I faced an error when I was building Tensorflow from the source with my laptop. It has only 8GB RAM and out of memory is the reason for the error. I’m going to buy a new laptop but I’m not sure how much memory Tensorflow requires. MacBook Air is one of the candidates. I would be happy if I know something about it. Thanks.
Learn about our joint effort in porting the ILT engine to GPU. We also identify future areas for EDA and mask inspection tool vendors to address for ILT to be adopted at logic foundries.
Inverse lithography technology (ILT) was first implemented and demonstrated in early 2003. It was created by Danping Peng, while he worked as an engineer at Luminescent Technologies Inc., a startup company founded by professors Stanley Osher and Eli Yabonovitch from UCLA and entrepreneurs Dan Abrams and Jack Herrik.
At that time, ILT was a revolutionary solution that showed far superior process-window than conventional Manhattan mask shapes used in lithography patterning. Unlike Manhattan mask shapes that are rectilinear, ILT’s advantage lies in its curvilinear mask shapes.
Following its development, ILT was demonstrated as a viable lithography technique in actual wafer printing at several memory and logic foundries. However, technical and economic factors hindered the adoption of ILT:
The ILT mask took an enormous amount of time to compute, >10x longer than the traditional Manhattan mask.
It also suffered from some stitching issues at the tile boundary when ILT generated the model-based assistant features.
The ILT mask file-size was huge (6-7x more than the conventional mask file-size) and therefore took a long time to write using a variable-shaped beam (VSB) writer.
ASML introduced the immersion lithography scanner with better focus and dose control, and manufacturing needs could be satisfied using a traditional Manhattan mask.
Due to these reasons, ILT’s usage was largely used in memory foundries for cell-array printing and in logic foundries as hot-spot repair or used to benchmark and improve the traditional optical proximity correction (OPC).
Current state of ILT
Fast forward to 20 years later and there is a different semiconductor landscape today. The challenges in patterning feature sizes at 7nm and lower require far greater accuracy and process margin. Thus, the ability to produce curvilinear mask shapes in ILT becomes increasingly critical to overcoming these wafer production limitations.
Today’s advancement in lithographic simulation on GPU achieved speedups of over 10x more than traditional CPU computation, with machine learning (ML) providing further speedup of the ILT model by learning from existing solutions.
Multi-Beam mask writers could also write masks of any complexity in fixed time and it has been successfully used in HVM.
Finally, next-generation lithography scanners are becoming increasingly expensive, therefore extracting value and performance from existing scanners through ILT was a more appealing option.
Through GPU computing and ML, the deployment of ILT for full-chip applications is becoming a reality. It is expected to play a key role in pushing the frontiers of mask patterning and defect inspection technologies.
Overcoming ILT adoption challenges in logic and foundry production environments
To use ILT successfully in a logic foundry environment, you must address the issues that prevented its mass adoption:
Long computation time
Mask-rule checking specific to curvilinear OPC
Large layout file sizes
Long computation time
ILT requires a long computation time due to the complexity of curvilinear mask shapes. Fortunately, recent progress in GPU computing performance and deep learning (DL) has significantly reduced the amount of time required to solve these complex computation algorithms.
Mask-rule checking specific to curvilinear OPC
Second, mask-rule checking (MRC) specific to curvilinear OPC must be addressed as mask shops need a method of verifying whether the incoming mask data is manufacturable. This is especially so for curvilinear mask shapes, as they are more challenging to verify than rectilinear mask shapes since simple width and space checks are no longer applicable in curvilinear masks.
To address MRC, the industry is converging to using simplified rules, such as minimal CD/Space, minimal area for holes and islands, and smoothness of mask edge (upper-bound for curvature).
Large layout file sizes
Lastly, layout file sizes generated by ILT are unacceptably large compared to conventional rectilinear shapes. The increased size represents a significantly increased cost of data generation, storage, transfer, and use in manufacturing.
EDA solutions
To solve this, EDA vendors have proposed various solutions, and a working group was formed to work on a common file format supported by all stakeholders (EDA vendors, tool suppliers, and foundries).
GPU + DL: The ideal solution to solving ILT’s challenges using GPUs
Our close partnership with EDA vendors and NVIDIA has resulted in a home-grown ILT solution. Using the NVIDIA GPU platform, we successfully ported most of the simulation and ILT engine using NVIDIA SDKs and libraries:
CUDA
cuFFT
cuSOLVER
NVPR: NVIDIA Path Rendering with OpenGL Extensions
Optix RT compute
And more
On NVIDIA V100 32-GB GPUs, we demonstrated over 10x speedup in ILT computations as compared to our typical CPU runs. In many key components of the optical and resist modeling, we saw an over 20x speedup.
