In part 1 of this series, we introduced new API functions, cudaMallocAsync and cudaFreeAsync, that enable memory allocation and deallocation to be stream-ordered operations. In this post, we highlight the benefits of this new capability by sharing some big data benchmark results and provide a code migration guide for modifying your existing applications. We also … Continued
In part 1 of this series, we introduced new API functions, cudaMallocAsync and cudaFreeAsync, that enable memory allocation and deallocation to be stream-ordered operations. In this post, we highlight the benefits of this new capability by sharing some big data benchmark results and provide a code migration guide for modifying your existing applications. We also … Continued
In part 1 of this series, we introduced new API functions, cudaMallocAsync and cudaFreeAsync, that enable memory allocation and deallocation to be stream-ordered operations. In this post, we highlight the benefits of this new capability by sharing some big data benchmark results and provide a code migration guide for modifying your existing applications. We also cover advanced topics to take advantage of stream-ordered memory allocation in the context of multi-GPU access and the use of IPC. This all helps you improve performance within your existing applications.
GPU Big Data Benchmark
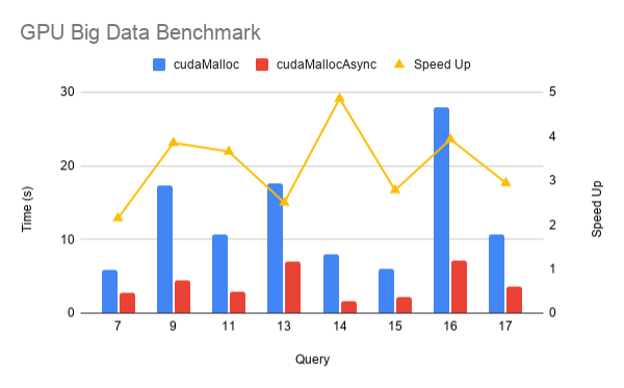
To measure the performance impact of the new stream-ordered allocator in a real application, here are results from the RAPIDS GPU Big Data Benchmark (gpu-bdb). gpu-bdb is a benchmark of 30 queries representing real-world data science and machine learning workflows at various scale factors: SF1000 is 1 TB of data and SF10000 is 10 TB. Each query is, in fact, a model workflow that can include SQL, user-defined functions, careful subsetting and aggregation, and machine learning.
Figure 1 shows the performance of cudaMallocAsync compared to cudaMalloc for a subset of gpu-bdb queries conducted at SF1000 on an NVIDIA DGX-2 across 16 V100 GPUs. As you can see, thanks to memory reuse and eliminating extraneous synchronization, there’s a 2–5x improvement in end-to-end performance when using cudaMallocAsync.
Interoperability with cudaMalloc and cudaFree
An application can use cudaFreeAsync to free a pointer allocated by cudaMalloc. The underlying memory is not freed until the next synchronization of the stream passed to cudaFreeAsync.
cudaMalloc(&ptr, size); kernel>>(ptr); cudaFreeAsync(ptr, stream); cudaStreamSynchronize(stream); // The memory for ptr is freed at this point
Similarly, an application can use cudaFree to free memory allocated using cudaMallocAsync. However, cudaFree does not implicitly synchronize in this case, so the application must insert the appropriate synchronization to ensure that all accesses to the to-be-freed memory are complete. Any application code that may be intentionally or accidentally relying on the implicit synchronization behavior of cudaFree must be updated.
cudaMallocAsync(&ptr, size, stream); kernel>>(ptr); cudaStreamSynchronize(stream); // Must synchronize first cudaFree(ptr);
Multi-GPU access
By default, memory allocated using cudaMallocAsync is accessible from the device associated with the specified stream. Accessing the memory from any other device requires enabling access to the entire pool from that other device. It also requires the two devices to be peer capable, as reported by cudaDeviceCanAccessPeer. Unlike cudaMalloc allocations, cudaDeviceEnablePeerAccess and cudaDeviceDisablePeerAccess have no effect on memory allocated from memory pools.
For example, consider enabling device 4access to the memory pool of device 3:
cudaMemPool_t mempool;
cudaDeviceGetDefaultMemPool(&mempool, 3);
cudaMemAccessDesc desc = {};
desc.location.type = cudaMemLocationTypeDevice;
desc.location.id = 4;
desc.flags = cudaMemAccessFlagsProtReadWrite;
cudaMemPoolSetAccess(mempool, &desc, 1 /* numDescs */);
Access from a device other than the device on which the memory pool resides can be revoked by using cudaMemAccessFlagsProtNone when calling cudaMemPoolSetAccess. Access from the memory pool’s own device cannot be revoked.
