I found a very similar issue to the one I am having on stack overflow here, but I’m posting here because no one figured it out. That post pretty much explains the issue I am having, but I am using an ImageDataGenerator instead. I cant seem to be able to get it to work within the train_step of a custom keras model. Any help is appreciated
I wrote a solution to the problem first with numpy, then numba optimized. When it comes to tensors, I have no idea how to even start the optimization. Are there some easy to follow tutorials out there? How do I even tell tensorflow the rules and goal of the optimization?
Hey (obligatory i am pretty noob). I’m training a neural network with Tensorflow (deuh) and during training the network takes about 300 micro seconds per sample. This is with dropout and layer normalization and back propagation of course and with 4 threads. During predictions however I can only predict one sample at a time (due to external needs) I would expect this to take about 1 ms or even less but when actually timing it I get more like 12ms. Are there any ways I can speed up this behavior how much can a less complex neural network bring me?
NVIDIA delivers industry-leading SDN performance benchmark results
The NVIDIA BlueField-2 data processing unit (DPU) delivers unmatched software-defined networking (SDN) performance, programmability, and scalability. It integrates eight Arm CPU cores, the secure and advanced ConnectX-6 Dx cloud network interface, and hardware accelerators that together offload, accelerate, and isolate SDN functions, performing connection tracking, flow matching, and advanced packet processing.
This post outlines the basic tenets of an accurate SDN performance benchmark and demonstrates the actual results achievable on the NVIDIA ConnectX-6 Dx with accelerators enabled. The BlueField-2 and next-generation BlueField-3 DPUs include additional acceleration capabilities and offer higher performance for a broader range of use cases.
SDN performance benchmark best practices
Any SDN performance evaluation of the BlueField DPUs or ConnectX SmartNICs should leverage the full power of the hardware accelerators. BlueField-2’s packet processing actions are programmable through the NVIDIA ASAP2 (accelerated switching and packet processing) engine. The SDN accelerators featured on both the BlueField DPUs and ConnectX SmartNICs rely on ASAP2 and other programmable hardware accelerators to achieve line-rate networking performance.