The encouraging results have led to further developments. We are currently in the process of production scale calibration and testing of key layers using our in-house ILT engine on an NVIDIA A100 80-GB GPU cluster.
Figure 1. GPU speedup with in-house ILT engine
Future opportunities with ILT
Advanced chip design increasingly relies on expensive simulations: from circuit performance and timing to thermal dissipation. When it comes to manufacturing, OPC/ILT requires a huge amount of computing power, which is expected to increase as we rapidly progress towards the next node.
Employing HPC with GPUs as well as the entire software stack, consistent with the observation in Huang’s Law, will be the key component to successfully rolling out future generation chips on schedule. More specifically, a unified acceleration architecture for HPC + Rendering (Computer Graphics) + ML/DL will enable better chips to be designed and manufactured, which in turn contributes to improving the speed and efficiency of mask patterning and defect detection applications.
In other words, it’s an iterative process of using GPUs to design faster and better GPUs.
To enable the rapid adoption of ILT masks in HVM, all stakeholders must participate in partnerships and collaborations.
EDA vendors should make sure that its OPC simulation and correction engine can generate curvilinear mask designs, which conform to standard mask rules that outputs into an acceptable file size and format.
Vendors for mask data preparation (MDP) should align their systems to process these curvilinear mask data.
Mask inspection and review tool suppliers should upgrade their systems and algorithms to inspect, model, and detect any potential defects.
There’s no doubt that curvilinear ILT mask designs provide circuit designers with greater freedom and creativity to create circuits with better performance while enabling better process margins with greatly simplified design rules. The benefits of using curvilinear design will have a significant impact on the semiconductor industry and ILT will be the key enabler to the future development of process nodes.
I have converted 2 csv files into arrays in the hopes that I can create a positive training sample. Could someone help me find a way to combine anchors and matches, so that they are a positive training sample. This would be hugely appreciated as I am quite stuck.
I read about Grappler and that it can optimize TF models, which is an interesting feature.
I use keras to create, train and save models, and also convert them to tflite in order to deploy them on other systems. My question is, whether this optimization is already integrated into keras and / or the tflite conversion.
It seems like quite a big topic to get into, so if it already happens automatically, I don’t want to spend so much time on it.
Howdy there! Pardon if this ain’t the right place but basically the gist is, I need an older version of Tensorflow that I (miraculously) used to run on an 18 year old 32-bit PC because I was too poor for a pi before my friend got me one as a gift once my dino finally died. I specifically need to get Tensorflow 1.12.2 running for a bot that I host for my buddies and I, but I’m at something of a loss as to how I’d do it. I’ve looked into guides but all of them are for 2.0 and or just announce “Tensorflow can be installed with pip/apt now!” and a command that doesn’t work for me. It feels as if all the guides for how to install Tensorflow 1.X on a Pi 4 onward have been wiped from the internet or replaced with stuff that just doesnt work or help, what guides I could find just didn’t work either. Bazel’s certainly not making it easy either. With that no python wheels work either, with all of them seemingly not made for arch64 or the version of TF I specifically need. So yeah, thats where I’m at. My Pi OS is the 64-bit lite version if that helps at all. Anything at all would be greatly appreciated as my poor bot has been offline for a long while. Thanks!
I need help in coming up with a technique to determine when an object is not in the list of already classified objects.
I am sorting parts that are the identical shape, but differ in the text written on them. Unfortunately the text is written in a circle, so I can’t simply read the text with OCR. (At least I couldn’t make it work.)
I have about 20 different labels on the parts I currently have. Some parts I have 1,000 pictures of, others I only have 100 pictures.
I discovered while I was sorting that there are actually more than 20 different labels, there are parts I didn’t know about that only occur once or twice in five hundred parts. I would like to be able to identify and handle parts like this separately.
I am using keras.resnet50 to classify the images (parts). I get about a 96% accuracy of a part being identified correctly when I use two different classifiers to look at the same image and then check their agreement. I do this because I would rather reject parts than have them sorted incorrectly. Classifier two just has a different number of epochs than classifier one.
My images are 300×300.
I look at the weight of the prediction, and 95% of my predictions are almost certain, say .99999, so I haven’t been able to do the simple thing of just looking at the strength of the prediction.
In case this is relevant, the resnet50 classifier that I have trained might be overtrained. Within three epochs it is at like 99.7% accuracy with a val_accuracy of 98%.
I have an NN multi-class text classifier. Input is a vector of embeddings (the input is a sequence of words that are looked up on a vocab, and its embedding is used, of course). Since the domain of this model is a closed set (the vocabulary, and the size of the sequence), I’m thinking it should be possible to try a small set of all possible inputs (random phrases) to get an idea of what words would maximize a given class.
My question: is there a more efficient algorithm to do this, other than trying random sequences of words from the vocabulary?
