Learn how to free your Jetson GPU for additional tasks by deploying neural network models on the NVIDIA Jetson Orin Deep Learning Accelerator (DLA).
If you’re an active Jetson developer, you know that one of the key benefits of NVIDIA Jetson is that it combines a CPU and GPU into a single module, giving you the expansive NVIDIA software stack in a small, low-power package that can be deployed at the edge.
Jetson also features a variety of other processors, including hardware accelerated encoders and decoders, an image signal processor, and the Deep Learning Accelerator (DLA).
The DLA is available on Jetson AGX Xavier, Xavier NX, Jetson AGX Orin and Jetson Orin NX modules. The recent NVIDIA DRIVE Xavier and Orin-based platforms also have DLA cores.
If you use the GPU for deep learning execution, read on to learn more about DLA, why it’s useful, and how to use it.
Overview of the Deep Learning Accelerator
The DLA is an application-specific integrated circuit that is capable of efficiently performing fixed operations, like convolutions and pooling, that are common in modern neural network architectures. Though the DLA doesn’t have as many supported layers as the GPU, it still supports a wide variety of layers used in many popular neural network architectures.
In many instances, the layer support may cover the requirements of your model. For example, the NVIDIA TAO Toolkit includes a wide variety of pre-trained models that are supported by the DLA, ranging from object detection to action recognition.
While it’s important to note that the DLA throughput is typically lower than that of the GPU, it is power-efficient and allows you to offload deep learning workloads, freeing the GPU for other tasks. Alternatively, depending on your application, you can run the same model on the GPU and DLA simultaneously to achieve higher net throughput.
Many NVIDIA Jetson developers are already using the DLA to successfully optimize their applications. Postmates optimized their delivery robot application on Jetson AGX Xavier leveraging the DLA along with the GPU. The Cainiao ET Lab used the DLA to optimize their logistics vehicle. If you’re looking to fully optimize your application, the DLA is an important piece in the Jetson repertoire to consider.
How to use the Deep Learning Accelerator
Figure 1. A coarse architecture diagram highlighting the Deep Learning Accelerators on Jetson Orin
To use the DLA, you first need to train your model with a deep learning framework like PyTorch or TensorFlow. Next, you need to import and optimize your model with NVIDIA TensorRT. TensorRT is responsible for generating the DLA engines, and can also be used as a runtime for executing them. Finally, you should profile your mode and make optimizations where possible to maximize DLA compatibility.
Get started with the Deep Learning Accelerator
Ready to dive in? The Jetson_dla_tutorial GitHub project demonstrates a basic DLA workflow to help you in your journey toward optimizing your application for Jetson.
With the tutorial, you can learn how to define the model in PyTorch, import the model with TensorRT, analyze the performance using the NVIDIA Nsight System profiler, modify the model for better DLA compatibility, and calibrate for INT8 execution. Note that the CIFAR10 dataset is used as a toy example to facilitate reproducing the steps.
Just as GPUs and DPUs enable accelerated computing today, they’re also helping a new kind of chip, the QPU, boot up the promise of quantum computing. In your hand, a quantum processing unit might look and feel very similar to a graphics or a data processing unit. They’re all typically chips, or modules with multiple Read article >
Data lakes can ingest a wide range of data types for big data and AI repositories. Data warehouses use structured data, mainly from business applications, with a focus on data transformation.
Data is the lifeblood of modern enterprises, whether you’re a retailer, financial service company, or digital advertiser. Across industries, organizations are recognizing the importance of their data for business analytics, machine learning, and AI.
Smart businesses are investing in new ways to extract value from their data: to better understand customer needs and behaviors, tailor new products and services, and make strategic decisions that will deliver competitive advantages in the years to come.
For decades, enterprise data warehouses have been used for all types of business analytics, with a robust ecosystem around SQL and relational databases. Now, a challenger has emerged.
Data lakes were created to store big data for training AI models and predictive analytics. This post covers the pros and cons of each repository: how they are used and, ultimately, which delivers the best outcomes for ML projects.
Key to this puzzle is processing data for AI and ML workflows. AI projects require massive amounts of data for training models and running predictive analytics. Technical teams must evaluate how to capture, process, and store data so that it is scalable, affordable, and readily available.
What’s a data warehouse?
Data warehouses were created in the 1980s to help enterprise companies organize high data volumes for the purpose of making better business decisions. Data warehouses are used with legacy sources such as enterprise resources planning (ERP), customer relationship management (CRM) software, inventory, and point of sale systems.
The primary goal is to provide operational reporting across lines of business, product analytics, and business intelligence.
Data warehouses have used ETL (extract, transform, load) for decades, with a bias for completing transform and clean data before uploading it. Traditional data warehouses have stringent standards for data structure and advance planning to meet schema requirements.
Data is only stored in data warehouses when it has already been processed and refined. ETL processes data by first cleaning data and then uploading into a relational database. The upside is that the data is in good shape and can be used. However, there is processing overhead that you pay up front, which is lost if the data is never used.
Data analysts must create a predetermined data structure and fixed schema before they can run their queries. This blocker is a huge pain point for data scientists, analysts, and other lines of business, as it takes months or longer to be able to run new queries.
Typically, the data in a warehouse is read-only, so it can be difficult to add, update, or delete data files.
Upside: Data quality
With any system, there are tradeoffs. The upside of data warehouses is their data is in good shape at ingest and will likely stay that way due to the discipline of data cleansing and data governance.
Traditional data warehouses excel as ledgers, providing clean, structured, and normalized data that serves as a single source of truth for an organization. Using relational databases, managers and business analysts across the organization can query massive amounts of corporate data quickly and accurately, to guide critical business strategies.
Downside: Schema requirement
Data warehouses are more likely to use ETL for operational analytics and machine learning workloads.
However, traditional data warehouses require a fixed schema for structuring the data, which could take months or years to agree across all teams and lines of business managers. By the time a schema gets implemented, its users have new queries, taking them back to square one.
It’s fair to say that data warehouse schema drove immense interest in data lakes.
Why use a data lake?
In the early 2000s, Apache Hadoop introduced a new paradigm for storing data in distributed file systems (HDFS) so enterprises could more easily mine their data for competitive advantage. The idea of a data lake came from Hadoop, enabling ingest of a wide spectrum of data types stored in low-cost blob or object storage.
Over the last decade, organizations have flocked to data lakes to capture diverse data types from the web, social media, sensors, Internet of Things, weather data, purchased lists, and so on. As big data gets bigger, data lakes became popular to store petabytes of raw data using elastic technologies.
Data lakes have two main draws: the easy ingest of a wide spectrum of data types and ready access to that data for improvised queries.
Using ELT (extract, load, transform), data lakes can ingest most any data type: structured, unstructured, semistructured, and binary for images and video.
Data going into a data lake does not have to be transformed before it is stored. Ingest is efficient, without the overhead of cleansing and normalizing data by type.
Data lakes make it easy to store all types of data (PDFs, audio, JSON documents) without knowing how that data might be used in the future.
Upside: Ad hoc queries
The upside of data lakes is that teams can access diverse data and run arbitrary queries on demand. The need to have data analytics available immediately is the main driver for adoption of data lakes.
Downside: Data degradation over time
Raw data goes bad fast in a data lake. There are few tools to tame raw data, making it hard to do merges, deduplication, and data continuity.
What do data warehouses and data lakes have in common?
Data warehouses and data lakes both function as large data repositories and have common characteristics and drawbacks, especially around cost and complexity.
Scale: Both have the capability to retain massive amounts of data, using both batch and streaming.
