NVIDIA technology has been behind some of the world’s most stunning virtual reality experiences. Each new generation of GPUs has raised the bar for VR environments, producing interactive experiences with photorealistic details to bring new levels of productivity, collaboration and fun. And with each GTC, we’ve introduced new technologies and software development kits that help Read article >
Developers can use cuQuantum to speed up quantum circuit simulations based on state vector, density matrix, and tensor network methods by orders of magnitude.
Quantum computing has the potential to offer giant leaps in computational capabilities. Until it becomes a reality, scientists, developers, and researchers are simulating quantum circuits on classical computers.
NVIDIA cuQuantum is an SDK of optimized libraries and tools for accelerating quantum computing workflows. Developers can use cuQuantum to speed up quantum circuit simulations based on state vector, density matrix, and tensor network methods by orders of magnitude.
The research community – including academia, laboratories, and private industry – are all using simulators to help design and verify algorithms to run on quantum computers. These simulators capture the properties of superposition and entanglement and are built on quantum circuit simulation frameworks including Qiskit, Cirq, ProjectQ, Q#, etc.
We showcase accelerated quantum circuit simulation results based on industry estimations, extrapolations, and benchmarks on real-world computers like ORNL’s Summit, and NVIDIA’s Selene, and reference collaborations with numerous industry partners.
“Using the Cotengra/Quimb packages, NVIDIA’s new cuQUANTUM SDK, and the Selene supercomputer, we’ve generated a sample of the Sycamore quantum circuit at depth=20 in record time (less than 10 minutes). This sets the benchmark for quantum circuit simulation performance and will help advance the field of quantum computing by improving our ability to verify the behavior of quantum circuits.”
Johnnie Gray, Research Scientist, Caltech Garnet Chan, Bren Professor of Chemistry, Caltech
Learn more about cuQuantum, our latest benchmark results, and apply for early interest today here.
How to replace the code snippet with TensorFlow 1.14.1 feature_columns = [tf. contrib. layers. real_value_column ( “” , dimension = 98)] in TensorFlow 2.4.1?
OptiX 7.3 brings temporal denoising and improvements to OptiX Curves primitives and new features to the OptiX Demand Loading library
OptiX 7.3 brings temporal denoising and improvements to OptiX Curves primitives and new features to the OptiX Demand Loading library
NVIDIA Optix Ray Tracing Engine is a scalable and seamless framework that offers optimal ray tracing performance on GPUs. In this spring’s update to the OptiX SDK, developers will be able to leverage temporal denoising, faster curve intersectors, and fully asynchronous demand loading library.
Smoother Denoising for Moving Sequences
The OptiX denoiser comes with a brand new denoising mode called temporal denoising, which is engineered to denoise multi-frame animation sequences without getting any of the low-frequency denoiser artifacts in the animation that you get when you denoise animated frames separately. The results are impressively smooth, and this update will be a boon to users of the OptiX denoiser who want to remove noise from moving sequences. This has been one of our most requested features and now it’s here. This release of the OptiX denoiser comes with yet another performance increase as well, and the recent AOV (layered) denoising and brand new temporal denoising are fast enough on the current generation of NVIDIA GPUs to be used in real time for interactive applications, with plenty of room to spare for rendering.
left: Denoising each frame separately; right: Temporal Denoising
Improved Curves For Better Ray Tracing Performance
OptiX 7.3 comes with a round of updates to the curve primitive intersectors. Our new cubic and quadratic curve intersectors are 20% to 80% faster with this release, and even the already very fast linear intersector (up to 2x faster than cubic) has improved in performance a bit as well. All the intersectors now support backface culling by default, which makes it easier for developers to support shadows, transparency, and other lighting effects that depend on reflected and transmitted secondary rays from hair and curves. The best kept secret so far about OptiX curves is how fast they are with OptiX motion blur on the new generation of Ampere GPUs. With Ampere’s new hardware acceleration of motion blur, we’re seeing performance increases on motion blurred hair up to 3x faster than motion blurred hair on Turing cards.
Image courtesy Koke Nunez. Rendered in Otoy Octane.