I’m thinking there has to be a way to do this backwards – looking at the weights in the various units in the last layers relative to the embedding values.
I need help in coming up with a technique to determine when an object is not in the list of already classified objects.
I am sorting parts that are the identical shape, but differ in the text written on them. Unfortunately the text is written in a circle, so I can’t simply read the text with OCR. (At least I couldn’t make it work.)
I have about 20 different labels on the parts I currently have. Some parts I have 1,000 pictures of, others I only have 100 pictures.
I discovered while I was sorting that there are actually more than 20 different labels, there are parts I didn’t know about that only occur once or twice in five hundred parts. I would like to be able to identify and handle parts like this separately.
I am using keras.resnet50 to classify the images (parts). I get about a 96% accuracy of a part being identified correctly when I use two different classifiers to look at the same image and then check their agreement. I do this because I would rather reject parts than have them sorted incorrectly. Classifier two just has a different number of epochs than classifier one.
My images are 300×300.
I look at the weight of the prediction, and 95% of my predictions are almost certain, say .99999, so I haven’t been able to do the simple thing of just looking at the strength of the prediction.
In case this is relevant, the resnet50 classifier that I have trained might be overtrained. Within three epochs it is at like 99.7% accuracy with a val_accuracy of 98%.
This post details how the filesystem specification’s new parquet model provides a format-aware byte-cashing optimization.
As datasets continue to grow in size, the adoption of cloud-storage platforms like Amazon S3 and Google Cloud Storage (GCS) are becoming more popular. Although node-local storage is likely to result in better IO performance, this approach can become impractical after the dataset exceeds the single-terabyte scale.
For cases where remote storage is the only practical solution, much of the PyData ecosystem has already adopted Filesystem Spec (fsspec) as a universal file-system API. While fsspec has provided users with adequate remote storage access since the introduction of s3fs and gcsfs, the internal byte-transfer and caching algorithms have not yet leveraged format-specific optimizations for high-performance file formats like Parquet.
Key learnings
In this post, we introduce the fsspec.parquet module, which provides a format-aware, byte-caching optimization for remote Parquet files. This module is both experimental and limited in scope to a single public API: open_parquet_file.
This API provides faster remote-file access. When compared with the default read_parquet behavior in the pandas and cuDF DataFrame libraries, there is a consistent performance boost in overall throughput for partial I/O (column-chunk and row-group selection) from large Parquet files.
We also discuss the optimizations used within this new module and present the preliminary performance results.
What is fsspec?
Filesystem Spec (fsspec) is an open-sourced project providing a unified Python interface to a variety of backend storage systems. fsspec corresponds to a specific fsspec Python library and a larger GitHub organization containing many system-specific repositories (for example, s3fs and gcsfs).
The advantage of using fsspec within a Python-based library or application is that the same POSIX-like file API can write and read from remote objects and local files alike. When a cloud-based object is opened by an fsspec-compatible file system, the underlying application is given an AbstractBufferedFile object, or some other file-like object designed to duck-type with native Python file objects. Now, these file-like objects can be treated the same way as local Python-file handles.
One obvious difference is the AbstractBufferedFile object must use file system-specific commands internally to put and get bytes to and from the remote storage system. As internal data-transfer operations typically have higher latency than local disk accesses, fsspec offers several caching strategies to prefetch data while avoiding many small requests.
Later in this post, we explain why the default caching strategy is often suboptimal for large Parquet files, and how a new KnownPartsOfAFile (“parts”) option can dramatically reduce read latency.
What is Parquet?
Parquet is a binary column-oriented data-storage format, designed with performance, compression, and partial I/O in mind. Due to its dramatic performance advantages over text-formatted files like CSV, the open-source format has experienced rapid growth in popularity since its initial release in 2013.
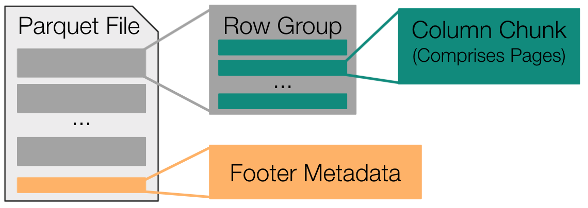
To understand the optimizations used within the Fsspec-Parquet module, it is useful to have a high-level understanding of the Parquet specification. Figure 1 shows that all Parquet files consist of a collection of contiguously stored row-groups, and each of these row-groups includes a collection of contiguously stored column chunks.
Figure 1. High-level visual representation of the Parquet file format
Altogether, the majority of all bytes in a Parquet file correspond to these column chunks. The remaining bytes are used to store file metadata within a thrift-formatted footer. This footer metadata includes byte offsets and optional statistics (min, max, valid count, null count) for every column-chunk in the file.
