Clara Parabricks now includes rapid variant annotation tools, support for tumor-only variant calling in clinical settings, and additional support on ampere GPUs.
Bioinformaticians are constantly looking for new tools that simplify and enhance genomic analysis pipelines. With over 60 tools, NVIDIA Clara Parabricks powers accurate and accelerated genomic analysis for germline and somatic workflows in research and clinical settings.
The rapid increase in sequencing data demands faster variant call format (VCF) reading and writing speeds. Clara Parabricks 3.8 expands rapid variant annotation, post-variant calling, support of custom database annotation with snpswift, and variant consequence calling with bcftools. On Clara Parabricks, snpswift provides fast and accurate VCF database annotation and leverages a wide range of databases.
Advances in sequencing technologies are amplifying the role of genomics in clinical oncology. NVIDIA Clara Parabricks now provides tumor-only calling with somatic callers LoFreq and Mutect2 for clinical cancer workflows. Tumor-normal calling is available on Parabricks with LoFreq, Mutect2, Strelka2, SomaticSniper, Muse.
Genomic scientists can further accelerate genomic analysis workflows by running Clara Parabricks with a wider array of GPU architectures, including A6000, A100, A10, A30, A40, V100, and T4. This also supports customers using next-generation sequencing instruments powered by specific NVIDIA GPUs for basecalling that want to use the same GPUs for secondary analysis with Clara Parabricks.
Expanded rapid variant annotation
In the January release of Clara Parabricks 3.7, a new variant annotation tool was added that helps provide functional information of a variant for downstream genomic analysis. This is important, as correct variant annotation can assist with final conclusions of genomic studies and clinical diagnosis.
Parabricks’ variant annotation tool, snpswift, provides fast and accurate VCF database annotation that delivers results in shorter runtimes than other community variant annotation solutions such as vcfanno. Snpswift brings more functionality and acceleration while retaining the essential functionality of accurate allele-based database annotation of VCF files. The new snpswift tool also supports annotating a VCF file with gene name data from ENSEMBL, helping to make sense of coding variants.
Supported databases include dbSNP, gnomAD, COSMIC, ClinVar, and 1000 Genomes. Snpswift can annotate these jointly to provide important information for filtering VCF variants and interpreting their significance. Additionally, snpswift is able to annotate VCFs with information from an ENSEMBL GTF to add detailed information and leverage other widely used databases in the field.
Figure 1. Clara Parabricks’ variant annotation tool snpswift provides faster, more accurate VCF database annotation than other community variant annotation tools such as vcfanno
In addition to these widely used databases, many research institutions and companies have their own rich internal datasets, which can provide valuable domain-specific information for each variant.
Snpswift in Clara Parabricks 3.8 now annotates VCFs with multiple custom TSV databases. Snpswift is also able to annotate a 6 million variant HG002 VCF with a custom TSV containing 500K variants in less than 30 seconds. Users are able to annotate VCFs with VCF, GTF, and TSV databases jointly—all with one command and in one run.
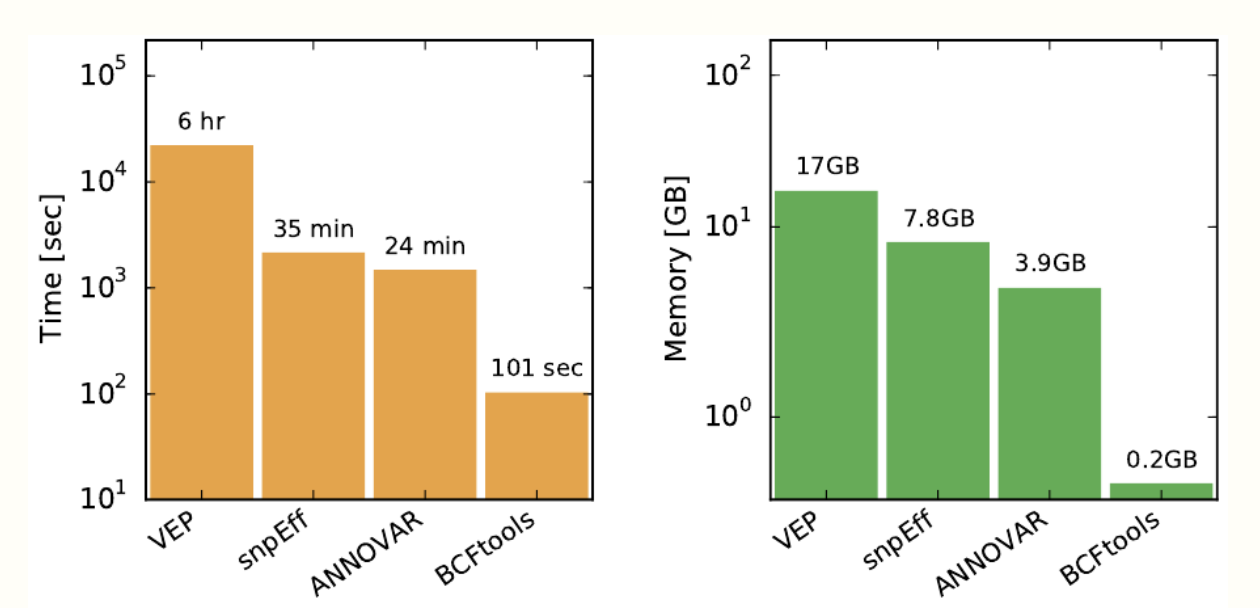
Finally, Clara Parabricks 3.8 has included consequence prediction. Predicting the functional outcome of a variant is a vital step in annotation for categorization and prioritization of genetic variants. Parabricks 3.8 offers a bcftoolscsq command that wraps the well known and extremely fast bcftools csq tool, providing haplotype-aware consequence predictions. This leads to phasing of variants in a VCF file to avoid common errors when variants affect the same codon.