NVIDIA ASAP2 support has been integrated into the upstream Linux Kernel and the Data Plane Development Kit (DPDK) framework and is readily available in a range of Linux OS distributions and cloud management platforms.
Connection tracking acceleration is available starting with Linux Kernel 5.6. The best practice is to use a modern enterprise Linux OS, for example, Ubuntu 20.04, Red Hat Enterprise Linux 8.4, and so on. These newer kernels include inbox support for SDN with connection tracking acceleration with ConnectX-6 Dx SmartNICs and BlueField-2 DPUs. Benchmarking SDN with connection tracking based on a Linux system with an outdated kernel would be misleading.
Finally, for any SDN benchmark to be effective, it must be representative of SDN pipelines implemented in real-world cloud data centers where hundreds of thousands of connections are the norm. Both ConnectX-6 Dx SmartNICs and BlueField-2 DPUs are designed for, and deployed in hyperscale environments, and deliver breakthrough network performance at cloud-scale.
Accelerated SDN performance
Look at the NVIDIA ConnectX-6 Dx performance. The following benchmarks show the throughput and latency of SDN pipeline performance with connection tracking hardware acceleration enabled. We ran tests using a system set up, testing tools, and procedures similar to other reported results. We ran Open VSwitch (OVS) DPDK to seamlessly enable connection tracking acceleration on the ConnectX-6 Dx SmartNIC.
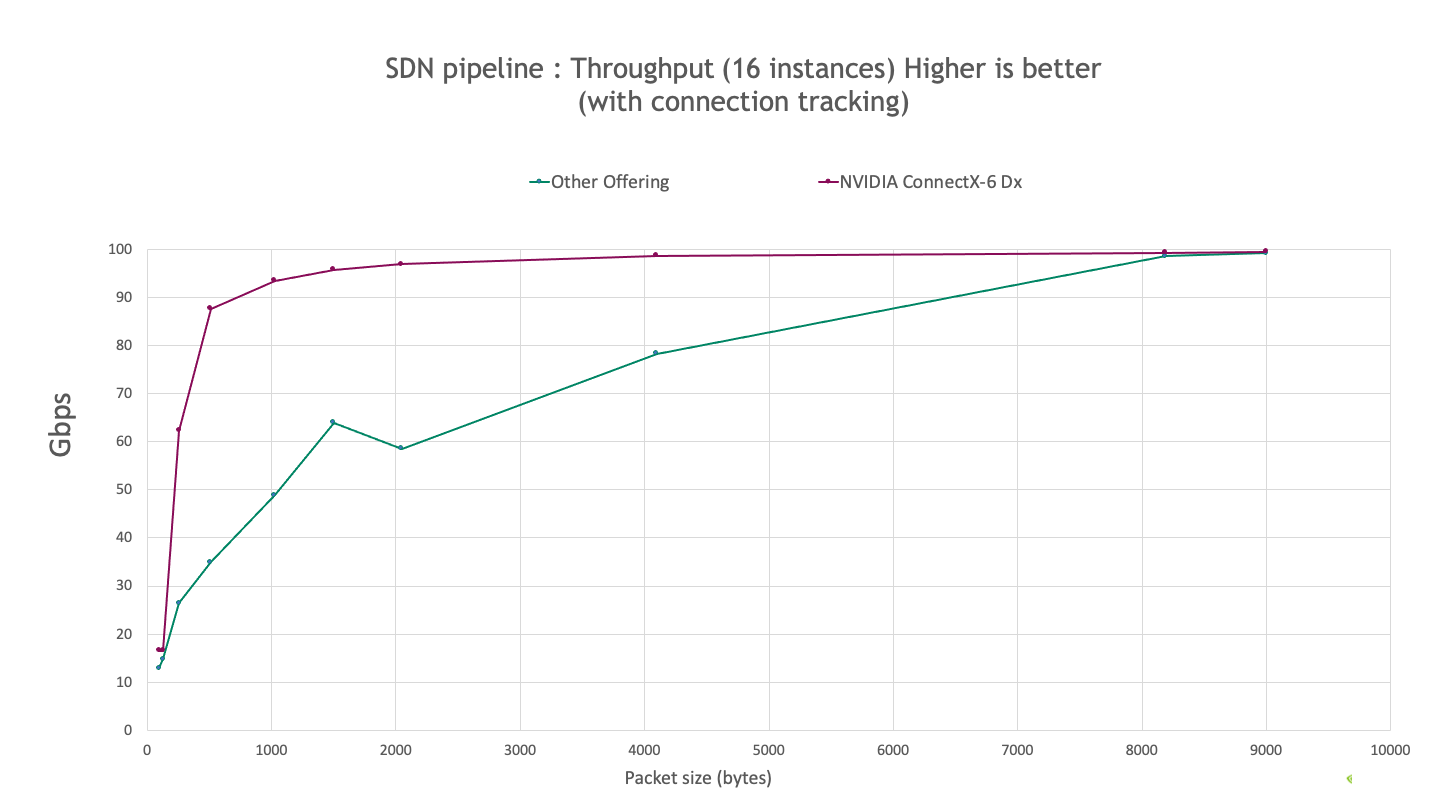
The following charts describe the observed SDN performance by using the iperf3 tool for 4 and 16 iperf instances with one flow per instance.
Figure 1. Observed SDN performance with the iperf3 tool for 4 instances
Figure 2. Observed SDN performance with 16 iperf instances
Key findings:
ConnectX-6 Dx provides higher throughput, achieving up to 120% and 150% higher for 4 and 16 instances respectively, for all packet sizes tested.
ConnectX-6 Dx achieves >90% line rate for packets as small as 1 KB compared to 8-KB packets for the other offerings.
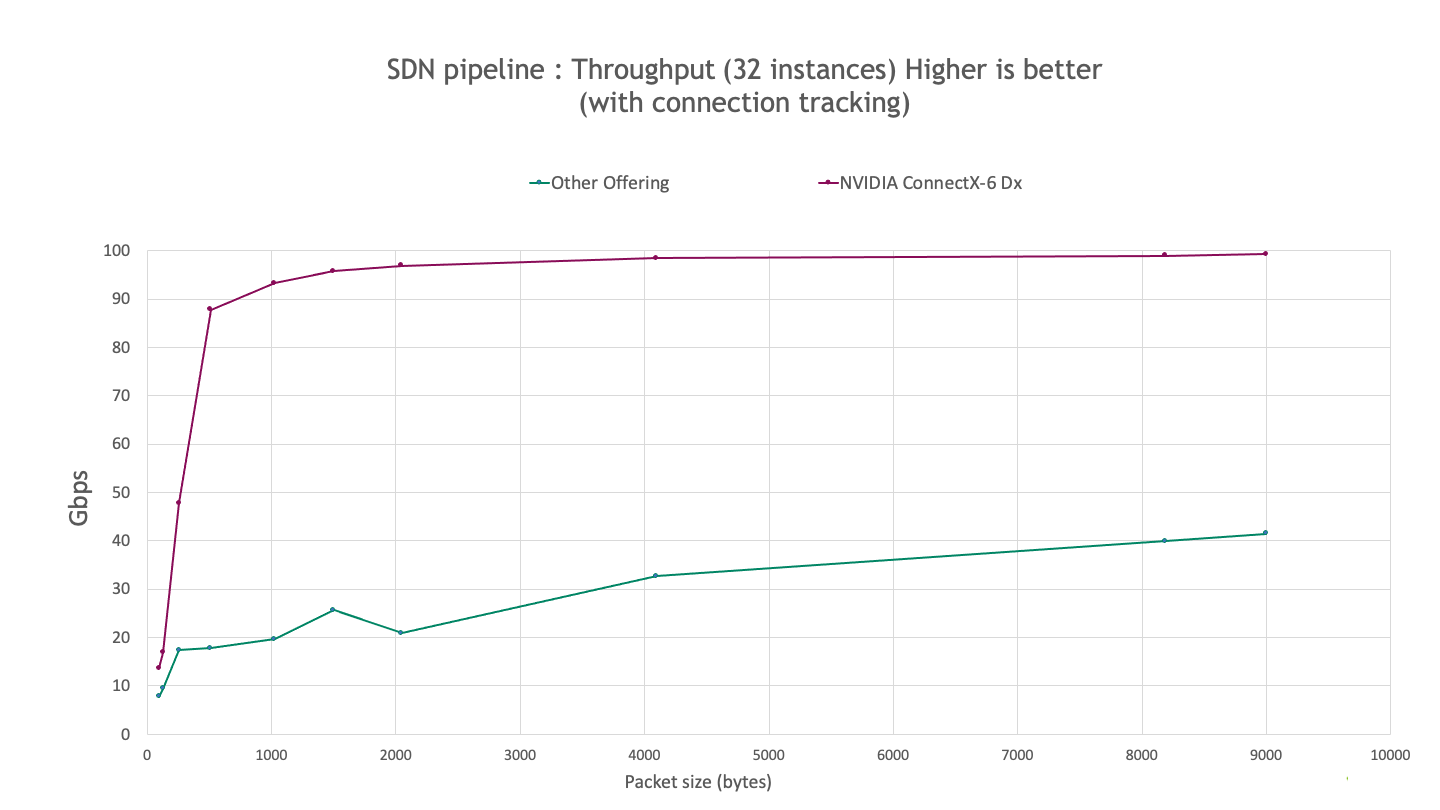
The following chart shows the observed performance for an SDN pipeline with 32 instances on the same system setup. The results show that ConnectX-6 Dx provides much better scaling as the number of flows increases and up to 4x higher throughput.
