However, this choice has traditionally been considered an unimportant implementation detail, because it does not affect performance significantly in the fully supervised setting. In contrast, for partially supervised settings, we find that cropping methodology plays a significant role—while cropping exclusively to ground truth boxes during training doesn’t change the results significantly in the fully supervised setting, it has a surprising and dramatic positive impact in the partially supervised setting, performing significantly better on unseen classes.
 |
| Performance of Mask R-CNN on unseen classes when trained with either proposals and ground truth (the default) or with only ground truth boxes. Training mask heads with only ground truth boxes yields a significant boost to performance on unseen classes, upwards of 9% mAP. We report performance with the ResNet-101-FPN backbone. |
Unlocking the Full Generalization Potential of the Mask Head
Even more surprisingly, the above approach unlocks a novel phenomenon—with cropping-to-ground truth enabled during training, the mask head of Mask R-CNN takes on a disproportionate role in the ability of the model to generalize to unseen classes. As an example, in the following figure, we compare models that all have cropping-to-ground-truth enabled, but different out-of-the-box mask-head architectures on a parking meter, cell phone, and pizza (classes unseen during training).
 |
| Mask predictions for unseen classes with four different mask-head architectures (from left to right: ResNet-4, ResNet-12, ResNet-20, Hourglass-20, where the number refers to the number of layers of the neural network). Despite never having seen masks from the ‘parking meter’, ‘pizza’ or ‘mobile phone’ class, the rightmost mask-head architecture can segment these classes correctly. From left to right, we show better mask-head architectures predicting better masks. Moreover, this difference is only apparent when evaluating on unseen classes — if we evaluate on seen classes, all four architectures exhibit similar performance. |
Particularly notable is that these differences between mask-head architectures are not as obvious in the fully supervised setting. Incidentally, this may explain why previous works in instance segmentation have almost exclusively used shallow (i.e., low number of layers) mask heads, as there has been no benefit to the added complexity. Below we compare the mask mAP of three different mask-head architectures on seen versus unseen classes. All three models do equally well on the set of seen classes, but the deep hourglass mask heads stand out when applied to unseen classes. We find hourglass mask heads to be the best among the architectures we tried and we use hourglass mask heads with 50 or more layers to get the best results.
 |
| Performance of ResNet-4, Hourglass-10 and Hourglass-52 mask-head architectures on seen and unseen classes. There is a significant difference in performance on unseen classes, even though the performance on seen classes barely changes. |
Finally, we show that our findings are general, holding for a variety of backbones (e.g., ResNet, SpineNet, Hourglass) and detector architectures including anchor-based and anchor-free detectors and even when there is no detector at all.
Putting It Together
To achieve the best result, we combined the above findings: We trained a Mask R-CNN model with cropping-to-ground-truth enabled and a deep Hourglass-52 mask head with a SpineNet backbone on high resolution images (1280×1280). We call this model Deep-MARC (Deep Mask heads Above R–CNN). Without using any offline training or other hand-crafted priors, Deep-MARC exceeds previous state-of-the-art models by > 4.5% (absolute) mask mAP. Demonstrating the general nature of this approach, we also see strong results with a CenterNet-based (as opposed to Mask R-CNN-based) model (called Deep-MAC), which also exceeds the previous state of the art.
 |
| Comparison of Deep-MAC and Deep-MARC to other partially supervised instance segmentation approaches like MaskX R-CNN, ShapeMask and CPMask. |
Conclusion
We develop instance segmentation models that are able to generalize to classes that were not part of the training set. We highlight the role of two key ingredients that can be applied to any crop-then-segment model (such as Mask R-CNN): (1) cropping-to-ground truth boxes during training, and (2) strong mask-head architectures. While neither of these ingredients have a large impact on the classes for which masks are available during training, employing both leads to significant improvement on novel classes for which masks are not available during training. Moreover, these ingredients are sufficient for achieving state-of-the-art-performance on the partially-supervised COCO benchmark. Finally, our findings are general and may also have implications for related tasks, such as panoptic segmentation and pose estimation.
Acknowledgements
We thank our co-authors Zhichao Lu, Siyang Li, and Vivek Rathod. We thank David Ross and our anonymous ICCV reviewers for their comments which played a big part in improving this research.

 A new study creates a deep convolutional neural network using global satellite imagery to detect sustainable roofscapes—a promising strategy for climate mitigation.
A new study creates a deep convolutional neural network using global satellite imagery to detect sustainable roofscapes—a promising strategy for climate mitigation.
A new AI-mapping tool is helping scientists assess how cities across the globe are using rooftops to combat climate change. Named Roofpedia, the research creates an open-source and scalable map of sustainable rooftops—a promising strategy for climate mitigation. Identifying areas with solar or green installations could help guide urban development, while also boosting community health, prosperity, and the environment.