Figure 2. Image taken from this Consequence Calling GitHub link. Performance comparison of BCFtools/csq with three popular consequence callers using a single-sample VCF with 4.5M sites
Clara Parabricks has demonstrated 60x acceleration for state-of-the-art bioinformatics tools compared to CPU-based environments. End-to-end analysis of whole-genome workflows runs in 22 minutes and exome workflows in just 4 minutes. Large-scale sequencing projects and other whole-genome studies are able to analyze over 60 genomes a day on a single DGX server while reducing associated costs and generating more useful insights than ever before.
To get started on NVIDIA Clara Parabricks for your germline, cancer, and RNA-Seq analysis workflows, try a free 90-day trial. You can access Clara Parabricks on premise or in the cloud with AWS Marketplace.
An overview of how to annotate variants with Parabricks 3.8 and run consequence prediction using example data is available here as a GitHub Gist.
I have adapted this autoencoder code from one of the tutorials and is as below. I am training the network on mnist images.
I found while experimenting with the network that model.fit() fires encoder-decoder network twice; even when the number of training sample is just 1 and number of epochs selected is also 1 with batch_size is None
import numpy as np import tensorflow as tf import tensorflow.keras as k import matplotlib.pyplot as plt from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, UpSampling2D # seed values np.random.seed(111) tf.random.set_seed(111)
# Encoder Network class Encoder(k.layers.Layer): def __init__(self): super(Encoder, self).__init__() self.conv1 = Conv2D(filters=32, kernel_size=3, strides=1, activation = 'relu', padding='same') self.conv2 = Conv2D(filters=32, kernel_size=3, strides=1, activation='relu', padding='same') self.conv3 = Conv2D(filters=16, kernel_size=3, strides=1, activation='relu', padding='same') self.pool = MaxPooling2D(padding='same') def call(self, input_features): x = self.conv1(input_features) x = self.pool(x) x = self.conv2(x) x = self.pool(x) x = self.conv3(x) x = self.pool(x) return x # Decoder Network class Decoder(k.layers.Layer): def __init__(self): super(Decoder, self).__init__() self.conv1 = Conv2D(filters=16, kernel_size=3, strides=1, activation='relu', padding='same') self.conv2 = Conv2D(filters=32, kernel_size=3, strides=1, activation='relu', padding='same') self.conv3 = Conv2D(filters=32, kernel_size=3, strides=1, activation='relu', padding='valid') self.conv4 = Conv2D(filters = 1, kernel_size=3, strides=1, activation='softmax', padding='same') self.upsample = UpSampling2D(size=(2,2)) def call(self, encoded_features): x = self.conv1(encoded_features) x = self.upsample(x) x = self.conv2(x) x = self.upsample(x) x = self.conv3(x) x = self.upsample(x) x = self.conv4(x) return x # Autoencoder Network class Autoencoder(k.Model): def __init__(self): super(Autoencoder, self).__init__() self.encoder = Encoder() self.decoder = Decoder() def call(self, input_features): print("Autoencoder call") encode = self.encoder(input_features) decode = self.decoder(encode) return decode
Train the model
model = Autoencoder() model.compile(loss='binary_crossentropy', optimizer='adam') sample = np.expand_dims(x_train[1], axis=0) sample_noisy = np.expand_dims(x_train_noisy[1], axis=0) print("shape of sample: {}".format(sample.shape)) print("shape of sample_noisy: {}n".format(sample_noisy.shape)) loss = model.fit(x=sample_noisy, y=sample, epochs=1)
I am training the model on only one sample for only 1 iteration. However, the print statements shows that my autoencoder.call() function is getting called twice.
