NVIDIA recently released Clara Train 4.0, an application framework for medical imaging that includes pre-trained models, AI-Assisted Annotation, AutoML, and Federated Learning. In this 4.0 release, there are three new features to help get you started training quicker.
NVIDIA recently released Clara Train 4.0, an application framework for medical imaging that includes pre-trained models, AI-Assisted Annotation, AutoML, and Federated Learning. In this 4.0 release, there are three new features to help get you started training quicker.
Clara Train has upgraded its underlying infrastructure from TensorFlow to MONAI. MONAI is an open-source, PyTorch-based framework that provides domain-optimized foundational capabilities for healthcare. By leveraging MONAI, users now have access to a comprehensive list of medical image–specific transformations and reference networks. Clara Train has also updated its DeepGrow model to work on 3D CT images. This updated model gives you the ability to segment an organ in 3D with only a few clicks across the organ.
Expanding into Digital Pathology, Clara Train helps users navigate these new workloads by providing a Digital Pathology pipeline that includes data loading and training optimizations. These data loading optimizations involve using the new cuCIM library included in RAPIDS.
Clara Train 4.0 continues to improve on its Federated Learning framework by adding homomorphic encryption tools. Homomorphic encryption allows you to compute data while the data is still encrypted. It can play an important role in healthcare in ensuring that patient data stays secure at each hospital while still benefiting from using federated learning with other institutions.
To learn more about these new features, check out our Clara Train 4.0 features highlight video below or the latest blog posts which includes a walkthrough of how you can Bring-Your-Own-Components to Clara Train.
Download Clara Train 4.0 from NGC, and try out the newly updated Jupyter notebooks on GitHub.
Banks use AI to determine whether to extend credit, and how much, to customers. Radiology departments deploy AI to help distinguish between healthy tissue and tumors. And HR teams employ it to work out which of hundreds of resumes should be sent on to recruiters. These are just a few examples of how AI is Read article >
The regular RNN layers feedback to themselves. Instead, I want to create a network where I can connect a latter layer across multiple layers to a previous one.
Hey guys! So my research professor wants me to construct a notebook that uses image data alongside genetic data in segmentation. I’ve already constructed a segmentation model that runs fine, and I have all of the genetic data in a dataframe – I was wondering how I’d go about incorporating that into the model
I’m benchmarking a model in a controlled environment (docker container with 1 CPU and 4GB RAM).
Running 100 inferences on SATRN model with batch size 1 takes on average 1.26 seconds/inference using the TFLite model and 0.86 seconds /inference using the SavedModel.
Is it expected? What would explain the performance difference?
Introduction The RAPIDS Forest Inference Library, affectionately known as FIL, dramatically accelerates inference (prediction) for tree-based models, including gradient-boosted decision tree models (like those from XGBoost and LightGBM) and random forests. (For a deeper dive into the library overall, check out the original FIL blog.) Models in the original FIL are stored as dense binary … Continued
This post was originally published on the RAPIDS AI Blog.
Introduction
The RAPIDS Forest Inference Library, affectionately known as FIL, dramatically accelerates inference (prediction) for tree-based models, including gradient-boosted decision tree models (like those from XGBoost and LightGBM) and random forests. (For a deeper dive into the library overall, check out the original FIL blog.) Models in the original FIL are stored as dense binary trees. That is, the storage of the tree assumes that all leaf nodes occur at the same depth. This leads to a simple, runtime-efficient layout for shallow trees. But for deep trees, it also requires a lot of GPU memory 2d+1-1 nodes for a tree of depth d. To support even the deepest forests, FIL supports
sparse tree storage. If a branch of a sparse tree ends earlier than the maximum depth d, no storage will be allocated for potential children of that branch. This can deliver significant memory savings. While a dense tree of depth 30 will always require over 2 billion nodes, the skinniest possible sparse tree of depth 30 would require only 61 nodes.
Using Sparse Forests with FIL
Using sparse forests in FIL is no harder than using dense forests. The type of forest created is controlled by the new storage_type parameter to ForestInference.load(). Its possible values are:
DENSE to create a dense forest,
SPARSE to create a sparse forest,
AUTO (default) to let FIL decide, which currently always creates a dense forest.
