Automatic speech recognition (ASR) is a well-established technology that is widely adopted for various applications such as conference calls, streamed video transcription and voice commands. While the challenges for this technology are centered around noisy audio inputs, the visual stream in multimodal videos (e.g., TV, online edited videos) can provide strong cues for improving the robustness of ASR systems — this is called audiovisual ASR (AV-ASR).
Although lip motion can provide strong signals for speech recognition and is the most common area of focus for AV-ASR, the mouth is often not directly visible in videos in the wild (e.g., due to egocentric viewpoints, face coverings, and low resolution) and therefore, a new emerging area of research is unconstrained AV-ASR (e.g., AVATAR), which investigates the contribution of entire visual frames, and not just the mouth region.
Building audiovisual datasets for training AV-ASR models, however, is challenging. Datasets such as How2 and VisSpeech have been created from instructional videos online, but they are small in size. In contrast, the models themselves are typically large and consist of both visual and audio encoders, and so they tend to overfit on these small datasets. Nonetheless, there have been a number of recently released large-scale audio-only models that are heavily optimized via large-scale training on massive audio-only data obtained from audio books, such as LibriLight and LibriSpeech. These models contain billions of parameters, are readily available, and show strong generalization across domains.
With the above challenges in mind, in “AVFormer: Injecting Vision into Frozen Speech Models for Zero-Shot AV-ASR”, we present a simple method for augmenting existing large-scale audio-only models with visual information, at the same time performing lightweight domain adaptation. AVFormer injects visual embeddings into a frozen ASR model (similar to how Flamingo injects visual information into large language models for vision-text tasks) using lightweight trainable adaptors that can be trained on a small amount of weakly labeled video data with minimum additional training time and parameters. We also introduce a simple curriculum scheme during training, which we show is crucial to enable the model to jointly process audio and visual information effectively. The resulting AVFormer model achieves state-of-the-art zero-shot performance on three different AV-ASR benchmarks (How2, VisSpeech and Ego4D), while also crucially preserving decent performance on traditional audio-only speech recognition benchmarks (i.e., LibriSpeech).