I have trained a model on my computer using the YoloV5 algorithm and I was trying to run it on my Raspberry Pi. It was a classification model and I converted the model from .pt to .tflite. Unfortunately, when I run it, it tells me the index is out of range. Did I convert the file wrong? My labels file has the right amount of classes…
I load a really big image. I then downscale the image, and feed it to keras, who’s gonna perform filter = model.predict(image) on it. I then wanna take the results of model.predict(image) and be able to use it as a filter, i could apply to the original image
I want to do this since i have plenty of power for a 4k or even 6k image, but larger than that, and the model starts to struggle. But applying a 6k filter on a 8k, 10k or even 12k image doesn’t really affect the results at all (tested with good ol’ photoshop) So performing model.predict(image) on a lower res version, would save RAM, computational power, and a lot of time 🙂
Libraries and drivers are not one and the same. This blog explains which is the best for your need to clear up any confusion.
The NVIDIA DOCA Software framework includes everything needed to program the NVIDIA BlueField data processing unit (DPU) and provides a consistent experience regardless of the development environment. NVIDIA offers the following resources:
Developer Program
SDK manager support
A compilation of tools:
Compilers
Benchmarks
API reference and programmer’s guides
Reference applications
Use cases
NVIDIA delivers the stack by offering a DOCA SDK for developers and DOCA runtime software for out-of-the-box deployment.
DOCA drivers or DOCA libraries?
The DOCA drivers and DOCA libraries are critical pieces for developers, IT security and operations teams, and IT administrators. They are used to develop and deploy software-defined and hardware-accelerated applications for DPUs. However, I sometimes receive questions about the correct one to use.
To ensure that there is no confusion and to determine which might be best for your development needs, I’ve written this post to discuss when to use which.
DOCA drivers
DOCA libraries
Hardware-accelerated
Yes
Yes
Code management
Fine-grained control
Implicit initialization and unified APIs
Coding complexity
High complexity
Simplified, with programming guides
License
Mostly open source
DOCA
Multi-generation compatibility
Limited
Supported
Per-use case logic
Developers’ responsibility
Built-in
Reference applications
Partially available
Available for every library
Performance
Optimized
Maximized
Scale
Component dependent
Maximized
Table 1. DOCA drivers vs. DOCA libraries
Table 1 compares drivers and libraries and emphasizes the pros and cons of each. Essentially, DOCA drivers provide more room for customization, while DOCA libraries are architected to provide the best per-use case performance and scale with lower coding complexity.
DOCA libraries
First, DOCA libraries are higher-level abstraction APIs tuned for specific use cases. Libraries can be used to achieve outstanding performance with quicker development times and time-to-market. They also include a variety of guides and sample applications that provide a shorter learning curve than DOCA drivers when used for development.
NVIDIA libraries have been pre-accelerated. They enable you to build various applications quickly, with significant performance gains, as the logic has been created and tuned for designated use cases. They also ensure multi-generation compatibility, which can’t be guaranteed when using DOCA drivers.
The libraries aim to address a specific use case, such as a firewall, gateway, or storage controller. They use PMD and DPDK and contain additional functionality and logic that doesn’t exist within DPDK or at the driver level.
