An accurate record of building footprints is important for a range of applications, from population estimation and urban planning to humanitarian response and environmental science. After a disaster, such as a flood or an earthquake, authorities need to estimate how many households have been affected. Ideally there would be up-to-date census information for this, but in practice such records may be out of date or unavailable. Instead, data on the locations and density of buildings can be a valuable alternative source of information.
A good way to collect such data is through satellite imagery, which can map the distribution of buildings across the world, particularly in areas that are isolated or difficult to access. However, detecting buildings with computer vision methods in some environments can be a challenging task. Because satellite imaging involves photographing the earth from several hundred kilometres above the ground, even at high resolution (30–50 cm per pixel), a small building or tent shelter occupies only a few pixels. The task is even more difficult for informal settlements, or rural areas where buildings constructed with natural materials can visually blend into the surroundings. There are also many types of natural and artificial features that can be easily confused with buildings in overhead imagery.
 |
| Objects that can confuse computer vision models for building identification (clockwise from top left) pools, rocks, enclosure walls and shipping containers. |
In “Continental-Scale Building Detection from High-Resolution Satellite Imagery”, we address these challenges, using new methods for detecting buildings that work in rural and urban settings across different terrains, such as savannah, desert, and forest, as well as informal settlements and refugee facilities. We use this building detection model to create the Open Buildings dataset, a new open-access data resource containing the locations and footprints of 516 million buildings with coverage across most of the African continent. The dataset will support several practical, scientific and humanitarian applications, ranging from disaster response or population mapping to planning services such as new medical facilities or studying human impact on the natural environment.
Model Development
We built a training dataset for the building detection model by manually labelling 1.75 million buildings in 100k images. The figure below shows some examples of how we labelled images in the training data, taking into account confounding characteristics of different areas across the African continent. In rural areas, for example, it was necessary to identify different types of dwelling places and to disambiguate them from natural features, while in urban areas we needed to develop labelling policies for dense and contiguous structures.
 |
| (1) Example of a compound containing both dwelling places as well as smaller outbuildings such as grain stores. (2) Example of a round, thatched-roof structure that can be difficult for a model to distinguish from trees, and where it is necessary to use cues from pathways, clearings and shadows to disambiguate. (3) Example of several contiguous buildings for which the boundaries cannot be easily distinguished. |
We trained the model to detect buildings in a bottom-up way, first by classifying each pixel as building or non-building, and then grouping these pixels together into individual instances. The detection pipeline was based on the U-Net model, which is commonly used in satellite image analysis. One advantage of U-Net is that it is a relatively compact architecture, and so can be applied to large quantities of imaging data without a heavy compute burden. This is critical, because the final task of applying this to continental-scale satellite imagery means running the model on many billions of image tiles.
 |
| Example of segmenting buildings in satellite imagery. Left: Source image; Center: Semantic segmentation, with each pixel assigned a confidence score that it is a building vs. non-building; Right: Instance segmentation, obtained by thresholding and grouping together connected components. |
Initial experiments with the basic model had low precision and recall, for example due to the variety of natural and artificial features with building-like appearance. We found a number of methods that improved performance. One was the use of mixup as a regularisation method, where random training images are blended together by taking a weighted average. Though mixup was originally proposed for image classification, we modified it to be used for semantic segmentation. Regularisation is important in general for this building segmentation task, because even with 100k training images, the training data do not capture the full variation of terrain, atmospheric and lighting conditions that the model is presented with at test time, and hence, there is a tendency to overfit. This is mitigated by mixup as well as random augmentation of training images.
Another method that we found to be effective was the use of unsupervised self-training. We prepared a set of 100 million satellite images from across Africa, and filtered these to a subset of 8.7 million images that mostly contained buildings. This dataset was used for self-training using the Noisy Student method, in which the output of the best building detection model from the previous stage is used as a ‘teacher’ to then train a ‘student’ model that makes similar predictions from augmented images. In practice, we found that this reduced false positives and sharpened the detection output. The student model gave higher confidence to buildings and lower confidence to background.
 |
| Difference in model output between the student and teacher models for a typical image. In panel (d), red areas are those that the student model finds more likely to be buildings than the teacher model, and blue areas more likely to be background. |
One problem that we faced initially was that our model had a tendency to create “blobby” detections, without clearly delineated edges and with a tendency for neighbouring buildings to be merged together. To address this, we applied another idea from the original U-Net paper, which is to use distance weighting to adapt the loss function to emphasise the importance of making correct predictions near boundaries. During training, distance weighting places greater emphasis at the edges by adding weight to the loss — particularly where there are instances that nearly touch. For building detection, this encourages the model to correctly identify the gaps in between buildings, which is important so that many close structures are not merged together. We found that the original U-Net distance weighting formulation was helpful but slow to compute. So, we developed an alternative based on Gaussian convolution of edges, which was both faster and more effective.
 |
| Distance weighting schemes to emphasise nearby edges: U-Net (left) and Gaussian convolution of edges (right). |
Our technical report has more details on each of these methods.
