
Looking at photos from the past can help people relive some of their most treasured moments. Last December we launched Cinematic photos, a new feature in Google Photos that aims to recapture the sense of immersion felt the moment a photo was taken, simulating camera motion and parallax by inferring 3D representations in an image. In this post, we take a look at the technology behind this process, and demonstrate how Cinematic photos can turn a single 2D photo from the past into a more immersive 3D animation.
| Camera 3D model courtesy of Rick Reitano. |
Depth Estimation
Like many recent computational photography features such as Portrait Mode and Augmented Reality (AR), Cinematic photos requires a depth map to provide information about the 3D structure of a scene. Typical techniques for computing depth on a smartphone rely on multi-view stereo, a geometry method to solve for the depth of objects in a scene by simultaneously capturing multiple photos at different viewpoints, where the distances between the cameras is known. In the Pixel phones, the views come from two cameras or dual-pixel sensors.
To enable Cinematic photos on existing pictures that were not taken in multi-view stereo, we trained a convolutional neural network with encoder-decoder architecture to predict a depth map from just a single RGB image. Using only one view, the model learned to estimate depth using monocular cues, such as the relative sizes of objects, linear perspective, defocus blur, etc.
Because monocular depth estimation datasets are typically designed for domains such as AR, robotics, and self-driving, they tend to emphasize street scenes or indoor room scenes instead of features more common in casual photography, like people, pets, and objects, which have different composition and framing. So, we created our own dataset for training the monocular depth model using photos captured on a custom 5-camera rig as well as another dataset of Portrait photos captured on Pixel 4. Both datasets included ground-truth depth from multi-view stereo that is critical for training a model.
Mixing several datasets in this way exposes the model to a larger variety of scenes and camera hardware, improving its predictions on photos in the wild. However, it also introduces new challenges, because the ground-truth depth from different datasets may differ from each other by an unknown scaling factor and shift. Fortunately, the Cinematic photo effect only needs the relative depths of objects in the scene, not the absolute depths. Thus we can combine datasets by using a scale-and-shift-invariant loss during training and then normalize the output of the model at inference.
The Cinematic photo effect is particularly sensitive to the depth map’s accuracy at person boundaries. An error in the depth map can result in jarring artifacts in the final rendered effect. To mitigate this, we apply median filtering to improve the edges, and also infer segmentation masks of any people in the photo using a DeepLab segmentation model trained on the Open Images dataset. The masks are used to pull forward pixels of the depth map that were incorrectly predicted to be in the background.

