
 We are excited to share over a dozen new and updated developer tools released today at GTC for game developers, including NVIDIA Reflex, RTXDI, and our new RTX Technology Showcase.
We are excited to share over a dozen new and updated developer tools released today at GTC for game developers, including NVIDIA Reflex, RTXDI, and our new RTX Technology Showcase.
SDK Updates For Game Developers and Digital Artists
GTC is a great opportunity to get hands-on with NVIDIA’s latest graphics technologies. Developers can apply now for access to RTX Direct Illumination (RTXDI), the latest advancement in real-time ray tracing. Nsight Perf, the next in a line of developer optimization tools, has just been made available to all members of the NVIDIA Developer Program. In addition, several exciting updates to aid game development and professional visualization were announced for existing SDKs.
REAL TIME RAY TRACING MADE EASIER
RTX Direct Illumination (RTXDI)
Imagine adding millions of dynamic lights to your game environments without worrying about performance or resource constraints. RTXDI makes this possible while rendering in real time.
Geometry of any shape can now emit light and cast appropriate shadows: Tiny LEDs. Times Square billboards. Even exploding fireballs. RTXDI easily incorporates lighting from user-generated models. And all of these lights can move freely and dynamically.
In this scene, you can see neon signs, brake lights, apartment windows, store displays, and wet roads all acting as independent light sources. All of that can now be captured in real-time with RTXDI.
RTXDI removes the limits on the amount of lights artists can put in a scene. Artists no longer have to cheat, or make painful decisions about which lights matter, and which ones don’t. They can light scenes completely unconstrained by anything but their creative vision. Developers can apply for access to RTXDI here.
RTX Global Illumination (RTXGI)
Leveraging the power of ray tracing, the RTX Global Illumination (RTXGI) SDK provides scalable solutions to compute multi-bounce indirect lighting without bake times, light leaks, or expensive per-frame costs. Version 1.1.30 allows developers to enable, disable, and rotate individual DDGI volumes. The RTXGI plugin comes pre-installed on the latest version of NVRTX, which can be found here. Developers can apply for general access to RTXGI here.

NVIDIA Real Time Denoiser (NRD)
NRD is a spatio-temporal API-agnostic denoising library that’s designed to work with low ray-per-pixel signals. In version 2.0, a high frequency denoiser (called ReLAX) has been added to support RTXDI signals. Split screen view support is included for denoised image comparisons, dynamic flow control is accessible, and checkerboard support for ReLAX and shadow denoisers have been included. Developers can apply for access here.

NVIDIA RTX Unreal Engine Branch (NvRTX)
NvRTX is a custom UE4 branch for NVIDIA technologies on GitHub. Having custom UE4 branches on GitHub shortens the development cycle, and helps make games look more stunning. NvRTX 4.26.1 includes RTX Direct Illumination with ReLAX Denoiser in preview and RTX Global Illumination. This branch is the only place to get all NVIDIA RTX technology in one place. NvRTX also includes an application for developers to experience and play with the latest RTX technology that will continue to be updated in the future. Try it for yourself here.
IMPROVING FRAME RATES AND RESPONSIVENESS INSTANTLY
Deep Learning Super Sampling (DLSS)
NVIDIA DLSS is a new and improved deep learning neural network that boosts frame rates and generates beautiful, sharp images for your games. It gives you the performance headroom to maximize ray tracing settings and increase output resolution. DLSS is powered by dedicated AI processors on RTX GPUs called Tensor Cores. It is now available as a plugin for Unreal Engine 4.26; the latest version can be found at NVIDIA Developer or Unreal Marketplace.
Unity has announced that DLSS will be natively supported in Unity Engine version 2021.2 later this year. Learn more here.
Reflex
Reflex SDK allows developers to implement a low latency mode that aligns game engine work to complete just-in-time for rendering, eliminating GPU render queue and reducing CPU back pressure. Reflex 1.4 introduces a new boost feature that further reduces latency when a game becomes CPU render thread bound. In addition, the flash indicator was added to the Unity Plugin, making it easier to begin measuring latency.
Nsight Perf SDK
Nsight Perf is a graphics profiling toolbox for DirectX, Vulkan, and OpenGL, enabling you to collect GPU performance metrics directly from your application. Profile while you’re in-application, upgrade your CI/CD, and be one with the GPU.
Nsight Perf 2021.1 is available now here.
Nsight Graphics
Nsight Graphics is a standalone developer tool that enables you to debug, profile, and export frames built with DirectX12, Vulkan, OpenGL, and OpenVR. In version 2021.2, we’re introducing Trace Analysis; a powerful new GPU Trace feature that provides developers detailed information on where in your frame you should focus on in order to improve your application’s performance. In addition to Trace Analysis, GPU trace can now show sample values in addition to percentages. We’ve also improved window docking to provide more ways for you to configure them (especially in multi-monitor setups). For captures, you can now specify which swap chain you want to use, making the Nsight Graphics easier to use on applications that have multiple windows/swap chains (such as level editors).
All of the powerful debugging and profiling features in Nsight Graphics are available for realtime ray tracing, which includes support for DXR and Vulkan Ray Tracing. Watch this short video to see how you can leverage Nsight Graphics to improve your developer productivity and ensure that your game is fast and visually breathtaking.
Nsight Systems
Nsight Systems is a system-wide performance analysis tool designed to visualize an application’s algorithms, help you identify the largest opportunities to optimize, and tune to scale efficiently across any quantity or size of CPUs and GPUs, from large servers to our smallest SoC. Version 2021.2 includes CUDA UVM CPU & GPU Page faults, Reflex SDK trace and GPU Metrics Sampling providing a system wide overview of efficiency for your GPU workloads. This expands Nsight Systems ability to profile system-wide activity and help track GPU workloads and their CPU origins. By providing a deeper understanding of the GPU utilization over multiple processes and contexts; covering the interop of Graphics and Compute workloads including CUDA, OptiX, DirectX and Vulkan ray tracing + rasterization APIs.
Download the latest version here.
CREATING AND SIMULATING PHOTO-REALISTIC GRAPHICS
OptiX
OptiX is an application framework for achieving optimal ray tracing performance on the GPU. It provides a simple, recursive, and flexible pipeline for accelerating ray tracing algorithms. Optix 7.3 enables object loading from disk, freeing up the GPU and making developers less reliant on the CPU. This update also brings improvements to denoising capabilities for objects in motion while improving the real time performance of Curves. Download OptiX today here.