Results
We evaluated the performance of the model on several different regions across the continent, in different categories: urban, rural, and medium-density. In addition, with the goal of preparing for potential humanitarian applications, we tested the model on regions with displaced persons and refugee settlements. Precision and recall did vary between regions, so achieving consistent performance across the continent is an ongoing challenge.
 |
| Precision-recall curves, measured at 0.5 intersection-over-union threshold. |
When visually inspecting the detections for low-scoring regions, we noted various causes. In rural areas, label errors were problematic. For example, single buildings within a mostly-empty area can be difficult for labellers to spot. In urban areas, the model had a tendency to split large buildings into separate instances. The model also underperformed in desert terrain, where buildings were hard to distinguish against the background.
We carried out an ablation study to understand which methods contributed most to the final performance, measured in mean average precision (mAP). Distance weighting, mixup and the use of ImageNet pre-training were the biggest factors for the performance of the supervised learning baseline. The ablated models that did not use these methods had a mAP difference of -0.33, -0.12 and -0.07 respectively. Unsupervised self-training gave a further significant boost of +0.06 mAP.
 |
| Ablation study of training methods. The first row shows the mAP performance of the best model combined with self-training, and the second row shows the best model with supervised learning only (the baseline). By disabling each training optimization from the baseline in turn, we observe the impact on mAP test performance. Distance weighting has the most significant effect. |