 |
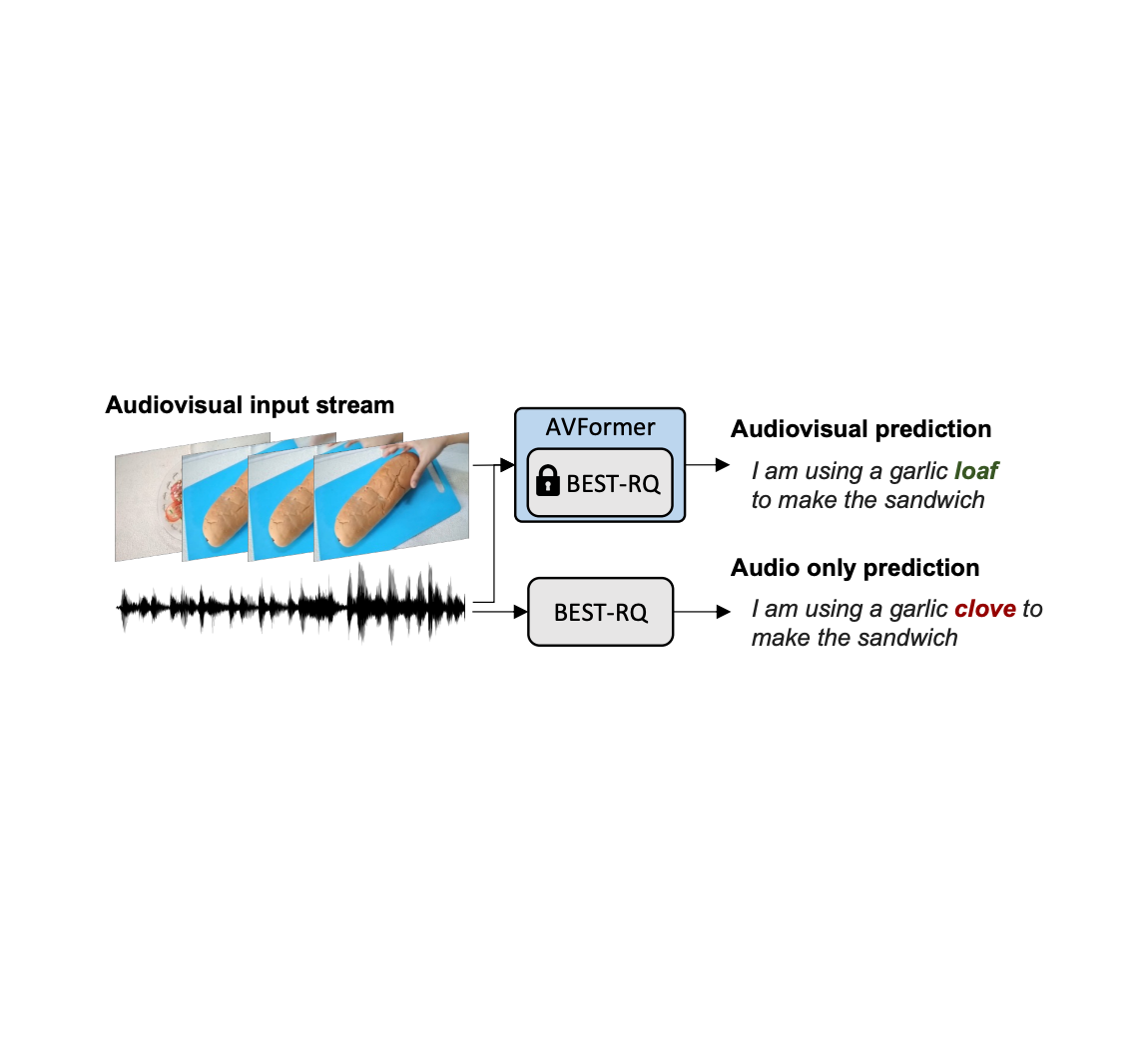
| Unconstrained audiovisual speech recognition. We inject vision into a frozen speech model (BEST-RQ, in grey) for zero-shot audiovisual ASR via lightweight modules to create a parameter- and data-efficient model called AVFormer (blue). The visual context can provide helpful clues for robust speech recognition especially when the audio signal is noisy (the visual loaf of bread helps correct the audio-only mistake “clove” to “loaf” in the generated transcript). |
Injecting vision using lightweight modules
Our goal is to add visual understanding capabilities to an existing audio-only ASR model while maintaining its generalization performance to various domains (both AV and audio-only domains).
To achieve this, we augment an existing state-of-the-art ASR model (Best-RQ) with the following two components: (i) linear visual projector and (ii) lightweight adapters. The former projects visual features in the audio token embedding space. This process allows the model to properly connect separately pre-trained visual feature and audio input token representations. The latter then minimally modifies the model to add understanding of multimodal inputs from videos. We then train these additional modules on unlabeled web videos from the HowTo100M dataset, along with the outputs of an ASR model as pseudo ground truth, while keeping the rest of the Best-RQ model frozen. Such lightweight modules enable data-efficiency and strong generalization of performance.
We evaluated our extended model on AV-ASR benchmarks in a zero-shot setting, where the model is never trained on a manually annotated AV-ASR dataset.
Curriculum learning for vision injection
After the initial evaluation, we discovered empirically that with a naïve single round of joint training, the model struggles to learn both the adapters and the visual projectors in one go. To mitigate this issue, we introduced a two-phase curriculum learning strategy that decouples these two factors — domain adaptation and visual feature integration — and trains the network in a sequential manner. In the first phase, the adapter parameters are optimized without feeding visual tokens at all. Once the adapters are trained, we add the visual tokens and train the visual projection layers alone in the second phase while the trained adapters are kept frozen.
