
Earlier this year, we launched Contactless Sleep Sensing in Nest Hub, an opt-in feature that can help users better understand their sleep patterns and nighttime wellness. While some of the most critical sleep insights can be derived from a person’s overall schedule and duration of sleep, that alone does not tell the complete story. The human brain has special neurocircuitry to coordinate sleep cycles — transitions between deep, light, and rapid eye movement (REM) stages of sleep — vital not only for physical and emotional wellbeing, but also for optimal physical and cognitive performance. Combining such sleep staging information with disturbance events can help you better understand what’s happening while you’re sleeping.
Today we announced enhancements to Sleep Sensing that provide deeper sleep insights. While not intended for medical purposes1, these enhancements allow better understanding of sleep through sleep stages and the separation of the user’s coughs and snores from other sounds in the room. Here we describe how we developed these novel technologies, through transfer learning techniques to estimate sleep stages and sensor fusion of radar and microphone signals to disambiguate the source of sleep disturbances.
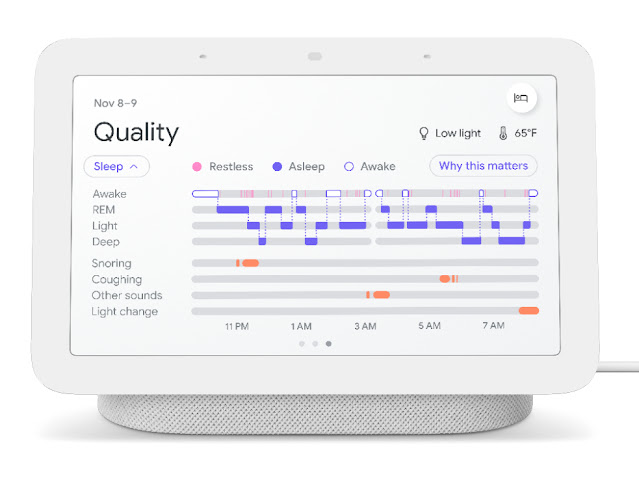 |
| To help people understand their sleep patterns, Nest Hub displays a hypnogram, plotting the user’s sleep stages over the course of a sleep session. Potential sound disturbances during sleep will now include “Other sounds” in the timeline to separate the user’s coughs and snores from other sound disturbances detected from sources in the room outside of the calibrated sleeping area. |
Training and Evaluating the Sleep Staging Classification Model
Most people cycle through sleep stages 4-6 times a night, about every 80-120 minutes, sometimes with a brief awakening between cycles. Recognizing the value for users to understand their sleep stages, we have extended Nest Hub’s sleep-wake algorithms using Soli to distinguish between light, deep, and REM sleep. We employed a design that is generally similar to Nest Hub’s original sleep detection algorithm: sliding windows of raw radar samples are processed to produce spectrogram features, and these are continuously fed into a Tensorflow Lite model. The key difference is that this new model was trained to predict sleep stages rather than simple sleep-wake status, and thus required new data and a more sophisticated training process.
In order to assemble a rich and diverse dataset suitable for training high-performing ML models, we leveraged existing non-radar datasets and applied transfer learning techniques to train the model. The gold standard for identifying sleep stages is polysomnography (PSG), which employs an array of wearable sensors to monitor a number of body functions during sleep, such as brain activity, heartbeat, respiration, eye movement, and motion. These signals can then be interpreted by trained sleep technologists to determine sleep stages.
To develop our model, we used publicly available data from the Sleep Heart Health Study (SHHS) and Multi-ethnic Study of Atherosclerosis (MESA) studies with over 10,000 sessions of raw PSG sensor data with corresponding sleep staging ground-truth labels, from the National Sleep Research Resource. The thoracic respiratory inductance plethysmography (RIP) sensor data within these PSG datasets is collected through a strap worn around the patient’s chest to measure motion due to breathing. While this is a very different sensing modality from radar, both RIP and radar provide signals that can be used to characterize a participant’s breathing and movement. This similarity between the two domains makes it possible to leverage a plethysmography-based model and adapt it to work with radar.
To do so, we first computed spectrograms from the RIP time series signals and used these as features to train a convolutional neural network (CNN) to predict the groundtruth sleep stages. This model successfully learned to identify breathing and motion patterns in the RIP signal that could be used to distinguish between different sleep stages. This indicated to us that the same should also be possible when using radar-based signals.
To test the generality of this model, we substituted similar spectrogram features computed from Nest Hub’s Soli sensor and evaluated how well the model was able to generalize to a different sensing modality. As expected, the model trained to predict sleep stages from a plethysmograph sensor was much less accurate when given radar sensor data instead. However, the model still performed much better than chance, which demonstrated that it had learned features that were relevant across both domains.