Figure 3. Observed SDN performance with 32 iperf instances
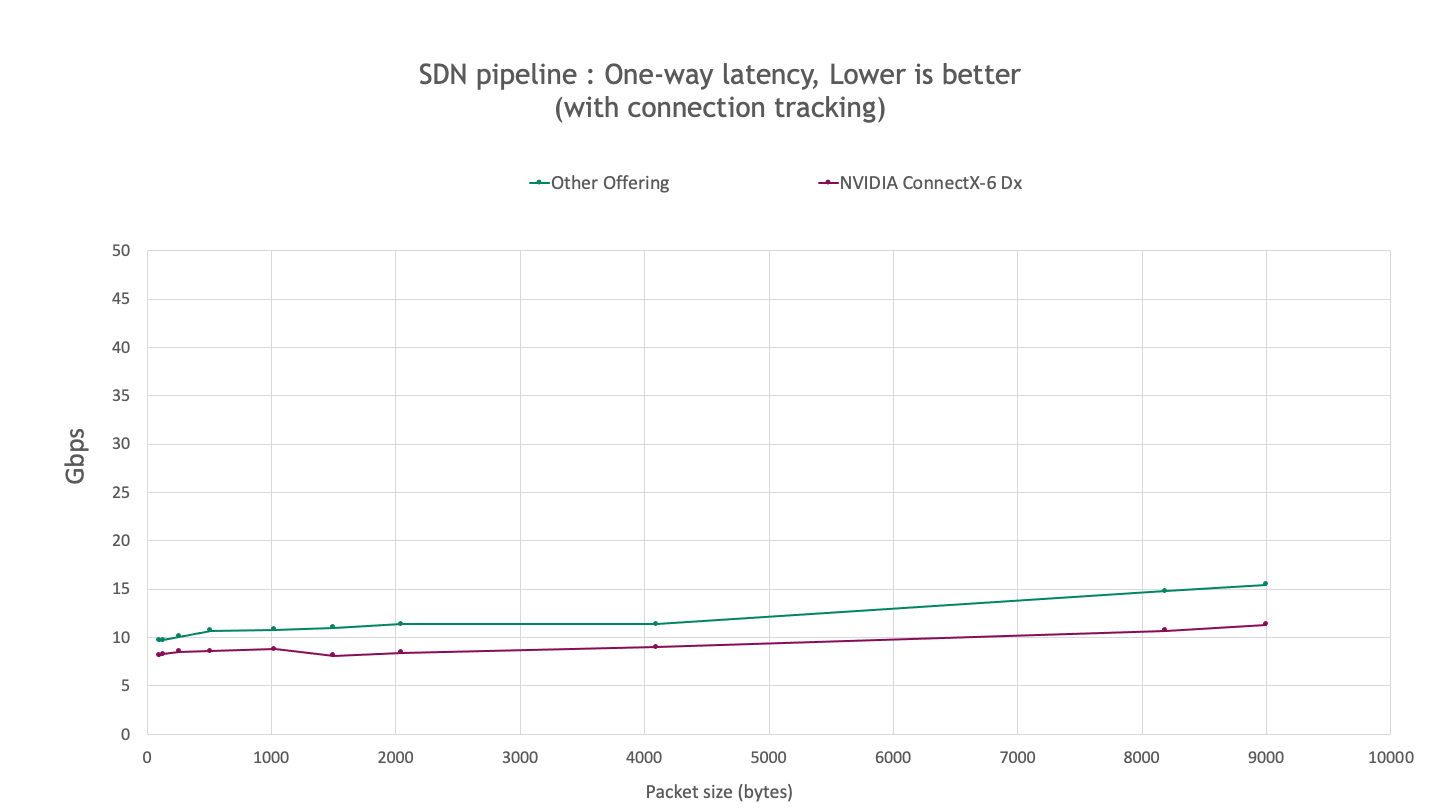
The following benchmark measures latency using sockperf. The results indicate that ConnectX-6 Dx provides ~20-30% lower latency compared to other offerings for all packet sizes that were tested.