The first stage focuses on audio domain adaptation. By the second phase, the adapters are completely frozen and the visual projector must simply learn to generate visual prompts that project the visual tokens into the audio space. In this way, our curriculum learning strategy allows the model to incorporate visual inputs as well as adapt to new audio domains in AV-ASR benchmarks. We apply each phase just once, as an iterative application of alternating phases leads to performance degradation.
 |
| Overall architecture and training procedure for AVFormer. The architecture consists of a frozen Conformer encoder-decoder model, and a frozen CLIP encoder (frozen layers shown in gray with a lock symbol), in conjunction with two lightweight trainable modules – (i) visual projection layer (orange) and bottleneck adapters (blue) to enable multimodal domain adaptation. We propose a two-phase curriculum learning strategy: the adapters (blue) are first trained without any visual tokens, after which the visual projection layer (orange) is tuned while all the other parts are kept frozen. |
The plots below show that without curriculum learning, our AV-ASR model is worse than the audio-only baseline across all datasets, with the gap increasing as more visual tokens are added. In contrast, when the proposed two-phase curriculum is applied, our AV-ASR model performs significantly better than the baseline audio-only model.
 |
| Effects of curriculum learning. Red and blue lines are for audiovisual models and are shown on 3 datasets in the zero-shot setting (lower WER % is better). Using the curriculum helps on all 3 datasets (for How2 (a) and Ego4D (c) it is crucial for outperforming audio-only performance). Performance improves up until 4 visual tokens, at which point it saturates. |
Results in zero-shot AV-ASR
We compare AVFormer to BEST-RQ, the audio version of our model, and AVATAR, the state of the art in AV-ASR, for zero-shot performance on the three AV-ASR benchmarks: How2, VisSpeech and Ego4D. AVFormer outperforms AVATAR and BEST-RQ on all, even outperforming both AVATAR and BEST-RQ when they are trained on LibriSpeech and the full set of HowTo100M. This is notable because for BEST-RQ, this involves training 600M parameters, while AVFormer only trains 4M parameters and therefore requires only a small fraction of the training dataset (5% of HowTo100M). Moreover, we also evaluate performance on LibriSpeech, which is audio-only, and AVFormer outperforms both baselines.
.png) |
| Comparison to state-of-the-art methods for zero-shot performance across different AV-ASR datasets. We also show performances on LibriSpeech which is audio-only. Results are reported as WER % (lower is better). AVATAR and BEST-RQ are finetuned end-to-end (all parameters) on HowTo100M whereas AVFormer works effectively even with 5% of the dataset thanks to the small set of finetuned parameters. |
Conclusion
We introduce AVFormer, a lightweight method for adapting existing, frozen state-of-the-art ASR models for AV-ASR. Our approach is practical and efficient, and achieves impressive zero-shot performance. As ASR models get larger and larger, tuning the entire parameter set of pre-trained models becomes impractical (even more so for different domains). Our method seamlessly allows both domain transfer and visual input mixing in the same, parameter efficient model.
Acknowledgements
This research was conducted by Paul Hongsuck Seo, Arsha Nagrani and Cordelia Schmid.
 When you see a context-relevant advertisement on a web page, it’s most likely content served by a Taboola data pipeline. As the leading content recommendation…
When you see a context-relevant advertisement on a web page, it’s most likely content served by a Taboola data pipeline. As the leading content recommendation…

 A new model generates 3D reconstructions using neural networks, turns 2D video clips into detailed 3D structures — generating lifelike virtual replicas of…
A new model generates 3D reconstructions using neural networks, turns 2D video clips into detailed 3D structures — generating lifelike virtual replicas of…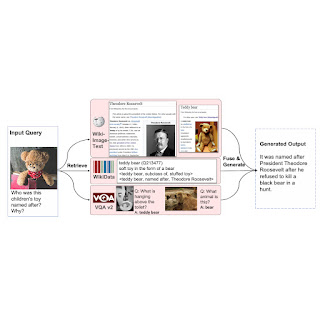






 Learn how AI is transforming financial services across use cases such as fraud detection, risk prediction models, contact centers, and more.
