AI can design chips no human could, said Bill Dally in a virtual keynote today at the Design Automation Conference (DAC), one of the world’s largest gatherings of semiconductor engineers. The chief scientist of NVIDIA discussed research in accelerated computing and machine learning that’s making chips smaller, faster and better. “Our work shows you can Read article >
GPU Operator 1.9 includes support NVIDIA DGX A100 systems with DGX OS and streamlined installation processes.
NVIDIA GPU Operator allows organizations to easily scale NVIDIA GPUs on Kubernetes.
By simplifying the deployment and management of GPUs with Kubernetes, the GPU Operator enables infrastructure teams to scale GPU applications error-free, within minutes, automatically.
GPU Operator 1.9 is now available and includes several key features, among other updates, that allow users to get started faster and maintain uninterrupted service.
GPU Operator 1.9 includes:
Support for NVIDIA DGX A100 systems with DGX OS
Streamlined installation process
Support for DGX A100 with DGX OS
With 1.9, the GPU Operator automatically deploys the software required for initializing the fabric on NVIDIA NVSwitch systems, including the DGX A100 when used with DGX OS. Once initialized, all GPUs can communicate with one another at full NVLink bandwidth to create an end-to-end scalable computing platform.
The DGX A100 features the world’s most advanced accelerator, enabling enterprises to consolidate training, inference, and analytics into a unified, easy-to-deploy AI infrastructure. And now, with GPU Operator support, organizations can take their applications from training to scale with the world’s most advanced systems.
Streamlined installation process
With previous versions of GPU Operator, organizations using GPU Operator with OpenShift needed to apply additional entitlements from Red Hat in order to successfully use the GPU Operator. As entitlement keys expired, users would need to re-apply them to ensure that their workflow was not interrupted.
GPU Operator 1.9 now supports entitlement-free driver containers for OpenShift. This is done by leveraging Driver-Toolkit images provided by RedHat with necessary kernel packages preinstalled for building NVIDIA kernel modules. Users no longer need to ensure that valid certificates with an RHEL subscription are always applied for running GPU Operator. More importantly for disconnected clusters, it eliminates dependencies on private package repositories.
Version 1.9 also includes support for preinstalled drivers with the MIG Manager, support for preinstalled MOFED to use GPUDirect RDMA, automatic detection of container runtime, and automatic disabling of NOUVEAU – all designed to make it easier for users to get started and continue GPU-accelerated Kubernetes.
Additionally, GPU Operator 1.9 automatically detects the container runtime installed on the worker node. There is no need to specify the container runtime at install time.
GPU Operator requires Nouveau to be disabled. With previous GPU Operator versions, the K8s admin had to disable Nouveau as documented here. GPU Operator 1.9 automatically detects if Nouveau is enabled and disables it for you.
GPU Operator Resources
The following resources are available for using NVIDIA GPU Operator:
There’s an old axiom that the best businesses thrive during periods of uncertainty. No doubt, that will be tested to the limits as 2022 portends upheaval on a grand scale. Pandemic-related supply chain disruptions are affecting everything from production of cars and electronics to toys and toilet paper. At the same time, global food prices Read article >
Posted by Michael Ryoo, Research Scientist, Robotics at Google and Anurag Arnab, Research Scientist, Google Research
Transformer models consistently obtain state-of-the-art results in computer vision tasks, including object detection and video classification. In contrast to standard convolutional approaches that process images pixel-by-pixel, the Vision Transformers (ViT) treat an image as a sequence of patch tokens (i.e., a smaller part, or “patch”, of an image made up of multiple pixels). This means that at every layer, a ViT model recombines and processes patch tokens based on relations between each pair of tokens, using multi-head self-attention. In doing so, ViT models have the capability to construct a global representation of the entire image.
At the input-level, the tokens are formed by uniformly splitting the image into multiple segments, e.g., splitting an image that is 512 by 512 pixels into patches that are 16 by 16 pixels. At the intermediate levels, the outputs from the previous layer become the tokens for the next layer. In the case of videos, video ‘tubelets’ such as 16x16x2 video segments (16×16 images over 2 frames) become tokens. The quality and quantity of the visual tokens decide the overall quality of the Vision Transformer.
The main challenge in many Vision Transformer architectures is that they often require too many tokens to obtain reasonable results. Even with 16×16 patch tokenization, for instance, a single 512×512 image corresponds to 1024 tokens. For videos with multiple frames, that results in tens of thousands of tokens needing to be processed at every layer. Considering that the Transformer computation increases quadratically with the number of tokens, this can often make Transformers intractable for larger images and longer videos. This leads to the question: is it really necessary to process that many tokens at every layer?
In “TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?”, an earlier version of which is presented at NeurIPS 2021, we show that adaptively generating a smaller number of tokens, rather than always relying on tokens formed by uniform splitting, enables Vision Transformers to run much faster and perform better. TokenLearner is a learnable module that takes an image-like tensor (i.e., input) and generates a small set of tokens. This module could be placed at various different locations within the model of interest, significantly reducing the number of tokens to be handled in all subsequent layers. The experiments demonstrate that having TokenLearner saves memory and computation by half or more without damaging classification performance, and because of its ability to adapt to inputs, it even increases the accuracy.