“By collecting such data, Roofpedia allows us to gauge how cities might further utilize their rooftops to mitigate carbon emissions and how much untapped potential their roofscapes have,” coauthor Filip Biljecki, an assistant professor at the National University of Singapore and principal investigator for the Urban Analytics Lab, said in a press release.
By 2050, an estimated 68% of the world’s population will be living in urban areas. Strategies focused on the well-being of people and the planet remain central to creating healthy and thriving communities in the future. Studies have shown the benefits of sustainable rooftops—most commonly roofs with solar or green space— are plentiful and wide-ranging. Beyond creating an efficient and relatively clean source of energy, they also reduce carbon emissions, add to food production, aid stormwater management, improve air quality, create wildlife habitat, reduce traffic noise, and promote biodiversity.
Accounting for current installations could help planners and developers benchmark spaces, identify new potential areas, gauge the effectiveness of current incentives such as subsidies, and track the progress of environmentally friendly businesses.
Despite the advantages, most research focuses on estimating the potential of these roofscapes, rather than their distribution globally. A lack of data also limits the understanding of current totals, distribution, and global growth.
The team sought out to fill this data gap with the creation of Roofpedia, an open registry of sustainable roofscapes around the world.
The tool was created using high-resolution satellite imagery from Mapbox, with images from 17 diverse cities across Europe, North America, Australia, and Asia. Sampling a range of urban contexts and image conditions, the team hand-labeled some of the satellite images and trained a convolutional neural network to identify and tag roofs with solar, green space, or both.
According to study co-author Abraham Wu, Roofpedia was developed on PyTorch using NVIDIA Docker and an NVIDIA RTX 2060 GPU.
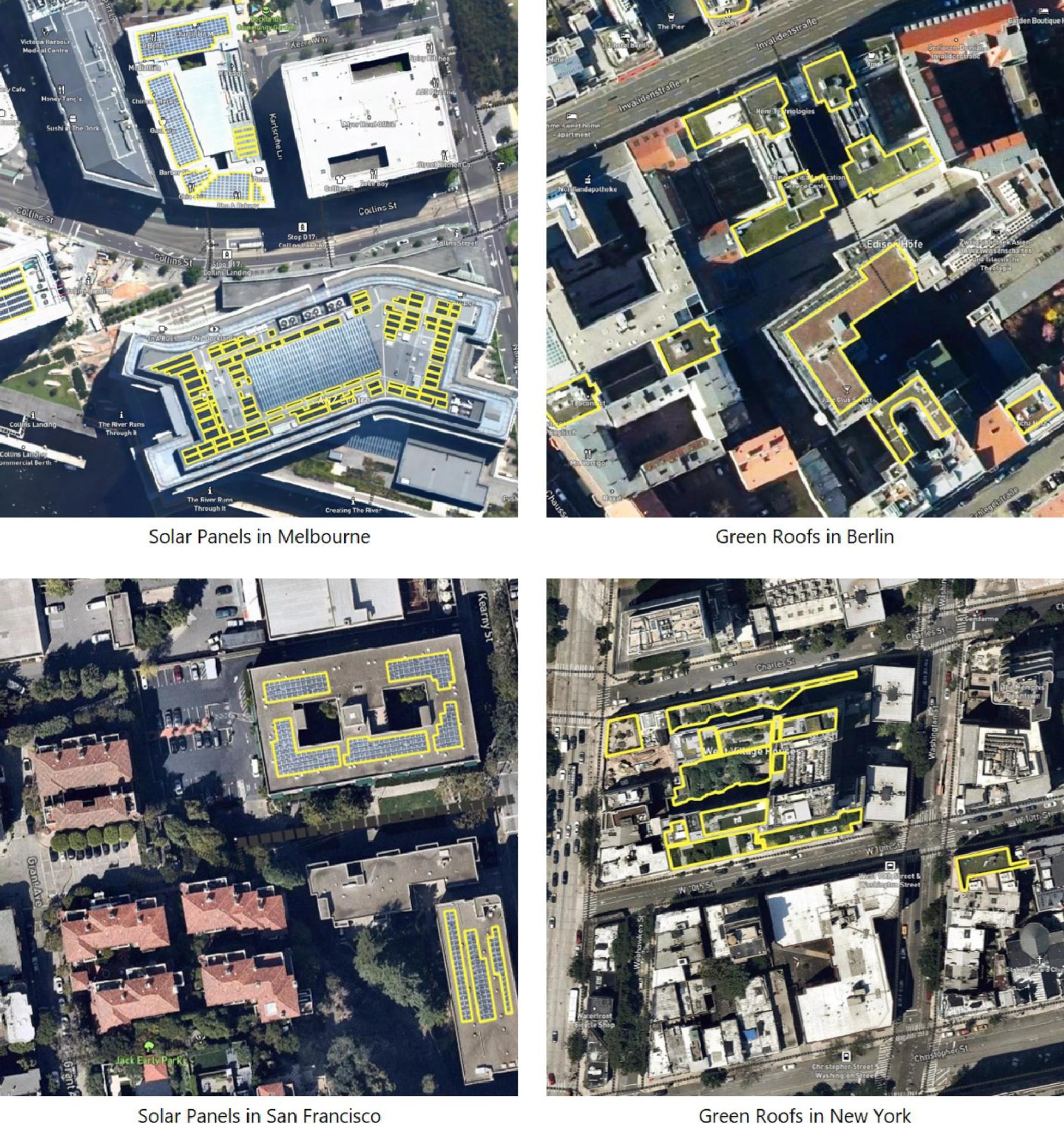
As data is added to the Roofpedia Registry and Index, the tool maps the distribution of solar and green rooftops and calculates the rank of a city. Scores and ranks are calculated by comparing solar and green roofs against the total number of buildings and area of buildings in a city, along with an overall combined score.