Figure 4. Observed one-way latency for an SDN pipeline with connection tracking
Non-accelerated connection tracking implementations create bottlenecks on the host CPU. Offloading connection tracking to the on-chip accelerators means the performance achieved in these benchmarks is not strongly dependent on the host CPU or its ability to drive the test bench. These results are also indicative of the performance achievable on the BlueField-2 DPU, which integrates ConnectX-6 Dx.
BlueField-3 supports higher performance levels
NVIDIA welcomes the opportunity to test and showcase the performance of ConnectX-6 Dx and BlueField-2 while also adhering to industry best practices and operating standards. The data shown in this post compares the performance benchmark results for ConnectX-6 Dx to results reported elsewhere. The ConnectX-6 Dx provides up to 4X higher throughput and up to 30% lower latency compared to other offerings. These benchmark results demonstrate the NVIDIA leadership position in SDN acceleration technologies.
BlueField-3 is the next-generation NVIDIA DPU and integrates the advanced ConnectX-7 adapter and additional acceleration engines. Providing 400 Gb/s networking, more powerful Arm CPU cores, and a highly programmable Datapath Accelerator (DPA), BlueField-3 delivers even higher levels of performance and programmability to address the most demanding workloads in massive-scale data centers. Existing DPU-accelerated SDN applications built on BlueField-2 using DOCA will benefit from the performance enhancements that the BlueField-3 brings, without any code changes.
Learn more about modernizing your data center infrastructure with BlueField DPUs. Stay tuned for even higher SDN performance with BlueField-3 arriving in 2022.
Learn about new OpenCL support for Vulkan interoperability using semaphores and memory sharing extensions.
Developers often use OpenCL for compute together with other APIs, such as OpenGL, to access functionality including graphics rendering. OpenCL has long enabled the sharing of implicit buffer and image objects with OpenGL, OpenGL ES, EGL, Direct3D 10, and Direct3D 11 through extensions:
New generation GPU APIs such as Vulkan use explicit references to external memory together with semaphores to coordinate access to shared resources. Until now, there have been no OpenCL extensions to enable external memory and semaphore sharing with this new class of API.
Interop between OpenCL and Vulkan has been in strong demand for both mobile and desktop platforms. NVIDIA has closely worked with the Khronos OpenCL Working Group to release a set of provisional cross-vendor KHR extensions. The extensions enable applications to efficiently share data between OpenCL and APIs such as Vulkan, with significantly increased flexibility compared to previous-generation interop APIs using implicit resources.
This set of new external memory and semaphore sharing extensions provide a generic framework that enables OpenCL to import external memory and semaphore handles exported by external APIs, using a methodology that will be familiar to Vulkan developers. OpenCL then uses those semaphores to synchronize the external runtime, coordinating the use of shared memory.
Figure 1. Interoperability relationship between OpenCL and Vulkan software
External API-specific interop extensions can then be added to handle the details of interacting with specific APIs. Vulkan interop is available today, and additional APIs, such as DirectX 12, are planned.
The OpenCL new external semaphore and memory sharing functionality includes separate sets of carefully structured extensions.
Semaphore extensions
This set of extensions adds the ability to create OpenCL semaphore objects from OS-specific semaphore handles.
cl_khr_semaphore—Represents semaphores with wait and signal. This is a new class of OpenCL objects.
The following extensions extend cl_khr_external_semaphore with handle-type-specific behavior:
cl_khr_external_semaphore_opaque_fd—Shares external semaphores using Linux fd handles with reference transference, similar to VK_KHR_external_semaphore_fd.
cl_khr_external_semaphore_win32—Shares external semaphores using win32 NT and KMT handles with reference transference, similar to VK_KHR_external_semaphore_win32.
Memory extensions
These extensions add the ability to create OpenCL memory objects from OS-specific memory handles. They have a similar design to the Vulkan external memory extension VK_KHR_external_memory.
The following extensions extend cl_khr_external_memory with handle-type-specific behavior:
cl_khr_external_memory_opaque_fd—Shares external memory using Linux fd handles, similar to VK_KHR_external_memory_fd.
cl_khr_external_memory_win32—Shares external memory using win32 NT and KMT handles, similar to VK_KHR_external_memory_win32.
Using OpenCL
The typical interop use case consists of the following steps.
Check if the required support is available:
Check if the required extensions cl_khr_external_semaphore and cl_khr_external_memory are supported by the underlying OpenCL platform and devices with clGetPlatformInfo and clGetDeviceInfo.
To be able to use Win32 semaphore and memory handles, check if the cl_khr_external_semaphore_win32_khr and cl_khr_external_memory_win32_khr extensions are present.
To be able to use FD semaphore and memory handles, check if the cl_khr_external_semaphore_opaque_fd_khr and cl_khr_external_memory_opaque_fd_khr extensions are present. This can also be checked by querying the supported handle types.
Importing external semaphores requires cl_khr_external_semaphore. If cl_khr_external_semaphore_opaque_fd is supported, you can import external semaphores exported by Vulkan using FD handles in OpenCL with clCreateSemaphoreWithPropertiesKHR.