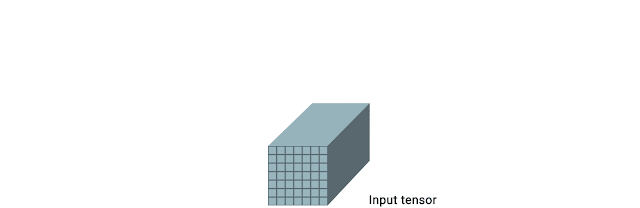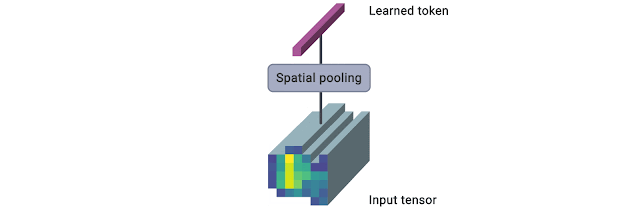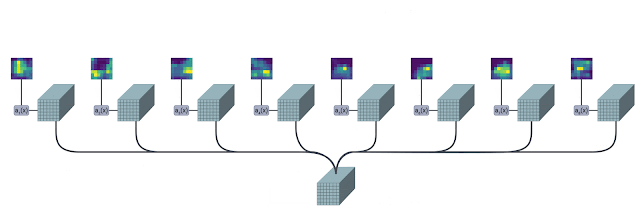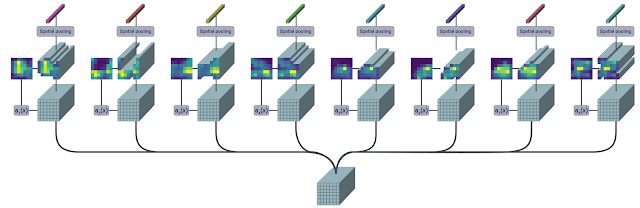
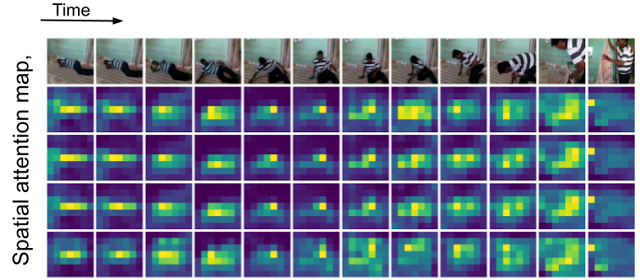
The TokenLearner We implement TokenLearner using a straightforward spatial attention approach. In order to generate each learned token, we compute a spatial attention map highlighting regions-of-importance (using convolutional layers or MLPs). Such a spatial attention map is then applied to the input to weight each region differently (and discard unnecessary regions), and the result is spatially pooled to generate the final learned tokens. This is repeated multiple times in parallel, resulting in a few (~10) tokens out of the original input. This can also be viewed as performing a soft-selection of the pixels based on the weight values, followed by global average pooling. Note that the functions to compute the attention maps are governed by different sets of learnable parameters, and are trained in an end-to-end fashion. This allows the attention functions to be optimized in capturing different spatial information in the input. The figure below illustrates the process.
The TokenLearner module learns to generate a spatial attention map for each output token, and uses it to abstract the input to tokenize. In practice, multiple spatial attention functions are learned, are applied to the input, and generate different token vectors in parallel.
As a result, instead of processing fixed, uniformly tokenized inputs, TokenLearner enables models to process a smaller number of tokens that are relevant to the specific recognition task. That is, (1) we enable adaptive tokenization so that the tokens can be dynamically selected conditioned on the input, and (2) this effectively reduces the total number of tokens, greatly reducing the computation performed by the network. These dynamically and adaptively generated tokens can be used in standard transformer architectures such as ViT for images and ViViT for videos.
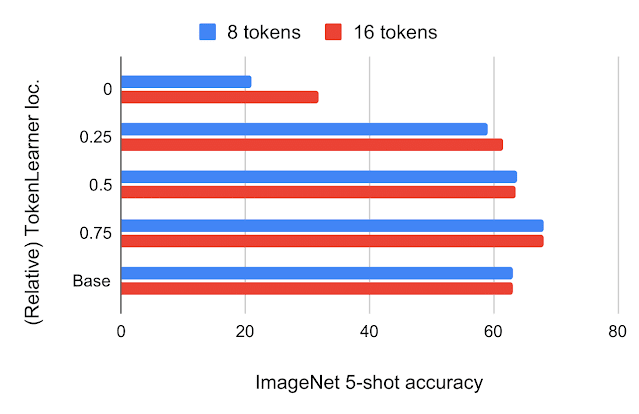
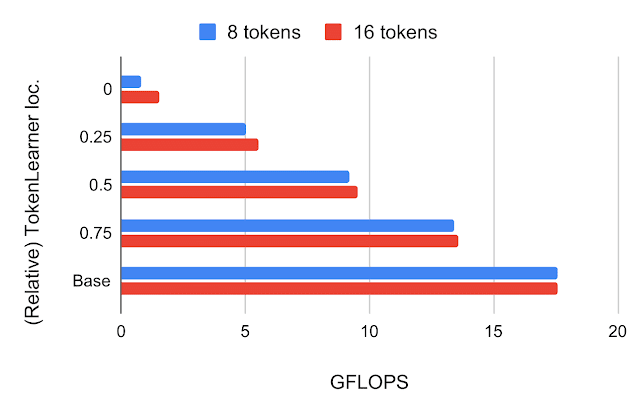
Where to Place TokenLearner After building the TokenLearner module, we had to determine where to place it. We first tried placing it at different locations within the standard ViT architecture with 224×224 images. The number of tokens TokenLearner generated was 8 and 16, much less than 196 or 576 tokens the standard ViTs use. The below figure shows ImageNet few-shot classification accuracies and FLOPS of the models with TokenLearner inserted at various relative locations within ViT B/16, which is the base model with 12 attention layers operating on 16×16 patch tokens.