Because this vital information is consolidated in the footer, it is only necessary to sample the end of a Parquet file to determine the specific location of each column-chunk in the file.
What is the purpose of fsspec’s new Parquet module?
fsspec is already the most common means of loading Parquet files under Python. The primary purpose of the new fsspec.parquet module is to provide an optimized utility for exactly this task.
Internally, this new utility (open_parquet_file) essentially wraps a conventional open call in Parquet-specific logic that is designed to begin the transfer of all relevant data from the remote file into local memory before the user has even initiated an explicit read operation.
Although reads of any size may benefit from this new utility, the most significant improvements are seen when the read operation targets only a subset of all columns and row-groups. For example, when the remote read is using column projection, the same list of columns can be passed directly to open_parquet_file:
from fsspec.parquet import open_parquet_file
import pandas as pd
path = “://my-bucket/my-data”
columns = [“col1”, “col2”]
options = {“necessary”: ”credentials”}
with open_parquet_file(
path,
columns=columns,
storage_options=options,
) as f:
df = pd.read_parquet(path, columns=columns)
As we mentioned earlier, the primary purpose of the fsspec new open_parquet_file function is to improve read performance from large Parquet files by using a format-aware caching strategy within AbstractBufferedFile.open.
To understand why the specific optimizations used by the Parquet module are beneficial, it is helpful to start with an understanding of the simple cache-free approach, as well as the default read-ahead strategy.
Understanding cache-free and read-ahead approaches
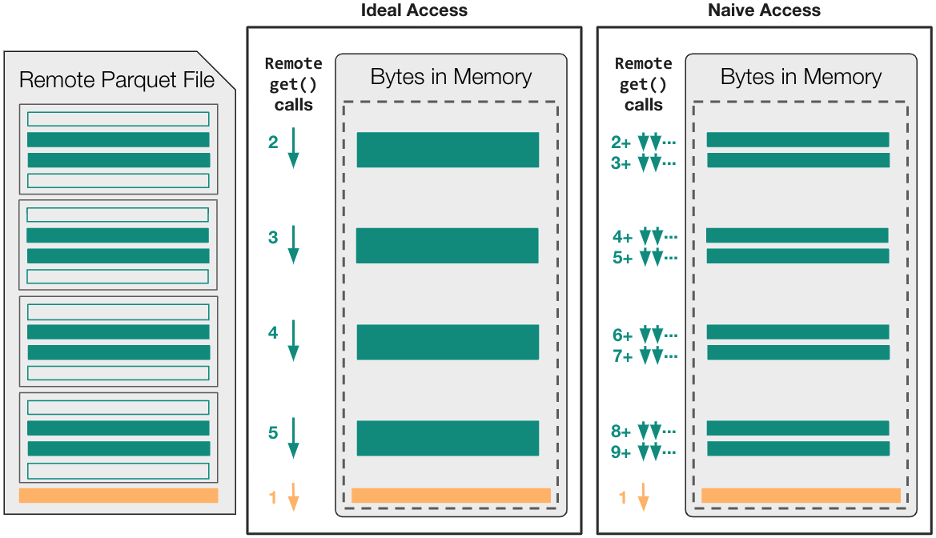
Figure 2 shows how cache-free file access is likely to map onto remote get calls within a read_parquet operation (after the remote file is already opened) for both an ideal and naive sequence of read calls.
Figure 2. Comparison of ideal and naive data access patterns from a remote Parquet file
In this particular example, assume the Parquet file is large enough (~400MB+) to comprise four distinct row-groups, and the read_parquet call is targeting two out of the four available columns. This means the AbstractBufferedFile object must ultimately transfer eight distinct column-chunk ranges, along with the footer metadata, into local memory.
In the case that caching is disabled, it is possible for a well-tuned Parquet library to move only the necessary data into local memory using five distinct requests. However, as fsspec’s file-like interface contains state, these five read calls are always serial and incur one whole latency time for each call.
This ideal-access scenario is incapable of leveraging concurrency to minimize latency, even though the strategy is likely to minimize the number of file-system requests and produce high overall throughput. For Parquet libraries that take a naive-access approach and do not explicitly minimize the number of read calls, the read_parquet operation is likely to suffer from high latency and low overall throughput!
