Select from 20 hands-on workshops, offered at GTC, available in multiple languages and time zones. Early bird pricing of just $99 ends Aug 29 (regular $500).
Select from 20 hands-on workshops, offered at GTC, available in multiple languages and time zones. Early bird pricing of just $99 ends Aug 29 (regular $500).
We recently kicked off our NVIDIA Developer Program exclusive series of Connect with Experts Ask Me Anything (AMA) sessions featuring NVIDIA experts and Ray…
During the AMA, the editors offered some valuable guidance and tips on how to successfully integrate real-time rendering. Check out the top five questions and answers from the AMA:
1. Are there some rules of thumb one should follow when adding ray tracing (RT) applications like translucency, reflections, shadows, GI, or diffuse illumination to games?
Adam: There are many things to take into consideration when adding ray-traced effects to a game’s renderer. The main consideration to keep top of mind is for the ray-traced effects to work hand-in-hand with the goals of your game’s art direction. This will change what performance costs are reasonable for any given effect.
For example, if shadows are an important game mechanic (think of Splinter Cell), then a higher cost for extra-nice ray-traced shadows makes sense, but spending extra performance on RT translucency probably doesn’t make as much sense. For guidance on how to balance ray tracing and performance, we have a variety of webinars and other content that you can learn from. In fact, there’s an event coming up about RTX in Unreal Engine 5. (Note that you can access this content on demand.)
2. When sampling direct lighting, both reservoir sampling and resampled importance sampling can be useful techniques. But it seems difficult to recompute PDFs for the sake of MIS when a light has been sampled through a BSDF sample. Could you provide any insights into this problem?
Ingo: Sample importance resampling is only generating samples relative to an existing PDF (that you choose to take these samples). So it should be possible to evaluate that existing PDF to compute PDF values for other samples (in an MIS context).
3. Do ray tracing and deep learning overlap?
Eric: Yes, in many ways. Deep learning can be used to complement ray tracing, “filling in” missing information with plausible interpolated data, such as with NVIDIA Deep Learning Super Sampling (DLSS). This works today.
Neural rendering and neural graphics primitives are hot areas of research currently. One place to start is with Advances in Neural Rendering from SIGGRAPH 2021. Another good resource is a recent overview of NeRF at CVPR 2022, where ray tracing is used to render radiance fields.
4. What’s the latest scoop on using ML training to help with ray-traced GI? Are there any neat advances in ray tracing that benefit from deep learning? Have you connected lower sampling and filtering using an ML upscaling 2D filter?
Adam: There’s been quite a lot of work in the machine learning space to assist with real-time (and not real-time) graphics. For ray-traced global illumination, check out a paper recently published by Thomas Müller, Real-Time Neural Radiance Caching for Path Tracing. Their approach trains a neural network to learn the light transport characteristics of a scene and then builds a light cache that can be queried at a lower cost than tracing the full paths.
5. What are your top three favorite graphics papers of all time?
Register for GTC 2022 to learn the latest about RTX real-time ray tracing. For a full list of content for game developers including tools and training, visit NVIDIA Game Development.
In four talks over two days, senior NVIDIA engineers will describe innovations in accelerated computing for modern data centers and systems at the edge of the network. Speaking at a virtual Hot Chips event, an annual gathering of processor and system architects, they’ll disclose performance numbers and other technical details for NVIDIA’s first server CPU, Read article >
Graphics pioneer Dr. Donald Greenberg shares the new chapter in digital design and how NVIDIA Omniverse supports the expansion. #DigitalTwins #SIGGRAPH2022
Posted by Yutian Chen, Staff Research Scientist, DeepMind, and Xingyou (Richard) Song, Research Scientist, Google Research, Brain Team
One of the most important aspects in machine learning is hyperparameter optimization, as finding the right hyperparameters for a machine learning task can make or break a model’s performance. Internally, we regularly use Google Vizier as the default platform for hyperparameter optimization. Throughout its deployment over the last 5 years, Google Vizier has been used more than 10 million times, over a vast class of applications, including machine learning applications from vision, reinforcement learning, and language but also scientific applications such as protein discovery and hardware acceleration. As Google Vizier is able to keep track of use patterns in its database, such data, usually consisting of optimization trajectories termed studies, contain very valuable prior information on realistic hyperparameter tuning objectives, and are thus highly attractive for developing better algorithms.