High costs: Both are wildly expensive, costing more than a million dollars a year to maintain.
Complexity: Data centers are managing dozens of unique data sources, with rapid volume growth of 50% a year or more. Storage infrastructure is taking more IT person hours, raising storage costs and driving down overall efficiency.
Data processing: Both can use ETL and ELT processing.
Shared use cases: As data scientists prioritize ML techniques to derive new insights from their data, many organizations are now getting the best of both worlds: AI-enabled data analytics and a wide range of diverse data types.
What’s the difference between data warehouses and data lakes?
Comparing data warehouses to data lakes is a bit like comparing apples and oranges. They offer different things.
A data warehouse organizes, cleans, and stores data for analysis.
A data lake stores many data types and transforms them on demand.
As teams become more focused on AI projects, the gaps in functionality, manageability, and data quality issues come to light, causing both approaches to evolve and improve.
Deployment
Data warehouses are more likely to be on-premises or in a hybrid cloud. Data lakes are more likely to be cloud-based to take advantage of more affordable storage options.
Data processing
Data warehouses are more likely to use ETL for operational analytics and machine learning workloads. Data lakes ingest data using ELT pipelines of raw data in case that it’s needed in the future. Data lakes also do not require a schema, so teams can pose improvised queries without significant delay.
Tools
Data lakes lack the robustness of a data warehouse, in terms of a functioning programming model and mature, enterprise-ready software and tools. Data lakes have a myriad of pain points, including no support for transactions, atomicity, or data governance.
Data quality
It’s always a problem. It’s a bigger problem for data lakes. Expect to do a lot of monitoring and maintenance on data in a data lake. If you can’t manage raw data efficiently, you can end up with a data swamp, where performance is poor and storage costs are out of control.
Roughly 85% of data lakes fail, Gartner estimates, due to low-quality data. As the adage says: Data pipelines are only as good as the data that flows through them.
Buy compared to build
Companies like Teradata, Oracle, and IBM can sell you a data warehouse for millions of dollars. Storage is one of the most expensive components, as average companies are seeing data volumes growing more than 50% a year.
To get a data lake, most companies build their own on a free PaaS using open source Apache Spark, Kafka, or Zookeeper. This does not mean that building and maintaining a data lake is less expensive, however.
By one estimate, it can cost upwards of a million dollars each year to hire the people for deploying a production data lake with cloud storage. Standing up a data lake can take 6 months to a year, if you can get the expertise.
What’s best for ML workloads?
The short answer is both. Most companies will use both a data warehouse and a data lake for AI projects. Here’s why.
Data lakes are popular because they can scale up for big data—petabytes or exabytes—without breaking the bank. However, data lakes do not offer an end-to-end solution for ML workloads, due to constraints in its programming model.
Many organizations adopted the Hadoop paradigm, only to find that it was nearly impossible to get highly skilled talent to extract data from a data lake using MapReduce. The introduction and development of Apache Spark has kept data lakes afloat, making it easier to access data.
Still, the Hadoop model has not fulfilled its promise for ML. Data lakes’ ongoing pain points include a lack of atomicity, poor performance, lack of semantic updates, and an evolving Spark engine for SQL.
Compare that to a data warehouse, which is compatible with an entire SQL ecosystem. Any software written for a SQL backend can access enterprise software. The methods range from a WYSIWYG frontend and drag-and-drop interfaces to automatically generated dashboards to fully automated ways to do Kube analysis and hyper Kubes, to name a few.
All the business intelligence and data analytics work of the last 30 years is inherited in SQL databases. None of it works on Hadoop or in data lakes.
More data warehouses are supporting ELT that’s commonly used by data lakes. A primary use case for data lakes is to ingest data into a data warehouse, so that data can be extracted and structured for ML projects. ELT enables data scientists to both define a way to structure data and to query it while keeping raw data as a source of truth.
The promise of a data lakehouse
For data engineers looking for a more robust data solution for their big data needs, a data lakehouse (a combination of a data lake and data warehouse) promises to address the drawbacks of data lakes.
A data lakehouse can offer data integrity and governance, support for transactions, and ongoing high performance, with help from an open-source framework called delta lake.
Hybrid cloud options
If you’re just starting with AI data architectures, companies like Amazon and Google are offering cloud-based data warehouses (Amazon Redshift, Google BigQuery) to help lower storage and deployment costs.
CoreDB is an open-source database service that functions as a data lake as a service under an Apache license.
Conclusion
Data warehouses and data lakes are both useful approaches to tame big data and make steps forward for advanced ML analytics. Data lakes are a recent approach to storing massive amounts in commercial clouds, such as Amazon S3 and Azure Blob.
The definitions of data warehouse and data lakes are evolving. Each approach is experimenting with new data processes and models for novel use cases. Going forward, techniques for optimizing performance will be critical, both for managing costs and for monitoring data hygiene in large repositories.
A data lake offers a more flexible solution for data analytics and can process and store data at a low price. However, the Hadoop data lake paradigm does not offer a fully functional solution for machine learning at scale today. Many organizations are forging new tactics and trying new tools to enable better functionality for both data warehouses and data lakes in the near future.
For more information, see the following resources:
A record number of interns calls for a record-sized celebration. In our largest contingent ever, over 1,650 interns from 350+ schools started with NVIDIA worldwide over the past year. Amidst busy work days tackling real-world projects across engineering, automation, robotics and more, the group’s also finishing up a three-day celebration, culminating today with National Intern Read article >
The TAO Toolkit lab on LaunchPad has everything you need to experience the end-to-end process of fine-tuning and deploying an object detection application.
Building AI Models from scratch is incredibly difficult, requiring mountains of data and an army of data scientists. With the NVIDIA TAO Toolkit, you can use the power of transfer learning to fine-tune NVIDIA pretrained models with your own data and optimize for inference—without AI expertise or large training datasets.
You can now experience the TAO Toolkit through NVIDIA LaunchPad, a free program that provides short-term access to a large catalog of hands-on labs.
LaunchPad helps developers, designers, and IT professionals speed up the creation and deployment of modern, data-intensive applications. LaunchPad is the best way to enjoy and experience the transformative power of the NVIDIA hardware and software stack working in unison to power your AI applications.
TAO Toolkit on LaunchPad
The TAO Toolkit lab on LaunchPad has everything you need to experience the end-to-end process of fine-tuning and deploying an object detection application.
Object detection is a popular computer vision task that involves classifying and putting bounding boxes around images or frames of videos. It can be used for real-world applications in retail (self check-out, for example), transportation, manufacturing, and more.
With the TAO Toolkit, you can also:
Achieve up to 4x in inference speed-up with built-in model optimization
Generalize your model with offline and online data augmentation
Scale up and out with multi-GPU and multi-node to speed-up your model training
Visualize and understand model training performance in TensorBoard
The TAO Toolkit lab is preconfigured with the datasets, GPU-optimized pretrained models, Jupyter notebooks, and the necessary SDKs for you to seamlessly accomplish your task.
Ready to get started? Apply now to access the free lab.
More than 160 years after the legendary Pony Express delivery service completed its first route, a new generation of “Pony”-emblazoned vehicles are taking an AI-powered approach to long-haul delivery. Autonomous driving company Pony.ai announced today a partnership with SANY Heavy Truck (SANY), China’s largest heavy equipment manufacturer, to jointly develop level 4 autonomous trucks. The Read article >
Palo Alto Networks and NVIDIA have developed an Intelligent Traffic Offload (ITO) solution to solve the scaling, efficiency, and economic challenges this creates.
