Hi, i am just starting with Tensorflow for my AI and i ran into an error i don’t know how to solve
[2021-09-06 21:55:50.461476: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-09-06 21:55:51.050032: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 2781 MB memory: -> device: 0, name: NVIDIA GeForce GTX 970, pci bus id: 0000:01:00.0, compute capability: 5.2
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packageskerasoptimizer_v2optimizer_v2.py:355: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
warnings.warn(
2021-09-06 21:55:51.508673: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:185] None of the MLIR Optimization Passes are enabled (registered 2)
Epoch 1/200
Traceback (most recent call last):
File “C:UsersGamereclipse-workspaceAItraining_jarvis.py”, line 69, in <module>
model.fit(np.array(training_1), np.array(training_2), epochs=200, batch_size=5, verbose=2)
File “C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packageskerasenginetraining.py“, line 1184, in fit
tmp_logs = self.train_function(iterator)
File “C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packagestensorflowpythoneagerdef_function.py”, line 885, in __call__
result = self._call(*args, **kwds)
File “C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packagestensorflowpythoneagerdef_function.py”, line 933, in _call
self._initialize(args, kwds, add_initializers_to=initializers)
File “C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packagestensorflowpythoneagerdef_function.py”, line 759, in _initialize
self._stateful_fn._get_concrete_function_internal_garbage_collected( # pylint: disable=protected-access
File “C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packagestensorflowpythoneagerfunction.py“, line 3066, in _get_concrete_function_internal_garbage_collected
graph_function, _ = self._maybe_define_function(args, kwargs)
File “C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packagestensorflowpythoneagerfunction.py“, line 3463, in _maybe_define_function
graph_function = self._create_graph_function(args, kwargs)
File “C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packagestensorflowpythoneagerfunction.py“, line 3298, in _create_graph_function
func_graph_module.func_graph_from_py_func(
File “C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packagestensorflowpythonframeworkfunc_graph.py”, line 1007, in func_graph_from_py_func
func_outputs = python_func(*func_args, **func_kwargs)
File “C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packagestensorflowpythoneagerdef_function.py”, line 668, in wrapped_fn
out = weak_wrapped_fn().__wrapped__(*args, **kwds)
File “C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packagestensorflowpythonframeworkfunc_graph.py”, line 994, in wrapper
raise e.ag_error_metadata.to_exception(e)
TypeError: in user code:
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packageskerasenginetraining.py:853 train_function *
return step_function(self, iterator)
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packageskerasenginetraining.py:842 step_function **
outputs = model.distribute_strategy.run(run_step, args=(data,))
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packagestensorflowpythondistributedistribute_lib.py:1286 run