There is no need to change the format of the input file, input data or prediction output. The initial model could be trained by scikit-learn, cuML, XGBoost, or LightGBM. Below is an example of using FIL with sparse forests.
from cuml import ForestInference
import sklearn.datasets
# Load the classifier previously saved with xgboost model_save()
model_path = 'xgb.model'
fm = ForestInference.load(model_path, output_class=True,
storage_type='SPARSE')
# Generate random sample data
X_test, y_test = sklearn.datasets.make_classification()
# Generate predictions (as a gpu array)
fil_preds_gpu = fm.predict(X_test.astype('float32'))
Implementation
Figure 1: Storing sparse forests in FIL.
Figure 1 depicts how sparse forests are stored in FIL. All nodes are stored in a single large nodes array. For each tree, the index of its root in the nodes array is stored in the trees array. Each sparse node, in addition to the information stored in a dense node, stores the index of its left child. As each node always has two children, left and right nodes are stored adjacently. Therefore, the index of the right child can always be obtained by adding 1 to the index of the left child. Internally, FIL continues to support dense as well as sparse nodes, with both approaches deriving from a base forest class.
Compared to the internal changes, the changes to the Python API have been kept to a minimum. The new storage_type parameter specifies whether to create a dense or sparse forest. Additionally, a new value,'AUTO', has been made the new default for the inference algorithm parameter; it allows FIL to choose the inference algorithm itself. For sparse forests, it currently uses the'NAIVE'algorithm, which is the only one supported. For dense forests, it uses the'BATCH_TREE_REORG' algorithm.
Benchmarks
To benchmark the sparse trees, we train a random forest using scikit-learn, specifically,sklearn.ensemble.RandomForestClassifier. We then convert the resulting model into a FIL forest and benchmark the performance of inference. The data is generated using sklearn.datasets.make_classification(), and contains 2 million rows split equally between training and validation dataset, and 32 columns. For benchmarking, inference is performed on 1 million rows.
We use two sets of parameters for benchmarking.
With the depth limit, set to either 10 or 20; in this case, either a dense or sparse FIL forest can fit into GPU memory.
Without depth limit; in this case, the model trained by SKLearn contains really deep trees. In our benchmark runs, the trees usually have a depth between 30 and 50. Trying to create a dense FIL forest runs out of memory, but a sparse forest can be created smoothly.
In both cases, the size of the forest itself remains relatively small, as the number of leaf nodes in a tree is limited to 2048, and the forest consists of 100 trees. We measure the time of the CPU inference and the GPU inference. The GPU inference was performed on V100, and the CPU inference was performed on a system with 2 sockets, each with 16 cores with 2-way hyperthreading. The benchmark results are presented in Figure 2.
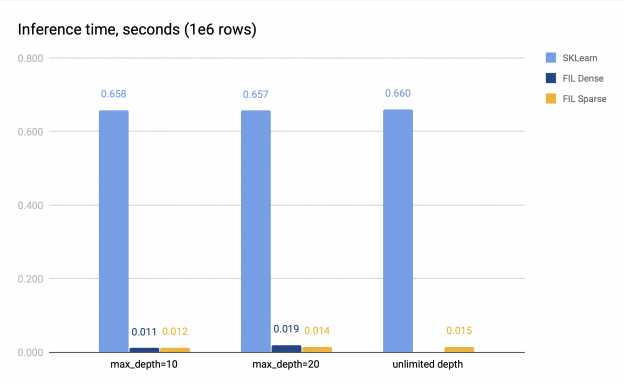
Figure 2: Benchmark results for FIL (dense and sparse trees) and SKLearn.
Both sparse and dense FIL predictors (if the latter is available) are about 34–60x faster than the SKLearn CPU predictor. The sparse FIL predictor is slower compared to the dense one for shallow forests, but can be faster for deeper forests; the exact performance difference varies. For instance, in Figure 2 with max_depth=10, the dense predictor is about 1.14x faster than the sparse predictor, but with max_depth=20, it is slower, achieving only 0.75x speed of the sparse predictor. Therefore, the dense FIL predictor should be used for shallow forests.