Faster Object Loading Without Extra GPU Resources
The demand loading library, included with the OptiX 7.3 download, has also received updates. It is now fully asynchronous, with sparse texture tiles loaded in the background by multiple CPU threads in parallel with OptiX kernels executing on the GPU. Support has also been added for multiple streams, which allows for the hiding of texture I/O latency and an easier implementation of bucketed rendering approach. This increased parallelism, in conjunction with additional performance updates present in the OptiX 7.3 SDK should offer a compelling reward for adding demand loading in your projects. A new sample has been added and the existing associated samples have been updated to give you a great place to start.
Image courtesy Daniel Bates. Rendered in Chaos V-Ray
The Omniverse platform provides researchers, developers, and engineers with the ability to virtually collaborate and work between different software applications. Omniverse Kaolin is an interactive application that acts as a companion to the NVIDIA Kaolin library, helping 3D deep learning researchers accelerate their process.
The Kaolin app leverages the Omniverse platform, USD format and RTX rendering to provide interactive tools that allow visualizing 3D outputs of any deep learning model as it is training, inspecting 3D datasets to find inconsistencies and gain intuition, and rendering large synthetic datasets from collections of 3D data.
Omniverse Kaolin enables users to reduce the time needed to develop AI research for a wide range of 3D applications.
TRAINING VISUALIZER
The Omniverse Kaolin Training Visualizer extension allows interactive visualization of 3D checkpoints exported using Kaolin Library python API. By scrubbing through iterations, researchers can see the progression of training over time, and visualize multiple textures and labels that may be predicted for each 3D model.
The 3D checkpoints can include meshes, point clouds and voxel grids in any number of categories, with multiple textures and labels supported for meshes. The extension also allows creating and saving custom layouts for visualizing results consistently across experiments.
DATASET VISUALIZER
The performance of machine learning models can depend heavily on the properties of the training data. The Omniverse Kaolin Dataset Visualizer extension allows sampling and visualizing batches from 3D datasets to gain intuition and identify problems that can hinder learning.
DATA GENERATOR
Many machine learning techniques rely on images and ground truth labels for training, and synthetic data is a powerful tool to support such applications. The Omniverse Kaolin Data Generator extension uses NVIDIA RTX ray and path tracing to render massive image datasets from a collection of 3D data, while also exporting custom ground truth labels from a variety of sensors.
AI machine learning is unlocking breakthrough applications in fields such as online product recommendations, image classification, chatbots, forecasting, and manufacturing quality inspection. There are two parts to AI: training and inference. Inference is the production phase of AI. The trained model and associated code are deployed in the data center or public cloud, or at … Continued
AI machine learning is unlocking breakthrough applications in fields such as online product recommendations, image classification, chatbots, forecasting, and manufacturing quality inspection. There are two parts to AI: training and inference.
Inference is the production phase of AI. The trained model and associated code are deployed in the data center or public cloud, or at the edge to make predictions. This process is called inference serving and is complex for the following reasons:
Multiple model frameworks: Data scientists and researchers use different AI and deep learning frameworks like TensorFlow, PyTorch, TensorRT, ONNX Runtime, or just plain Python to build models. Each of these frameworks requires an execution backend to run the model in production.
Different inference query types: Inference serving requires handling different types of inference queries like real time online predictions, offline batch, streaming data, and a complex pipeline of multiple models. Each of these requires special processing for inference.
Constantly evolving models: Models are continuously retrained and updated based on new data and new algorithms. So, the models in production need to be updated continuously without restarting the server or any downtime. A given application can use many different models and it compounds the scale.
Diverse CPUs and GPUs: The models can be executed on a CPU or GPU and there are different types of GPUs and CPUs.
Often, organizations end up having multiple, disparate inference serving solutions, per model, per framework, or per application.