To improve on this, we collected a smaller secondary dataset of radar sensor data with corresponding PSG-based groundtruth labels, and then used a portion of this dataset to fine-tune the weights of the initial model. This smaller amount of additional training data allowed the model to adapt the original features it had learned from plethysmography-based sleep staging and successfully generalize them to our domain. When evaluated on an unseen test set of new radar data, we found the fine-tuned model produced sleep staging results comparable to that of other consumer sleep trackers.
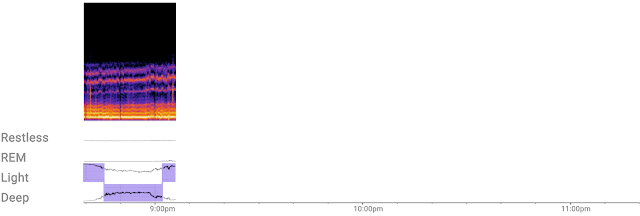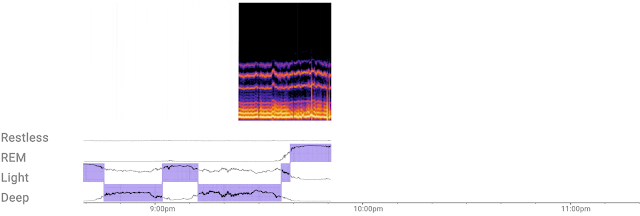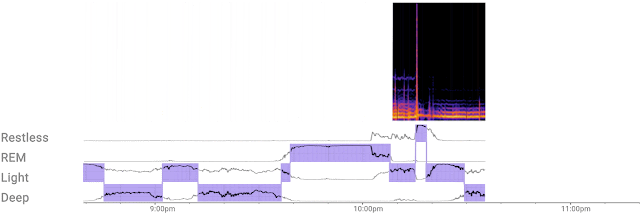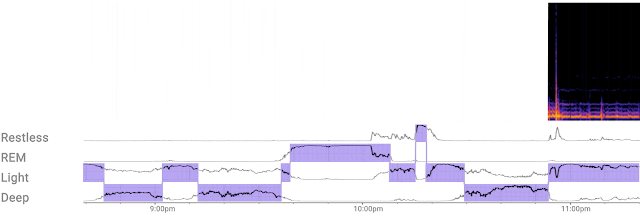 |
| The custom ML model efficiently processes a continuous stream of 3D radar tensors (as shown in the spectrogram at the top of the figure) to automatically compute probabilities of each sleep stage — REM, light, and deep — or detect if the user is awake or restless. |
More Intelligent Audio Sensing Through Audio Source Separation
Soli-based sleep tracking gives users a convenient and reliable way to see how much sleep they are getting and when sleep disruptions occur. However, to understand and improve their sleep, users also need to understand why their sleep may be disrupted. We’ve previously discussed how Nest Hub can help monitor coughing and snoring, frequent sources of sleep disturbances of which people are often unaware. To provide deeper insight into these disturbances, it is important to understand if the snores and coughs detected are your own.
The original algorithms on Nest Hub used an on-device, CNN-based detector to process Nest Hub’s microphone signal and detect coughing or snoring events, but this audio-only approach did not attempt to distinguish from where a sound originated. Combining audio sensing with Soli-based motion and breathing cues, we updated our algorithms to separate sleep disturbances from the user-specified sleeping area versus other sources in the room. For example, when the primary user is snoring, the snoring in the audio signal will correspond closely with the inhalations and exhalations detected by Nest Hub’s radar sensor. Conversely, when snoring is detected outside the calibrated sleeping area, the two signals will vary independently. When Nest Hub detects coughing or snoring but determines that there is insufficient correlation between the audio and motion features, it will exclude these events from the user’s coughing or snoring timeline and instead note them as “Other sounds” on Nest Hub’s display. The updated model continues to use entirely on-device audio processing with privacy-preserving analysis, with no raw audio data sent to Google’s servers. A user can then opt to save the outputs of the processing (sound occurrences, such as the number of coughs and snore minutes) in Google Fit, in order to view their night time wellness over time.
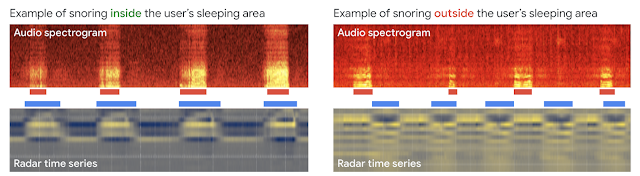 |
| Snoring sounds that are synchronized with the user’s breathing pattern (left) will be displayed in the user’s Nest Hub’s Snoring timeline. Snoring sounds that do not align with the user’s breathing pattern (right) will be displayed in Nest Hub’s “Other sounds” timeline. |
Since Nest Hub with Sleep Sensing launched, researchers have expressed interest in investigational studies using Nest Hub’s digital quantification of nighttime cough. For example, a small feasibility study supported by the Cystic Fibrosis Foundation2 is currently underway to evaluate the feasibility of measuring night time cough using Nest Hub in families of children with cystic fibrosis (CF), a rare inherited disease, which can result in a chronic cough due to mucus in the lungs. Researchers are exploring if quantifying cough at night could be a proxy for monitoring response to treatment.