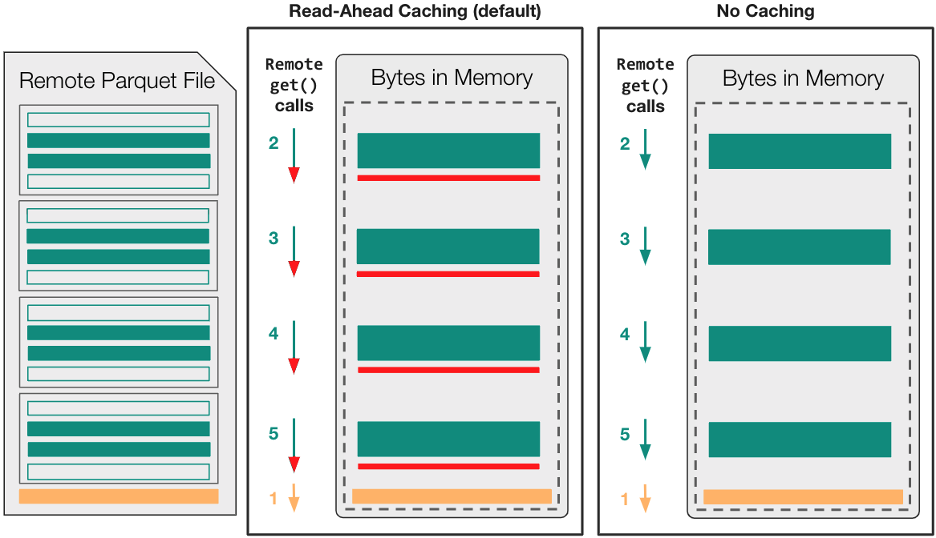
At this point, we’ve established that the I/O library is unable to take advantage of file-system concurrency after the file is already opened for reading. What is even more important to consider is that the default read-ahead caching strategy can degrade the observed performance even further when partial I/O is involved. This is because the inherent assumption of read-ahead caching is that sequential file accesses are likely to be contiguous.
Figure 3 shows that read-ahead caching is likely to transfer about 20 MB of unnecessary data, 5 MB of read-ahead for each row-group.
Figure 3. Comparison of the read-ahead and cache-free file-access strategies in fsspec
As you see in the following performance results, the benefit of disabled caching over read-ahead caching is dependent on both the engine used within read_parquet and the specific storage system.
If the engine already includes format-aware optimizations to move the necessary byte ranges into local memory (that is, pyarrow and fastparquet), then the no-caching option is likely the better choice. When the engine assumes local file access is fast (cuDF), some form of fsspec-level caching may be critical.
In either case, the engine is unable to begin the transfer of the required byte ranges until after the fsspec file object is created. It is limited by the additive latency of sequential data transfer.
Now that we’ve established a high-level understanding of both default and cache-free AbstractBufferedFile behavior within a typical read_parquet call, we can now explain the two general optimizations used by open_parquet_file to improve overall read throughput.
Optimization 1: Use the “parts” caching strategy
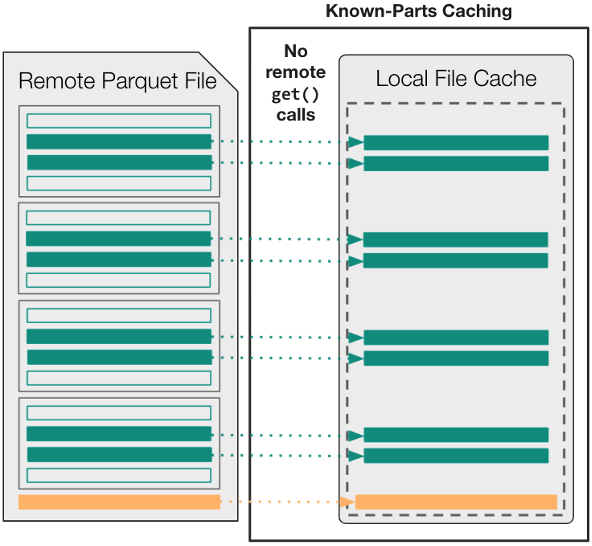
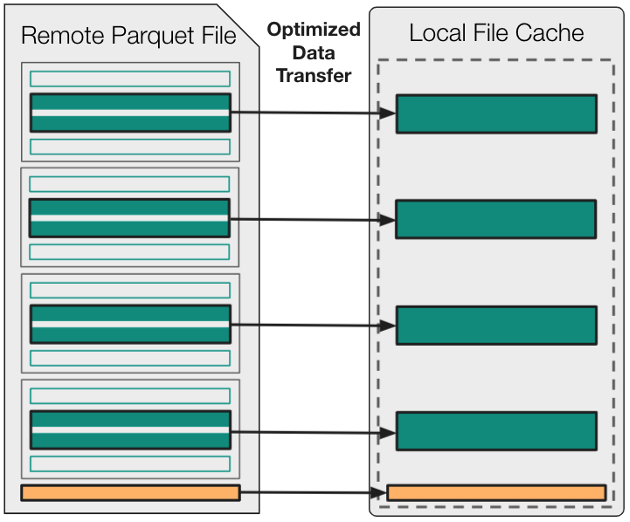
Instead of the format-agnostic caching strategies used within AbstractBufferedFile by default, you use the new KnownPartsOfAFile (“parts”) option to cache exactly what you need before the file is even open.