For deep forests, however, the dense predictor runs out of memory, as its space requirements grow exponentially with the forest depth. The sparse predictor does not have this problem and provides fast inference on the GPU even for very deep trees.
Conclusion
With sparse forest support, FIL applies to a wider range of problems. Whether you’re building gradient-boosted decision trees with XGBoost or random forests with cuML or scikit-learn, FIL should be an easy drop-in option to accelerate your inference. As always, if you encounter any issues, feel free to file issues on GitHub or ask questions in our public Slack channel!
as my output, and while when I define the model, I see that the majority of my GPU memory is being used (specifically 7.6/8GB), when i try training it, all of the memory just instantly disappears, as if there never was a model.
NVIDIA’s GPU Technology Conference is a hotbed for sharing groundbreaking innovations — making it the perfect forum for developers, students and professionals from underrepresented communities to discuss the challenges and opportunities surrounding AI. Last month’s GTC brought together virtually tens of thousands of attendees from around the world, with more than 20,000 developers from emerging Read article >
NetEase Thunder Fire Games Uses Mesh Shading To Create Beautiful Game Environments for Justice In December, we interviewed Haiyong Qian, NetEase Game Engine Development Researcher and Manager of NetEase Thunder Fire Games Technical Center, to see what he’s learned as the Justice team added NVIDIA ray-tracing solutions to their development pipeline. Their results were nothing … Continued
NetEase Thunder Fire Games Uses Mesh Shading To Create Beautiful Game Environments for Justice
In December, we interviewed Haiyong Qian, NetEase Game Engine Development Researcher and Manager of NetEase Thunder Fire Games Technical Center, to see what he’s learned as the Justice team added NVIDIA ray-tracing solutions to their development pipeline. Their results were nothing short of stunning with local 8K DLSS support and global illumination through RTXGI.
Recently, NetEase introduced Mesh Shader support to Justice. Not only are the updated environments breathtaking, the game supports 1.8 billion triangles running over 60 FPS in 4K on an NVIDIA 3060Ti.
To learn more about the implementation and results, we sat down with Yuheng Zou, game engine developer at NetEase. His work focuses on the rendering engine in Justice, specifically GPU features enabled by DirectX 12.
Q: What are you trying to achieve by adding mesh shading to Justice?
Our first thought is to render some highly detailed models which may need insane number of triangles. Soon we found we can combine Mesh Shaders with auto-generated LODs to achieve almost only-resolution-relevant rendering complexity, instead of polygon number. And we decided to try it out. With so much potential of Mesh Shader, we conceive that it would be the main stream of future games.
Q: What is not currently working with regular compute / draw indirect / traditional methods?
The simple draw call just doesn’t work for this. It lacks the ability to process mesh in a coarser grain than triangle, like meshlet culling.
Compute or draw indirect may be fine, but we do need to make a huge change on the rendering pipeline. The underlying idea of the algorithm is, in the first place, to do culling, then draw the effective parts of mesh. While it can be achieved by culling and compacting with compute shader and then drawing indirect, the data exchange between the two-step process can sometimes be fatal to GPU under highpoly rendering context. Mesh shader solves this problem from the hardware level.
Q: How do Mesh Shaders solve this?
Mesh shader can extend the scalability of geometry stage, and is very easy to integrate to engine runtime. It has the ability to encapsulate the culling procedure in a single API call, which omits tedious state and resource set up procedure as draw indirect requires. With MeshShaders, the culling algorithms we use can be of great flexibility. For example, in the shadow pass, we don’t have the depth information so occlusion culling is simply ignored in the shader.
Q: Is the end result of adding Mesh Shaders something your players will quickly notice, or is the effect more subtle?
Our technology customizes a highpoly mesh pipeline, including production, processing, serialization, streaming and rendering, aiming to provide our players with a refreshed experience with such high-fidelity contents. Actually, it works. Soon after “Wan Fo Ku” released, our players found the models presented were much more elaborate than the traditional one, with many close-up screenshots posted on the forums. While adding Mesh Shaders under customized highpoly scene do boost the rendering effectiveness, how to optimize our traditional scene remains subtle and needs more engineering efforts.