For example, if you use RegEx to identify complex string patterns for deep packet inspection (DPI), the DOCA DPI library includes preprocessing (packet header parsing) and post-processing routines to make it easier to use the RegEx accelerator to provide actions on network packets. The DPDK RegEx API does not include any of this. The DOCA DPI library API is abstracted and easier to develop packet inspection routines with, as there is no need to understand the logic.
DOCA libraries enable you to choose the preferred APIs with built-in hardware acceleration. The current revision of DOCA 1.3 includes over 120 DOCA APIs:
These services are available through the NGC Catalog and are deployable on BlueField DPUs in minutes.
The libraries’ value is delivered through a runtime environment, DOCA services, and an expansive set of documentation. The typical library user is not expected to develop applications but rather to leverage existing applications and services from NVIDIA or third parties.
DOCA services are containerized drivers and libraries made up of multiple items that can run as a service to provide specific functionality. Each service offers different capabilities, such as the DOCA telemetry API, which can be pulled in minutes from the NGC catalog. It provides a fast and convenient way to collect user-defined data and transfer it to DOCA telemetry service (DTS).
In addition, the API offers several built-in outputs for user convenience, including saving data directly to storage, NetFlow, Fluent Bit forwarding, and Prometheus endpoint.
Each of these libraries share objects and are not tied in any way except that they each use the PMD driver. Similarly, each has a common infrastructure, and each has its own documentation and programmer’s guide.
DOCA drivers and DOCA SDK
Although libraries eliminate low-level programming, they may not support all features and functionality that you are looking for, so NVIDIA offers DOCA drivers. DOCA drivers are open source-based and provide more flexibility if you’re developing yourown solutions or must create a unique solution.
NVIDIA drivers are designed for developers and are delivered through the DOCA SDK. The SDK includes all the components required to create and build applications, including reference application sources, development tools, documentation, and the NVIDIA SDK manager. The SDK manager enables the quick deployment of the development environment and can also flash and install an image to a local DPU.
The developer container enables the development of DOCA-accelerated applications anywhere. You don’t have to do this on the Arm processors on the DPU. On a host with the physical DPU, you can do this in a developer container, which emulates the Arm processor. NVIDIA provides detailed documentation, examples, and API compatibility.
The DOCA SDK is the most efficient way for you to leverage the DOCA libraries and drivers and create unique and personalized software to meet your application development needs.
The DOCA runtime is also available for you to verify and test your applications.
DOCA Runtime
If you’re unready or unable to port your application to the Arm architecture, NVIDIA provides the DOCA runtime for x86. In this case, a gRPC client runs on the DPU and establishes a communications channel with the x86 runtime. The application can access DPU runtime components, and you don’t have to compile any Arm code.
DOCA simplifies the programming and application development for BlueField DPUs and removes obstacles by providing a higher level of abstraction. By providing runtime binaries and high-level APIs, the DOCA framework enables you to focus on application code rather than learning.
There are two development routes you can choose: through libraries and services or through an SDK and drivers. Currently, the DOCA software stack includes over 120 DOCA APIs that are being used by more than 2500 DOCA developers worldwide. They are available through the NGC Catalog.
If you are new to DOCA, NVIDIA offers a complimentary, self-paced course, Introduction to DOCA for DPUs. It covers the essentials of the DOCA platform.
I hope I’ve cleared up any confusion and I encourage you to start your development journey by joining the DOCA developer program today.
For more information, see the following resources:
NVIDIA Holoscan for HPC brings AI to edge computing. Streaming Reactive Framework will be released in June to simplify code changes to stream AI for instrument processing workflows.
Scientific instruments are being upgraded to deliver 10–100x more sensitivity and resolution over the next decade, requiring a corresponding scale-up for storage and processing. The data produced from these enhanced instruments will reach limits that Moore’s law cannot adequately address and it will challenge traditional operating models solely based upon HPC in data centers.
Introducing the NVIDIA Holoscan platform for HPC Edge
The NVIDIA Holoscan platform has expanded to meet the specific needs of DevOps engineers, performance engineers, data scientists, and researchers working at these incredible edge instruments.
Modern real-time, edge AI applications are increasingly becoming multimodal. They involve high-speed IO, vision AI, imaging AI, graphics, streaming technologies, and more. Creating and maintaining these applications is extremely difficult. Scaling them is even harder.
NVIDIA is building the Streaming Reactive Framework (SRF) to address these challenges.