Cyberattacks are gaining sophistication and are presenting an ever-growing challenge. This challenge is compounded by an increase in remote workforce connections driving growth in secure tunneled traffic at the edge and core, the expansion of traffic encryption mandates for the federal government and healthcare networks, and an increase in video traffic.
In addition, an increase in mobile and IoT traffic is being generated by the introduction of 5G speeds and the addition of billions of connected devices.
These trends are creating new security challenges that require a new direction in cybersecurity to maintain adequate protection. IT Departments—and firewalls—must inspect exponentially more data and take deeper looks inside traffic flows to address new threats. They must be able to check traffic between virtual machines and containers that run on the same host, traffic that traditional firewall appliances cannot see.
Operators must deploy enough firewalls capable of handling the total traffic throughput, but doing so without sacrificing performance can be extremely cost-prohibitive. This is because general-purpose processors (server CPUs) are not optimized for packet inspection and cannot handle the higher network speeds. This results in suboptimal performance, poor scalability, and increased consumption of expensive CPU cores.
Security applications such as next-generation firewalls (NGFW) are struggling to keep up with higher traffic loads. While software-defined NGFWs offer the flexibility and agility to place firewalls anywhere in modern data centers, scaling them for performance, efficiency, and economics is challenging for today’s enterprises.
Next-generation firewalls
To address these challenges, NVIDIA partnered with Palo Alto Networks to accelerate their VM-Series Next Generation Firewalls through the NVIDIA BlueField data processing unit (DPU). The DPU accelerates packet filtering and forwarding by offloading traffic from the host processor to dedicated accelerators and ARM cores on the BlueField DPU.
The solution delivers the intrusion prevention and advanced security capabilities of Palo Alto Networks’ virtual NGFWs to every server without sacrificing network performance or consuming the CPU cycles needed for business applications. This hardware-accelerated, software-defined NGFW is a milestone in boosting firewall performance and maximizing data center security coverage and efficiency.
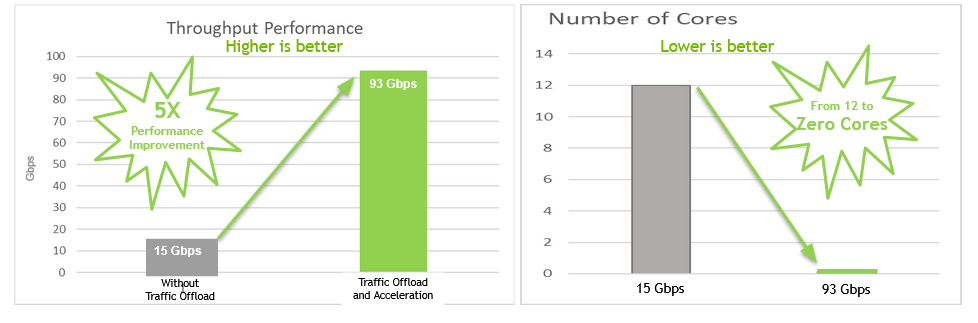
The DPU operates as an intelligent network filter to parse and steer traffic flows based on predefined policies with zero CPU overhead, enabling the NGFW to support close to 100 Gb/s throughput for typical use cases. This is a 5x performance boost versus running the VM-Series firewall on a CPU alone, and up to 150 percent CapEx savings compared to legacy hardware.
Intelligent traffic offload service
The joint Palo Alto Networks-NVIDIA solution creates an intelligent traffic offload (ITO) service that overcomes the challenges of performance, scalability, and efficiency. Integration of the VM-Series NGFWs with the NVIDIA BlueField DPUs turbocharges the NGFW solution to improve cost economics while improving threat detection and mitigation.
Figure 1. ITO using the Palo Alto Networks NGFW with the BlueField DPU helps enterprises that are challenged with performance vs. security vs. cost
In certain customer environments, up to 80% of network traffic doesn’t need to be—or can’t be—inspected by a firewall, such as encrypted traffic or streaming traffic from video, gaming, and conferencing. NVIDIA and Palo Alto Networks’ joint solution addresses this through the ITO service, which examines network traffic to determine whether each session would benefit from deep security inspection.
ITO optimizes firewall resources by checking all control packets but only checking payload flows that require deep security inspection. Suppose the firewall determines that the session would not benefit from security inspection. In that case, the firewall inspects the initial packets of the flow then ITO instructs the DPU to forward all subsequent packets in that session directly to their destination without sending them through the firewall (Figure 2).
Figure 2. DPU acceleration of NGFW provides unprecedented performance and efficiency gains
By only examining flows that can benefit from security inspection and offloading the rest to the DPU, the overall load on the firewall and the host CPU is reduced, and performance increases without sacrificing security.
ITO empowers enterprises to protect end users with an NGFW that can run on every host in a zero-trust environment, helping expedite their digital transformation while keeping them safe from a myriad of cyber threats.
First NGFW to market
To stay ahead of emerging threats, Palo Alto Networks jointly developed the first virtual NGFW to be accelerated by BlueField DPU. The VM-Series firewall enables application-aware segmentation, prevents malware, detects new threats, and stops data exfiltration, all at higher speeds and with less CPU consumption, by offloading these tasks from the host processor to the BlueField DPU.
The DPU operates as an intelligent network filter to parse, classify and steer traffic flows with zero CPU overhead, enabling the NGFW to support close to 100 Gb/s throughput per server for typical use cases. The recently announced DPU-enabled Palo Alto Networks VM-Series NGFW uses zero-trust network security principles.
The ITO solution was presented at NVIDIA GTC during a joint session with Palo Alto Networks. For more information about the ITO service’s role in delivering a software-defined, hardware-accelerated NGFW that addresses ever-evolving cybersecurity threats for enterprise data centers, see the Accelerating Enterprise Cybersecurity with Software-Defined DPU-Powered Firewall GTC session.
Join this webinar on August 4, 2022 to learn about moving from an Ignition Gazebo simulation to Isaac Sim using the Ignition-Omniverse experimental converter.
NVIDIA AI platform makes LLMs accessible. Announcing new parallelism techniques and a hyperparameter tool to speed-up training by 30% on any number of GPUs.
As the size and complexity of large language models (LLMs) continue to grow, NVIDIA is today announcing updates to the NeMo Megatron framework that provide training speed-ups of up to 30%.
These updates–which include two trailblazing techniques and a hyperparameter tool to optimize and scale training of LLMs on any number of GPUs–offer new capabilities to train and deploy models using the NVIDIA AI platform.
BLOOM, the world’s largest open-science, open-access multilingual language model, with 176 billion parameters, was recently trained on the NVIDIA AI platform, enabling text generation in 46 languages and 13 programming languages. The NVIDIA AI platform has also powered one of the most powerful transformer language models, with 530 billion parameters, Megatron-Turing NLG model (MT-NLG).
Recent advances in LLMs
LLMs are one of today’s most important advanced technologies, involving up to trillions of parameters that learn from text. Developing them, however, is an expensive, time-consuming process that demands deep technical expertise, distributed infrastructure, and a full-stack approach.
Yet their benefit is enormous in advancing real-time content generation, text summarization, customer service chatbots, and question-answering for conversational AI interfaces.
These new optimizations to the NVIDIA AI platform help solve many of the existing pain points across the entire stack. NVIDIA looks forward to working with the AI community to continue making the power of LLMs accessible to everyone.
Build LLMs faster
The latest updates to NeMo Megatron offer 30% speed-ups for training GPT-3 models ranging in size from 22 billion to 1 trillion parameters. Training can now be done on 175 billion-parameter models using 1,024 NVIDIA A100 GPUs in just 24 days–reducing time to results by 10 days, or some 250,000 hours of GPU computing, prior to these new releases.