Top: ImageNet5-shot transfer accuracy with JFT 300M pre-training, with respect to the relative TokenLearner locations within ViT B/16. Location 0 means TokenLearner is placed before any Transformer layer. Base is the original ViT B/16. Bottom: Computation, measured in terms of billions of floating point operations (GFLOPS), per relative TokenLearner location.
We found that inserting TokenLearner after the initial quarter of the network (at 1/4) achieves almost identical accuracies as the baseline, while reducing the computation to less than a third of the baseline. In addition, placing TokenLearner at the later layer (after 3/4 of the network) achieves even better performance compared to not using TokenLearner while performing faster, thanks to its adaptiveness. Due to the large difference between the number of tokens before and after TokenLearner (e.g., 196 before and 8 after), the relative computation of the transformers after the TokenLearner module becomes almost negligible.
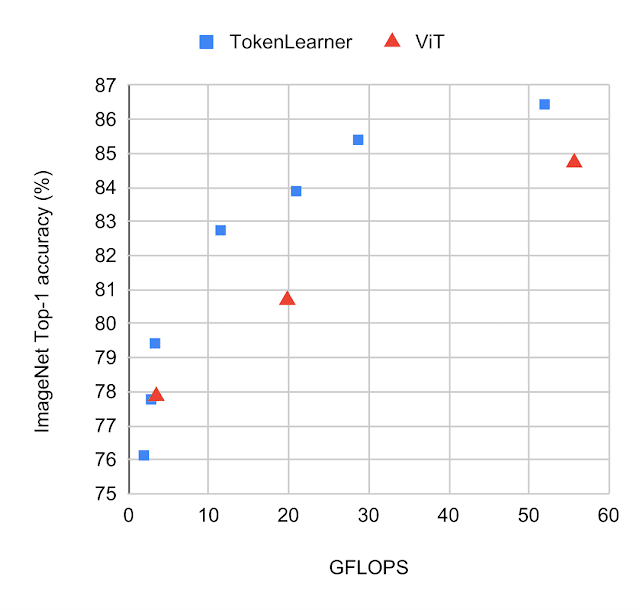
Comparing Against ViTs We compared the standard ViT models with TokenLearner against those without it while following the same setting on ImageNet few-shot transfer. TokenLearner was placed in the middle of each ViT model at various locations such as at 1/2 and at 3/4. The below figure shows the performance/computation trade-off of the models with and without TokenLearner.
Performance of various versions of ViT models with and without TokenLearner, on ImageNet classification. The models were pre-trained with JFT 300M. The closer a model is to the top-left of each graph the better, meaning that it runs faster and performs better. Observe how TokenLearner models perform better than ViT in terms of both accuracy and computation.
We also inserted TokenLearner within larger ViT models, and compared them against the giant ViT G/14 model. Here, we applied TokenLearner to ViT L/10 and L/8, which are the ViT models with 24 attention layers taking 10×10 (or 8×8) patches as initial tokens. The below figure shows that despite using many fewer parameters and less computation, TokenLearner performs comparably to the giant G/14 model with 48 layers.
Left: Classification accuracy of large-scale TokenLearner models compared to ViT G/14 on ImageNet datasets. Right: Comparison of the number of parameters and FLOPS.
High-Performing Video Models Video understanding is one of the key challenges in computer vision, so we evaluated TokenLearner on multiple video classification datasets. This was done by adding TokenLearner into Video Vision Transformers (ViViT), which can be thought of as a spatio-temporal version of ViT. TokenLearner learned 8 (or 16) tokens per timestep.
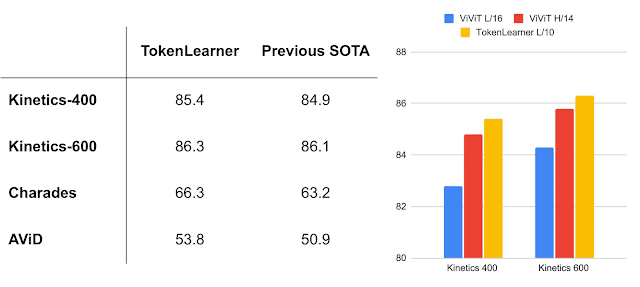
When combined with ViViT, TokenLearner obtains state-of-the-art (SOTA) performance on multiple popular video benchmarks, including Kinetics-400, Kinetics-600, Charades, and AViD, outperforming the previous Transformer models on Kinetics-400 and Kinetics-600 as well as previous CNN models on Charades and AViD.