Figure 1. NVIDIA Holoscan for HPC workflow
While it was initially targeted at healthcare, Holoscan is a universal computation and imaging platform built for high performance while meeting the Size-Weight-and-Power (SWaP) constraints at the edge.
Now, the Holoscan platform has been extended, thanks to an easy-to-use software framework that maximizes developer productivity by ensuring maximum streaming data performance and computation. The platform is cloud-native and supports hybrid computing and data pipelining between edge locations and data centers. It is also architected for scalability, using network-aware optimizations and asynchronous computation.
The extended Holoscan platform delivers a flexible software stack that can run on embedded devices based on the NVIDIA Jetson AGX Xavier or Jetson AGX Orin. There is also a cloud-native version that runs on common high-performance hardware to accelerate data analysis and visualization workflows at the edge.
Introducing the NVIDIA Streaming Reactive Framework
The finest minds in HPC and AI research are continuously developing faster and better algorithms to solve today’s most challenging problems. However, many developers find it challenging to port their models and codes to full-rate production, particularly when faced with high-rate streaming input and strict throughput and latency requirements.
An effective solution requires a myriad of skill sets: talent coming from data scientists to performance engineers while spanning multiple software languages, hardware and software architectures, localities, and scaling rules. As a result, NVIDIA created the streaming reactive framework (SRF) to ease the research-to-production burden while maintaining speed-of-light performance.
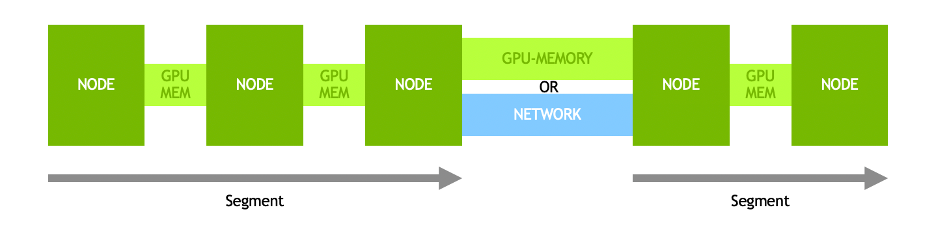
Figure 2. Within Holoscan, the HPC streaming data pipelines are standardized, using SRF, for building a modular and reusable pipeline for sensor data
NVIDIA SRF is a network-aware, flexible, and performance-oriented streaming data framework that standardizes and simplifies cloud-to-edge production HPC and AI deployments for C++ and Python developers alike.
When you build an NVIDIA SRF pipeline, specify the application data flow. along with scaling and placement logic. The placement logic dictates what hardware a data flow runs, and the scaling logic expresses how many parallel copies are needed to meet performance requirements.
NVIDIA SRF easily integrates with both C++ and Python code along with the NVIDIA catalog of domain-specific SDKs.
NVIDIA SRF is still in its experimental phase and is under active development. You can download NVIDIA SRF on GitHub in mid-June 2022.
AI for visualization and imaging
NVIDIA Orin, a low-power system-on-chip based on the NVIDIA Ampere architecture, set new records in AI inference, raising the bar in per-accelerator performance at the edge. It ran up to 5x faster than the previous generation Jetson AGX Xavier, while delivering an average of 2x better energy efficiency.
Jetson AGX Orin is a key ingredient in Holoscan for HPC and NVIDIA Clara Holoscan, a platform system makers and researchers are using to develop next-generation AI instruments. Its powerful computation capabilities for imaging and its versatile software stack makes it appealing to HPC edge use cases involving visualization and imaging.
With its JetPack SDK, Orin runs the full NVIDIA AI platform, a software stack already proven in the data center and the cloud. It is backed by a million developers using the NVIDIA Jetson platform.
The Advanced Photon Source (APS) at the US Department of Energy’s Argonne National Laboratory produces ultrabright, high-energy photon beams. The photons are 100 billion times brighter than a standard hospital X-ray machine and can capture images at the nano and atomic scale. With its APS-U upgrade in 2024, it will be able to generate photons that are up to 500x brighter than the current machine.
The Diamond Light Source at Oxford is a world-class synchrotron facility and is upgrading its brightness and coherence, up to 20 times, across existing beamlines plus five new flagship beamlines. Data rates from Diamond are already petabytes per month and, with Diamond-II, are expected to be at least an order of magnitude greater.