NeMo Megatron is a quick, efficient, and easy-to-use end-to-end containerized framework for collecting data, training large-scale models, evaluating models against industry-standard benchmarks, and for inference with state-of-the-art latency and throughput performance.
It makes LLM training and inference easy and reproducible on a wide range of GPU cluster configurations. Currently, these capabilities are available to early access customers to run on NVIDIA DGX SuperPODs, and NVIDIA DGX Foundry as well as in Microsoft Azure cloud. Support for other cloud platforms will be available soon.
You can try the features on NVIDIA LaunchPad, a free program that provides short-term access to a catalog of hands-on labs on NVIDIA-accelerated infrastructure.
Two new techniques to speed-up LLM training
Two new techniques included in the updates that optimize and scale the training of LLMs are sequence parallelism (SP) and selective activation recomputation (SAR).
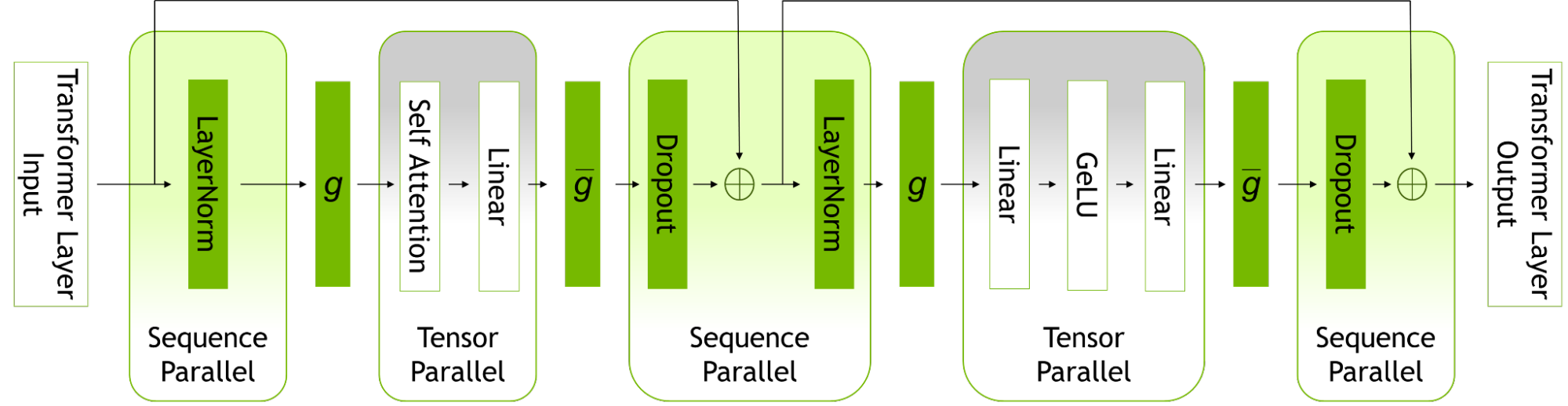
Sequence parallelism expands tensor-level model parallelism by noticing that the regions of a transformer layer that haven’t previously been parallelized are independent along the sequence dimension.
Splitting these layers along the sequence dimension enables distribution of the compute and, most importantly, the activation memory for these regions across the tensor parallel devices. Since the activations are distributed, more activations can be saved for the backward pass instead of recomputing them.
Figure 1. Parallelism modes within a transformer layer.
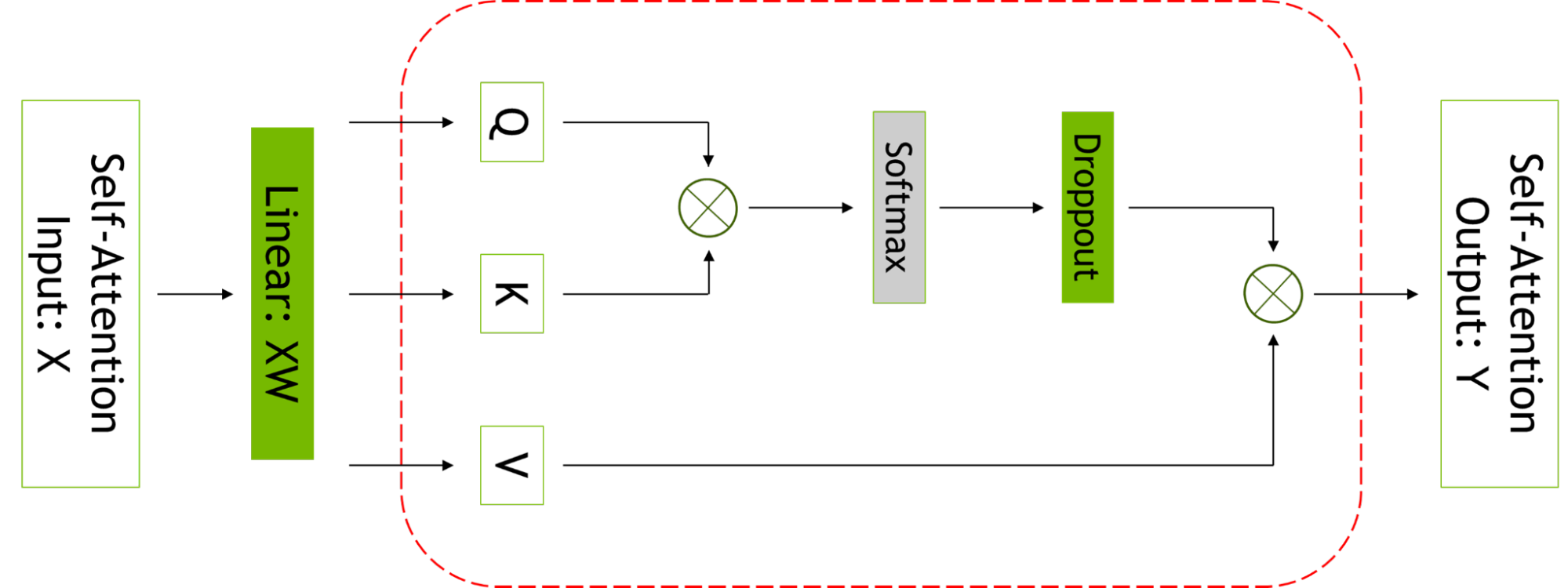
Selective activation recomputation improves cases where memory constraints force the recomputation of some, but not all, of the activations, by noticing that different activations require different numbers of operations to recompute.
Instead of checkpointing and recomputing full transformer layers, it’s possible to checkpoint and recompute only parts of each transformer layer that take up a considerable amount of memory but aren’t computationally expensive to recompute.
Figure 2. Self-attention block. The red dashed line shows the regions to which selective activation recomputation is applied.