Models with TokenLearner outperform state-of-the-art on popular video benchmarks (captured from Nov. 2021). Left: popular video classification tasks. Right: comparison to ViViT models.
Visualization of the spatial attention maps in TokenLearner, over time. As the person is moving in the scene, TokenLearner pays attention to different spatial locations to tokenize.
Conclusion While Vision Transformers serve as powerful models for computer vision, a large number of tokens and their associated computation amount have been a bottleneck for their application to larger images and longer videos. In this project, we illustrate that retaining such a large number of tokens and fully processing them over the entire set of layers is not necessary. Further, we demonstrate that by learning a module that extracts tokens adaptively based on the input image allows attaining even better performance while saving compute. The proposed TokenLearner was particularly effective in video representation learning tasks, which we confirmed with multiple public datasets. A preprint of our work as well as code are publicly available.
Acknowledgement We thank our co-authors: AJ Piergiovanni, Mostafa Dehghani, and Anelia Angelova. We also thank the Robotics at Google team members for the motivating discussions.
I’m at my wits end, every single tutorial for classification I find for Tensorflow 1.x is a goddamn MNIST tutorial, they always skip the basics, and I need the basics.
I have a test set with 6 numerical features and a label that is binary 1 or 0.
With Tensorflow 2.0 I can easily just use something like this
model = tf.keras.Sequential([ tf.keras.layers.Dense(21, activation="tanh"), tf.keras.layers.Dense(10, activation="sigmoid"), tf.keras.layers.Dense(1, activation="sigmoid") ]) model.compile( loss=tf.keras.losses.binary_crossentropy, optimizer=tf.keras.optimizers.Adam(0.001), metrics=['accuracy'] ) history = model.fit(X_train, y_train, epochs=25)
For the life of me I don’t know how to go about doing this in Tensorflow 1.x.
At the forefront of AI innovation, NVIDIA continues to push the boundaries of technology in machine learning, self-driving cars, robotics, graphics, and more.
At the forefront of AI innovation, NVIDIA continues to push the boundaries of technology in machine learning, self-driving cars, robotics, graphics, and more. NVIDIA researchers will present 20 papers at the thirty-fifth annual conference on Neural Information Processing Systems (NeurIPS) from December 6 to December 14, 2021.
Here are some of the featured papers:
Alias-Free Generative Adversarial Networks (StyleGAN3) Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, Timo Aila | Paper | GitHub | Blog
StyleGAN3, a model developed by NVIDIA Research, will be presented on Tuesday, December 7 from 12:40 AM – 12:55 AM PST, advances the state-of-the-art in generative adversarial networks used to synthesize realistic images. The breakthrough brings graphics principles in signal processing and image processing to GANs to avoid aliasing: a kind of image corruption often visible when images are rotated, scaled or translated.
Video 1. Results from the StyleGAN3 model
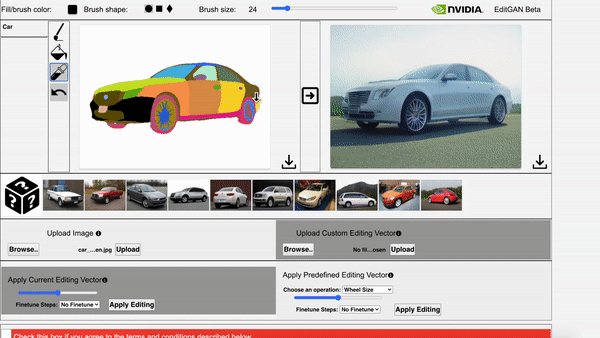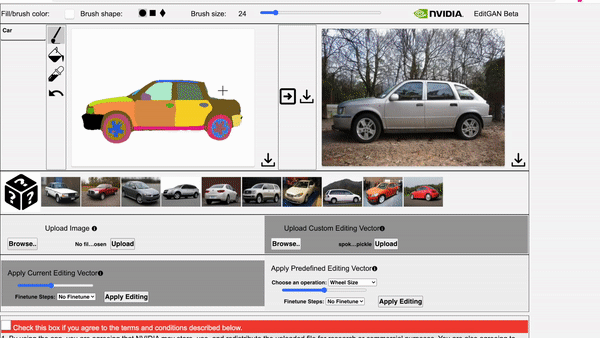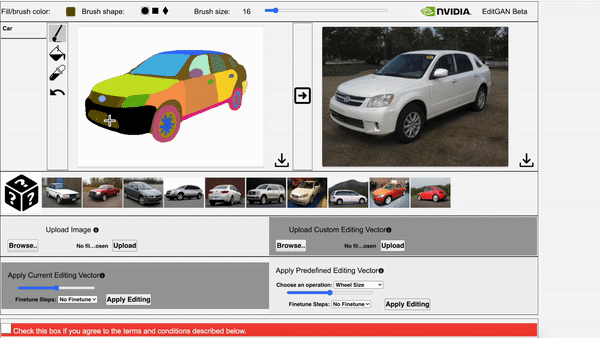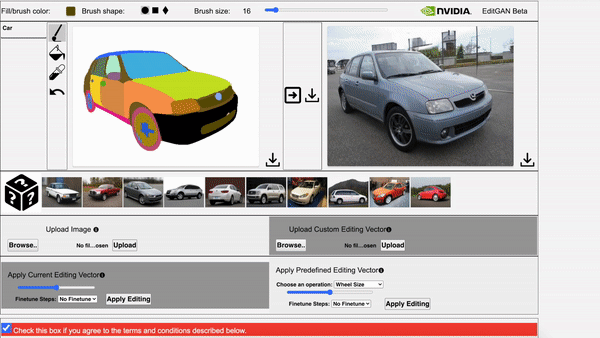
EditGAN: High-Precision Semantic Image Editing Huan Ling*, Karsten Kreis*, Daiqing Li, Seung Wook Kim, Antonio Torralba, Sanja Fidler | Paper | GitHub
EditGAN, a novel method for high quality, high precision semantic image editing, allowing users to edit images by modifying their highly detailed part segmentation masks, e.g., drawing a new mask for the headlight of a car. EditGAN builds on a GAN framework that jointly models images and their semantic segmentations, requiring only a handful of labeled examples, making it a scalable tool for editing. The poster session will be held on Thursday, December 9 from 8:30 AM – 10:00 AM PST.