Camera Trajectory
There can be many degrees of freedom when animating a camera in a 3D scene, and our virtual camera setup is inspired by professional video camera rigs to create cinematic motion. Part of this is identifying the optimal pivot point for the virtual camera’s rotation in order to yield the best results by drawing one’s eye to the subject.
The first step in 3D scene reconstruction is to create a mesh by extruding the RGB image onto the depth map. By doing so, neighboring points in the mesh can have large depth differences. While this is not noticeable from the “face-on” view, the more the virtual camera is moved, the more likely it is to see polygons spanning large changes in depth. In the rendered output video, this will look like the input texture is stretched. The biggest challenge when animating the virtual camera is to find a trajectory that introduces parallax while minimizing these “stretchy” artifacts.
 |
| The parts of the mesh with large depth differences become more visible (red visualization) once the camera is away from the “face-on” view. In these areas, the photo appears to be stretched, which we call “stretchy artifacts”. |
Because of the wide spectrum in user photos and their corresponding 3D reconstructions, it is not possible to share one trajectory across all animations. Instead, we define a loss function that captures how much of the stretchiness can be seen in the final animation, which allows us to optimize the camera parameters for each unique photo. Rather than counting the total number of pixels identified as artifacts, the loss function triggers more heavily in areas with a greater number of connected artifact pixels, which reflects a viewer’s tendency to more easily notice artifacts in these connected areas.
We utilize padded segmentation masks from a human pose network to divide the image into three different regions: head, body and background. The loss function is normalized inside each region before computing the final loss as a weighted sum of the normalized losses. Ideally the generated output video is free from artifacts but in practice, this is rare. Weighting the regions differently biases the optimization process to pick trajectories that prefer artifacts in the background regions, rather than those artifacts near the image subject.
 |
| During the camera trajectory optimization, the goal is to select a path for the camera with the least amount of noticeable artifacts. In these preview images, artifacts in the output are colored red while the green and blue overlay visualizes the different body regions. |
Framing the Scene
Generally, the reprojected 3D scene does not neatly fit into a rectangle with portrait orientation, so it was also necessary to frame the output with the correct right aspect ratio while still retaining the key parts of the input image. To accomplish this, we use a deep neural network that predicts per-pixel saliency of the full image. When framing the virtual camera in 3D, the model identifies and captures as many salient regions as possible while ensuring that the rendered mesh fully occupies every output video frame. This sometimes requires the model to shrink the camera’s field of view.
 |
| Heatmap of the predicted per-pixel saliency. We want the creation to include as much of the salient regions as possible when framing the virtual camera. |
Conclusion
Through Cinematic photos, we implemented a system of algorithms – with each ML model evaluated for fairness – that work together to allow users to relive their memories in a new way, and we are excited about future research and feature improvements. Now that you know how they are created, keep an eye open for automatically created Cinematic photos that may appear in your recent memories within the Google Photos app!

Acknowledgments
Cinematic Photos is the result of a collaboration between Google Research and Google Photos teams. Key contributors also include: Andre Le, Brian Curless, Cassidy Curtis, Ce Liu, Chun-po Wang, Daniel Jenstad, David Salesin, Dominik Kaeser, Gina Reynolds, Hao Xu, Huiwen Chang, Huizhong Chen, Jamie Aspinall, Janne Kontkanen, Matthew DuVall, Michael Kucera, Michael Milne, Mike Krainin, Mike Liu, Navin Sarma, Orly Liba, Peter Hedman, Rocky Cai, Ruirui Jiang, Steven Hickson, Tracy Gu, Tyler Zhu, Varun Jampani, Yuan Hao, Zhongli Ding.

 This month, we spotlight Lorenzo Baraldi, Assistant Professor at the University of Modena and Reggio Emilia in Italy.
This month, we spotlight Lorenzo Baraldi, Assistant Professor at the University of Modena and Reggio Emilia in Italy.


