Hey guys, need your help, please 🙂
submitted by /u/markwatsn
[visit reddit] [comments]
 DataBloom
DataBloomHey guys, need your help, please 🙂
submitted by /u/markwatsn
[visit reddit] [comments]
What do u think about it?
submitted by /u/markwatsn
[visit reddit] [comments]
Hello to everyone,
I am trying to adapt the script from this link keras example to my custom dataset but I run into the following issue:
‘ValueError: Unexpected result of train_function
(Empty logs). Please use Model.compile(…, run_eagerly=True)
, or tf.config.run_functions_eagerly(True)
for more information of where went wrong, or file a issue/bug to tf.keras
.
My dataset is (I flattened it in order to surpass error for converting dict to tensorflow)
<TensorSliceDataset element_spec={'image/filename': TensorSpec(shape=(), dtype=tf.string, name=None), 'image/id': TensorSpec(shape=(), dtype=tf.int32, name=None), 'is_crowd': TensorSpec(shape=(), dtype=tf.bool, name=None), 'area': TensorSpec(shape=(), dtype=tf.float32, name=None), 'bbox': TensorSpec(shape=(1, 4), dtype=tf.float32, name=None), 'id': TensorSpec(shape=(), dtype=tf.int32, name=None), 'image': TensorSpec(shape=(480, 640, 3), dtype=tf.float32, name=None), 'label': TensorSpec(shape=(), dtype=tf.int32, name=None)}>
while the example dataset is
<PrefetchDataset element_spec={'image': TensorSpec(shape=(None, None, 3), dtype=tf.uint8, name=None), 'image/filename': TensorSpec(shape=(), dtype=tf.string, name=None), 'image/id': TensorSpec(shape=(), dtype=tf.int64, name=None), 'objects': {'area': TensorSpec(shape=(None,), dtype=tf.int64, name=None), 'bbox': TensorSpec(shape=(None, 4), dtype=tf.float32, name=None), 'id': TensorSpec(shape=(None,), dtype=tf.int64, name=None), 'is_crowd': TensorSpec(shape=(None,), dtype=tf.bool, name=None), 'label': TensorSpec(shape=(None,), dtype=tf.int64, name=None)}}>
My script is publicly available here. If anyone can help with what I am doing wrong (i.e. input images, tensors, model building), I would be so grateful!!
submitted by /u/agristats
[visit reddit] [comments]
We currently have an app built on Xamarin and C#. My aim is to provide an analytics platform (which I’ve built in TF), however what would be the best way to deploy it? I’ve done some readings of the docs, but I’d love to hear your guys experience / thoughts?
submitted by /u/PrijNaidu
[visit reddit] [comments]
I have a InceptionResNetV2 model that is trained for identification of insects. I was wondering if I could change the base identification part of YOLO to use my model? My understanding is that YOLO trains identification based on Darknet,VGG, or other small networks and then moves to a partitioning method for the object detection so based on my limited knowledge I’m guessing it should theoretically be possible to replace these small base models but I am not sure if it is this simple or if my neural network architecture could work. I couldn’t find much information about this online.
submitted by /u/188_888
[visit reddit] [comments]


|
submitted by /u/Kagermanov [visit reddit] [comments] |
While not immediately obvious, all of us experience the world in four dimensions (4D). For example, when walking or driving down the street we observe a stream of visual inputs, snapshots of the 3D world, which, when taken together in time, creates a 4D visual input. Today’s autonomous vehicles and robots are able to capture much of this information through various onboard sensing mechanisms, such as LiDAR and cameras.
LiDAR is a ubiquitous sensor that uses light pulses to reliably measure the 3D coordinates of objects in a scene, however, it is also sparse and has a limited range — the farther one is from a sensor, the fewer points will be returned. This means that far-away objects might only get a handful of points, or none at all, and might not be seen by LiDAR alone. At the same time, images from the onboard camera, which is a dense input, are incredibly useful for semantic understanding, such as detecting and segmenting objects. With high resolution, cameras can be very effective at detecting objects far away, but are less accurate in measuring the distance.
Autonomous vehicles collect data from both LiDAR and onboard camera sensors. Each sensor measurement is recorded at regular time intervals, providing an accurate representation of the 4D world. However, very few research algorithms use both of these in combination, especially when taken “in time”, i.e., as a temporally ordered sequence of data, mostly due to two major challenges. When using both sensing modalities simultaneously, 1) it is difficult to maintain computational efficiency, and 2) pairing the information from one sensor to another adds further complexity since there is not always a direct correspondence between LiDAR points and onboard camera RGB image inputs.