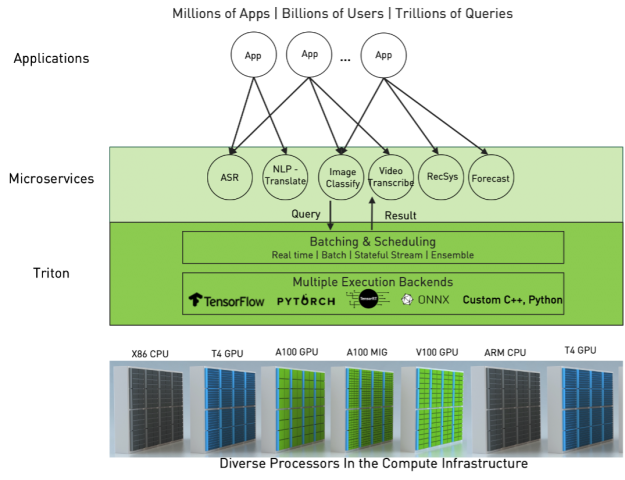
NVIDIA Triton Inference Server is an open-source inference serving software that simplifies inference serving for an organization by addressing the above complexities. Triton provides a single standardized inference platform which can support running inference on multi-framework models, on both CPU and GPU, and in different deployment environments such as datacenter, cloud, embedded devices, and virtualized environments.
It natively supports multiple framework backends like TensorFlow, PyTorch, ONNX Runtime, Python, and even custom backends. It supports different types of inference queries through advanced batching and scheduling algorithms, supports live model updates, and runs models on both CPUs and GPUs. Triton is also designed to increase inference performance by maximizing hardware utilization through concurrent model execution and dynamic batching. Concurrent execution allows you to run multiple copies of a model, and multiple different models, in parallel on the same GPU. Through dynamic batching, Triton can dynamically group together inference requests on the server-side to maximize performance.
Figure 1. Triton Inference Server architecture.
Automatic model conversion and deployment
To further simplify the process of deploying models in production, the 2.9 release introduces a new suite of capabilities. A trained model is generally not optimized for deployment in production. You must go through a series of conversion and optimizations for your specific target environment. The following process shows a TensorRT deployment using Triton on a GPU. This applies to any inference framework, whether it’s deployed on CPU or GPU.
Convert models from different frameworks (TensorFlow, PyTorch) to TensorRT to get the best performance.
Check for optimizations, such as precision.
Generate the optimized model.
Validate the accuracy of the model post-conversion.
Manually test different model configurations to find the one that maximizes performance, such as batch size, number of concurrent model instances per GPU.
Prepare model configuration and repository for Triton.
(Optional) Prepare a Helm chart for deploying Triton on Kubernetes.
As you can see, this process can take significant time and effort.
You can use the new Model Navigator in Triton to automate the process. Available as an alpha version, it can convert an input model from any framework (TensorFlow and PyTorch are supported in this release) to TensorRT, validate the conversion for correctness, automatically find and create the most optimal model configuration, and generate the repo structure for the model deployment. What could take days for each type of model now can be done in hours.
Optimizing model performance
For efficient inference serving, you must identify the optimal model configurations, such as the batch size and number of concurrent models. Today, you must try different combinations manually to eventually find the optimal configuration for your throughput, latency, and memory utilization requirements.
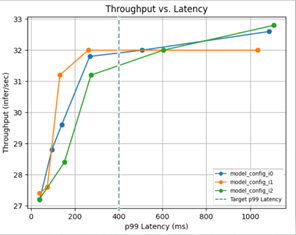
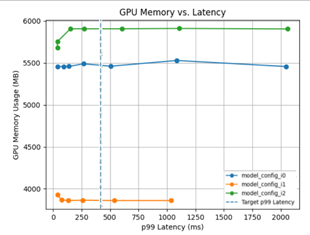
Triton Model Analyzer is another optimization tool that automates this selection for you by automatically finding the best configuration for models to get the highest performance. You can specify performance requirements, such as a latency constraint, throughput target, or memory footprint. The model analyzer searches through different model configurations and finds the one that provides the best performance under your constraints. To help visualize the performance of the top configurations, it then outputs a summary report, which includes charts (Figure 2).
Figure 2. Choosing optimal configuration with Triton Model Analyzer.
You do not have to settle for a less optimized inference service because of the inherent complexity in getting to an optimized model. You can use Triton to easily get to the most efficient inference.