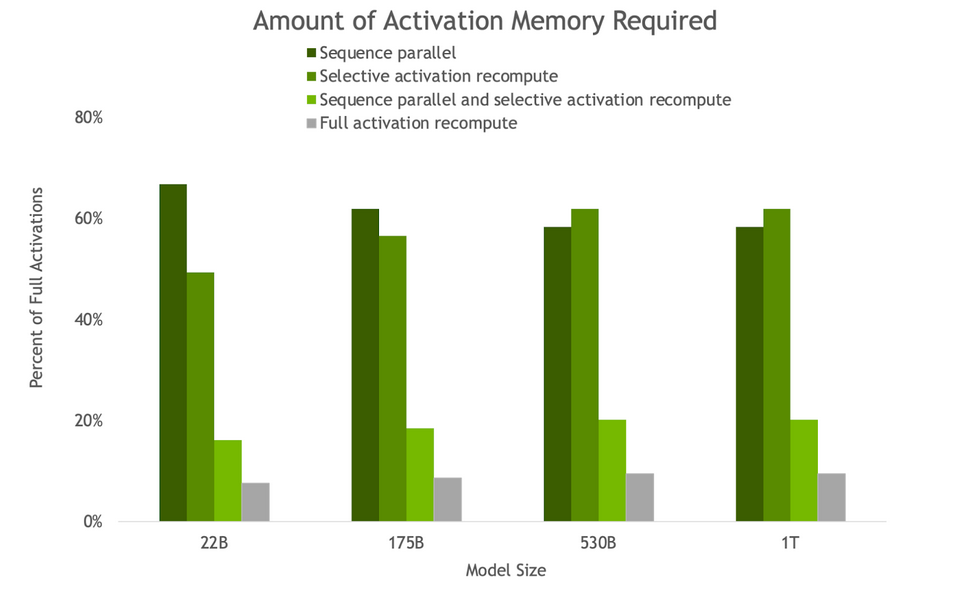
Figure 3. Amount of activation memory required in backward pass thanks to SP and SAR. As model size increases, both SP and SAR have similar memory savings, reducing the memory required by ~5x.
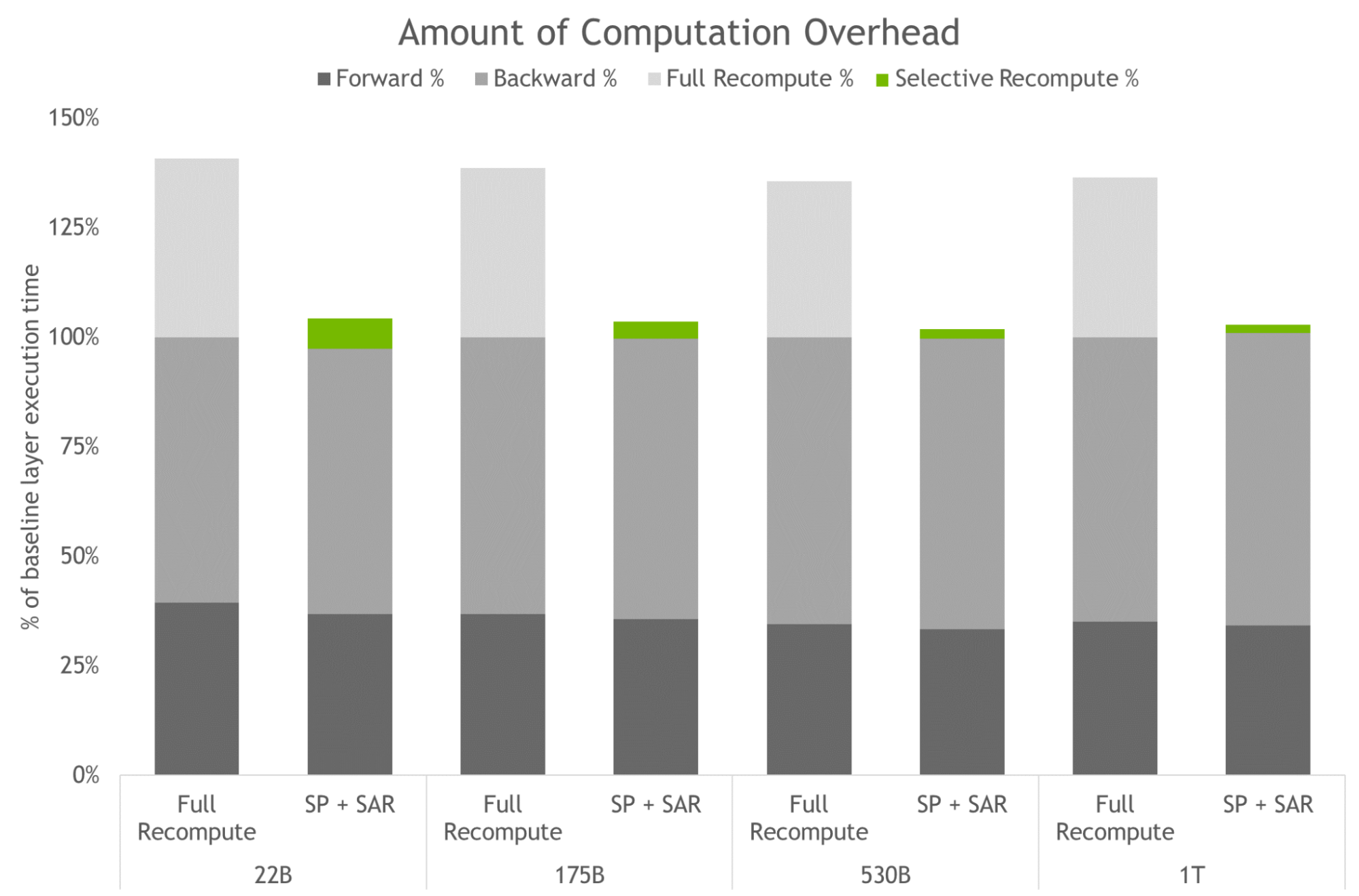
Figure 4. Amount of computation overhead for full activation recomputation, and SP plus SAR. Bars represent per-layer breakdown of forward, backward, and recompute times. Baseline is the case with no recomputation and no sequence parallelism. These techniques are effective at reducing the overhead incurred when all activations are recomputed instead of saved. For the largest models, overhead drops from 36% to just 2%.
Accessing the power of LLMs also requires a highly optimized inference strategy. Users can easily use the trained models for inference, and optimize for different use cases using p-tuning and prompt tuning capabilities.
These capabilities are parameter-efficient alternatives to fine-tuning and allow LLMs to adapt to new use cases without the heavy-handed approach of fine-tuning the full pretrained models. In this technique, the parameters of the original model are not altered. As such, catastrophic ‘forgetting’ issues associated with fine-tuning models are avoided.
New hyperparameter tool for training and inference
Finding model configurations for LLMs across distributed infrastructure is a time consuming process. NeMo Megatron introduces a hyperparameter tool to automatically find optimal training and inference configurations, with no code changes required. This enables LLMs to be trained to convergence for inference from day one, eliminating time wasted searching for efficient model configurations.
It uses heuristics and empirical grid search across distinct parameters to find configurations with best throughputs: data parallelism, tensor parallelism, pipeline parallelism, sequence parallelism, micro batch size, and number of activation checkpointing layers (including selective activation recomputation).