In “4D-Net for Learned Multi-Modal Alignment”, published at ICCV 2021, we present a neural network that can process 4D data, which we call 4D-Net. This is the first attempt to effectively combine both types of sensors, 3D LiDAR point clouds and onboard camera RGB images, when both are in time. We also introduce a dynamic connection learning method, which incorporates 4D information from a scene by performing connection learning across both feature representations. Finally, we demonstrate that 4D-Net is better able to use motion cues and dense image information to detect distant objects while maintaining computational efficiency.
4D-Net
In our scenario, we use 4D inputs (3D point clouds and onboard camera image data in time) to solve a very popular visual understanding task, the 3D box detection of objects. We study the question of how one can combine the two sensing modalities, which come from different domains and have features that do not necessarily match — i.e., sparse LiDAR inputs span the 3D space and dense camera images only produce 2D projections of a scene. The exact correspondence between their respective features is unknown, so we seek to learn the connections between these two sensor inputs and their feature representations. We consider neural network representations where each of the feature layers can be combined with other potential layers from other sensor inputs, as shown below.
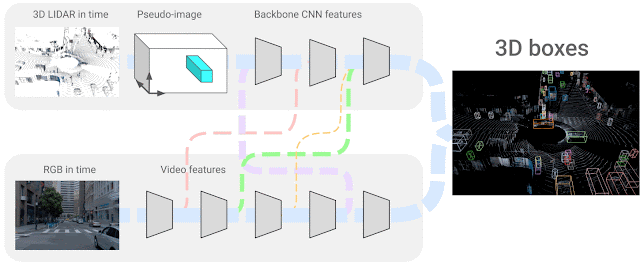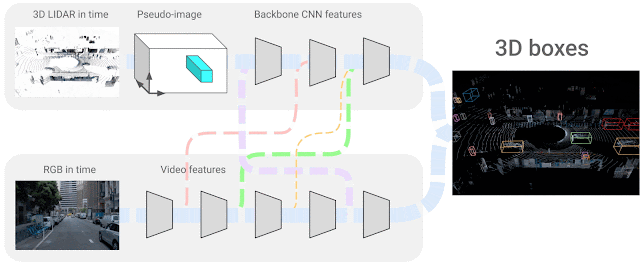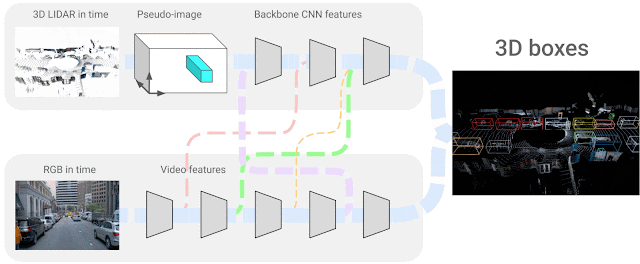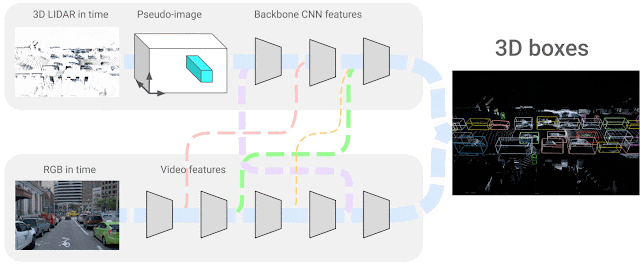 |
| 4D-Net effectively combines 3D LiDAR point clouds in time with RGB images, also streamed in time as video, learning the connections between different sensors and their feature representations. |
Dynamic Connection Learning Across Sensing Modalities
We use a light-weight neural architecture search to learn the connections between both types of sensor inputs and their feature representations, to obtain the most accurate 3D box detection. In the autonomous driving domain it is especially important to reliably detect objects at highly variable distances, with modern LiDAR sensors reaching several hundreds of meters in range. This implies that more distant objects will appear smaller in the images and the most valuable features for detecting them will be in earlier layers of the network, which better capture fine-scale features, as opposed to close-by objects represented by later layers. Based on this observation, we modify the connections to be dynamic and select among features from all layers using self-attention mechanisms. We apply a learnable linear layer, which is able to apply attention-weighting to all other layer weights and learn the best combination for the task at hand.