Triton giant model inference
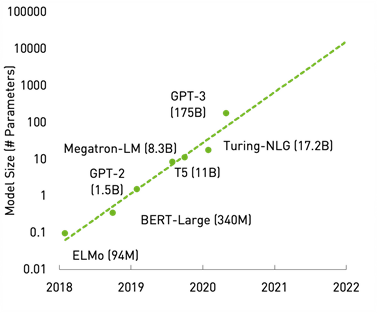
Models are rapidly growing especially in areas of natural language processing. For example, consider the GPT-3 model. Its full capabilities are still being explored. It has been shown to be effective in use cases such as reading comprehension and summarization of text, Q&A, human-like chatbots, and software code generation.
In this post, we don’t delve into the models. Instead, we look at the cost-effective inference of such giant models. GPUs are naturally the right compute resource for these workloads, but these models are so large that they cannot fit on a single GPU. For more information about a framework to train giant models on multi-GPU, multi-node systems, see Scaling Language Model Training to a Trillion Parameters Using Megatron.
Figure 3. Exponential growth in the size of language models.
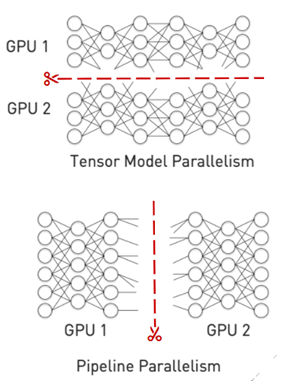
For inference, you must split the model into multiple smaller files and load each on a separate GPU. There are generally two approaches to splitting a model:
Pipeline parallelism splits the model vertically across layer boundaries and runs these layers across multiple GPUs in a pipeline.
Tensor parallelism cuts the network horizontally and splits individual layers across GPUs.
The Triton custom backend feature can be used to run multi-GPU, multi-node backends. In addition, Triton has a model ensemble feature that can be used for pipeline parallelism.
Figure 4. Tensor model and pipeline parallelism.
Giant models are still in their infancy, but it won’t be long until you see production AI running multiple giant models for different use cases.
Ecosystem integrations
Inference serving is a production activity and can require integration with many ecosystem software and tools. Triton integrates with several, with new integrations added regularly.
Framework backends: Triton supports all the major deep learning framework execution backends out of the box, like TensorFlow, PyTorch, and ONNX RT. It allows custom backends in C++ and Python to be integrated easily. As part of the 21.03 release, a beta version of the OpenVINO backend in Triton is available for high performance CPU inferencing on the Intel platform.
Kubernetes ecosystem: Triton is designed for scale. It integrates with major Kubernetes platforms on the cloud like AKS, EKS, and GKE and on-premises implementations including Red Hat OpenShift. It is also part of the Kubeflow project.
Cloud AI platforms and MLOPs software: MLOps is a process that brings automation and governance to AI development and deployment workflow. Triton is integrated in cloud AI platforms such as Azure ML and can be deployed in Google CAIP and Amazon SageMaker as a custom container. It is also integrated with KFServing, Seldon Core, and Allegro ClearML.
Customer case studies
Triton is used by both large and small customers to serve models in production for all types of applications, such as computer vision, natural language processing, and recommender systems. Here are a few examples across different use cases:
Volkswagen Smart Lab: Integrates Triton into its Volkswagen Computer Vision Workbench so users can make contributions to the Model Zoo without needing to worry about whether they are based on ONNX, PyTorch, or TensorFlow frameworks. Triton simplifies model management and deployment, and that’s key for VW’s work serving up AI models in new and interesting environments, Bormann says in his GTC session, Taming the Computer Vision Zoo with NVIDIA Triton for an easy scalable eco system.
Natural language processing
Salesforce: Uses Triton to develop state-of-the-art transformer models. For more information, see the Benchmarking Triton Inference Server GTC 21 session.
LivePerson: Uses Triton as a standardized platform to serve NLP models from different frameworks on both CPUs and GPUs for chatbot applications.
Ant Group: Uses Triton as a standardized platform to serve models for different applications, such as AntChain, copyright management platform, fraud detection, and more.
Figure 5. Triton for standardized AI deployment across the data center.
Conclusion
Triton helps with a standardized scalable production AI in every data center, cloud, and embedded device. It supports multiple frameworks, runs models on both CPUs and GPUs, handles different types of inference queries, and integrates with Kubernetes and MLOPs platforms.
This DevKit targets heterogeneous GPU/CPU system development, and includes an Arm CPU, an NVIDIA A100 Tensor Core GPU, and the NVIDIA HPC SDK suite of tools.