Video 2. The video showcases EditGAN in an interactive demo tool.
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo | Paper | GitHub
SegFormer, a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with lightweight multilayer perception (MLP) decoders. SegFormer has two appealing features: 1) SegFormer comprises a novel hierarchically structured Transformer encoder which outputs multiscale features. It does not need positional encoding, thereby avoiding the interpolation of positional codes which leads to decreased performance when the testing resolution differs from training. 2) SegFormer avoids complex decoders. The poster will be presented on Tuesday, December 7 from 8:30 AM – 10:00 AM PST.
Video 3. The video shows the excellent zero-shot robustness of SegFormer on the Cityscapes-C dataset.
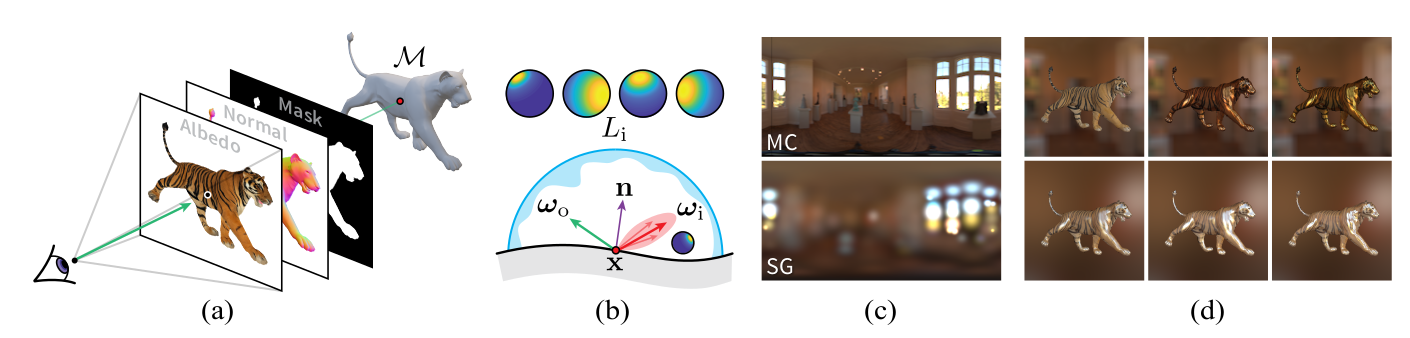
DIB-R++: Learning to Predict Lighting and Material with a Hybrid Differentiable Renderer Wenzheng Chen, Joey Litalien, Jun Gao, Zian Wang, Clement Fuji Tsang, Sameh Khamis, Or Litany, Sanja Fidler | Paper
DIB-R++, a deferred, image-based renderer which supports these photorealistic effects by combining rasterization and ray-tracing, taking advantage of their respective strengths—speed and realism. The poster session is on Thursday, December 9 from 4:30 PM – 6:00 PM PST.
Image 1. DIB-R++ is a hybrid renderer that combines rasterization and ray tracing together. Given a 3D mesh M, we employ (a) a rasterization-based renderer to obtain diffuse albedo, surface normals and mask maps. In the shading pass (b), we then use these buffers to compute the incident radiance by sampling or by representing lighting and the specular BRDF using a spherical Gaussian basis. Depending on the representation used in (c), we can render with advanced lighting and material effect (d).
In addition to the papers at NeurIPS 2021, researchers and developers can accelerate 3D deep learning research with new Kaolin features:
Kaolin is launching new features to accelerate 3D deep learning research. Updates to the NVIDIA Omniverse Kaolin app will bring robust visualization of massive point clouds. Updates to the Kaolin library will include support for tetrahedral meshes, rays management functionality, and a strong speedup to DIB-R. To learn more about Kaolin, watch the recent GTC session.
Image 2. Results from NVIDIA Kaolin
To view the complete list of NVIDIA Research accepted papers, workshop and tutorials, demos, and to explore job opportunities at NVIDIA, visit the NVIDIA at NeurIPS 2021 website.
hi, i tried to load model on cpu with tf.device while inference of 500 images , the cpu usage resches to 100% , inference time is 0.6sec and how do I minimize the inference time and also the utilization of cpu .