While there have been many previous methods for meta-learning over such data, such methods share one major common drawback: their meta-learning procedures depend heavily on numerical constraints such as the number of hyperparameters and their value ranges, and thus require all tasks to use the exact same total hyperparameter search space (i.e., tuning specifications). Additional textual information in the study, such as its description and parameter names, are also rarely used, yet can hold meaningful information about the type of task being optimized. Such a drawback becomes more exacerbated for larger datasets, which often contain significant amounts of such meaningful information.
Today in “Towards Learning Universal Hyperparameter Optimizers with Transformers”, we are excited to introduce the OptFormer, one of the first Transformer-based frameworks for hyperparameter tuning, learned from large-scale optimization data using flexible text-based representations. While numerous works have previously demonstrated the Transformer’s strong abilities across various domains, few have touched on its optimization-based capabilities, especially over text space. Our core findings demonstrate for the first time some intriguing algorithmic abilities of Transformers: 1) a single Transformer network is capable of imitating highly complex behaviors from multiple algorithms over long horizons; 2) the network is further capable of predicting objective values very accurately, in many cases surpassing Gaussian Processes, which are commonly used in algorithms such as Bayesian Optimization.
Approach: Representing Studies as Tokens Rather than only using numerical data as common with previous methods, our novel approach instead utilizes concepts from natural language and represents all of the study data as a sequence of tokens, including textual information from initial metadata. In the animation below, this includes “CIFAR10”, “learning rate”, “optimizer type”, and “Accuracy”, which informs the OptFormer of an image classification task. The OptFormer then generates new hyperparameters to try on the task, predicts the task accuracy, and finally receives the true accuracy, which will be used to generate the next round’s hyperparameters. Using the T5X codebase, the OptFormer is trained in a typical encoder-decoder fashion using standard generative pretraining over a wide range of hyperparameter optimization objectives, including real world data collected by Google Vizier, as well as public hyperparameter (HPO-B) and blackbox optimization benchmarks (BBOB).
The OptFormer can perform hyperparameter optimization encoder-decoder style, using token-based representations. It initially observes text-based metadata (in the gray box) containing information such as the title, search space parameter names, and metrics to optimize, and repeatedly outputs parameter and objective value predictions.
Imitating Policies As the OptFormer is trained over optimization trajectories by various algorithms, it may now accurately imitate such algorithms simultaneously. By providing a text-based prompt in the metadata for the designated algorithm (e.g. “Regularized Evolution”), the OptFormer will imitate the algorithm’s behavior.
Over an unseen test function, the OptFormer produces nearly identical optimization curves as the original algorithm. Mean and standard deviation error bars are shown.
Predicting Objective Values In addition, the OptFormer may now predict the objective value being optimized (e.g. accuracy) and provide uncertainty estimates. We compared the OptFormer’s prediction with a standard Gaussian Process and found that the OptFormer was able to make significantly more accurate predictions. This can be seen below qualitatively, where the OptFormer’s calibration curve closely follows the ideal diagonal line in a goodness-of-fit test, and quantitatively through standard aggregate metrics such as log predictive density.
Combining Both: Model-based Optimization We may now use the OptFormer’s function prediction capability to better guide our imitated policy, similar to techniques found in Bayesian Optimization. Using Thompson Sampling, we may rank our imitated policy’s suggestions and only select the best according to the function predictor. This produces an augmented policy capable of outperforming our industry-grade Bayesian Optimization algorithm in Google Vizier when optimizing classic synthetic benchmark objectives and tuning the learning rate hyperparameters of a standard CIFAR-10 training pipeline.