// Get cl_devices of the platform.
clGetDeviceIDs(..., &devices, &deviceCount);// Create cl_context with just first device
clCreateContext(..., 1, devices, ...);// Obtain fd/win32 or similar handle for external semaphore to be imported from the other API.
int fd = getFdForExternalSemaphore();// Create clSema of type cl_semaphore_khr usable on the only available device assuming the semaphore was imported from the same device.cl_semaphore_properties_khr sema_props[] =
{(cl_semaphore_properties_khr)CL_SEMAPHORE_TYPE_KHR,
(cl_semaphore_properties_khr)CL_SEMAPHORE_TYPE_BINARY_KHR,
(cl_semaphore_properties_khr)CL_SEMAPHORE_HANDLE_OPAQUE_FD_KHR,
(cl_semaphore_properties_khr)fd, 0};
int errcode_ret = 0;
cl_semaphore_khr clSema = clCreateSemaphoreWithPropertiesKHR(context,
sema_props,
&errcode_ret);
Importing images requires cl_khr_external_memory and support for images. In OpenCL, import external semaphores exported by Vulkan using Win32 handles with clCreateSemaphoreWithPropertiesKHR.
// Get cl_devices of the platform.
clGetDeviceIDs(..., &devices, &deviceCount);// Create cl_context with just first device
clCreateContext(..., 1, devices, ...);// Obtain fd/win32 or similar handle for external semaphore to be imported from the other API.
void *handle = getWin32HandleForExternalSemaphore(); // Create clSema of type cl_semaphore_khr usable on the only available device assuming the semaphore was imported from the same device.
cl_semaphore_properties_khr sema_props[] =
{(cl_semaphore_properties_khr)CL_SEMAPHORE_TYPE_KHR,
(cl_semaphore_properties_khr)CL_SEMAPHORE_TYPE_BINARY_KHR,
(cl_semaphore_properties_khr)CL_SEMAPHORE_HANDLE_OPAQUE_WIN32_KHR,
(cl_semaphore_properties_khr)handle, 0};
int errcode_ret = 0;
cl_semaphore_khr clSema = clCreateSemaphoreWithPropertiesKHR(context,
sema_props,
&errcode_ret);
In OpenCL, import external memory exported by Vulkan using the FD handle as buffer memory with clCreateBufferWithProperties.
// Get cl_devices of the platform. clGetDeviceIDs(..., &devices, &deviceCount);
// Create cl_context with just first device clCreateContext(..., 1, devices, ...);
// Obtain fd/win32 or similar handle for external memory to be imported from other API. int fd = getFdForExternalMemory();
In OpenCL, import external memory exported by Vulkan as image memory using clCreateImageWithProperties.
// Create img of type cl_mem. Obtain fd/win32 or similar handle for external memory to be imported from other API.
int fd = getFdForExternalMemory();// Set cl_image_format based on external image info
cl_image_format clImgFormat = { };
clImageFormat.image_channel_order = CL_RGBA;
clImageFormat.image_channel_data_type = CL_UNORM_INT8;// Set cl_image_desc based on external image info
size_t clImageFormatSize;
cl_image_desc image_desc = { };
image_desc.image_type = CL_MEM_OBJECT_IMAGE2D_ARRAY;
image_desc.image_width = width;
image_desc.image_height = height;
image_desc.image_depth = depth;
cl_mem_properties_khr extMemProperties[] =
{ (cl_mem_properties_khr)CL_EXTERNAL_MEMORY_HANDLE_OPAQUE_FD_KHR,
(cl_mem_properties_khr)fd,
0
};cl_mem img = clCreateImageWithProperties(/*context*/ clContext,
/*properties*/ extMemProperties,
/*flags*/ 0,
/*image_format*/ &clImgFormat,
/*image_desc*/ &image_desc,
/*errcode_ret*/ &errcode_ret)
Synchronize between OpenCL and Vulkan using semaphore wait and signal.
// Create clSema using one of the above examples of external semaphore creation.
int errcode_ret = 0;
cl_semaphore_khr clSema = clCreateSemaphoreWithPropertiesKHR(context,
sema_props,
&errcode_ret);
while (true) {
// (not shown) Signal the semaphore from the other API,// Wait for the semaphore in OpenCL
clEnqueueWaitSemaphoresKHR( /*command_queue*/ command_queue,
/*num_sema_objects*/ 1,
/*sema_objects*/ &clSema,
/*num_events_in_wait_list*/ 0,
/*event_wait_list*/ NULL,
/*event*/ NULL);
clEnqueueNDRangeKernel(command_queue, ...);
clEnqueueSignalSemaphoresKHR(/*command_queue*/ command_queue,
/*num_sema_objects*/ 1,
/*sema_objects*/ &clSema,
/*num_events_in_wait_list*/ 0,
/*event_wait_list*/ NULL,
/*event*/ NULL);
// (not shown) Launch work in the other API that waits on 'clSema'
MatX is an experimental library that allows you to write high-performance GPU code in C++, with high-level syntax and a common data type across all functions.
Rob Smallshire once said, “You can write faster code in C++, but write code faster in Python.” Since its release more than a decade ago, CUDA has given C and C++ programmers the ability to maximize the performance of their code on NVIDIA GPUs.