I am trying to increase the training speed of my model by using mixed precision and the nvidia gpu tensor cores. For this, I just use the keras mixed precision, but the speed increment is only of 10%. Then I found the nividia ngc container, which is optimized for their gpus, and with mixed precision I can increase the training speed a 60%, although with float32 the speed in lower than native. I would like to have at least the speed increase of ngc container natively, what do I need to do?
Dive deep into the new features and use cases available for networking, security, storage in the latest release of the DOCA software framework.
Today, NVIDIA released the NVIDIA DOCA 1.2 software framework for NVIDIA BlueField DPUs, the world’s most advanced data processing unit (DPU). Designed to enable the NVIDIA BlueField ecosystem and developer community, DOCA is the key to unlocking the potential of the DPU by offering services to offload, accelerate, and isolate infrastructure applications services from the CPU.
DOCA is a software framework that brings together APIs, drivers, libraries, sample code, documentation, services, and prepackaged containers to simplify and speed up application development and deployment on BlueField DPUs on every data center node. Together, DOCA and BlueField create an isolated and secure services domain for networking, security, storage, and infrastructure management that is ideal for enabling a zero-trust strategy.
The DOCA 1.2 release introduces several important features and use cases.
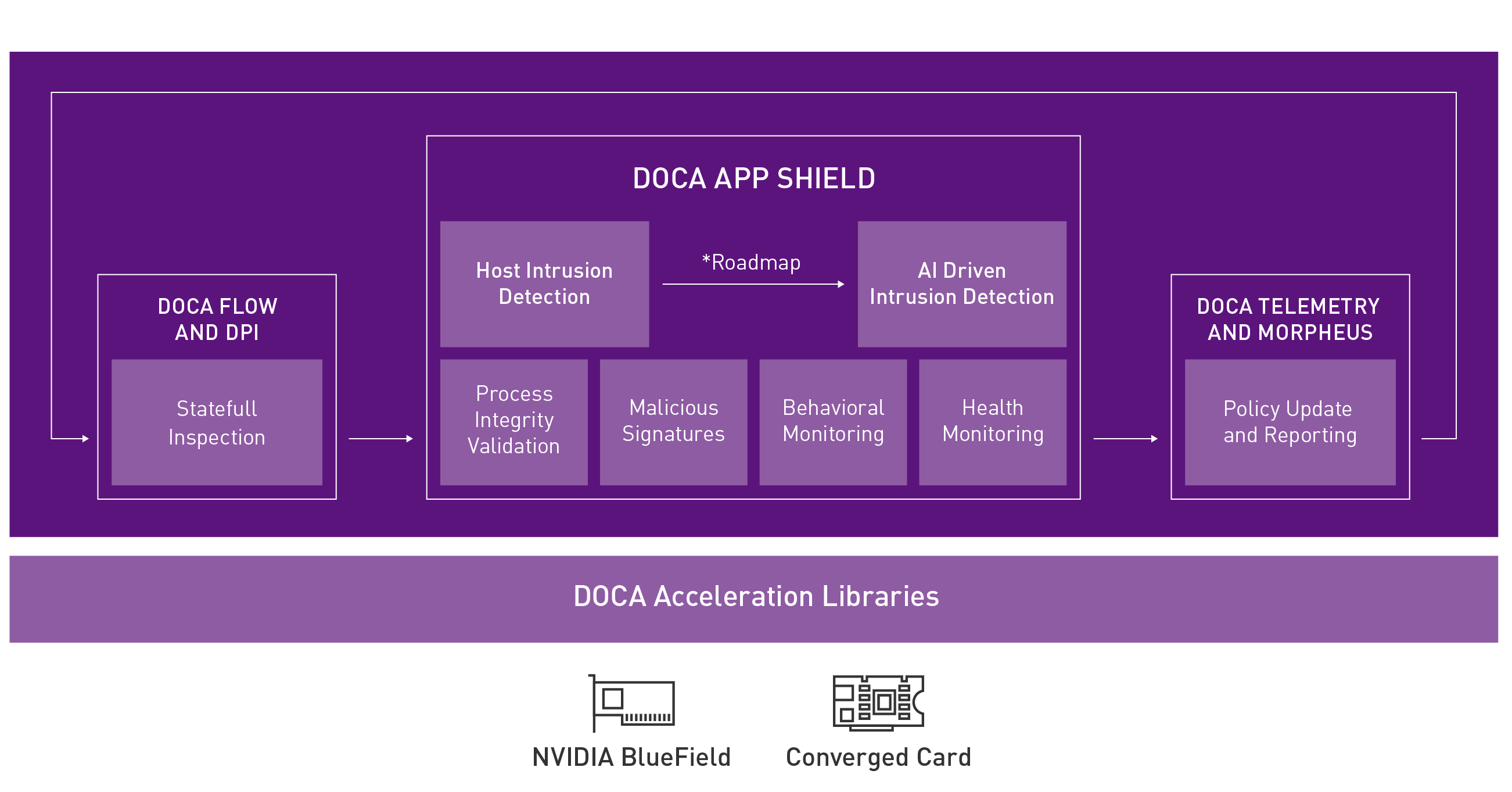
Protect host services with adaptive cloud security
A modern approach to security based on zero trust principles is critical to securing today’s data centers, as resources inside the data center can no longer be trusted automatically. App Shield enables detection of attacks on critical services in a system. In many systems, those critical services are responsible for ensuring the integrity and privacy of the execution of many applications.