Conclusion
Based on privacy-preserving radar and audio signals, these improved sleep staging and audio sensing features on Nest Hub provide deeper insights that we hope will help users translate their night time wellness into actionable improvements for their overall wellbeing.
Acknowledgements
This work involved collaborative efforts from a multidisciplinary team of software engineers, researchers, clinicians, and cross-functional contributors. Special thanks to Dr. Logan Schneider, a sleep neurologist whose clinical expertise and contributions were invaluable to continuously guide this research. In addition to the authors, key contributors to this research include Anupam Pathak, Jeffrey Yu, Arno Charton, Jian Cui, Sinan Hersek, Jonathan Hsu, Andi Janti, Linda Lei, Shao-Po Ma, Jo Schaeffer, Neil Smith, Siddhant Swaroop, Bhavana Koka, Dr. Jim Taylor, and the extended team. Thanks to Mark Malhotra and Shwetak Patel for their ongoing leadership, as well as the Nest, Fit, and Assistant teams we collaborated with to build and validate these enhancements to Sleep Sensing on Nest Hub.
1Not intended to diagnose, cure, mitigate, prevent or treat any disease or condition. ↩
2Google did not have any role in study design, execution, or funding. ↩


















")
 Recommender systems are the economic engine of the Internet. It is hard to imagine any other type of applications with more direct impact in our daily digital lives: Trillions of items to be recommended to billions of people. Recommender systems filter products and services among an overwhelming number of options, easing the paradox of choice …
Recommender systems are the economic engine of the Internet. It is hard to imagine any other type of applications with more direct impact in our daily digital lives: Trillions of items to be recommended to billions of people. Recommender systems filter products and services among an overwhelming number of options, easing the paradox of choice … 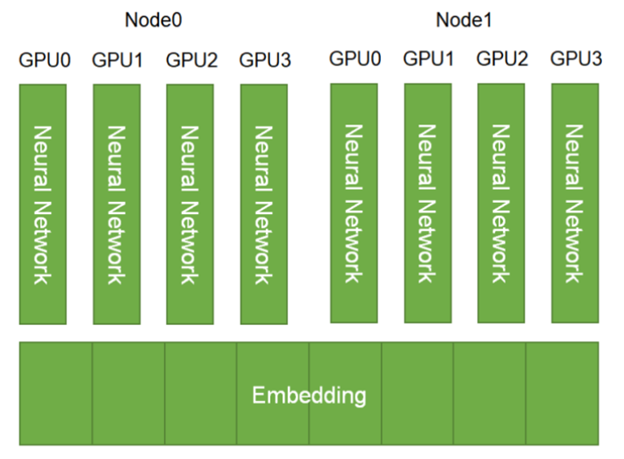
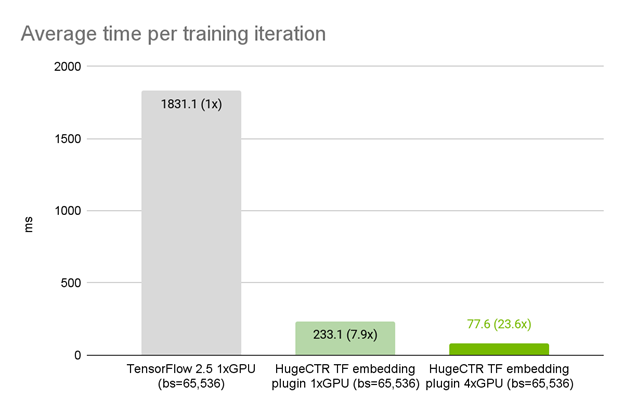
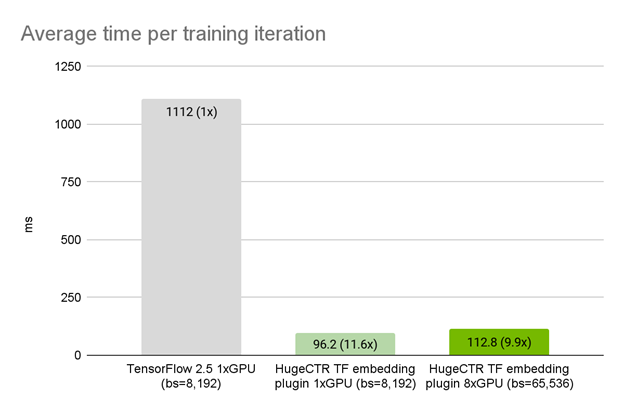
{kind=link}
{kind=link}