Worldwide, there are over 50 advanced light sources supporting the work of more than 16,000 researcher scientists and there are many more upgrades occurring at these instruments as well. While all these advancements are remarkable in their own accord, they are dependent on computational and data scientists to be ready with their AI-enabled data processing applications running on supercomputers at the edge.
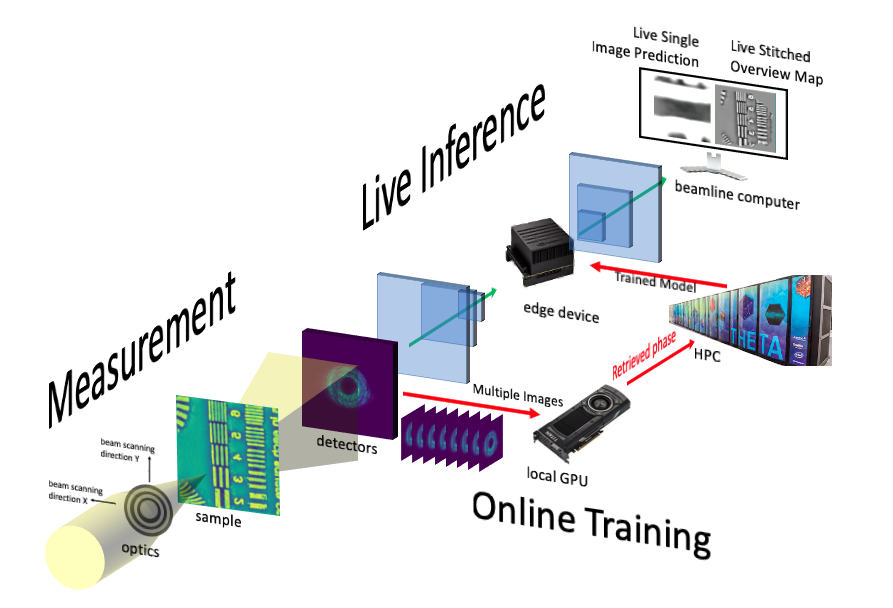
PtychoNN: The APS edge computing platform
The APS is a machine about the size of a football field that produces photon beams. The beams are used to study materials, physics, and biological structures.
Today, one way of generating images of a material with nanoscale resolution is ptychography, a computationally intensive method to convert scattered X-ray interference patterns into images of the actual object.
To date, the method requires solving a challenging inverse problem, namely using forward and inverse Fourier transforms to iteratively compute the image of the object from the diffraction patterns observed in tens of thousands of X-ray measurements. Scientists wait for days just to get the experiment image results.
Now, with AI, scientists can bypass much of the inversion process and view images of the object while the experiment is running, even potentially making adjustments on-the-fly.
With AI, APS scientists were able to use a streaming ptychography pipeline, accelerated by a deep convolutional neural network model, PtychoNN, to speed up image processing by over 300x and reduce the data required to produce high-quality images by 25x.
Figure 3. Train the PtychoNN model at the data center on A100s and deploy the trained AI model at the beamline instrument with AGX Orin running PtychoNN to stream images 300x faster
The PtychoNN model is trained on NVIDIA A100 Tensor Core GPUs with deep learning and X-ray image phase-retrieval data. The trained model can run on an edge appliance to directly map the incoming diffraction images to images of the object in real space and in real time in only milliseconds.
Faster sampling means more productive use of the instrument, delivering opportunities to investigate more materials. It provides capabilities not possible before, such as looking at biological materials samples that were damaged in the X-ray beam, samples that are changing rapidly, or samples that are large compared to the size of the X-ray beam.
A common hardware and software architecture simplifies orchestration with NVIDIA AGX at the edge and clusters of A100 GPUs in the data center. The solution is easily extensible to keep up with the 125x increase in data rate expected at the APS. The increase is expected from a detector upgrade in 2022 and a facility upgrade in 2024.
“In order to make full use of what the upgraded APS will be capable of, we have to reinvent data analytics. Our current methods are not enough to keep up. Machine learning can make full use and go beyond what is currently possible.”