Figure 1. Shield your host services with adaptive cloud security
DOCA App Shield provides host monitoring enabling cybersecurity vendors to create accelerated intrusion detection system (IDS) solutions to identify an attack on any physical or virtual machine. It can feed data about application status to security information and event management (SIEM) or extended detection and response (XDR) tools and also enhances forensic investigations.
If a host is compromised, attackers normally exploit the security control mechanism breaches to move laterally across data center networks to other servers and devices. App Shield enables security teams to shield their application processes, continuously validate their integrity, and in turn detect malicious activity.
In the event that an attacker kills the machine security agent’s processes, App Shield can mitigate the attack by isolating the compromised host, preventing the malware from accessing confidential data or spreading to other resources. App Shield is an important advancement in the fight against cybercrime and an effective tool to enable a zero-trust security stance.
BlueField DPUs and the DOCA software framework provide an open foundation for partners and developers to build zero-trust solutions and address the security needs of the modern data center. Together, DOCA and BlueField create an isolated and secure services domain for networking, security, storage, and infrastructure management that is ideal for enabling a zero-trust strategy.
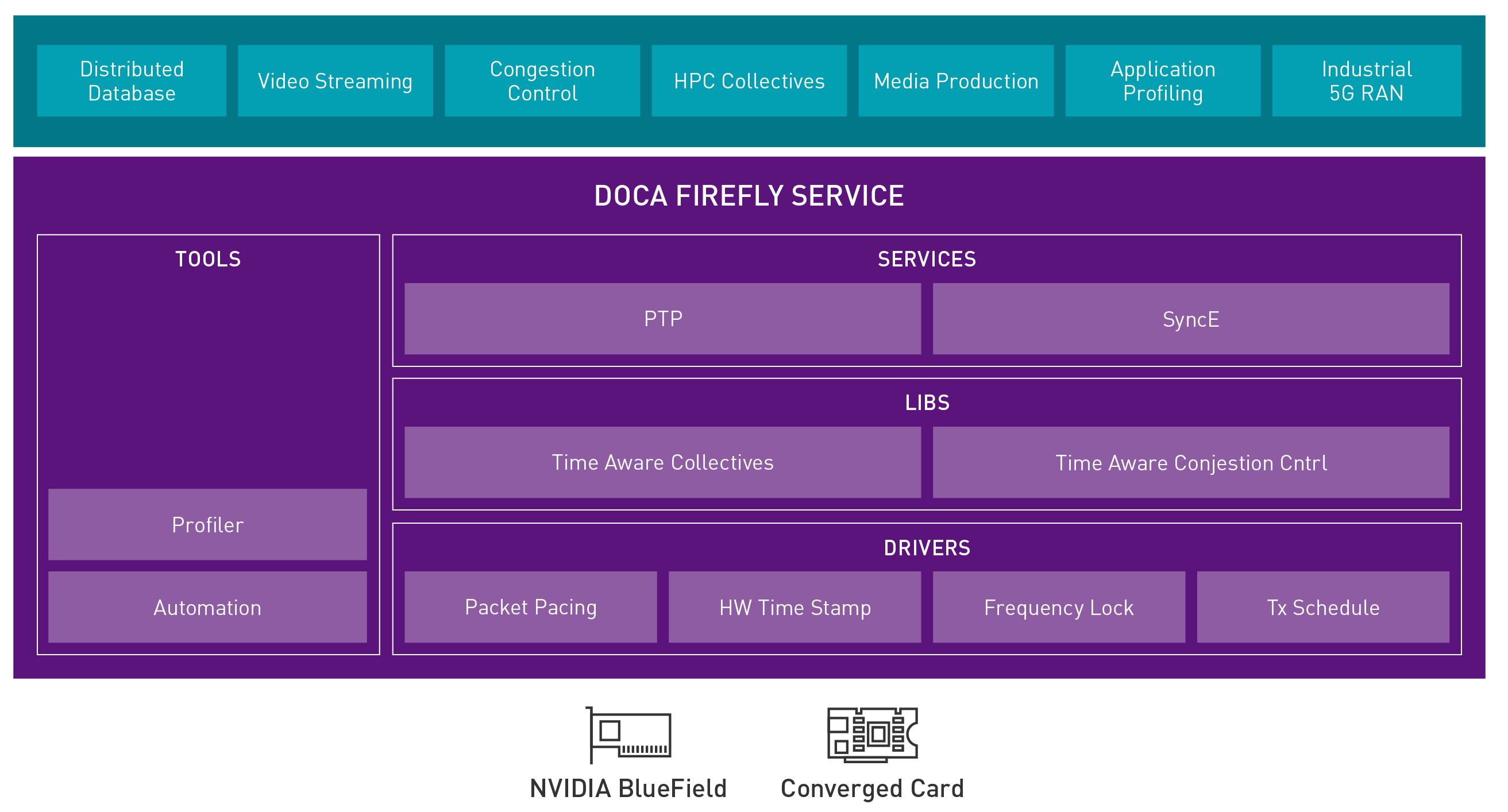
Create time-synchronized data centers
Precision timing is a critical capability to enable and accelerate distributed apps from edge to core. DOCA Firefly is a data center timing service that supports extremely precise time synchronization everywhere. With nanosecond-level clock synchronization, you can enable a new broad range of timing-critical and delay-sensitive applications.