More recently, libraries such as CuPy and PyTorch allowed developers of interpreted languages to leverage the speed of the optimized CUDA libraries from other languages. These interpreted languages have many excellent properties, including easy-to-read syntax, automatic memory management, and common types across all functions.
However, sometimes having these features means paying a performance penalty due to memory management and other factors outside your control. The decrease in performance is often worth it to save development time. Still, it may ultimately require rewriting portions of the application later when performance becomes an issue.
What if you could still achieve the maximum performance using C++ while still reaping all the benefits from the interpreted languages?
MatX overview
MatX is an experimental, GPU-accelerated, numerical computing C++ library aimed at bridging the gap between users wanting the highest performance possible, with the same easy syntax and types across all CUDA libraries. Using the C++17 support added in CUDA 11.0, MatX allows you to write the same natural algebraic expressions that you would in a high-level language like Python without the performance penalty that may come from it.
Tensor types
MatX includes interfaces to many of the popular math libraries, such as cuBLAS, CUTLASS, cuFFT, and CUB, but uses a common data type (tensor_t) across all these libraries. This greatly simplifies the API to these libraries by deducing information that it knows about the tensor type and calling the correct APIs based on that.
The following code examples show an FFT-based resampler.
Python
N = min(ns, ns_resamp)
nyq = N // 2 + 1
# Create an empty vector
sv = np.empty(ns)
# Real to complex FFT
svc = np.fft.rfft(sv)
# Slice
sv = svc[0:nyq]
# Complex to real IFFT
rsv = np.fft.irfft(sv, ns_resamp)
MatX
uint32_t N = std::min(ns, ns_resamp);
uint32_t nyq = N / 2 + 1;
auto sv = make_tensor({ns});
auto svc = make_tensor({ns / 2 + 1});
auto rv = make_tensor({ns_resamp});
// Real to complex FFT
fft(svc, sv, stream);
// Slice the vector
auto sv = svc.Slice({0}, {nyq});
// Complex to real IFFT
ifft(rsv, sv, stream);
While the code length and readability are similar, the MatX version on an A100 runs about 2100x faster than the NumPy version running on CPU. The MatX version also has many hidden benefits over directly using the CUDA libraries, such as type checking, input and output size checking, and slicing a tensor without pointer manipulation.
The tensor types are not limited to FFTs, though, and the same variables can be used inside of other libraries and expressions. For example, if you wanted to perform a GEMM using CUTLASS on the resampler output, you could write the following:
matmul(resampOut, resampView, B, stream);
In this code, resampOut and B are appropriately sized tensors for the GEMM operation. As in the FFT sample preceding, types, sizes, batches, and strides are all inferred by the tensor metadata. Using a strongly typed C++ API also means that many runtime and compile-time errors can be caught without additional debugging.
In addition to supporting the optimized CUDA libraries as backends, these same tensor types can be used in algebraic expressions to perform element-wise operations:
(C = A * B + (D / 5.0) + cos(E)).run(stream);
Lazy evaluation
MatX uses lazy evaluation to create a GPU kernel at compile time representing the expression in parentheses. Only when the run function is called on the expression does the operation execute on the GPU. Over 40 different types of operators are supported and can be mixed and matched across different size and type tensors with compatible parameters. If you look at the earlier expression written as a CUDA kernel, it would look something like this:
While the earlier code is not complicated, it’s hiding several problems:
The data types are hard-coded to floats. To change to another type, you must edit the kernel signature. Astute readers would say to use templates and let the compiler deduce types for you. While that may work for some types, it won’t work for all types you may want to use. For example, cosf is not defined for half precision types, so you must use compile-time conditionals to handle different types.
Any small change to the function signature needs a completely different function. For example, what if you wanted to add a tensor F in some cases, but still retain this original signature? That would be two functions to maintain that are nearly identical.
While a grid-stride loop is good practice and is used to handle different sizes of blocks and grids, you must still have code ensuring that during kernel launch there are enough threads to keep the GPU busy.
All inputs are assumed to be 1D vectors; higher dimensions could break with non-unity strides.
There are numerous other deficiencies not listed, including the inability to broadcast different-sized tensors, no checking on sizes, requiring contiguous memory layouts, and more.
Obviously, this code only works under specific conditions, while the MatX version solves all these issues and more while typically maintaining the same performance as writing the kernel directly.
Additional MatX features
Other key features of MatX include the following:
Creating zero-copy tensor views by slicing, cloning, and permuting existing tensors.
Supporting arbitrary-dimension tensors.
Generators for generating data on-the-fly without storing in memory. Common examples would be to create a linearly spaced vector, hamming window, or a diagonal matrix.
Supports almost every type used in CUDA, including half precision (both FP16 and BF16) and complex numbers (both full and half precision).
Linear solver functions through cuSolver, sorting and scanning using CUB, random number generation using cuRAND, reductions, and more
Summary
MatX is open-sourced under the BSDv3 license. For more information, see the following resources:
The recent Taiwan Computing Cloud GPU Hackathon helped 12 teams advance their HPC and AI projects, using innovative technologies to address pressing global challenges.