 NVIDIA released NVIDIA Clara Parabricks Pipelines version 3.5, adding a set of new features to the software suite that accelerates end-to-end genome sequencing analysis.
NVIDIA released NVIDIA Clara Parabricks Pipelines version 3.5, adding a set of new features to the software suite that accelerates end-to-end genome sequencing analysis.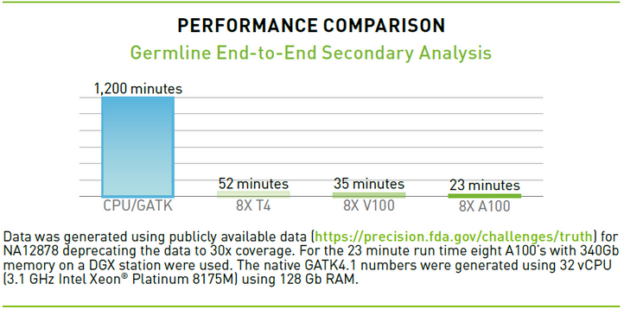
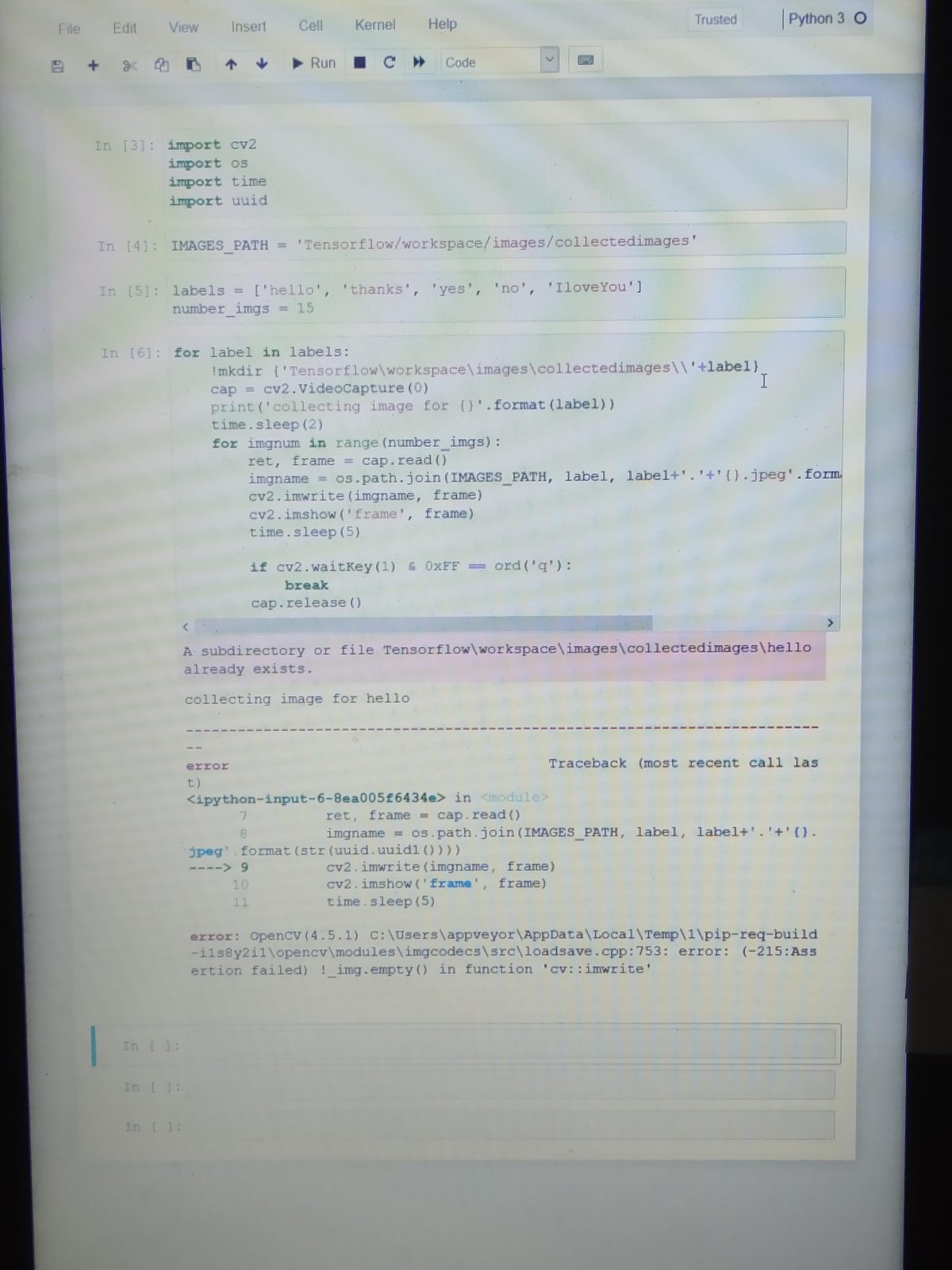
 Learn how to train your own gesture recognition deep learning pipeline. We’ll start with a pre-trained detection model, repurpose it for hand detection, and use it together with the purpose-built gesture recognition model.
Learn how to train your own gesture recognition deep learning pipeline. We’ll start with a pre-trained detection model, repurpose it for hand detection, and use it together with the purpose-built gesture recognition model.


{kind=link}