Interprocess communication support
Memory allocated using the default memory pool associated with a device cannot be shared with other processes. An application must explicitly create its own memory pools to share memory allocated using cudaMallocAsync with other processes. The following code sample shows how to create an explicit memory pool with interprocess communication (IPC) capabilities:
cudaMemPool_t exportPool;
cudaMemPoolProps poolProps = {};
poolProps.allocType = cudaMemAllocationTypePinned;
poolProps.handleTypes = cudaMemHandleTypePosixFileDescriptor;
poolProps.location.type = cudaMemLocationTypeDevice;
poolProps.location.id = deviceId;
cudaMemPoolCreate(&exportPool, &poolProps);
The location type Device and location ID deviceId indicate that the pool memory must be allocated on a specific GPU. The allocation type Pinned indicates that the memory should be non-migratable, also known as non-pageable. The handle type PosixFileDescriptor indicates that the user intends to query a file descriptor for the pool to share it with another process.
The first step to share memory from this pool through IPC is to query the file descriptor that represents the pool:
int fd; cudaMemAllocationHandleType handleType = cudaMemHandleTypePosixFileDescriptor; cudaMemPoolExportToShareableHandle(&fd, exportPool, handleType, 0);
The application can then share the file descriptor with another process, for example through a UNIX domain socket. The other process can then import the file descriptor and obtain a process-local pool handle:
cudaMemPool_t importPool; cudaMemAllocationHandleType handleType = cudaMemHandleTypePosixFileDescriptor; cudaMemPoolImportFromShareableHandle(&importPool, &fd, handleType, 0);
The next step is for the exporting process to allocate memory from the pool:
cudaMallocFromPoolAsync(&ptr, size, exportPool, stream);
There is also an overloaded version of cudaMallocAsync that takes the same arguments as cudaMallocFromPoolAsync:
cudaMallocAsync(&ptr, size, exportPool, stream);
After memory is allocated from this pool through either of these two APIs, the pointer can then be shared with the importing process. First, the exporting process gets an opaque handle representing the memory allocation:
cudaMemPoolPtrExportData data; cudaMemPoolExportPointer(&data, ptr);
This opaque data can then be shared with the importing process through any standard IPC mechanism, such as through shared memory, pipes, and so on The importing process then converts the opaque data into a process-local pointer:
cudaMemPoolImportPointer(&ptr, importPool, &data);
Now both processes share access to the same memory allocation. The memory must be freed in the importing process before it is freed in the exporting process. This is to ensure that the memory does not get reutilized for another cudaMallocAsync request in the exporting process while the importing process is still accessing the previously shared memory allocation, potentially causing undefined behavior.
The existing function cudaIpcGetMemHandle works only with memory allocated through cudaMalloc and cannot be used on any memory allocated through cudaMallocAsync, regardless of whether the memory was allocated from an explicit pool.
Changing a device pool
If the application expects to use an explicit memory pool most of the time, it can consider setting that as the current pool for the device through cudaDeviceSetMemPool. This enables the application to avoid having to specify the pool argument each time that it must allocate memory from that pool.
cudaDeviceSetMemPool(device, pool); cudaMallocAsync(&ptr, size, stream); // This now allocates from the earlier pool set instead of the device’s default pool.
This has the advantage that any other function allocating with cudaMallocAsync now automatically uses the new pool as its default. The current pool associated with a device can be queried using cudaDeviceGetMemPool.
Library composability
In general, libraries should not change a device’s pool, as doing so affects the entire top-level application. If a library must allocate memory with different properties than those of the default device pool, it may create its own pool and then allocate from that pool using cudaMallocFromPoolAsync. The library could also use the overloaded version of cudaMallocAsync that takes the pool as an argument.
To make interoperability easier for applications, libraries should consider providing APIs for the top-level application to coordinate the pools used. For example, libraries could provide set or get APIs to enable the application to control the pool in a more explicit manner. The library could also take the pool as a parameter to individual APIs.
Code migration guide
When porting an existing application that uses cudaMalloc or cudaFree to the new cudaMallocAsync or cudaFreeAsync APIs, consider the following guidelines.
Guidelines for determining the appropriate pool:
- The initial default pool is suitable for many applications.
- Today, an explicitly constructed pool is only required to share pool memory across processes with CUDA IPC. This may change with future features.
- For convenience, consider making the explicitly created pool the device’s current pool to ensure that all
cudaMallocAsynccalls within the process use that pool. This must be done by the top-level application and not by libraries, so as to avoid conflicting with the goals of the top-level application.