NVIDIA announced the NVIDIA Arm HPC Developer Kit, an integrated hardware-software platform for creating, evaluating, and benchmarking HPC, AI and scientific computing applications. Developers can apply today for the early interest program.
This DevKit targets heterogeneous GPU/CPU system development, and includes an Arm CPU, an NVIDIA A100 Tensor Core GPU, and the NVIDIA HPC SDK suite of tools.
It delivers:
A validated system for quick and easy bring-up in a stable environment for accelerated computing code execution and evaluation, performance analysis, system experimentation, and system characterization.
A stable hardware and software platform for development and performance analysis of accelerated HPC, AI, and scientific computing applications
Experimentation and characterization of high-performance, NVIDIA-accelerated, Arm server-based system architectures
The NVIDIA Arm HPC Developer Kit is based on the GIGABYTE G242-P32 2U server, and leverages the NVIDIA HPC SDK, a comprehensive suite of compilers, libraries, and tools for HPC delivering performance, portability, and productivity. The platform will support Ubuntu, SLES, and RHEL operating systems.
Developers are invited to apply for our early interest program to stay informed of pricing and availability. Learn more and apply now.
The NVIDIA CloudXR platform will be available on NVIDIA GPU-powered virtual machine instances on Azure.
NVIDIA is raising the bar for XR streaming. Announced today, the NVIDIA CloudXR platform will be available on NVIDIA GPU-powered virtual machine instances on Azure.
NVIDIA CloudXR is built on NVIDIA RTX GPUs to enable streaming of immersive AR, VR or mixed reality experiences from anywhere. By streaming from the cloud, enterprises can easily set up and scale immersive experiences from any location, to any VR or AR device. Companies and customers no longer need to purchase expensive high-performing workstations to experience high-quality, immersive environments.
Delivering High-Fidelity Experiences from the Cloud
NVIDIA partners Innoactive, TechViz, and Vection Technologies are among the first to use CloudXR on Azure instances.
With NVIDIA CloudXR, customers of Vection Technologies can access the Mindesk platform from anywhere, using standalone AR or VR headsets like the HTC Vive Focus. Enterprises can now easily share their 3D CAD, CAM, and BIM environments among colleagues and customers in real time. And since most of the computation happens in the cloud, any business can take advantage of the capabilities of CloudXR without spending money on expensive computational powerhouses.
“One of the greatest obstacles to the adoption of AR and VR was the necessity for a dedicated GPU. And even when that is available, it is not enough for more complex and dynamic content like CAD, CAM, BIM and simulations,” said Gabriele Sorrento, director of Vection Technologies. “NVIDIA CloudXR solves both problems. By decoupling the app from the workstation, CloudXR makes complex AR and VR data available anywhere.”
Vection Technologies plans to ship the Mindesk Suite with NVIDIA CloudXR.
Another early user of CloudXR on Azure is Innoactive, a company that provides a platform to deploy VR training at scale in large organizations. Working with companies such as SAP, Innoactive uses NVIDIA CloudXR and Azure to enhance VR training while keeping content secure and easily accessible from the cloud.
“SAP customers have large and complex CAD models which they want to use in their VR process simulations and training applications,” said Michael Spiess, venture lead for extended reality at SAP. “With CloudXR, we can easily stream those VR simulations with the highest quality visuals to any device — whether it’s an HMD, a tablet, or even a smartphone. Innoactive Portal supports NVIDIA CloudXR and makes all this available with a click of a button. This will help us to offer XR Cloud services to our 200 million business users.”
Users can try CloudXR on Azure today by downloading the Innoactive Portal app, and experience XR streaming from the cloud with their own VR headset.
CloudXR Sets the Stage for Advanced AR and VR
The CloudXR platform includes:
NVIDIA CloudXR SDK, which supports all OpenVR apps and includes broad client support for phones, tablets and head-mounted displays.
NVIDIA RTX Virtual Workstations to provide high quality graphics at the fastest frame rates.
NVIDIA AI SDKs to accelerate performance and increase immersive presence.
With CloudXR running on GPU-powered VM instances on Azure, companies can provide users with high-quality virtual experiences from anywhere in the world.