Left: Best-so-far optimization curve over a classic Rosenbrock function. Right: Best-so-far optimization curve over hyperparameters for training a ResNet-50 on CIFAR-10 via init2winit. Both cases use 10 seeds per curve, and error bars at 25th and 75th percentiles.
Conclusion Throughout this work, we discovered some useful and previously unknown optimization capabilities of the Transformer. In the future, we hope to pave the way for a universal hyperparameter and blackbox optimization interface to use both numerical and textual data to facilitate optimization over complex search spaces, and integrate the OptFormer with the rest of the Transformer ecosystem (e.g. language, vision, code) by leveraging Google’s vast collection of offline AutoML data.
Acknowledgements The following members of DeepMind and the Google Research Brain Team conducted this research: Yutian Chen, Xingyou Song, Chansoo Lee, Zi Wang, Qiuyi Zhang, David Dohan, Kazuya Kawakami, Greg Kochanski, Arnaud Doucet, Marc’aurelio Ranzato, Sagi Perel, and Nando de Freitas.
We would like to also thank Chris Dyer, Luke Metz, Kevin Murphy, Yannis Assael, Frank Hutter, and Esteban Real for providing valuable feedback, and further thank Sebastian Pineda Arango, Christof Angermueller, and Zachary Nado for technical discussions on benchmarks. In addition, we thank Daniel Golovin, Daiyi Peng, Yingjie Miao, Jack Parker-Holder, Jie Tan, Lucio Dery, and Aleksandra Faust for multiple useful conversations.
Finally, we thank Tom Small for designing the animation for this post.
LEGO lovers scratching their heads reading assembly instructions could soon have help with complicated builds thanks to a new study from Stanford University,…
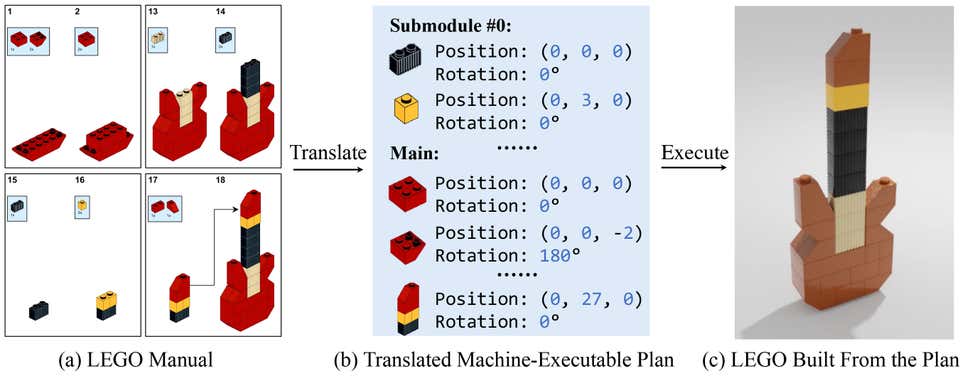
LEGO lovers scratching their heads reading assembly instructions could soon have help with complicated builds thanks to a new study from Stanford University, MIT, and Autodesk. The researchers designed a deep learning framework that translates 2D manuals into steps a machine can understand to build 3D LEGO kits. The work could advance research focused on creating machines that aid people while assembling objects.
“LEGO manuals provide a self-contained environment that exemplifies a core human skill: learning to complete tasks under guidance. Leveraging recent advances in visual scene parsing and program synthesis, we aimed to build machines with similar skills, starting with LEGO and eventually aiming for real-world scenarios,” said study senior author Jiajun Wu, an assistant professor in Computer Science at Stanford University.
According to the researchers, translating 2D manuals with AI presents two main challenges. First, AI must learn and understand the correspondence between a 3D shape during each assembly step based on the 2D manual images. This includes accounting for the orientation and alignment of the pieces.
It must also be capable of sorting through the bricks and inferring their 3D poses within semi-assembled models. As part of the LEGO build process, small pieces are combined to create larger parts, such as the head, neck, and body of a guitar. When combined, these larger parts create a complete project. This increases the difficulty as machines must parse out all the LEGO bricks, even those that may not be visible such as LEGO studs and antistuds.