Mathew Cherukara, Argonne National Laboratory Computational Scientist
In the example earlier, a single GPU edge device accelerates a stream of images using a trained neural network. Turnaround times for edge experiments that took days can now take fractions of a second, providing researchers with real-time interactive use of their large-scale scientific instruments. For more information about other relevant HPC and AI at the edge examples, see the following resources:
While many of our highlighted edge HPC applications are focused on streaming video and imaging pipelines, NVIDIA Holoscan can be extended to other sensor types with a variety of data formats and rates. Whether you are performing high-bandwidth spectrum analysis with a software-defined radio or monitoring telemetry from a power grid for anomalies, NVIDIA Holoscan is the platform of choice for software-defined instruments.
By focusing on developer productivity and application performance regardless of the sensor, HPC at the edge can provide real-time analytics and mission success.
Featured image courtesy of US Department of Energy’s Argonne National Laboratory, Advanced Photon Source (APS)
Celebrate the onset of summer this GFN Thursday with 25 more games joining the GeForce NOW library, including seven additions this week. Because why would you ever go outside? Looking to spend the summer months in Space Marine armor? Games Workshop is kicking off its Warhammer Skulls event for its sixth year, with great discounts Read article >

 Clara Parabricks now includes rapid variant annotation tools, support for tumor-only variant calling in clinical settings, and additional support on ampere GPUs.
Clara Parabricks now includes rapid variant annotation tools, support for tumor-only variant calling in clinical settings, and additional support on ampere GPUs.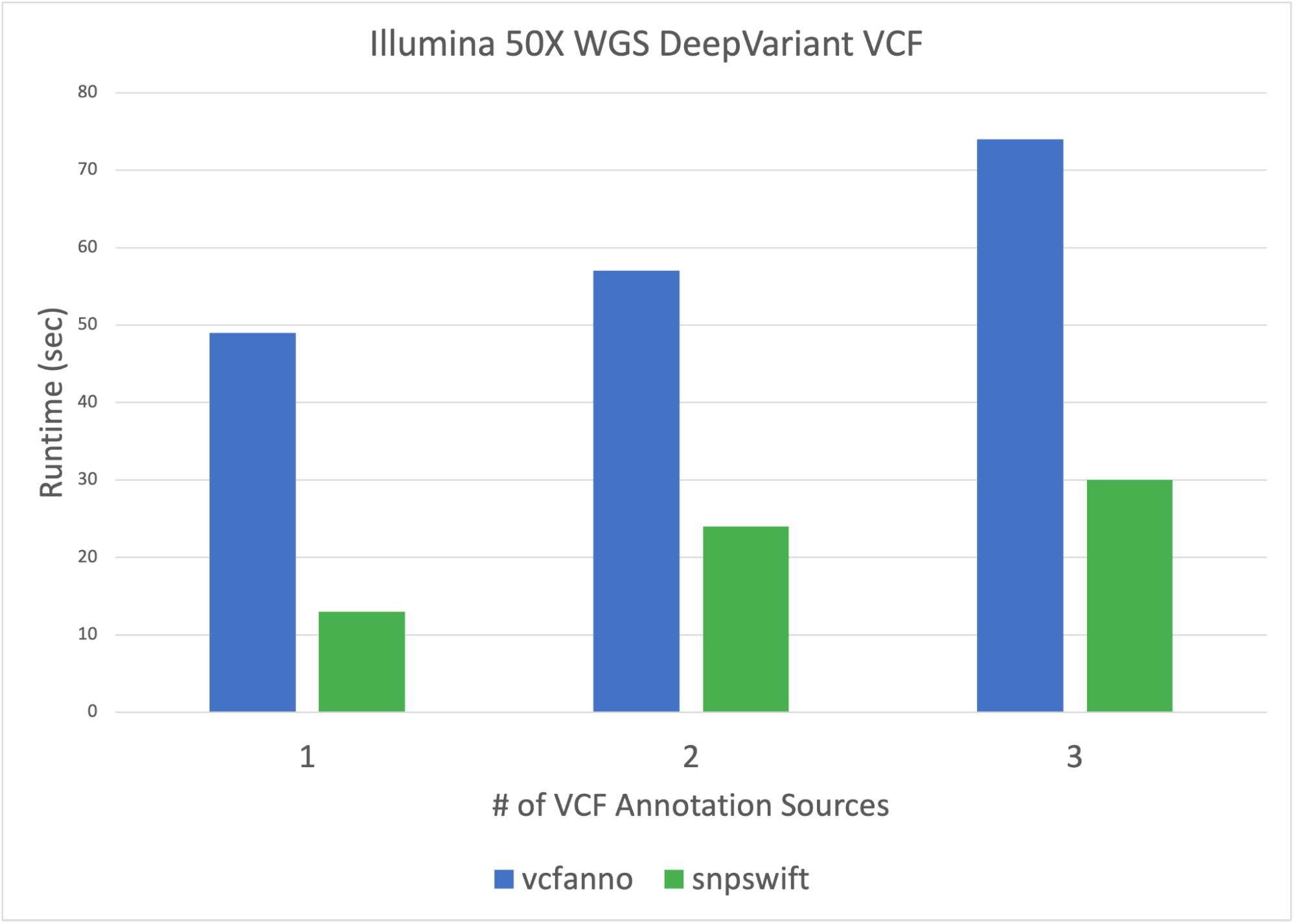
 Libraries and drivers are not one and the same. This blog explains which is the best for your need to clear up any confusion.