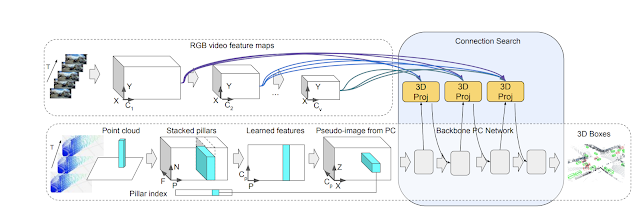 |
| Connection learning approach schematic, where connections between features from the 3D point cloud inputs are combined with the features from the RGB camera video inputs. Each connection learns the weighting for the corresponding inputs. |
Results
We evaluate our results against state-of-the-art approaches on the Waymo Open Dataset benchmark, for which previous models have only leveraged 3D point clouds in time or a combination of a single point cloud and camera image data. 4D-Net uses both sensor inputs efficiently, processing 32 point clouds in time and 16 RGB frames within 164 milliseconds, and performs well compared to other methods. In comparison, the next best approach is less efficient and accurate because its neural net computation takes 300 milliseconds, and uses fewer sensor inputs than 4D-Net.
 |
 |
| Results on a 3D scene. Top: 3D boxes, corresponding to detected vehicles, are shown in different colors; dotted line boxes are for objects that were missed. Bottom: The boxes are shown in the corresponding camera images for visualization purposes. |
Detecting Far-Away Objects
Another benefit of 4D-Net is that it takes advantage of both the high resolution provided by RGB, which can accurately detect objects on the image plane, and the accurate depth that the point cloud data provides. As a result, objects at a greater distance that were previously missed by point cloud-only approaches can be detected by a 4D-Net. This is due to the fusion of camera data, which is able to detect distant objects, and efficiently propagate this information to the 3D part of the network to produce accurate detections.
Is Data in Time Valuable?
To understand the value of the 4D-Net, we perform a series of ablation studies. We find that substantial improvements in detection accuracy are obtained if at least one of the sensor inputs is streamed in time. Considering both sensor inputs in time provides the largest improvements in performance.
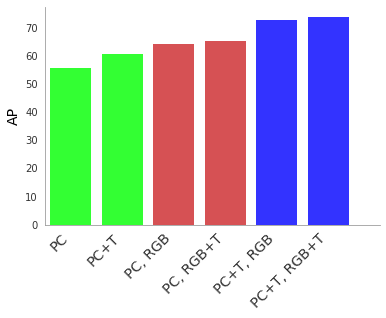 |
| 4D-Net performance for 3D object detection measured in average precision (AP) when using point clouds (PC), Point Clouds in Time (PC + T), RGB image inputs (RGB) and RGB images in Time (RGB + T). Combining both sensor inputs in time is best (rightmost columns in blue) compared to the left-most columns (green) which use a PC without RGB inputs. All joint methods use our 4D-Net multi-modal learning. |
Multi-stream 4D-Net
Since the 4D-Net dynamic connection learning mechanism is general, we are not limited to only combining a point cloud stream with an RGB video stream. In fact, we find that it is very cost-effective to provide a large resolution single-image stream, and a low-resolution video stream in conjunction with 3D point cloud stream inputs. Below, we demonstrate examples of a four-stream architecture, which performs better than the two-stream one with point clouds in time and images in time.
Dynamic connection learning selects specific feature inputs to connect together. With multiple input streams, 4D-Net has to learn connections between multiple target feature representations, which is straightforward as the algorithm does not change and simply selects specific features from the union of inputs. This is an incredibly light-weight process that uses a differentiable architecture search, which can discover new wiring within the model architecture itself and thus effectively find new 4D-Net models.
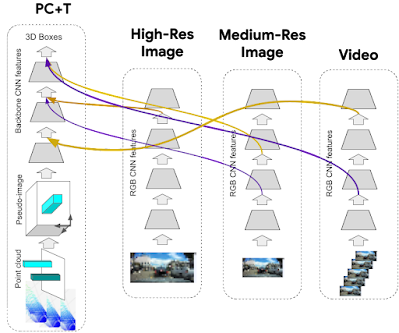 |
| Example multi-stream 4D-Net which consists of a stream of 3D point clouds in time (PC+T), and multiple image streams: a high-resolution single image stream, a medium-resolution single image stream and a video stream (of even lower resolution) images. |
Summary
While deep learning has made tremendous advances in real-life applications, the research community is just beginning to explore learning from multiple sensing modalities. We present 4D-Net which learns how to combine 3D point clouds in time and RGB camera images in time, for the popular application of 3D object detection in autonomous driving. We demonstrate that 4D-Net is an effective approach for detecting objects, especially at distant ranges. We hope this work will provide researchers with a valuable resource for future 4D data research.