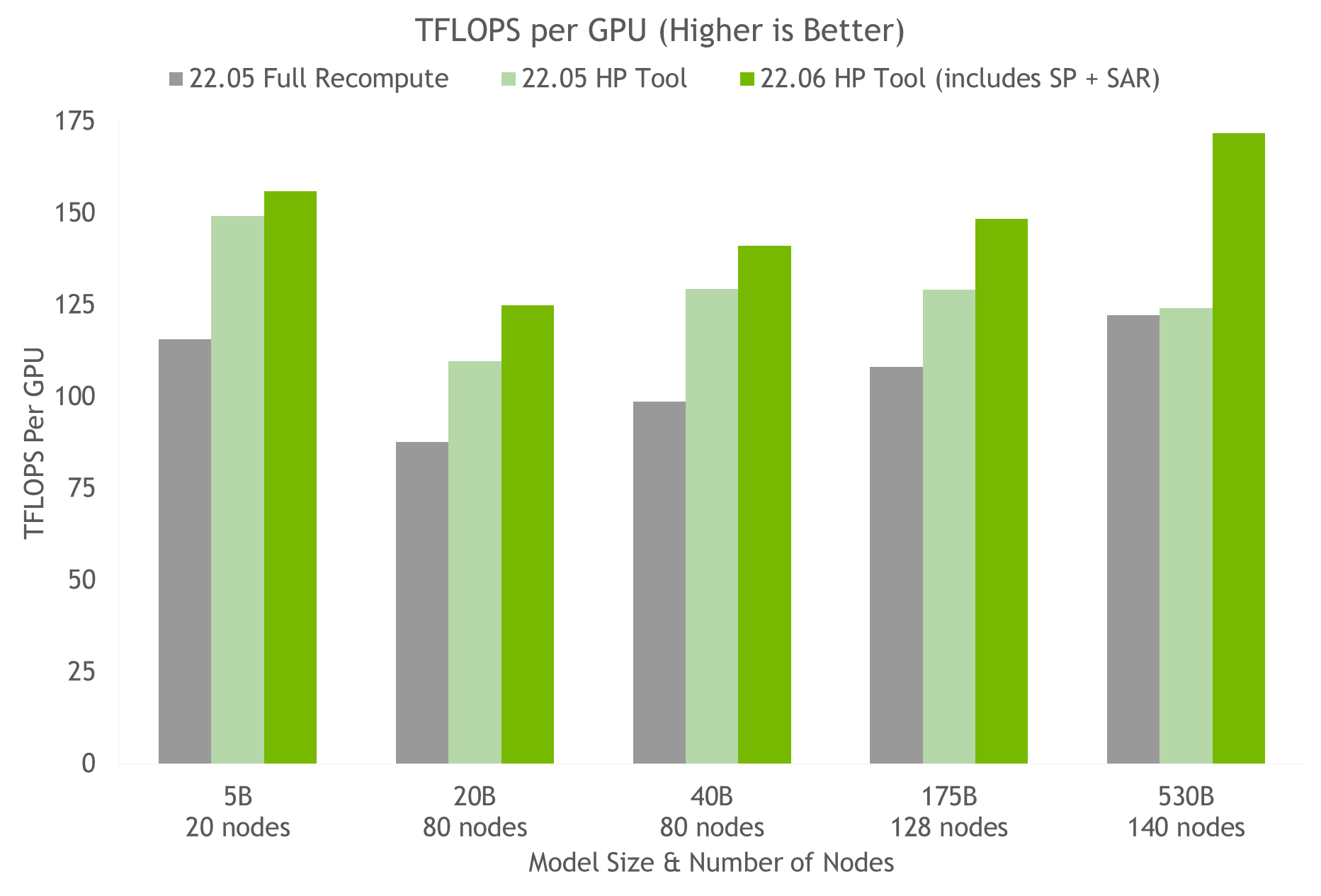
Using the hyperparameter tool and NVIDIA testing on containers on NGC, we arrived at the optimal training configuration for a 175B GPT-3 model in under 24 hours (see Figure 5). When compared with a common configuration that uses full activation recomputation, we achieve a 20%-30% throughput speed-up. Using the latest techniques, we achieve an additional 10%-20% speed-up in throughput for models with more than 20B parameters.
Figure 5. Results of the HP tool on several containers indicating speed-up with sequence parallelism and selective activation recomputation, wherein each node is a NVIDIA DGX A100.
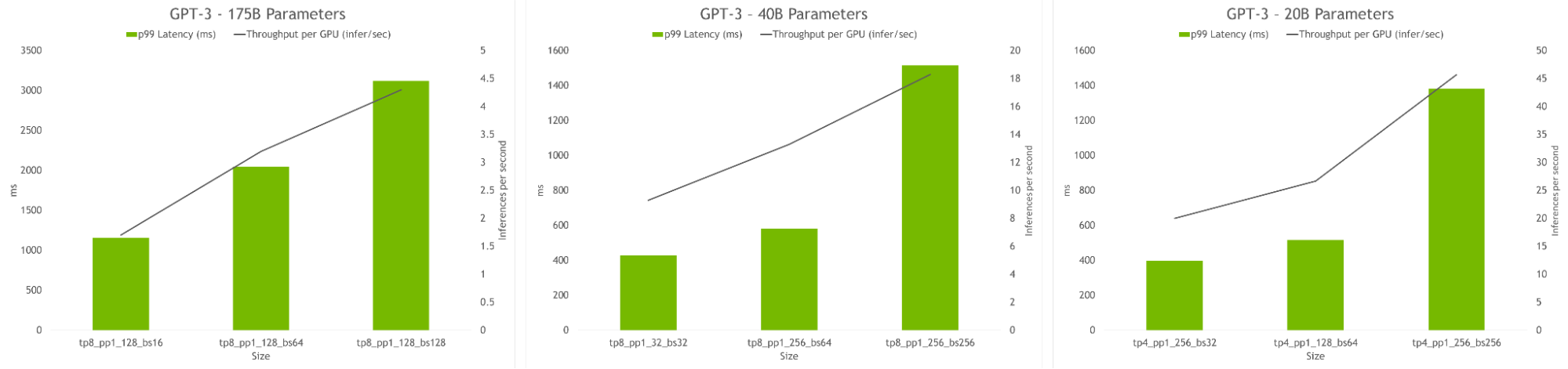
The hyperparameter tool also allows finding model configurations that achieve highest throughput or lowest latency during inference. Latency and throughput constraints can be provided to serve the model, and the tool will recommend suitable configurations.
Figure 6. HP tool results for inference, showing the throughput per GPU and the latency of different configurations. Optimal configurations include high throughput and low latency.
Learn how to get started with NVIDIA Riva, a fully accelerated speech AI SDK, on AWS EC2 using Jupyter Notebooks and a sample virtual assistant application.
Speech AI can assist human agents in contact centers, power virtual assistants and digital avatars, generate live captioning in video conferencing, and much more. Under the hood, these voice-based technologies orchestrate a network of automatic speech recognition (ASR) and text-to-speech (TTS) pipelines to deliver intelligent, real-time responses.
Building these real-time speech AI applications from scratch is no easy task. From setting up GPU-optimized development environments to deploying speech AI inferences using customized large transformer-based language models in under 300ms, speech AI pipelines require dedicated time, expertise, and investment.
In this post, we walk through how you can simplify the speech AI development process by using NVIDIA Riva to run GPU-optimized applications. With no prior knowledge or experience, you learn how to quickly configure a GPU-optimized development environment and run NVIDIA Riva ASR and TTS examples using Jupyter notebooks. After following along, this virtual assistant demo could be running on your web browser powered by NVIDIA GPUs on Amazon EC2.
Along with the step-by-step guide, we also provide you with resources to help expand your knowledge so you can go on to build and deploy powerful speech AI applications with NVIDIA support.
But first, here is how the Riva SDK works.
How does Riva simplify speech AI?
Riva is a GPU-accelerated SDK for building real-time speech AI applications. It helps you quickly build intelligent speech applications, such as AI virtual assistants.
By using powerful optimizations with NVIDIA TensorRT and NVIDIA Triton, Riva can build and deploy customizable, pretrained, out-of-the-box models that can deliver interactive client responses in less than 300ms, with 7x higher throughput on NVIDIA GPUs compared to CPUs.
The state-of-the-art Riva speech models have been trained for millions of hours on thousands of hours of audio data. When you deploy Riva on your platform, these models are ready for immediate use.
Riva can also be used to develop and deploy speech AI applications on NVIDIA GPUs anywhere: on premises, embedded devices, any public cloud, or the edge.