Generating the Open Buildings Dataset
To create the final dataset, we applied our best building detection model to satellite imagery across the African continent (8.6 billion image tiles covering 19.4 million km2, 64% of the continent), which resulted in the detection of 516M distinct structures.
Each building’s outline was simplified as a polygon and associated with a Plus Code, which is a geographic identifier made up of numbers and letters, akin to a street address, and useful for identifying buildings in areas that don’t have formal addressing systems. We also include confidence scores and guidance on suggested thresholds to achieve particular precision levels.

The sizes of the structures vary as shown below, tending towards small footprints. The inclusion of small structures is important, for example, to support analyses of informal settlements or refugee facilities.
 |
| Distribution of building footprint sizes. |
The data is freely available and we look forward to hearing how it is used. In the future, we may add new features and regions, depending on usage and feedback.
Acknowledgements
This work is part of our AI for Social Good efforts and was led by Google Research, Ghana. Thanks to the co-authors of this work: Wojciech Sirko, Sergii Kashubin, Marvin Ritter, Abigail Annkah, Yasser Salah Edine Bouchareb, Yann Dauphin, Daniel Keysers, Maxim Neumann and Moustapha Cisse. We are grateful to Abdoulaye Diack, Sean Askay, Ruth Alcantara and Francisco Moneo for help with coordination. Rob Litzke, Brian Shucker, Yan Mayster and Michelina Pallone provided valuable assistance with geo infrastructure.





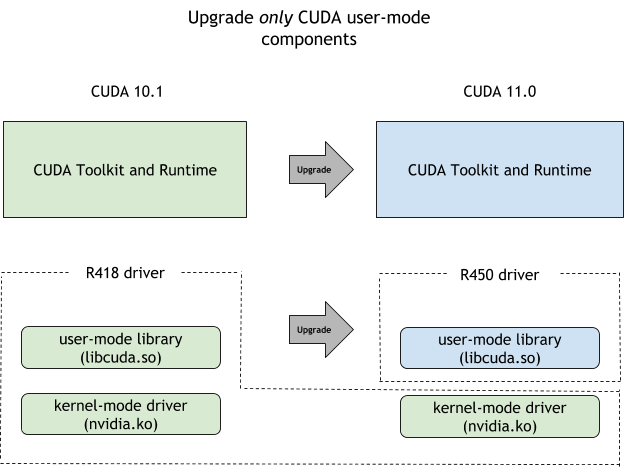