Currently, Las Vegas leads the solar ranking with a score of 86, while Zurich scores high in both solar (81) and green (100), for a combined score of 91.
There are over a million buildings in the current data set and the researchers note that more cities are being added as aerial or satellite imagery becomes available. Final results are rendered on Mapbox, with both the dataset and code available on GitHub.
“We are making this sustainable roofscape inventory available publicly, aiding researchers, practitioners, local governments, and the public to understand the current status of the roofscape in the context of sustainable urban development and achieving carbon neutrality,” the researchers write in the study.
Read the full article in Landscape and Urban Planning >>
Read more >>
Imagine trying to make contact with super-intelligent beings. Now imagine they’re not from space. Sperm whales, the largest of the toothed whales, boast enormous brains, explains David Gruber, a professor of biology and environmental science at the City University of New York. Their brains weigh 20 pounds compared to our three-pounders. Perhaps more important: their Read article >
The post Whale Hello There: NVIDIA Intern Part of Team Working to Understand, Communicate with Whales appeared first on The Official NVIDIA Blog.
Highlighting NVIDIA’s fast-growing impact, Time magazine Wednesday named NVIDIA CEO Jensen Huang to its list of most influential people of 2021. NVIDIA has enabled a revolution that “allows phones to answer questions out loud, farms to spray weeds but not crops, doctors to predict the properties of new drugs—with more wonders to come,” Andrew Ng Read article >
The post NVIDIA to Drive “Advances for Decades to Come,” Time Magazine Writes appeared first on The Official NVIDIA Blog.
A multi-hospital initiative sparked by the COVID-19 crisis has shown that, by working together, institutions in any industry can develop predictive AI models that set a new standard for both accuracy and generalizability. Published today in Nature Medicine, a leading peer-reviewed healthcare journal, the collaboration demonstrates how privacy-preserving federated learning techniques can enable the creation Read article >
The post Medical AI Needs Federated Learning, So Will Every Industry appeared first on The Official NVIDIA Blog.


|
Targetran is a new light-weight image augmentation library, to be used for object detection or image classification model training. While there are other powerful augmentation tools available, many of those operate only on NumPy arrays and do not work well with the TPU when accessing from Google Colab or Kaggle Notebooks. This is a known challenge addressed by some Kaggle practitioners. Targetran offers transformation tools using pure TensorFlow ops, and hence they work smoothly with the TPU via a TensorFlow Dataset. Please take a look if you are facing a similar challenge: https://github.com/bhky/targetran submitted by /u/xtorch501 |
Hi, guys!
I have been trying to find the cholesky decomposition of a bunch of randomly generated positive definite matrices but if the size of my matrix is any bigger than 2 by 2, tf gives me an error saying that the input is not correct for the tf.linalg.cholesky function.
I have even changed the data type to float64 but still no luck
Any help would be appreciated!
submitted by /u/RaunchyAppleSauce
[visit reddit] [comments]
 This post defines NICs, SmartNICs, and lays out a cost-benefit analysis for NIC categories and use cases.
This post defines NICs, SmartNICs, and lays out a cost-benefit analysis for NIC categories and use cases.
This post was originally published on the Mellanox blog.
Everyone is talking about data processing unit–based SmartNICs but without answering one simple question: What is a SmartNIC and what do they do?
NIC stands for network interface card. Practically speaking, a NIC is a PCIe card that plugs into a server or storage box to enable connectivity to an Ethernet network. A DPU-based SmartNIC goes beyond simple connectivity and implements network traffic processing on the NIC that would necessarily be performed by the CPU, in the case of a foundational NIC.