Figure 2. Precision time-synchronized data center service
DOCA Firefly addresses a wide range of use cases, including the following:
High-frequency trading
Distributed databases
Industrial 5G radio access networks (RAN)
Scientific research
High performance computing (HPC)
Omniverse digital twins
Gaming
AR/VR
Autonomous vehicles
Security
It enables data consistency, accurate event ordering, and causality analysis, such as ensuring the correct sequencing of stock market transactions and fair bidding during digital auctions. The hardware engines in the BlueField application-specific integrated circuit (ASIC) are capable of time-stamping data packets at full wire speed with breakthrough nanosecond-level accuracy.
Improving the accuracy of data center timing by orders of magnitude offers many advantages.
With globally synchronized data centers, you can accelerate distributed applications and data analysis including AI, HPC, professional media production, telco virtual network functions, and precise event monitoring. All the servers in the data center—or across data centers—can be harmonized to provide something that is far bigger than any single compute node.
The benefits of improving data center timing accuracy include a reduction in the amount of compute power and network traffic needed to replicate and validate the data. For example, Firefly synchronization delivers a 3x database performance gain to distributed databases.
DOCA HBN beta
The BlueField DPU is a unique solution for network acceleration and policy enforcement within an endpoint host. At the same time, BlueField provides an administrative and software demarcation between the host operating system and functions running on the DPU.
With DOCA host-based networking (HBN), top-of-rack (TOR) network configuration can extend down to the DPU, enabling network administrators to own DPU configuration and management while application management can be handled separately by x86 host administrators. This creates an unparalleled opportunity to reimagine how you can build data center networks.
DOCA 1.2 provides a new driver for HBN called Netlink to DOCA (nl2doca) that accelerates and offloads traditional Linux Netlink messages. nl2doca is provided as an acceleration driver integrated as part of the HBN service container. You can now accelerate host networking for L2 and L3 that relies on DPDK, OVS, or now kernel routing with Netlink.
NVIDIA is adding support for the open-source Free Range Routing (FRR) project, running on the DPU and leveraging this new nl2doca driver. This support enables the DPU to operate exactly like a TOR switch plus additional benefits. FRR on the DPU enables EVPN networks to move directly into the host, providing layer 2 (VLAN) extension and layer 3 (VRF) tenant isolation.
HBN on the DPU can manage and monitor traffic between VMs or containers on the same node. It can also analyze and encrypt or decrypt then analyze traffic to and from the node, both tasks that no ToR switch can perform. You can build your own Amazon VPC-like solution in your private cloud for containerized, virtual machine, and bare metal workloads.
HBN with BlueField DPUs revolutionizes how you build data center networks. It offers the following benefits:
Plug-and-play servers: Leveraging FRR’s BGP unnumbered, servers can be directly connected to the network with no need to coordinate server-to-switch configurations. No need for MLAG, bonding, or NIC teaming.
Open, interoperable multi-tenancy: EVPN enables server-to-server or server-to-switch overlays. This provides multi-tenant solutions for bare metal, closed appliances, or any hypervisor solution, regardless of the underlay networking vendor. EVPN provides distributed overlay configuration, while eliminating the need for costly, proprietary, centralized SDN controllers.
Secure network management: The BlueField DPU provides an isolated environment for network policy configuration and enforcement. There are no software or dependencies on the host.
Enabling advanced HCI and storage networking: BlueField provides a simple method for HCI and storage partners to solve current network challenges for multi-tenant and hybrid cloud solutions, regardless of the hypervisor.
Flexible network offloading: The nl2doca driver provided by HBN enables any netlink capable application to offload and accelerate kernel based networking without the complexities of traditional DPDK libraries.
Simplification of TOR switch requirements: More intelligence is placed on the DPU within the server, reducing the complexity of the TOR switch.
Additional DOCA 1.2 SDK updates:
DOCA FLOW – Firewall (Alpha)
DOCA FLOW – Gateway (Beta)
DOCA FLOW remote APIs
DOCA 1.2 includes enhancements and scale for IPsec and TLS
DLI course: Introduction to DOCA for the BlueField DPU
In addition, NVIDIA is introducing a Deep Learning Institute (DLI) course: Introduction to DOCA for the BlueField DPU. The main objective of this course is to provide students, including developers, researchers, and system administrators, with an introduction to DOCA and BlueField DPUs. This enables students to successfully work with DOCA to create accelerated applications and services powered by BlueField DPUs.
Try DOCA today
You can experience DOCA today with the DOCA software, which includes DOCA SDK and runtime accelerated libraries for networking, storage, and security. The libraries help you program your data center infrastructure running on the DPU.
The DOCA Early Access program is open now for applications. To receive news and updates about DOCA or to become an early access member/partner, register on the DOCA Early Access page.
For more information, see the following resources:

 GPU Operator 1.9 includes support NVIDIA DGX A100 systems with DGX OS and streamlined installation processes.
GPU Operator 1.9 includes support NVIDIA DGX A100 systems with DGX OS and streamlined installation processes.