Here are the steps to follow for getting started with Riva on AWS.
Running Riva ASR and TTS examples to launch a virtual assistant
If AWS is where you develop and deploy workloads, you already have access to all the requirements needed for building speech AI applications. With a broad portfolio of NVIDIA GPU-powered Amazon EC2 instances combined with GPU-optimized software like Riva, you can accelerate every step of the speech AI pipeline.
There are four simple steps to get started with Riva on an NVIDIA GPU-powered Amazon EC2 instance:
Launch an Amazon EC2 instance with NVIDIA GPU-optimized AMI.
Step 1: Launch an EC2 instance with the NVIDIA GPU-optimized AMI
In this post, you use the NVIDIA GPU-optimized AMI available on the AWS Marketplace. It is preconfigured with NVIDIA GPU drivers, CUDA, Docker toolkit, runtime, and other dependencies. It also provides a standardized stack for you to build speech AI applications. This AMI is validated and updated quarterly by NVIDIA with the newest drivers, security patches, and support for the latest GPUs to maximize performance.
We recommend using NVIDIA A100 GPUs (P4d instances) for best performance at scale but for this guide, an A10G single-GPU instance (g5.xlarge instances) powered by the NVIDIA Ampere Architecture is fine.
For a greater number of pre- or postprocessing steps, consider larger sizes with the same single GPU, more vCPUs, and higher system memory, or consider the P4d instances that take advantage of 8x NVIDIA A100 GPUs.
For Private key file format, select ppk for use with PuTTY, depending on how you plan to connect to the instance.
After the key pair is created, a file is downloaded to your local machine. You need this file in future steps for connecting to the EC2 instance.
Network settings enable you to control the traffic into and out of your instance. Select Create Security Group and check the rule Allow SSH traffic from: Anywhere. At any point in the future, this can customized based on individual security preferences.
Finally, configure the storage. For this example, 100 GiB on a general purpose SSD should be plenty.
Now you are ready to launch the instance. If successful, your screen should look like Figure 1.
Figure 1. Success message after launching an instance
Connect to the instance
After a few minutes under Instances on the sidebar, you will see your running instance with a public IPv4 DNS. Keep this address handy as it is used to connect to the instance using SSH. This address will change every time you start and stop your EC2 instance.
You may begin working with your NVIDIA GPU-powered Amazon EC2 instance.
Figure 2. Starting screen of the NVIDIA GPU-Optimized AMI on an EC2 instance
Log in with username ubuntu, and make sure that you have the right NVIDIA GPUs running:
nvidia-smi
Step 2: Pull the Riva container from the NGC catalog
To access Riva from your terminal, first create a free NGC account. The NGC catalog is a one-stop-shop for all GPU optimized software, containers, pretrained AI models, SDKs, Helm charts and other helpful AI tools. By signing up, you get access to the complete NVIDIA suite of monthly updated GPU optimized frameworks and training tools so that you can build your AI application in no time.
Now you can configure the NGC CLI (preinstalled with the NVIDIA GPU-Optimized AMI), by executing the following command:
ngc config set
Enter your NGC API Key from earlier, make sure that the CLI output is ASCIIor JSON, and follow the instructions using the Choicessection of the command line.
After configuration, on the Riva Skills Quick Start page, copy the download command by choosing Download at the top right side. Run the command in your PuTTY terminal. This initiates the Riva Quick Start resource to download onto your EC2 Linux instance.
Initialize Riva
After the download is completed, you are ready to initialize and start Riva.
The default settings will prepare all of the underlying pretrained models during the Riva start-up process, which can take up to a couple of hours depending on your Internet speed. However, you can modify the config.sh file within the /quickstart directory with your preferred configuration around which subset of models to retrieve from NGC to speed up this process.
Within this file, you can also adjust storage location and specify which GPU to use, if more than one is installed on your system. This post uses the default configuration settings. The version (vX.Y.Z) number of Riva Quick Start that you downloaded is used to run the following commands (v2.3.0 is the version number used in this post).
cd riva_quickstart_v2.3.0
bash riva_init.sh
bash riva_start.sh
Riva is now running on your virtual machine. To familiarize yourself with Riva, run the Hello Worldexamples next.
Step 3: Run the Riva ASR and TTS Hello Worldexamples
There are plenty of tutorials available in the /nvidia-riva GitHub repo. The TTS and ASR Python basics notebooks explore how you can use the Riva API.
Before getting started, you must clone the GitHub repo, set up your Python virtual environment, and install Jupyter on your machine by running the following commands in the /riva_quickstart_v2.3.0 directory:
To run some simpleHello Worldexamples, open the /tutorialsdirectory and launch the Jupyter notebook with the following commands:
cd tutorials
jupyter notebook --generate-config
jupyter notebook --ip=0.0.0.0 --allow-root
The GPU-powered Jupyter notebook is now running and is accessible through the web. Copy and paste one of the URLs shown on your terminal to start interacting with the GitHub tutorials.
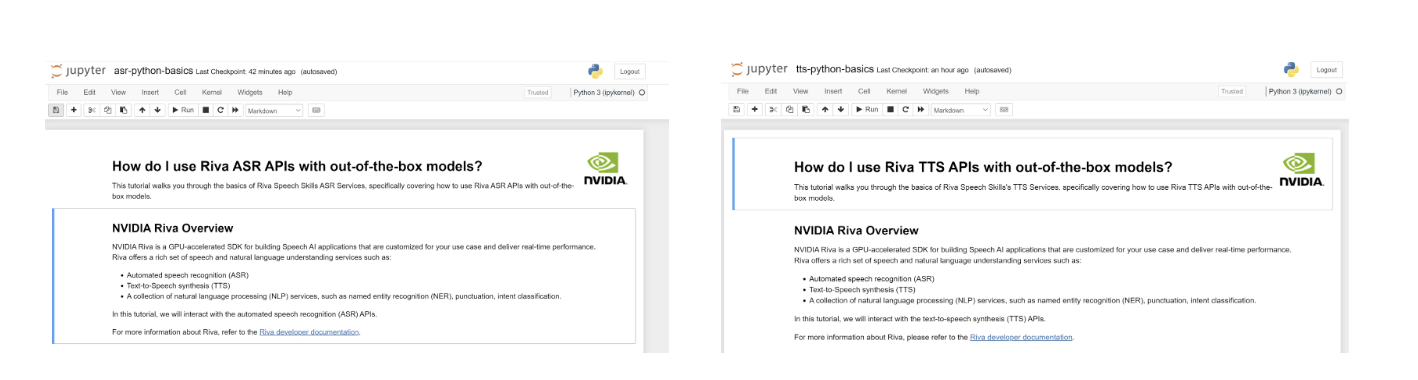
Open the tts-python-basics.ipynb and asr-python-basics.ipynb scripts on your browser and trust the notebook by selecting Not-Trusted at the top-right of your screen. To choose the venv-riva-tutorials kernel, choose Kernel, Change kernel.
You are now ready to work through the notebook to run your first Hello WorldRiva API calls using out-of-the-box models (Figure 3).
Figure 3. Example Hello World Riva API notebooks
Explore the other notebooks to take advantage of the more advanced Riva customization features, such as word boosting, updating vocabulary, TAO fine-tuning, and more. You can exit Jupyter by pressing Ctrl+Cwhile on the PuTTY terminal, and exit the virtual environment with the deactivate command.
Step 4: Launch an intelligent virtual assistant
Now that you are familiar with how Riva operates, you can explore how it can be applied with an intelligent virtual assistant found in /nvidia-riva/sample-apps GitHub repo.