Some vendors’ definitions of a DPU-based SmartNIC are focused entirely on the implementation. This is problematic, as different vendors have different architectures. Thus, a DPU-based SmartNIC can be ASIC–, FPGA–, and system-on-a-chip-based. Naturally, vendors who make just one kind of NIC insist that only their type of NIC should qualify as a SmartNIC.



There are various tradeoffs between these different implementations with regards to cost, ease of programming, and flexibility. An ASIC is cost-effective and may deliver the best price performance, but it suffers from limited flexibility. An ASIC-based NIC, like the NVIDIA ConnectX-5, can have a programmable data path that is relatively simple to configure. Ultimately, that functionality has limits based on what functions are defined within the ASIC. That can prevent certain workloads from being supported.
By contrast, an FPGA NIC, such as the NVIDIA Innova-2 Flex, is highly programmable. With enough time and effort, it can be made to support almost any functionality relatively efficiently, within the constraints of the available gates. However, FPGAs are notoriously difficult to program and expensive.
For more complex use cases, the SOC, such as the Mellanox BlueField DPU-programmable SmartNIC provides what appears to be the best DPU-based SmartNIC implementation option: good price performance, easy to program, and highly flexible.

Focusing on how a particular vendor implements a DPU-based SmartNIC doesn’t address what it’s capable of or how it should be architected. NVIDIA actually has products based on each of these architectures that could be classified as DPU-based SmartNICs. In fact, customers use each of these products for different workloads, depending on their needs. So the focus on implementation—ASIC vs. FPGA vs. SoC—reverses the ‘form follows function’ philosophy that underlies the best architectural achievements.
Rather than focusing on implementation, I tweaked this PC Magazine encyclopedia entry to give a working definition of what makes a NIC a DPU-based SmartNIC:
DPU-based SmartNIC:
A DPU-based network interface card (network adapter) that offloads processing tasks that the system CPU would normally handle. Using its own onboard processor, the DPU-based SmartNIC may be able to perform any combination of encryption/decryption, firewall, TCP/IP, and HTTP processing. SmartNICs are ideally suited for high-traffic web servers.
There are two things that I like about this definition. First, it focuses on the function more than the form. Second, it hints at this form with the statement, “…using its own onboard processor… to perform any combination of…” network processing tasks. So the embedded processor is key to achieving the flexibility to perform almost any networking function.
You could modernize that definition by adding that DPU-based SmartNICs might also perform network, storage, or GPU virtualization. Also, SmartNICs are also ideally suited for telco, security, machine learning, software-defined storage, and hyperconverged infrastructure servers, not just web servers.
Here’s how to differentiate three categories of NICs by the functions that the network adapters can support and use to accelerate different workloads:

Here I’ve defined three categories of NICs, based on their ability to accelerate specific functionality:
The foundational, or basic NIC simply moves network traffic and has few or no offloads, other than possibly SRIOV and basic TCP acceleration. It doesn’t save any CPU cycles and can’t offload packet steering or traffic flows. At NVIDIA, we don’t even sell a foundational NIC any more.
The NVIDIA ConnectX adapter family features a programmable data path and accelerates a range of functions that first became important in public cloud use cases. For this reason, I’ve defined this type of NIC as an iNIC, although today on-premises enterprise, telco, and private clouds are just as likely as public cloud providers to need this type of programmability and acceleration functionality. Another name for it could be smarterNIC without the capital “S.”
In many cases, customers tell us they need DPU based SmartNIC capabilities that are being offered by a competitor with either an FPGA or a NIC combined with custom, proprietary processing engines. But when customers really look at the functions they need for their specific workloads, ultimately they decide that the ConnectX family of iNICs provides all the function, performance, and flexibility of other so-called SmartNICs at a fraction of the power and cost. So by the definition of SmartNIC that some competitors use – our ConnectX NICs are indeed SmartNICs, though we might call them intelligent NICs or smarter NICs. Our FPGA NIC (Innova) is also a SmartNIC in the classic sense, and our SoC NIC (using BlueField) is the smartest of SmartNICs, to the extent that we could call them Genius NICs
So, what is a SmartNIC? A DPU-based SmartNIC is a network adapter that accelerates functionality and offloads it from the server (or storage) CPU.
How you should build a DPU-based SmartNIC and which SmartNIC is the best for each workload… well, the devil is in the details. It’s important to dig into exactly what data path and virtualization accelerations are available and how they can be used. If you’re interested, see my next post, Achieving a Cloud-Scale Architecture with DPUs.
For more information about SmartNIC use cases, see the following resources:
{kind=link}
{kind=link}