return self._extended.call_for_each_replica(fn, args=args, kwargs=kwargs)
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packagestensorflowpythondistributedistribute_lib.py:2849 call_for_each_replica
return self._call_for_each_replica(fn, args, kwargs)
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packagestensorflowpythondistributedistribute_lib.py:3632 _call_for_each_replica
return fn(*args, **kwargs)
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packageskerasenginetraining.py:835 run_step **
outputs = model.train_step(data)
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packageskerasenginetraining.py:787 train_step
y_pred = self(x, training=True)
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packageskerasenginebase_layer.py:1037 __call__
outputs = call_fn(inputs, *args, **kwargs)
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packageskerasenginesequential.py:369 call
return super(Sequential, self).call(inputs, training=training, mask=mask)
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packageskerasenginefunctional.py:414 call
return self._run_internal_graph(
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packageskerasenginefunctional.py:550 _run_internal_graph
outputs = node.layer(*args, **kwargs)
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packageskerasenginebase_layer.py:1037 __call__
outputs = call_fn(inputs, *args, **kwargs)
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packageskeraslayerscore.py:212 call
output = control_flow_util.smart_cond(training, dropped_inputs,
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packageskerasutilscontrol_flow_util.py:105 smart_cond
return tf.__internal__.smart_cond.smart_cond(
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packagestensorflowpythonframeworksmart_cond.py:56 smart_cond
return true_fn()
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packageskeraslayerscore.py:208 dropped_inputs
noise_shape=self._get_noise_shape(inputs),
C:UsersGamerAppDataLocalProgramsPythonPython39libsite-packageskeraslayerscore.py:197 _get_noise_shape
for i, value in enumerate(self.noise_shape):
TypeError: ‘int’ object is not iterable]
I guess it’s about the model.fit line but i am not sure, for reference here is a bit of my code:
[training_1 = list(training_ai[:,0])
training_2 = list(training_ai[:,1])
model = Sequential()
model.add(Dense(128, input_shape=(len(training_1[0]),),activation=’relu’))
model.add(Dropout(0,5))
model.add(Dense(64, activation = ‘relu’))
model.add(Dropout(0,5))
model.add(Dense(len(training_2[0]),activation=’softmax’))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss=’categorical_crossenropy’, optimizer=sgd, metrics=[‘accuracy’])
model.fit(np.array(training_1), np.array(training_2), epochs=200, batch_size=5, verbose=2)]
I would be happy if you could help me with this Error



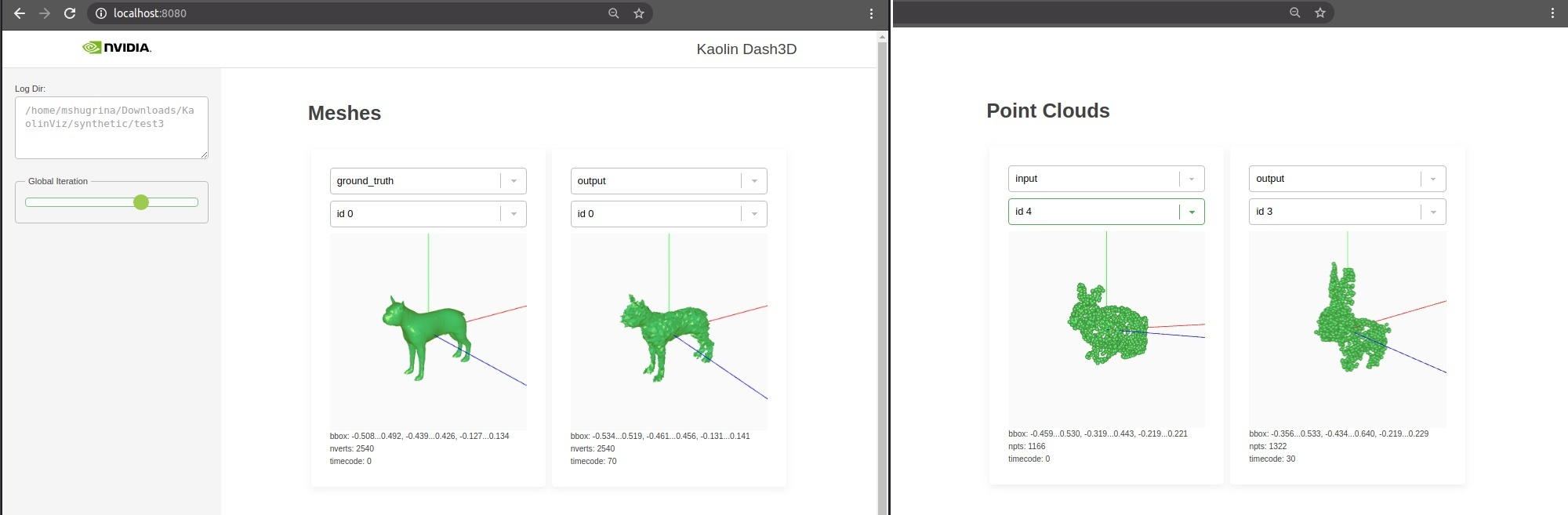
 3D deep learning researchers can build on more cutting edge algorithms and simplify their workflows with the latest version of the Kaolin PyTorch Library.
3D deep learning researchers can build on more cutting edge algorithms and simplify their workflows with the latest version of the Kaolin PyTorch Library.