The recent Taiwan Computing Cloud GPU Hackathon helped 12 teams advance their HPC and AI projects, using innovative technologies to address pressing global challenges.
The recent Taiwan Computing Cloud GPU Hackathon helped 12 teams advance their HPC and AI projects, using innovative technologies to address pressing global challenges.
While the world is continuously changing, one constant is the ongoing drive of developers to tackle challenges using innovative technologies. The recent Taiwan Computing Cloud (TWCC) GPU Hackathon exemplified such a drive, serving as a catalyst for developers and engineers to advance their HPC and AI projects using GPUs.
A collaboration between the National Center for High-Performance Computing, Taiwan Web Service Corporation, NVIDIA, and OpenACC, 12 teams and 15 NVIDIA mentors, used approaches to accelerate projects ranging from an AI-driven manufacturing scheduling model to a rapid flood prediction model.
Tapping AI to optimize production efficiency
One of the key areas of smart manufacturing is optimizing and automating production line processes. Team AI Scheduler, with members from the Computational Intelligence Technology Center (CITC) of Industrial Technology Research Center (ITRI), came to the hackathon to work on their manufacturing scheduling model using machine learning.
Traditional scheduling models mostly employ heuristic rules, which can respond to dynamic events instantly. However, their short-term approach does not often lead to the optimal solution and proves inflexible when dealing with changing variables, which limits their ongoing viability.
The team’s approach uses a Monte Carlo Tree Search (MCTS) method, combining the classic tree search implementations alongside machine learning principles of reinforcement learning. This method addresses existing heuristic limitations for improved efficiency of the overall scheduling model for improved efficiency.
Working with their mentor, Team AI Scheduler learned to use NVIDIA Nsight Systems to identify bottlenecks and use GPUs to parallelize their code. At the conclusion of the event, the team was able to accelerate the simulation step of their MCTS algorithm. This reduced the scheduling time from 6 hours to 30 minutes and achieved a speedup of 11.3x in overall scheduling efficiency.
“Having proved the feasibility of using GPUs to accelerate our model at this hackathon, the next step is to adopt it into our commercial models for industry use,” said Dr. Tsan-Cheng Su and Hao-Che Huang of CITC, ITRI.
Using GPUs to see the big picture in Earth sciences
Located between the Eurasian and the Philippine Sea Plate, Taiwan is one of the most tectonically active places in the world, and an important base for global seismological research. Geological research and the time scale of tectonic activity is often measured in units of thousands–or tens of thousands–of years. This requires the use of massive amounts of data and adequate compute power to analyze efficiently.

The IES-Geodynamics team, led by Dr. Tan from the Institute of Earth Research, Academia Sinica, came to the GPU Hackathon to accelerate their numerical geodynamical model. Named DynEarthSol, it simulates mantle convection, subduction, mountain building, and tectonics. Previously, the team handled large volumes of data by reducing the number of calculations and steps by chunking data into pieces and restricting the computing processes to fit the limited computing power of the CPU. This made it very difficult to see the full picture of the research.
Over the course of the hackathon, the team used a new data input method that leveraged the GPU to calculate the data and multiple steps. Using OpenACC, Team IES-Geodynamics was able to port 80% of their model to GPUs and achieved a 13.6X speedup.
“This is my second time attending a GPU Hackathon and I will definitely attend the next one,” said Professor Eh Tan, Research Fellow from IES, Academia Sinica. “We have learned the appropriate way to adopt GPUs and the user-friendly profiling tool gives us a great idea for how to optimize our model.”
The team will continue to work towards porting the remaining 20% of their model. They look forward to running more high-resolution models using GPUs to gain a deeper understanding of formation activities in Taiwan.
Rapid flood assessment for emergency planning and response
Flooding is among the most devastating natural disasters. Causing massive casualties and economic losses, floods affect an average of 21 million people worldwide each year with numbers expected to rise due to climate change and other factors. Preventing and mitigating these hazards is a critical endeavor.
THINKLAB, a team from National Yang Chiao University (NYCU), is working on the development of a model that can provide fast and accurate results for emergency purposes while maintaining simplicity in operation. The proposed hybrid inundation model (HIM) solves the zero-inertia equation through the Cellular Automata approach and works with subgrid-scale interpolation strategies to generate higher-resolution results.
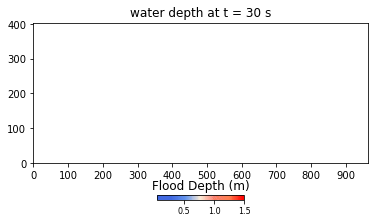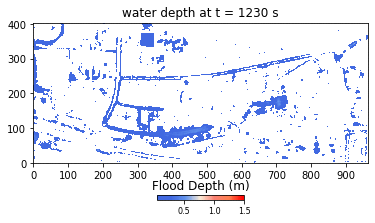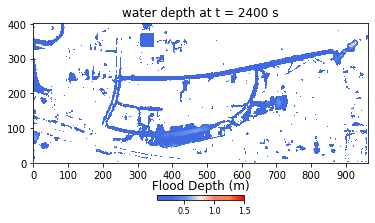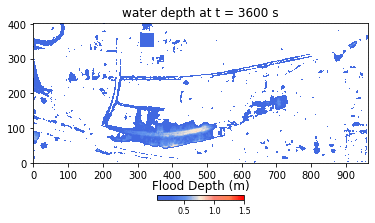
Developed using Python and NumPy libraries, the HIM model ran without parallel or GPU computations at the onset of the hackathon. During the event, Team THINKLAB used CuPy to parallelize their code to run on GPUs, then focused on applying user-defined CUDA kernels to the parameters. The result was a 672-time speedup, bringing the computation time from 2 weeks to approximately 30 minutes.
“We learned so many techniques during this event and highly recommend these events to others,” said Obaja Wijaya, team member of THINKLAB. “NVIDIA is the expert in this field and by working with their mentors we have learned how to optimize models/codes using GPU programming.”
Additional hackathons and boot camps are scheduled throughout 2022. For more information on GPU Hackathons and future events, visit https://www.gpuhackathons.org.