Guidelines for setting the release threshold for all memory pools:
- The choice of release threshold depends on whether and how a device is shared:
- Exclusive to a single process: Use the maximum release threshold.
- Shared among cooperating processes: Coordinate to use the same pool through IPC or set each process pool to an appropriate value to avoid any one process monopolizing all device memory.
- Shared among unknown processes: If known, set the threshold to the working set size of the application. Otherwise, leave it at zero and use a profiler to determine whether allocation performance is a bottleneck before using a nonzero value.
Guidelines for replacing cudaMalloc with cudaMallocAsync:
- Ensure that all memory accesses are ordered after the stream-ordered allocation.
- If peer access is required, use
cudaMemPoolSetAccessascudaEnablePeerAccessandcudaDisablePeerAccessshave no effect on pool memory. - Unlike
cudaMallocallocations,cudaDeviceResetdoes not implicitly free pool memory, so it must be explicitly freed. - If freeing with
cudaFree, ensure that all accesses are complete through appropriate synchronization before freeing, as there is no implicit synchronization in this case. Any subsequent code that relied on the implicit synchronization may also have to be updated. - If memory is shared with another process through IPC, allocate from an explicitly created pool with IPC support and remove all references to
cudaIpcGetMemHandle,cudaIpcOpenMemHandle, andcudaIpcCloseMemHandlefor that pointer. - If the memory must be used with GPUDirect RDMA, continue to use
cudaMallocfor now because memory allocated throughcudaMallocAsynccurrently does not support it. CUDA aims to support this in the future. - Unlike memory allocated with
cudaMalloc, memory allocated withcudaMallocAsyncis not associated with a CUDA context. This has the following implications:- Calling
cuPointerGetAttributewith the attributeCU_POINTER_ATTRIBUTE_CONTEXTreturns null for the context. - When calling
cudaMemcpywith at least one of source or destination pointers allocated usingcudaMallocAsync, that memory must be accessible from the calling thread’s current context/device. If it’s not accessible from that context or device, usecudaMemcpyPeerinstead.
- Calling
Guidelines for replacing cudaFree with cudaFreeAsync:
- Ensure that all memory accesses are ordered before the stream-ordered deallocation.
- The memory may not be freed back to the system until the next synchronization operation. If the release threshold is set to a nonzero value, the memory may not be freed back to the system until the corresponding pool is explicitly trimmed.
- Unlike
cudaFree,cudaFreeAsyncdoes not implicitly synchronize the device. Any code relying on this implicit synchronization must be updated to synchronize explicitly.
Conclusion
The stream-ordered allocator and cudaMallocAsync and cudaFreeAsync API functions added in CUDA 11.2 extend the CUDA stream programming model by introducing memory allocation and deallocation as stream-ordered operations. This enables allocations to be scoped to the kernels, which use them while avoiding costly device-wide synchronization that can occur with traditional cudaMalloc/cudaFree.
Furthermore, these API functions add the concept of memory pools to CUDA, enabling the reuse of memory to avoid costly system calls and improve performance. Use the guidelines to migrate your existing code and see how much your application performance improves!








 The NVIDIA, Facebook, and TensorFlow recommender teams will be hosting a summit with live Q&A to dive into best practices and insights on how to develop and optimize deep learning recommender systems.
The NVIDIA, Facebook, and TensorFlow recommender teams will be hosting a summit with live Q&A to dive into best practices and insights on how to develop and optimize deep learning recommender systems. Connected cars are vehicles that communicate with other vehicles using backend systems to enhance usability, enable convenient services, and keep distributed software maintained and up to date. At Volkswagen, we are working on connected car with NVIDIA to solve the challenges which have computational inefficiencies like Geospatial Indexing and K-Nearest Neighbors when implemented in native …
Connected cars are vehicles that communicate with other vehicles using backend systems to enhance usability, enable convenient services, and keep distributed software maintained and up to date. At Volkswagen, we are working on connected car with NVIDIA to solve the challenges which have computational inefficiencies like Geospatial Indexing and K-Nearest Neighbors when implemented in native … 
 King’s College London, along with partner hospitals and university collaborators, unveiled new details today about one of the first projects on Cambridge-1, the United Kingdom’s most powerful supercomputer. The Synthetic Brain Project is focused on building deep learning models that can synthesize artificial 3D MRI images of human brains. These models can help scientists understand …
King’s College London, along with partner hospitals and university collaborators, unveiled new details today about one of the first projects on Cambridge-1, the United Kingdom’s most powerful supercomputer. The Synthetic Brain Project is focused on building deep learning models that can synthesize artificial 3D MRI images of human brains. These models can help scientists understand …