In other words, begin by using an external Parquet engine (either fastparquet or pyarrow) to parse the footer metadata up-front. Then, transfer the necessary byte-ranges into local memory, and use the parts’ cache to ensure that downstream applications never have to wait for remote data after an open fsspec file object is acquired.
Figure 4 shows that there is no longer any relationship between the logic used to access data within read_parquet and the number or size of get calls used for remote-data access. From the perspective of the Parquet engine, any read operation is near-instantaneous, because all necessary data is already cached in memory.
Figure 4. The fsspec’s “parts” caching strategy. All necessary data must be cached in local memory before the file-like object is even opened.
Optimization 2: Transfer “parts” asynchronously and in parallel
Although the previous optimization enables you to avoid many small get operations and unnecessary data transfer within read_parquet, you must still populate the KnownPArtsOfAFile cache before AbstractBufferedFile can be initialized.
To do this as efficiently as possible, use cat_ranges to fetch all the required column-chunks at one time, both asynchronously and in parallel using asyncio. Because the total number of transferred column chunks can be large for files containing many fields or multiple row-groups, you also aggregate adjacent byte-range requests as long as the size of the aggregated request stays below an upper limit.
Figure 5 shows that this approach ultimately leads to the concurrent transfer of multiple byte ranges of optimal size.
Figure 5. Data-transfer optimizations used in fsspec.parquet
Preliminary fsspec.parquet benchmark results
To compare the performance of open_parquet_file with other fsspec– and pyarrow-based file-handling methods, use the available Python script:
pyarrow-6.0.1
fastparquet-0.8.0
cudf-22.04
fsspec/s3fs/gcfs-2022.2.0
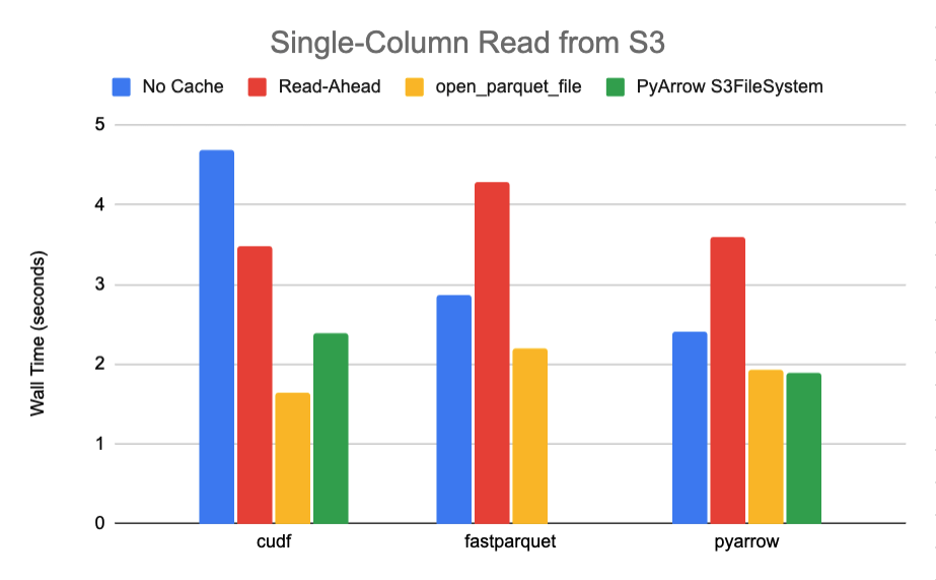
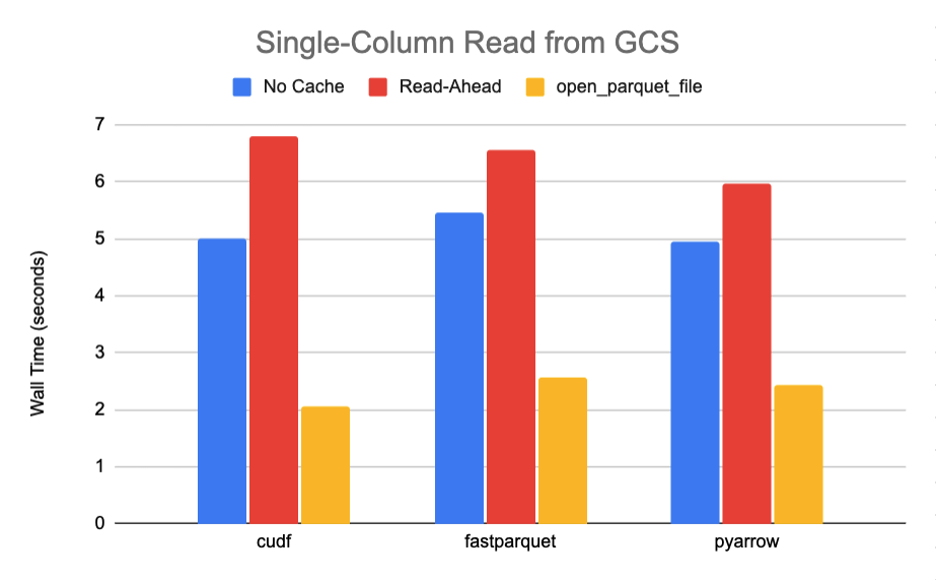
Using this script, we read a single column from a 789M Parquet file containing a total of 10 row-groups and 30 columns with snappy compression requiring the transfer of roughly 27M of data. The results for both S3 and GCS, summarized in Figures 6-7, clearly show a significant performance boost of 85% or more when moving from the default caching strategy to open_parquet_file.