Learn how AI is transforming financial services across use cases such as fraud detection, risk prediction models, contact centers, and more.  Wireless technology has evolved rapidly and the 5G deployments have made good progress around the world. Up until recently, wireless RAN was deployed using…
Wireless technology has evolved rapidly and the 5G deployments have made good progress around the world. Up until recently, wireless RAN was deployed using…
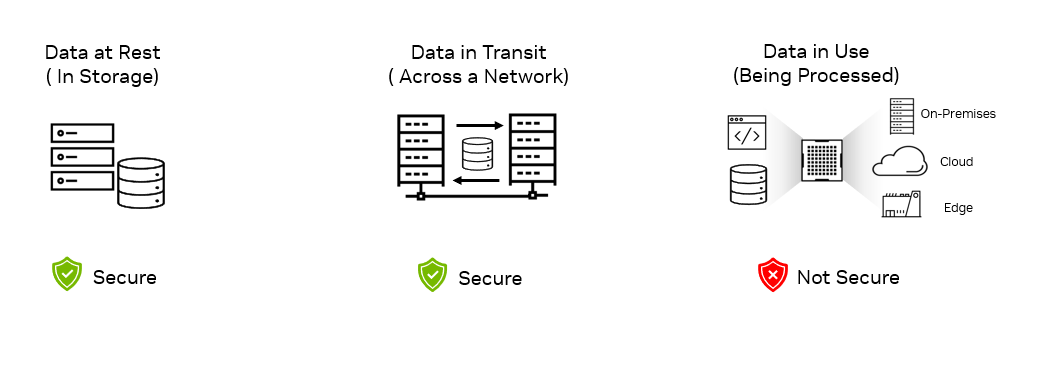