 NVIDIA announces the newest release of the CUDA development environment, CUDA 11.4. This release includes GPU-accelerated libraries, debugging and optimization tools, programming language enhancements, and a runtime library to build and deploy your application on GPUs across the major CPU architectures: x86, Arm, and POWER. CUDA 11.4 is focused on enhancing the programming model and …
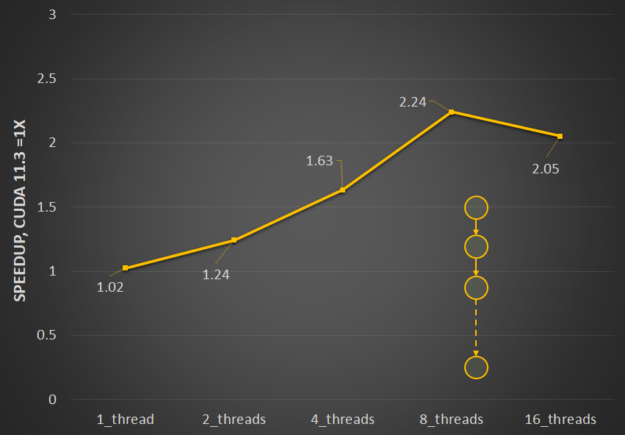
NVIDIA announces the newest release of the CUDA development environment, CUDA 11.4. This release includes GPU-accelerated libraries, debugging and optimization tools, programming language enhancements, and a runtime library to build and deploy your application on GPUs across the major CPU architectures: x86, Arm, and POWER. CUDA 11.4 is focused on enhancing the programming model and … 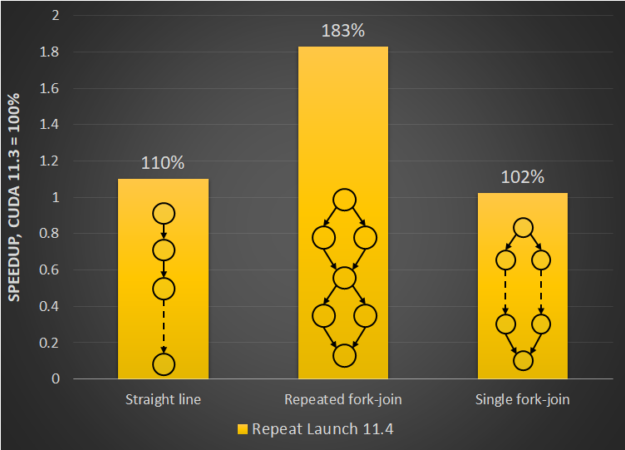
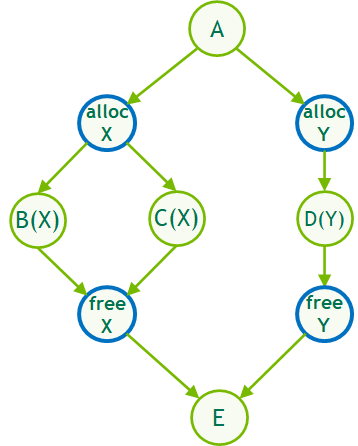
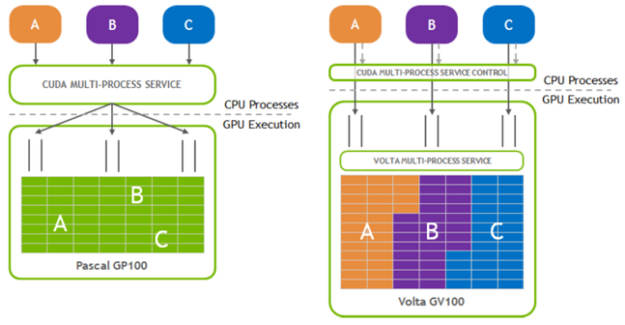
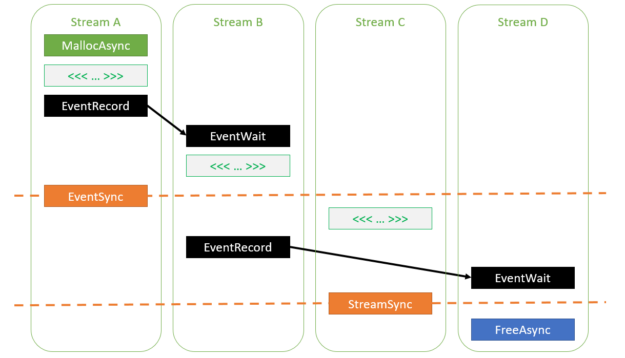
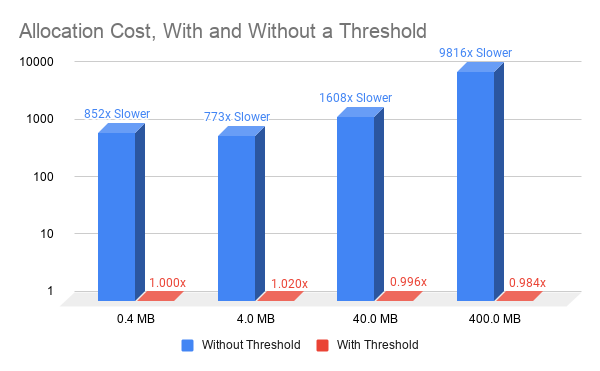
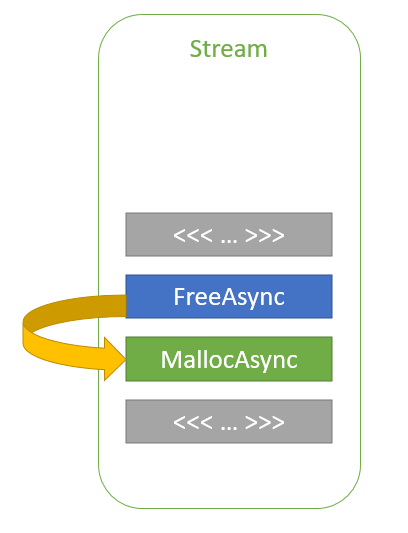
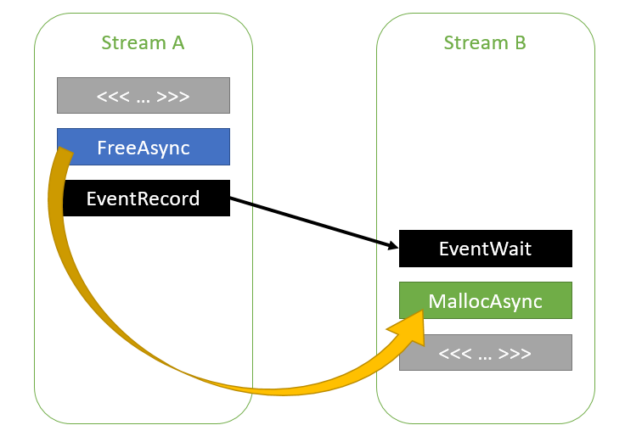
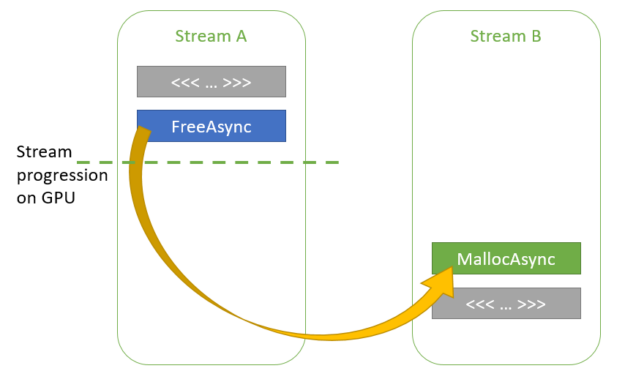
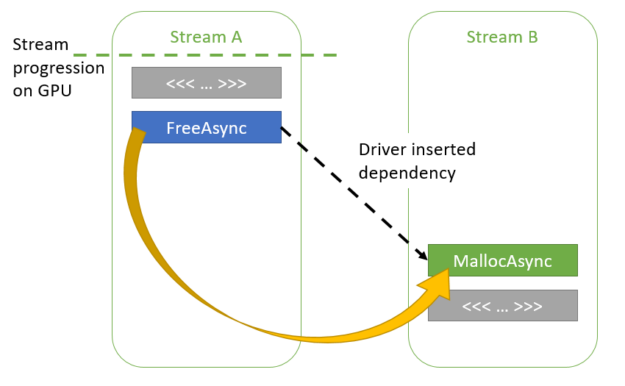
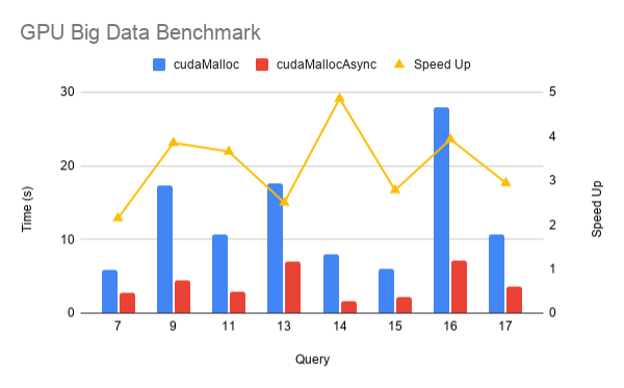
 Most CUDA developers are familiar with the cudaMalloc and cudaFree API functions to allocate GPU accessible memory. However, there has long been an obstacle with these API functions: they aren’t stream ordered. In this post, we introduce new API functions, cudaMallocAsync and cudaFreeAsync, that enable memory allocation and deallocation to be stream-ordered operations. In part …
Most CUDA developers are familiar with the cudaMalloc and cudaFree API functions to allocate GPU accessible memory. However, there has long been an obstacle with these API functions: they aren’t stream ordered. In this post, we introduce new API functions, cudaMallocAsync and cudaFreeAsync, that enable memory allocation and deallocation to be stream-ordered operations. In part …