In fact, the new function effectively matches the performance of PyArrow’s native S3FileSystem implementation, which is specifically designed for optimal performance with its Parquet engine. In this post, we compare it only with a native PyArrow filesystem for this single Amazon S3 benchmark, because PyArrow only offers publicly supported implementations for Amazon S3 and Hadoop at the time of publication.
Figure 6. General benchmark results for S3 storage
Figure 7. General benchmark results for GCS storage
To illustrate the benefit of using open_parquet_file scales with the overall size of the file, we also read a single column from a 12 GB Parquet file containing the first day of the Criteo dataset from public GCS storage with compression disabled. Figure 8 shows that the new fsspec function can offer a 10x speedup or more over default caching.
Figure 8. Criteo-dataset benchmark results for GCS storage
Test it out yourself
In this post, we introduced the fsspec.parquet module, which provides a format-aware, byte-caching optimization for opening remote Parquet files, open_parquet_file. Benchmarking clearly suggests that the new optimization can offer significant performance improvements over default file-opening behavior in fsspec, and may even approach the performance of optimized C++ file-system implementations in PyArrow for partial I/O.
Since being officially released in the 2021.11.0 version of fsspec, the open_parquet_file utility has already been adopted by both the RAPIDS cuDF library and Dask-Dataframe.
Due to dramatic and consistent improvement available for cuDF-based workflows, this new feature has already been adopted as the default file-opening approach within cudf.read_parquet and dask_cudf.read_parquet.
For Dask users without GPU resources, the optimized caching approach can now be opted into by passing an open_file_options argument to read_parquet. For example, the following code example instructs Dask to open all Parquet data files with the parquet pre-caching method:
Given this early success, we are hoping to expand and simplify the available pre-caching options in fsspec, and establish a clear precache_options API within all file-opening functions.
Community feedback here is critical. Please engage on GitHub or comment below, and let us know what you think!
- weight name: discriminator/gan/conv6/bias:0, shape: [256], size: 256 [32;1mTrigger callback: [0mTotal counts of trainable weights: 33579064. Total size of trainable weights: 0G 32M 24K 56B (Assuming32-bit data type.) 2022-05-05 11:29:14.865680: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cublas64_100.dll 2022-05-05 11:29:15.131382: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudnn64_7.dll 2022-05-05 11:29:15.901900: W tensorflow/stream_executor/cuda/redzone_allocator.cc:312] Internal: Invoking ptxas not supported on Windows Relying on driver to perform ptx compilation. This message will be only logged once.
however the linux stays at the
Total size of trainable weights: 0G 32M 24K 56B (Assuming32-bit data type.)
for ever,
assume this linux wasn’t able to open the cudnn???
cudnn is installed by running
$conda list cudatoolkit 10.0.130 hf841e97_10 conda-forge cudnn 7.6.5.32 ha8d7eb6_1 conda-forge
the version seems fine with tensorflow-gpu 1.15 tensorflow-cuda
after installing the cuda with system package manager,
but there is another cudatoolkit 10 and the cudnn comes withthe tensorflow-gpu. did not restart the machine. does this matter?
2022-05-05 12:46:14.496348: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 AVX512F FMA 2022-05-05 12:46:14.520365: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2601325000 Hz 2022-05-05 12:46:14.521958: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x5565bcb72f40 initialized for platform Host (this does not guarantee that XLA will be used). Devices: 2022-05-05 12:46:14.521982: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version 2022-05-05 12:46:14.523737: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcuda.so.1 2022-05-05 12:46:14.526821: E tensorflow/stream_executor/cuda/cuda_driver.cc:318] failed call to cuInit: CUDA_ERROR_SYSTEM_DRIVER_MISMATCH: system has unsupported display driver / cuda driver combination 2022-05-05 12:46:14.526889: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:200] libcuda reported version is: 510.60.2 2022-05-05 12:46:14.526904: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:204] kernel reported version is: 495.44.0 2022-05-05 12:46:14.526916: E tensorflow/stream_executor/cuda/cuda_diagnostics.cc:313] kernel version 495.44.0 does not match DSO version 510.60.2 -- cannot find working devices in this configuration
is this because the cuda 11 installed by system not compatible with the cudatoolkit 10 by conda?