Libraries and drivers are not one and the same. This blog explains which is the best for your need to clear up any confusion.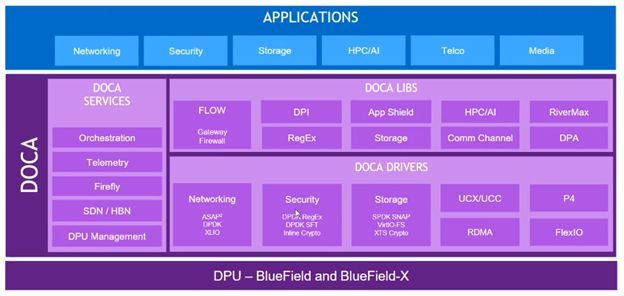
 NVIDIA Holoscan for HPC brings AI to edge computing. Streaming Reactive Framework will be released in June to simplify code changes to stream AI for instrument processing workflows.
NVIDIA Holoscan for HPC brings AI to edge computing. Streaming Reactive Framework will be released in June to simplify code changes to stream AI for instrument processing workflows.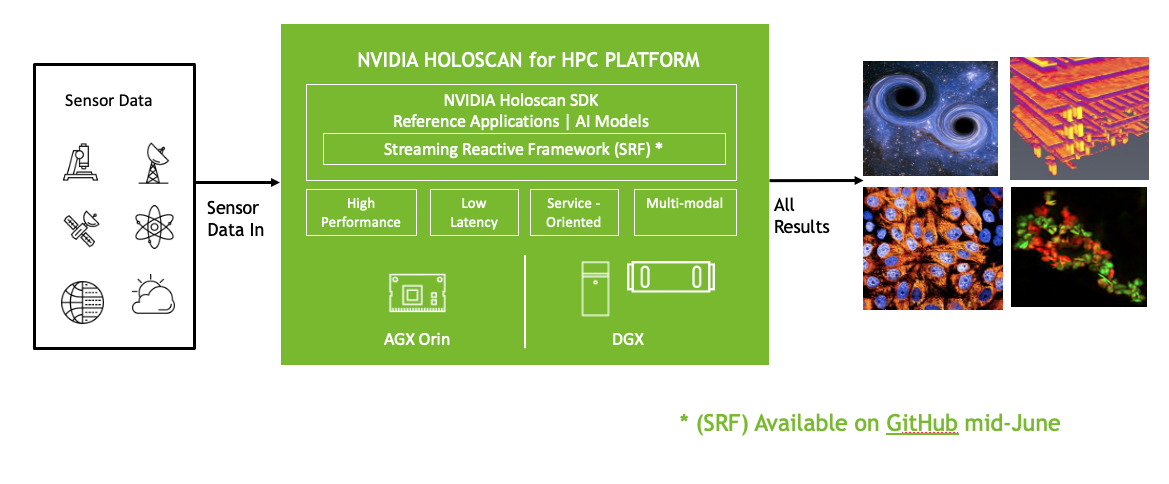
 Join this webinar on June 7 to learn how Aria Cybersecurity and NVIDIA are stopping modern security attacks in real time at demanding network speeds.
Join this webinar on June 7 to learn how Aria Cybersecurity and NVIDIA are stopping modern security attacks in real time at demanding network speeds.