While the world is continuously changing, one constant is the ongoing drive of developers to tackle challenges using innovative technologies. The recent Taiwan Computing Cloud (TWCC) GPU Hackathon exemplified such a drive, serving as a catalyst for developers and engineers to advance their HPC and AI projects using GPUs.
Traditional scheduling models mostly employ heuristic rules, which can respond to dynamic events instantly. However, their short-term approach does not often lead to the optimal solution and proves inflexible when dealing with changing variables, which limits their ongoing viability.
The team’s approach uses a Monte Carlo Tree Search (MCTS) method, combining the classic tree search implementations alongside machine learning principles of reinforcement learning. This method addresses existing heuristic limitations for improved efficiency of the overall scheduling model for improved efficiency.
Working with their mentor, Team AI Scheduler learned to use NVIDIA Nsight Systems to identify bottlenecks and use GPUs to parallelize their code. At the conclusion of the event, the team was able to accelerate the simulation step of their MCTS algorithm. This reduced the scheduling time from 6 hours to 30 minutes and achieved a speedup of 11.3x in overall scheduling efficiency.
“Having proved the feasibility of using GPUs to accelerate our model at this hackathon, the next step is to adopt it into our commercial models for industry use,” said Dr. Tsan-Cheng Su and Hao-Che Huang of CITC, ITRI.
Using GPUs to see the big picture in Earth sciences
Located between the Eurasian and the Philippine Sea Plate, Taiwan is one of the most tectonically active places in the world, and an important base for global seismological research. Geological research and the time scale of tectonic activity is often measured in units of thousands–or tens of thousands–of years. This requires the use of massive amounts of data and adequate compute power to analyze efficiently.
Figure 1. Led by Dr. Tan (center), Team IES-Geodynamics pictured.
The IES-Geodynamics team, led by Dr. Tan from the Institute of Earth Research, Academia Sinica, came to the GPU Hackathon to accelerate their numerical geodynamical model. Named DynEarthSol, it simulates mantle convection, subduction, mountain building, and tectonics. Previously, the team handled large volumes of data by reducing the number of calculations and steps by chunking data into pieces and restricting the computing processes to fit the limited computing power of the CPU. This made it very difficult to see the full picture of the research.
Over the course of the hackathon, the team used a new data input method that leveraged the GPU to calculate the data and multiple steps. Using OpenACC, Team IES-Geodynamics was able to port 80% of their model to GPUs and achieved a 13.6X speedup.
“This is my second time attending a GPU Hackathon and I will definitely attend the next one,” said Professor Eh Tan, Research Fellow from IES, Academia Sinica. “We have learned the appropriate way to adopt GPUs and the user-friendly profiling tool gives us a great idea for how to optimize our model.”
The team will continue to work towards porting the remaining 20% of their model. They look forward to running more high-resolution models using GPUs to gain a deeper understanding of formation activities in Taiwan.
Rapid flood assessment for emergency planning and response
Flooding is among the most devastating natural disasters. Causing massive casualties and economic losses, floods affect an average of 21 million people worldwide each year with numbers expected to rise due to climate change and other factors. Preventing and mitigating these hazards is a critical endeavor.
THINKLAB, a team from National Yang Chiao University (NYCU), is working on the development of a model that can provide fast and accurate results for emergency purposes while maintaining simplicity in operation. The proposed hybrid inundation model (HIM) solves the zero-inertia equation through the Cellular Automata approach and works with subgrid-scale interpolation strategies to generate higher-resolution results.
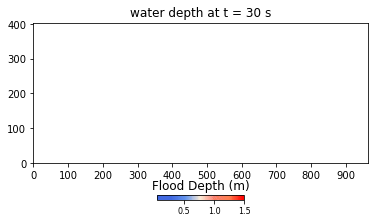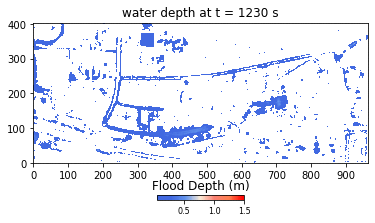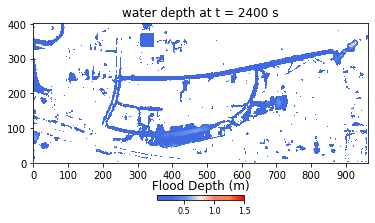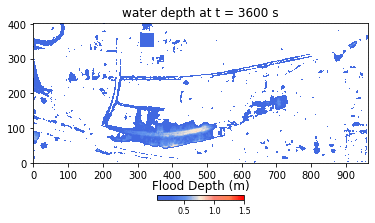
Figure 2. Example of flood extents produced by the HIM.
Developed using Python and NumPy libraries, the HIM model ran without parallel or GPU computations at the onset of the hackathon. During the event, Team THINKLAB used CuPy to parallelize their code to run on GPUs, then focused on applying user-defined CUDA kernels to the parameters. The result was a 672-time speedup, bringing the computation time from 2 weeks to approximately 30 minutes.
“We learned so many techniques during this event and highly recommend these events to others,” said Obaja Wijaya, team member of THINKLAB. “NVIDIA is the expert in this field and by working with their mentors we have learned how to optimize models/codes using GPU programming.”