 Learn about our joint effort in porting the ILT engine to GPU. We also identify future areas for EDA and mask inspection tool vendors to address for ILT to be adopted at logic foundries.
Learn about our joint effort in porting the ILT engine to GPU. We also identify future areas for EDA and mask inspection tool vendors to address for ILT to be adopted at logic foundries.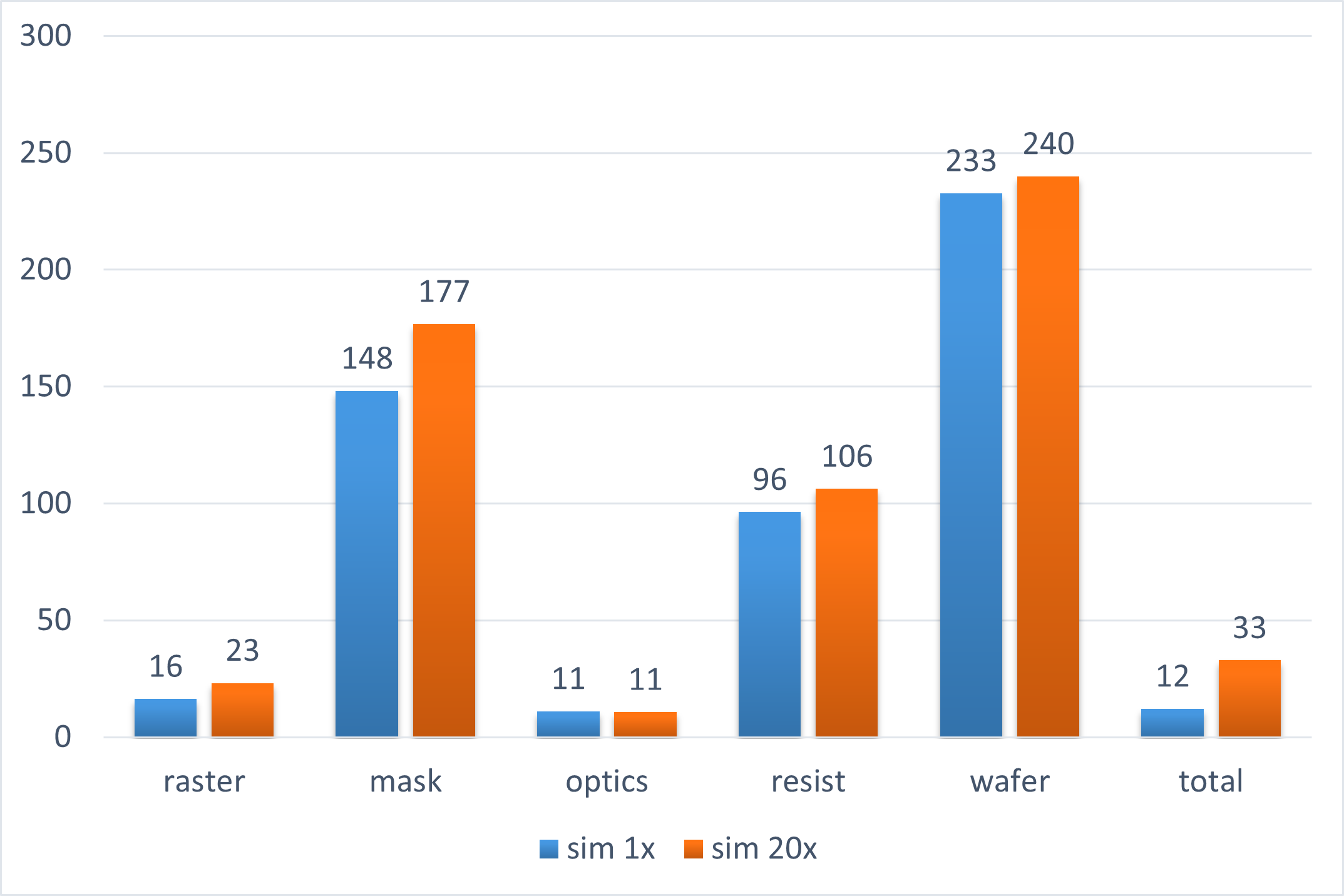
 This post details how the filesystem specification’s new parquet model provides a format-aware byte-cashing optimization.
This post details how the filesystem specification’s new parquet model provides a format-aware byte-cashing optimization.