Availability Coming Soon
NVIDIA CloudXR on Azure will be generally available later this year, with a private beta available soon. Apply now for early access to the SDK, and sign up to get the latest news and updates on upcoming CloudXR releases, including the private beta.
The latest versions of Nsight Systems 2021.2 and, Nsight Compute 2021.1 are now available with new features for GPU profiling and performance optimization.
Today we announced the latest versions of Nsight Systems 2021.2 and, Nsight Compute 2021.1 – now available with new features for GPU profiling and performance optimization.
We also announced the Nsight Visual Studio Code Edition, NVIDIA’s new addition to the series of world class developer tools for CUDA programming and debugging.
Nsight Systems 2021.2
Nsight Systems 2021.2, introduces support for GPU metrics sampling and tracing of CUDA Unified Memory page faults on the CPU and GPU. There’s also support for Reflex SDK, CUDA 11.3, and additional enhancements in network trace, including: NCCL, NVSHMEM, OpenSHMEM, and MPI fortran.
The GPU metrics sampling feature allows you to view and analyze low level utilization details on a timeline. These provide a system wide overview of efficiency for your GPU workloads. They include metrics on IO activity including throughput for PCIe, NVLink, and DRAM. They also show SM utilization, TensorCore activity, instructions issued, warp occupancy and unallocated warps.
This expands Nsight Systems ability to profile system-wide activity and help track GPU workloads and their CPU origins. By providing a deeper understanding of the GPU utilization over multiple processes and contexts; covering the interop of Graphics and Compute workloads including CUDA, OptiX, DirectX and Vulkan ray tracing + rasterization APIs.
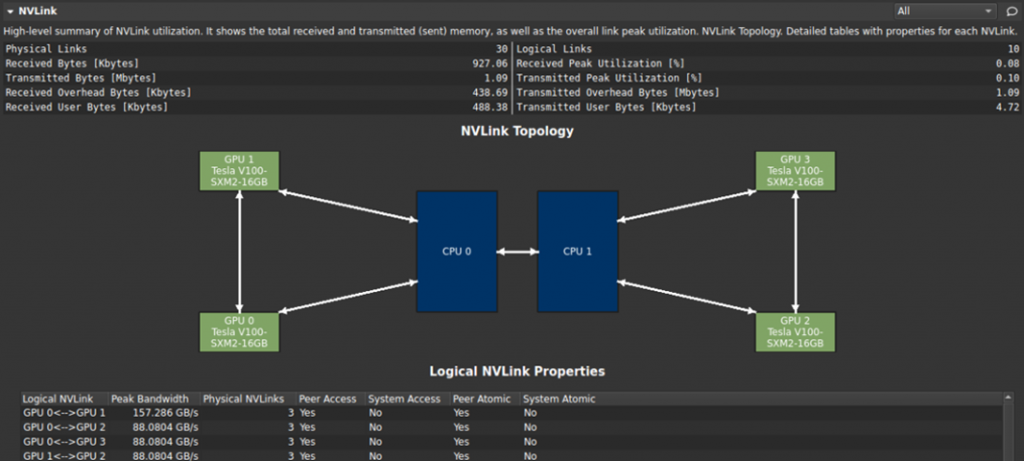
Nsight Compute 2021.1 is available now and adds a new NVLink topology and properties section to help users understand the hardware layout of their platform and how it may be impacting performance.