Additional hackathons and boot camps are scheduled throughout 2022. For more information on GPU Hackathons and future events, visit https://www.gpuhackathons.org.

 NVIDIA delivers industry-leading SDN performance benchmark results
NVIDIA delivers industry-leading SDN performance benchmark results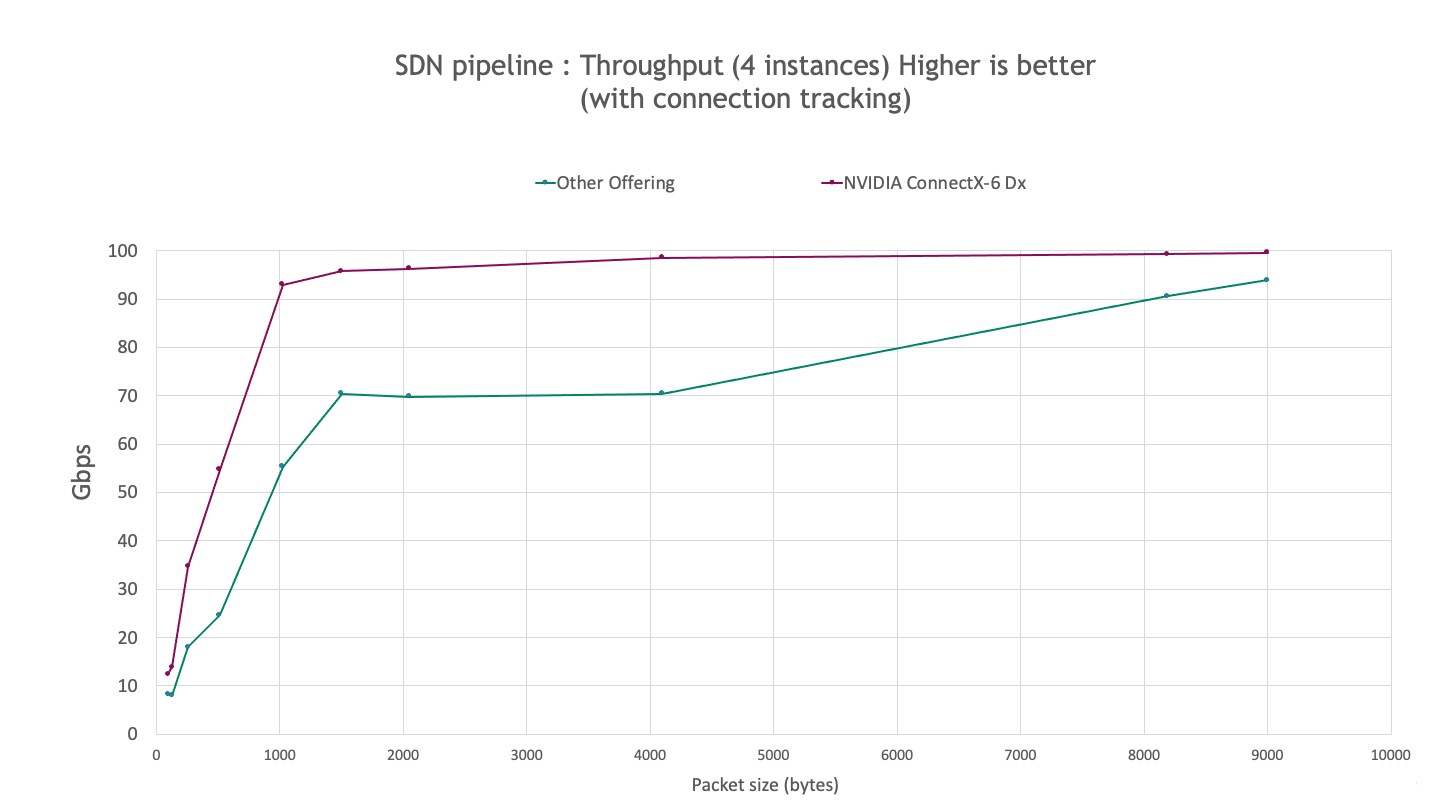
 Learn about new OpenCL support for Vulkan interoperability using semaphores and memory sharing extensions.
Learn about new OpenCL support for Vulkan interoperability using semaphores and memory sharing extensions.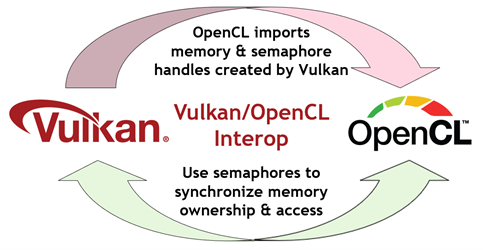
 MatX is an experimental library that allows you to write high-performance GPU code in C++, with high-level syntax and a common data type across all functions.
MatX is an experimental library that allows you to write high-performance GPU code in C++, with high-level syntax and a common data type across all functions. The recent Taiwan Computing Cloud GPU Hackathon helped 12 teams advance their HPC and AI projects, using innovative technologies to address pressing global challenges.
The recent Taiwan Computing Cloud GPU Hackathon helped 12 teams advance their HPC and AI projects, using innovative technologies to address pressing global challenges.