Q: What kinds of environments benefited most from the technology?
Our technology enables the ability of rendering parallax and silhouette of models in an incredible fidelity. For scenes like caves, these details can produce a visually better image. It also provides Chinese ancient buildings, furniture and ornaments with “meticulous” rendering result, which enables the culture carried by them to be expressed in Justice to the finest extent.
Q: What is the one thing you wish you knew before you added mesh shading? What would you do differently based on your learnings?
With such detailed models, large texture resolution is a must. We will pay more attention to texture loading or streaming. This also makes further requirements to our mesh/texture compression algorithms.
Q: Any other tips for developers looking to work with Mesh Shaders for the first time?
Mesh shader has the possibility of boosting geometry stage drastically. However, careful profiling and optimization is required. We highly recommend NSight for debugging and profiling Mesh Shaders.
Doing GPU culling with Mesh Shaders will sometimes require a change on mesh representation data format. A clever data format design will enable your trial and error, making a lot faster progress.
Since 2016, Justice has been closely engaged with NVIDIA in China on video game graphics technology innovation. As one of the best PC MMO games in China market, Justice has attracted thirty millions of players in the past three years with its excellent technologies and beautiful graphics.
Learn more about NVIDIA’s technical resources for Game Developers here.

 NVIDIA recently released Clara Train 4.0, an application framework for medical imaging that includes pre-trained models, AI-Assisted Annotation, AutoML, and Federated Learning. In this 4.0 release, there are three new features to help get you started training quicker.
NVIDIA recently released Clara Train 4.0, an application framework for medical imaging that includes pre-trained models, AI-Assisted Annotation, AutoML, and Federated Learning. In this 4.0 release, there are three new features to help get you started training quicker.  Introduction The RAPIDS Forest Inference Library, affectionately known as FIL, dramatically accelerates inference (prediction) for tree-based models, including gradient-boosted decision tree models (like those from XGBoost and LightGBM) and random forests. (For a deeper dive into the library overall, check out the original FIL blog.) Models in the original FIL are stored as dense binary …
Introduction The RAPIDS Forest Inference Library, affectionately known as FIL, dramatically accelerates inference (prediction) for tree-based models, including gradient-boosted decision tree models (like those from XGBoost and LightGBM) and random forests. (For a deeper dive into the library overall, check out the original FIL blog.) Models in the original FIL are stored as dense binary … 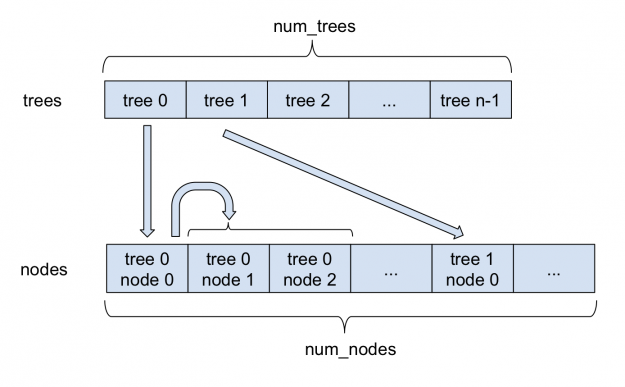
 NetEase Thunder Fire Games Uses Mesh Shading To Create Beautiful Game Environments for Justice In December, we interviewed Haiyong Qian, NetEase Game Engine Development Researcher and Manager of NetEase Thunder Fire Games Technical Center, to see what he’s learned as the Justice team added NVIDIA ray-tracing solutions to their development pipeline. Their results were nothing …
NetEase Thunder Fire Games Uses Mesh Shading To Create Beautiful Game Environments for Justice In December, we interviewed Haiyong Qian, NetEase Game Engine Development Researcher and Manager of NetEase Thunder Fire Games Technical Center, to see what he’s learned as the Justice team added NVIDIA ray-tracing solutions to their development pipeline. Their results were nothing … 

{kind=link}