To launch this application on your browser, run the following command in the /riva_quickstart_v2.3.0 directory:
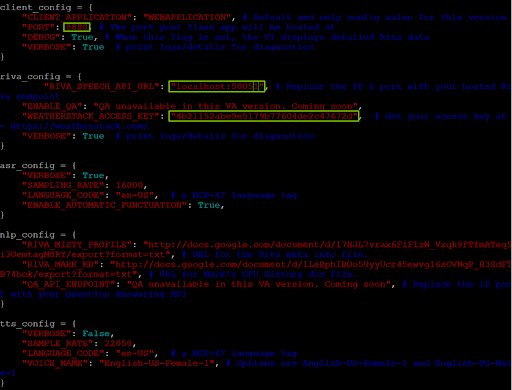
Before you run the demo, you must update the config.py file in the Virtual Assistant directory. Vim is one text editor that you can use to modify the file:
vim config.py
Figure 4. Editing the virtual assistant application’s config.py file
Make sure that the PORTvariable in client_configis set to 8888 and the RIVA_SPEECH_API_URLvalue is set to localhost:50051.
To allow the virtual assistant to access real-time weather data, sign up for the free tier of weatherstack, obtain your API access key, and insert the key value under WEATHERSTACK ACCESS KEYin riva_config.
Now you are ready to deploy the application!
Deploy the assistant
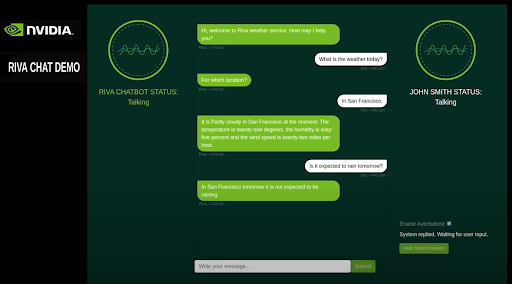
Run python3 main.pyand go to the following URL: https://localhost:8888/rivaWeather. This webpage opens the weather chatbot.
You’ve launched an NVIDIA GPU-powered Amazon EC2 instance with the NVIDIA GPU-Optimized AMI, downloaded Riva from NGC, executed basic Riva API commands for ASR and TTS services, and launched an intelligent virtual assistant!
You can stop Riva at any time by executing the following command in the riva_quickstart_v2.3.0directory:
bash riva_stop.sh.
Resources for exploring speech AI tools
You have access to several resources designed to help you learn how to build and deploy speech AI applications:
The /nvidia-riva/tutorials GitHub repo contains beginner to advanced scripts to walk you through ASR and TTS augmentations such as ASR word boosting and adjusting TTS pitch, rate, and pronunciation settings.
To build and customize your speech AI pipeline, you can use the NVIDIA low-code AI model development TAO toolkit and the NeMo application framework for those who like more visibility under the hood for fine-tuning the fully customizable Riva ASR and TTS pipelines.
Interested in learning about how customers deploy Riva in production? Minerva CQ, an AI platform for agent assist in contact centers, has deployed Riva on AWS alongside their own natural language and intent models to deliver a unique and elevated customer support experience in the electric mobility market.
“Using NVIDIA Riva to process the automatic speech recognition (ASR) on the Minerva CQ platform has been great. Performance benchmarks are superb, and the SDK is easy to use and highly customizable to our needs.” Cosimo Spera, CEO of Minerva CQ

 Learn how to free your Jetson GPU for additional tasks by deploying neural network models on the NVIDIA Jetson Orin Deep Learning Accelerator (DLA).
Learn how to free your Jetson GPU for additional tasks by deploying neural network models on the NVIDIA Jetson Orin Deep Learning Accelerator (DLA).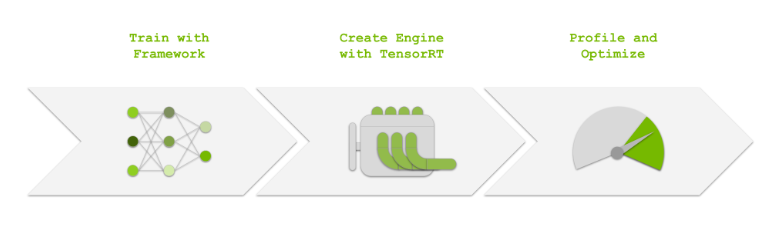
 Data lakes can ingest a wide range of data types for big data and AI repositories. Data warehouses use structured data, mainly from business applications, with a focus on data transformation.
Data lakes can ingest a wide range of data types for big data and AI repositories. Data warehouses use structured data, mainly from business applications, with a focus on data transformation.  The TAO Toolkit lab on LaunchPad has everything you need to experience the end-to-end process of fine-tuning and deploying an object detection application.
The TAO Toolkit lab on LaunchPad has everything you need to experience the end-to-end process of fine-tuning and deploying an object detection application. Palo Alto Networks and NVIDIA have developed an Intelligent Traffic Offload (ITO) solution to solve the scaling, efficiency, and economic challenges this creates.
Palo Alto Networks and NVIDIA have developed an Intelligent Traffic Offload (ITO) solution to solve the scaling, efficiency, and economic challenges this creates. 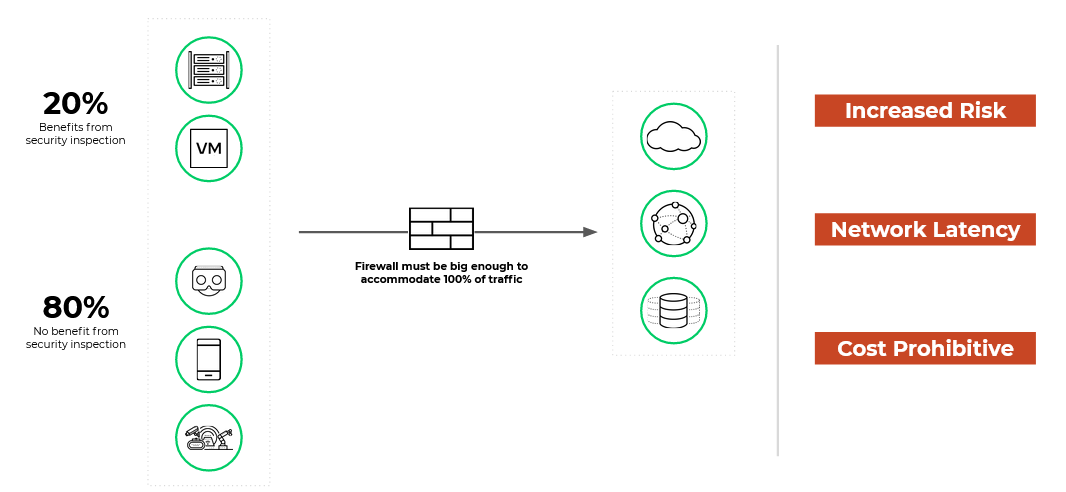
 Join this webinar on August 4, 2022 to learn about moving from an Ignition Gazebo simulation to Isaac Sim using the Ignition-Omniverse experimental converter.
Join this webinar on August 4, 2022 to learn about moving from an Ignition Gazebo simulation to Isaac Sim using the Ignition-Omniverse experimental converter. NVIDIA AI platform makes LLMs accessible. Announcing new parallelism techniques and a hyperparameter tool to speed-up training by 30% on any number of GPUs.
NVIDIA AI platform makes LLMs accessible. Announcing new parallelism techniques and a hyperparameter tool to speed-up training by 30% on any number of GPUs.