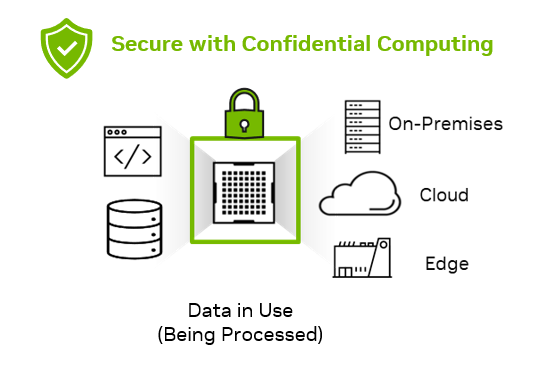
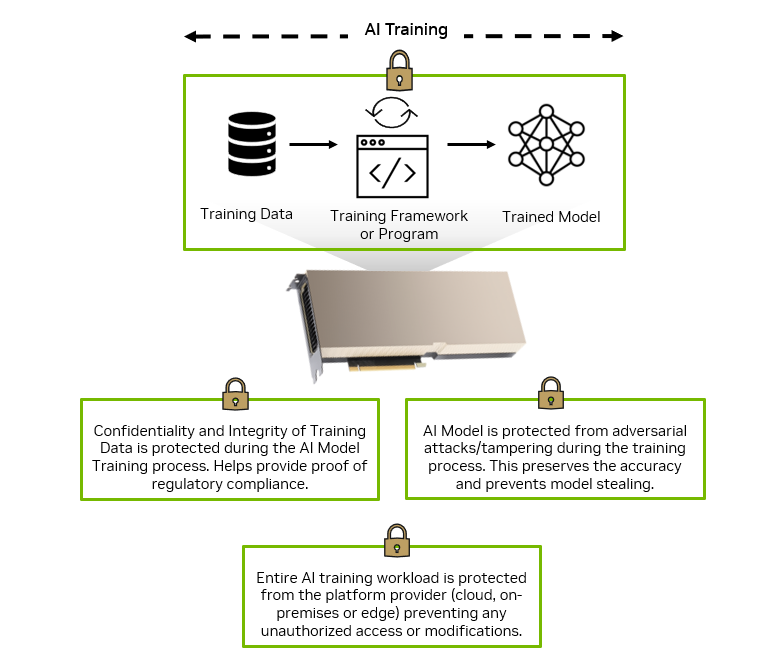
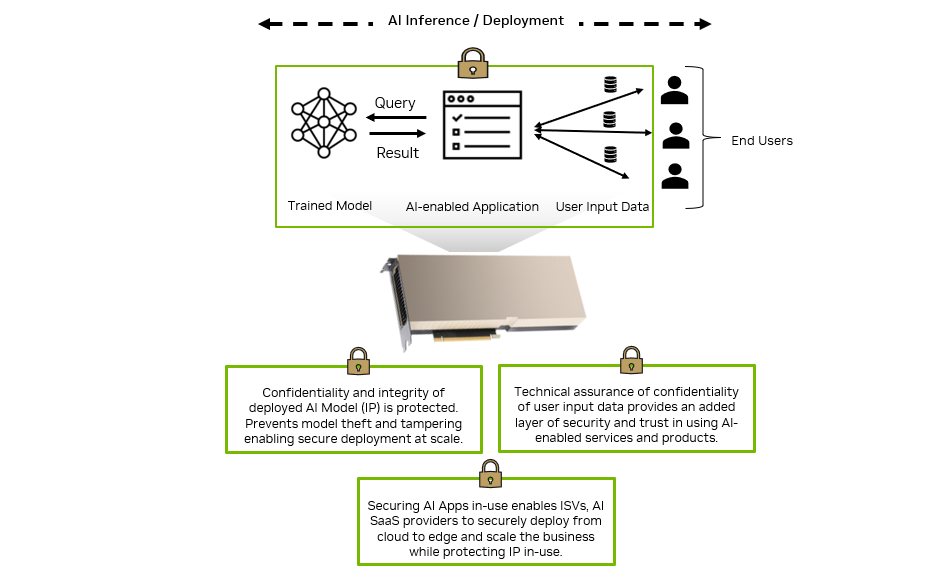
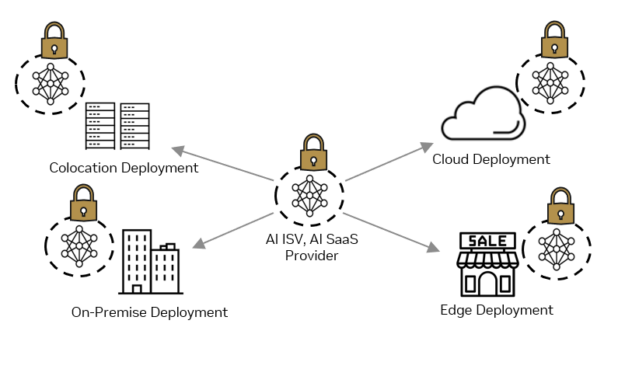
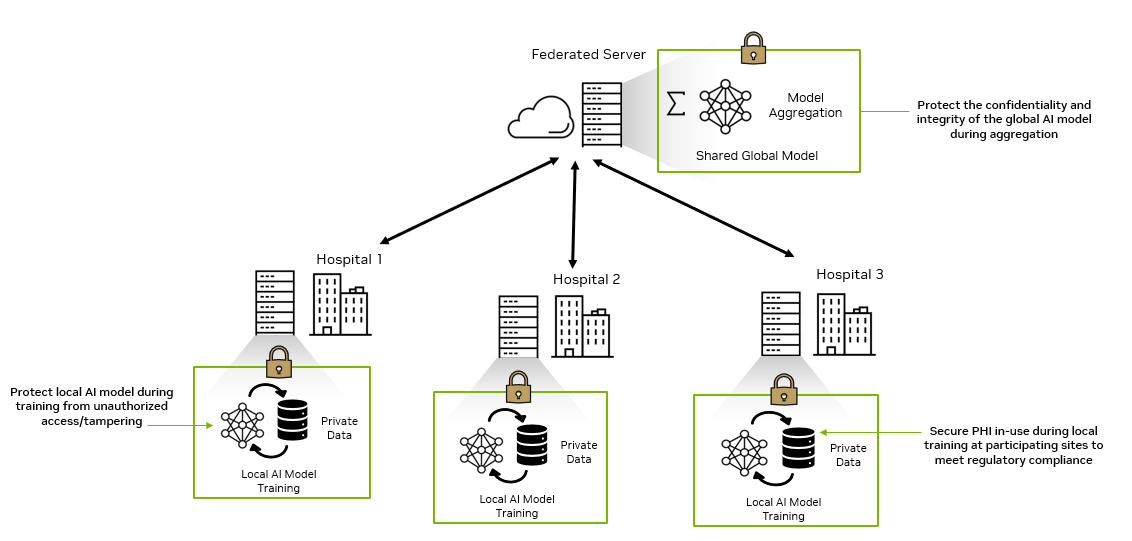
 Rapid digital transformation has led to an explosion of sensitive data being generated across the enterprise. That data has to be stored and processed in data…
Rapid digital transformation has led to an explosion of sensitive data being generated across the enterprise. That data has to be stored and processed in data…