NanoVDB
NanoVDB adds real-time rendering GPU support for OpenVDB. OpenVDB is the Academy Award-winning industry standard data-structure and toolset used for manipulating volumetric effects. The latest version of NanoVDB offers a significant footprint reduction to the GPU memory, freeing up resources for other tasks.

Texture Tools Exporter
Version 2021.1.1 of the NVIDIA Texture Tools Exporter brings AI-powered NGX Image Super-Resolution, initial support for the KTX and KTX2 file formats including Zstandard supercompression, resizing and high-DPI windowing, and more. You can get access to the latest version here.

Omniverse Audio2Face
NVIDIA Omniverse Audio2Face is now available in open beta. With the Audio2Face app, Omniverse users can generate AI-driven facial animation from audio sources. The beta release of Audio2Face includes the highly anticipated ‘character transfer’ feature, enabling users to retarget animation onto a custom 3D facial mesh.
Reallusion Character Creator Connector
With Character Creator 3 and Omniverse, individuals or design teams can create and deploy digital characters as task performers, virtual hosts, or citizens for simulations and visualizations.
The Connector adds the power of a full character generation system with motions and unlimited creative variations to Omniverse:
- Character Creator digital humans can be chosen from a library or custom creation can begin with highly morphable, fully-rigged bases allowing creators of all skill levels a way to easily design characters from scratch.
- Character Creator Headshot, SkinGen, and Smart Hair all allow for detailed character definition from head to toe.
- Omniverse users can transfer characters and motions from Character Creator with the Omniverse Exporter for a solution that is easy to learn and deploy digital humans for Omniverse Create and Omniverse Machinima.
This new Connector adds a complete digital human creation pipeline to any Omniverse-based application.
You can also find a lot more information about Reallusion applications and how they work with Omniverse on their website here: Creating Animated Digital Humans for Omniverse | Reallusion Character Creator & Nvidia Omniverse
Omniverse Connectors
This GTC, we unveiled a series of new Omniverse Connectors – plugins to third-party applications – including Autodesk 3ds Max, GRAPHISOFT Archicad, Autodesk Maya, Adobe Photoshop, Autodesk Revit, McNeel & Associates Rhino including Grasshopper, Trimble SketchUp, Substance Designer, Substance Painter, and Epic Games Unreal Engine 4.