The team worked to create a model that can translate 2D manuals into machine-executable plans to build a defined object. While there are two current approaches for performing this task—search-based and learning-based—both present limitations.
The search-based method seeks out possible 3D poses of pieces and manual images, looking for the correct pose. The method is compute intensive and slow, but precise.
Learning-based models rely on neural networks to predict a component’s 3D pose. They are fast, but not as accurate, especially when using unseen 3D shapes.
To solve this limitation, the researchers developed the Manual-to-Executable-Plan Network (MEPNet), which according to the study, uses deep learning and computer vision to integrate “neural 2D keypoint detection modules and 2D-3D projection algorithms.”
Working off a sequence of predictions, at each step, the model reads the manual, locates the pieces to add, and deduces the 3D positioning. After the model predicts the pose for each piece and step, it can parse the manual from scratch creating a building plan a robot could follow to build the LEGO object.
“For each step, the inputs consist of 1) a set of primitive bricks and parts that have been built in previous steps represented in 3D; and 2) a target 2D image showing how components should be connected. The expected output is the (relative) poses of all components involved in this step,” the researchers write in the study.
Figure 1. The study creates the MEPNet model to translate a LEGO manual (a), to a machine-executable plan (b), to build the target shape (c)
They created the first synthetic training data from a LEGO kit containing 72 types of bricks and employed an image rendering from LPub3D, an open-source application for “creating LEGO style digital building instructions.”
In total, the researchers generated 8,000 training manuals, using 10 sets for validation, and 20 sets for testing. There are around 200 individual steps in each data set accounting for about 200,000 individual steps in training.
“We train MEPNet with full supervision on a synthetically generated dataset where we have the ground truth keypoint, mask, and rotation information,” they write in the study. The MEPNet model was trained for 5 days on four NVIDIA TITAN RTX GPUs powered by NVIDIA Turing architecture.
They also tested the model on a Minecraft house dataset, which has a similar build style to LEGO.
Comparing MEPNet to existing models, the researchers found it outperformed the others in real-world LEGO sets, synthetically generated manuals, and the Minecraft example.
MEPNet was more accurate in pose estimations and better at identifying builds even with unseen pieces. The researchers also found that the model is able to apply learnings from synthetically generated manuals to real-world LEGO manuals.
While producing a robot capable of executing the plans is also needed, the researchers envision this work as a starting point.
“Our long-term goal is to build machines that can assist humans in constructing and assembling complex objects. We are thinking about extending our approach to other assembly domains, such as IKEA furniture,” said lead author Ruocheng Wang, an incoming Ph.D. student in Computer Science at Stanford University.

 Select from 20 hands-on workshops, offered at GTC, available in multiple languages and time zones. Early bird pricing of just $99 ends Aug 29 (regular $500).
Select from 20 hands-on workshops, offered at GTC, available in multiple languages and time zones. Early bird pricing of just $99 ends Aug 29 (regular $500). (1)_16x9") Create a project in Unreal Engine and submit it by September 1 for your chance to win an NVIDIA GeForce RTX 3080 GPU.
Create a project in Unreal Engine and submit it by September 1 for your chance to win an NVIDIA GeForce RTX 3080 GPU. Learn how startups use AI to build solutions faster and accelerate their growth with these recommended sessions at GTC.
Learn how startups use AI to build solutions faster and accelerate their growth with these recommended sessions at GTC. We recently kicked off our NVIDIA Developer Program exclusive series of Connect with Experts Ask Me Anything (AMA) sessions featuring NVIDIA experts and Ray…
We recently kicked off our NVIDIA Developer Program exclusive series of Connect with Experts Ask Me Anything (AMA) sessions featuring NVIDIA experts and Ray…



 LEGO lovers scratching their heads reading assembly instructions could soon have help with complicated builds thanks to a new study from Stanford University,…
LEGO lovers scratching their heads reading assembly instructions could soon have help with complicated builds thanks to a new study from Stanford University,…