Acknowledgements
This work is done by AJ Piergiovanni, Vincent Casser, Michael Ryoo and Anelia Angelova. We thank our collaborators, Vincent Vanhoucke, Dragomir Anguelov and our colleagues at Waymo and Robotics at Google for their support and discussions. We also thank Tom Small for the graphics animation.

Hi there! Hope you’re doing good.
First of all, I’m an Embedded Systems engineer trying to use TensorFlow Lite Micro to classify paintings, or pictures in general. I started out with Edge Impulse because, well, it’s an easy way to get started. I managed to get the public car detection project to work on an ESP32-cam in not too much time.
But then; classifying paintings… I don’t know why, but it appears there is one dominant class which gets classified more easily than others. That’s the case with three portraits and one unknown class. The confusion matrix, test dataset and test with my mobile phone (with which I’ve made the dataset) all look and work good. When I quantize the model and deploy it to an ESP32, everything appears to work, but one class specifically overshadows another one.
In short; training a MobileNetV1 96×96 rgb network results in a great confusion matrix identifying three portraits. When deployed to an ESP32, one specific class appears to not work. The other three (unknown and two portraits) seem to work correct.
What could be wrong here? Oh and btw, if anyone knows good resources for an embedded systems engineer to get to know ML better, that’s more than welcome.
submitted by /u/JVKran
[visit reddit] [comments]
There is an official example of a Variational AutoEncoder running on MNIST:
https://github.com/keras-team/keras-io/blob/master/examples/generative/vae.py
I downloaded that code to test it on my machine, and I want to save it. So I simply added at the end of the file:
vae.save('model_keras_example')
But that does not work it seems:
WARNING:tensorflow:Skipping full serialization of Keras layer <__main__.VAE object at 0x2abb26a278b0>, because it is not built. Traceback (most recent call last): File "/home/drozd/GAN/keras_example_vae.py", line 199, in <module> vae.save('model_keras_example') File "/opt/ebsofts/TensorFlow/2.6.0-foss-2021a-CUDA-11.3.1/lib/python3.9/site-packages/keras/engine/training.py", line 2145, in save save.save_model(self, filepath, overwrite, include_optimizer, save_format, File "/opt/ebsofts/TensorFlow/2.6.0-foss-2021a-CUDA-11.3.1/lib/python3.9/site-packages/keras/saving/save.py", line 149, in save_model saved_model_save.save(model, filepath, overwrite, include_optimizer, File "/opt/ebsofts/TensorFlow/2.6.0-foss-2021a-CUDA-11.3.1/lib/python3.9/site-packages/keras/saving/saved_model/save.py", line 75, in save saving_utils.raise_model_input_error(model) File "/opt/ebsofts/TensorFlow/2.6.0-foss-2021a-CUDA-11.3.1/lib/python3.9/site-packages/keras/saving/saving_utils.py", line 84, in raise_model_input_error raise ValueError( ValueError: Model <__main__.VAE object at 0x2abb26a278b0> cannot be saved because the input shapes have not been set. Usually, input shapes are automatically determined from calling `.fit()` or `.predict()`. To manually set the shapes, call `model.build(input_shape)`.
I guess I’m not familiar enough with custom models defined as a class. What seems to be the problem here?
I found this: https://stackoverflow.com/questions/69311861/tf2-6-valueerror-model-cannot-be-saved-because-the-input-shapes-have-not-been
which suggests to add a call to compute_output_shape . When I do, it tells me that my custom model needs a call() method but I have no idea how to implement that with a VAE.
Any help would be much appreciated!
Edit : Seems like I can save the encoder and decoder separately:
vae.decoder.save('model_keras_example_decoder') vae.encoder.save('model_keras_example_encoder')
Then I suppose I can build it back afterwards by reusing the same class…
submitted by /u/Milleuros
[visit reddit] [comments]
Within the Mogao Caves, a cultural crossroads along what was the Silk Road in northwestern China, lies a natural reserve of tens of thousands of historical documents, paintings and statues of the Buddha.
The post Meet the Omnivore: 3D Creator Makes Fine Art for Digital Era Inspired by Silk Road Masterpieces appeared first on NVIDIA Blog.