Alongside this, we have a boatload of new connectors in the works, and some of the ones that will be coming soon are Blender, Reallusion Character Creator 3, SideFX Houdini, Marvelous Designer, Autodesk Motionbuilder, Paraview, OnShape, DS SOLIDWORKS, Substance Source, and many, many more.
Explore Omniverse Open Beta today – download now.
Register for free for our game development track at GTC this week.
You can also find a list of all of our game development SDKS here.
 Finding ways to improve performance and visual fidelity in your games and applications is challenging. To help during the game development process, NVIDIA has packaged and released a suite of SDKs through our branch of Unreal Engine for all developers, from independent to AAA, to harness the power of RTX.
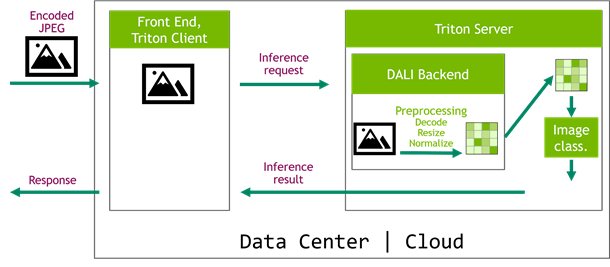
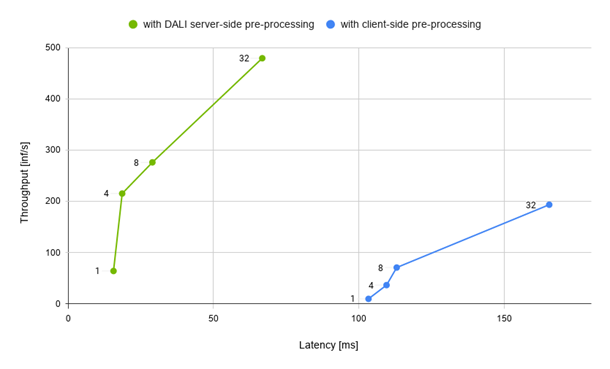
Finding ways to improve performance and visual fidelity in your games and applications is challenging. To help during the game development process, NVIDIA has packaged and released a suite of SDKs through our branch of Unreal Engine for all developers, from independent to AAA, to harness the power of RTX.  When you are working on optimizing inference scenarios for the best performance, you may underestimate the effect of data preprocessing. These are the operations required before forwarding an input sample through the model. This post highlights the impact of the data preprocessing on inference performance and how you can easily speed it up on the …
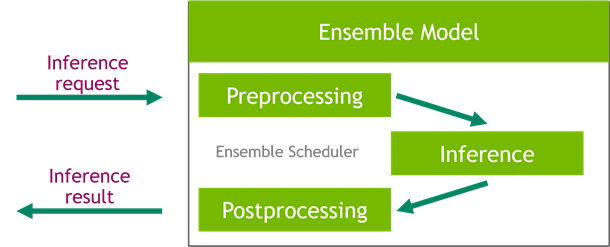
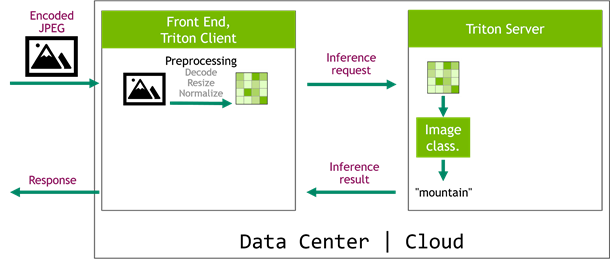
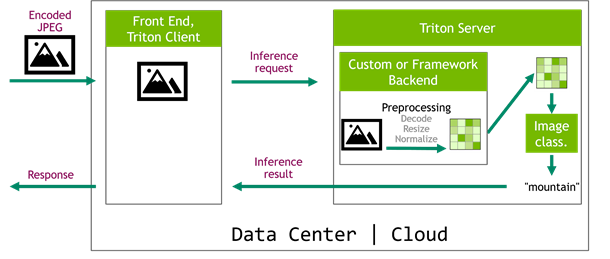
When you are working on optimizing inference scenarios for the best performance, you may underestimate the effect of data preprocessing. These are the operations required before forwarding an input sample through the model. This post highlights the impact of the data preprocessing on inference performance and how you can easily speed it up on the … 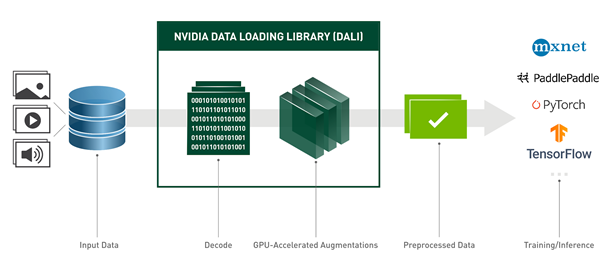
 Data science development faces many challenges in the areas of: Exploration and model development Training and evaluation Model scoring and inference Some estimates point to 70%-90% of the time is spent on experimentation – much of which will run fast and efficiently on GPU-enabled mobile and desktop workstations. Running on a Linux mobile workstation, for …
Data science development faces many challenges in the areas of: Exploration and model development Training and evaluation Model scoring and inference Some estimates point to 70%-90% of the time is spent on experimentation – much of which will run fast and efficiently on GPU-enabled mobile and desktop workstations. Running on a Linux mobile workstation, for …