Figure 2. NVLInk Topology and Properties Section
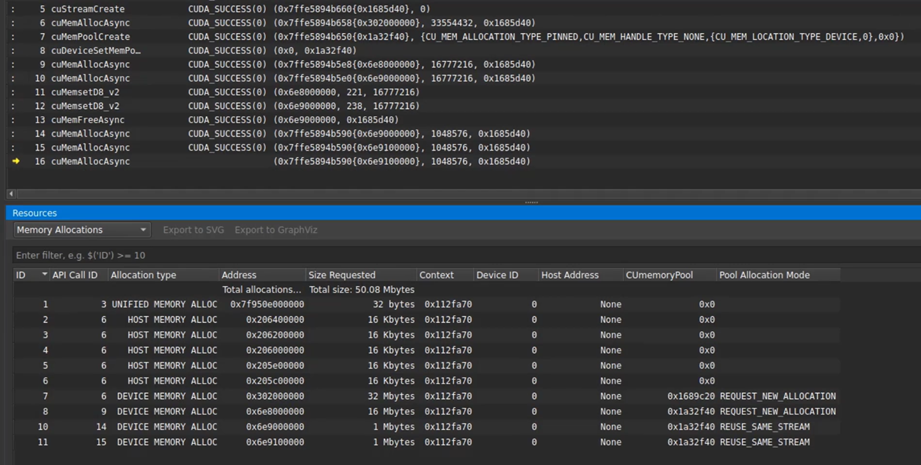
This new version also adds OptiX 7 API stepping, MacOS 11 Big Sur host support, and improved resource tracking capabilities for user objects, stream capture, and asynchronous suballocations.
Figure 3. CUDA asynchronous allocation tracking
These new features give the user increased visibility into the dynamic performance behavior of their workloads and how they are using hardware and software resources.
Nsight Visual Studio Code Edition provides syntax highlighting, CUDA debugging, Problems tab integration for nvcc, and Intellisense features for kernel functions including auto-completion, go to definition, and find all references.

 Developers can use cuQuantum to speed up quantum circuit simulations based on state vector, density matrix, and tensor network methods by orders of magnitude.
Developers can use cuQuantum to speed up quantum circuit simulations based on state vector, density matrix, and tensor network methods by orders of magnitude.  OptiX 7.3 brings temporal denoising and improvements to OptiX Curves primitives and new features to the OptiX Demand Loading library
OptiX 7.3 brings temporal denoising and improvements to OptiX Curves primitives and new features to the OptiX Demand Loading library

 3D deep learning researchers can enter NVIDIA Omniverse and simplify their workflows with the Omniverse Kaolin app, now available in open beta.
3D deep learning researchers can enter NVIDIA Omniverse and simplify their workflows with the Omniverse Kaolin app, now available in open beta. AI machine learning is unlocking breakthrough applications in fields such as online product recommendations, image classification, chatbots, forecasting, and manufacturing quality inspection. There are two parts to AI: training and inference. Inference is the production phase of AI. The trained model and associated code are deployed in the data center or public cloud, or at …
AI machine learning is unlocking breakthrough applications in fields such as online product recommendations, image classification, chatbots, forecasting, and manufacturing quality inspection. There are two parts to AI: training and inference. Inference is the production phase of AI. The trained model and associated code are deployed in the data center or public cloud, or at … 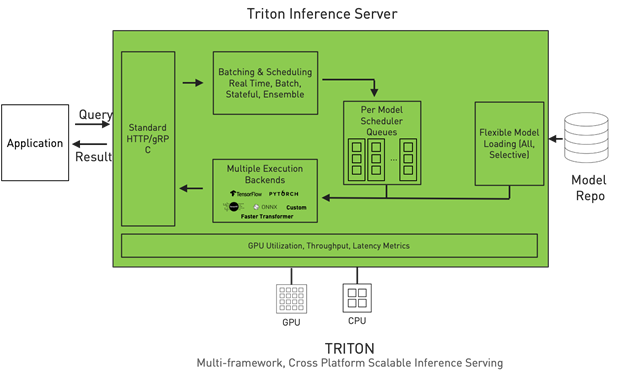
 This DevKit targets heterogeneous GPU/CPU system development, and includes an Arm CPU, an NVIDIA A100 Tensor Core GPU, and the NVIDIA HPC SDK suite of tools.
This DevKit targets heterogeneous GPU/CPU system development, and includes an Arm CPU, an NVIDIA A100 Tensor Core GPU, and the NVIDIA HPC SDK suite of tools.  The NVIDIA CloudXR platform will be available on NVIDIA GPU-powered virtual machine instances on Azure.
The NVIDIA CloudXR platform will be available on NVIDIA GPU-powered virtual machine instances on Azure.
 The latest versions of Nsight Systems 2021.2 and, Nsight Compute 2021.1 are now available with new features for GPU profiling and performance optimization.
The latest versions of Nsight Systems 2021.2 and, Nsight Compute 2021.1 are now available with new features for GPU profiling and performance optimization.