I’ve followed the same steps provided by Apple (https://developer.apple.com/metal/tensorflow-plugin/) to install the deep learning development environment on TensorFlow (based on tensorflow-metal plugin) on my MacBook Pro. My model employs the VGG19 through transfer-learning as its summary can be seen below. While I train this model on 1,859 75×75 RGB images, getting the error tensorflow.python.framework.errors_impl.InternalError: Failed copying input tensor from /job:localhost/replica:0/task:0/device:CPU:0 to /job:localhost/replica:0/task:0/device:GPU:0 in order to run _EagerConst: Dst tensor is not initialized. Isn’t this task an easy one for such a powerful SoC like M1 Pro 10-core CPU, 16-core GPU 16-core Neural Engine with 16 GB RAM? What is the issue here? Is this a bug or do I need to do some configuration to overcome this situation?
Here is the stack trace:
Metal device set to: Apple M1 Pro
systemMemory: 16.00 GB
maxCacheSize: 5.33 GB
Model: “sequential”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg19 (Functional) (None, 512) 20024384
_________________________________________________________________
flatten (Flatten) (None, 512) 0
_________________________________________________________________
dense (Dense) (None, 1859) 953667
=================================================================
Total params: 20,978,051
Trainable params: 953,667
Non-trainable params: 20,024,384
_________________________________________________________________
Traceback (most recent call last):
File “/Users/talhakabakus/PycharmProjects/keras-matlab-comp-metal/run.py”, line 528, in <module>
run_all_stanford_dogs()
File “/Users/talhakabakus/PycharmProjects/keras-matlab-comp-metal/run.py”, line 481, in run_all_stanford_dogs
H = model.fit(X_train, y_train_cat, validation_split=n_val_split, epochs=n_epochs,
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/keras/engine/training.py”, line 1134, in fit
data_handler = data_adapter.get_data_handler(
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/keras/engine/data_adapter.py”, line 1383, in get_data_handler
return DataHandler(*args, **kwargs)
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/keras/engine/data_adapter.py”, line 1138, in __init__
self._adapter = adapter_cls(
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/keras/engine/data_adapter.py”, line 230, in __init__
x, y, sample_weights = _process_tensorlike((x, y, sample_weights))
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/keras/engine/data_adapter.py”, line 1031, in _process_tensorlike
inputs = tf.nest.map_structure(_convert_numpy_and_scipy, inputs)
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/tensorflow/python/util/nest.py”, line 869, in map_structure
structure[0], [func(*x) for x in entries],
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/tensorflow/python/util/nest.py”, line 869, in <listcomp>
structure[0], [func(*x) for x in entries],
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/keras/engine/data_adapter.py”, line 1026, in _convert_numpy_and_scipy
return tf.convert_to_tensor(x, dtype=dtype)
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/tensorflow/python/util/dispatch.py”, line 206, in wrapper
return target(*args, **kwargs)
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/tensorflow/python/framework/ops.py”, line 1430, in convert_to_tensor_v2_with_dispatch
return convert_to_tensor_v2(
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/tensorflow/python/framework/ops.py”, line 1436, in convert_to_tensor_v2
return convert_to_tensor(
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/tensorflow/python/profiler/trace.py”, line 163, in wrapped
return func(*args, **kwargs)
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/tensorflow/python/framework/ops.py”, line 1566, in convert_to_tensor
ret = conversion_func(value, dtype=dtype, name=name, as_ref=as_ref)
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/tensorflow/python/framework/tensor_conversion_registry.py”, line 52, in _default_conversion_function
return constant_op.constant(value, dtype, name=name)
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/tensorflow/python/framework/constant_op.py”, line 271, in constant
return _constant_impl(value, dtype, shape, name, verify_shape=False,
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/tensorflow/python/framework/constant_op.py”, line 283, in _constant_impl
return _constant_eager_impl(ctx, value, dtype, shape, verify_shape)
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/tensorflow/python/framework/constant_op.py”, line 308, in _constant_eager_impl
t = convert_to_eager_tensor(value, ctx, dtype)
File “/Users/talhakabakus/miniforge3/envs/keras-matlab-comp-metal/lib/python3.9/site-packages/tensorflow/python/framework/constant_op.py”, line 106, in convert_to_eager_tensor
return ops.EagerTensor(value, ctx.device_name, dtype)
tensorflow.python.framework.errors_impl.InternalError: Failed copying input tensor from /job:localhost/replica:0/task:0/device:CPU:0 to /job:localhost/replica:0/task:0/device:GPU:0 in order to run _EagerConst: Dst tensor is not initialized.
Process finished with exit code 1



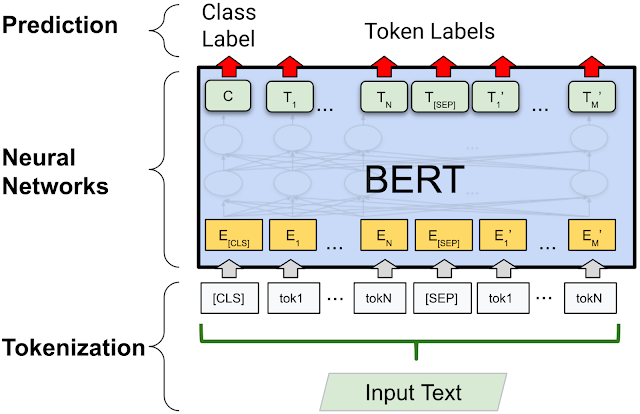


 The groundbreaking technology uses an optical metasurface and machine-learning algorithms to produce high-quality color images with a wide field of view.
The groundbreaking technology uses an optical metasurface and machine-learning algorithms to produce high-quality color images with a wide field of view.