
 NVIDIA NeMo is a conversational AI toolkit built for researchers working on automatic speech recognition (ASR), natural language processing (NLP), and text-to-speech synthesis (TTS). The primary objective of NeMo is to help researchers from industry and academia to reuse prior work (code and pretrained models and make it easier to create new conversational AI models. … Continued
NVIDIA NeMo is a conversational AI toolkit built for researchers working on automatic speech recognition (ASR), natural language processing (NLP), and text-to-speech synthesis (TTS). The primary objective of NeMo is to help researchers from industry and academia to reuse prior work (code and pretrained models and make it easier to create new conversational AI models. … Continued
NVIDIA NeMo is a conversational AI toolkit built for researchers working on automatic speech recognition (ASR), natural language processing (NLP), and text-to-speech synthesis (TTS). The primary objective of NeMo is to help researchers from industry and academia to reuse prior work (code and pretrained models and make it easier to create new conversational AI models. NeMo is an open-source project, and we welcome contributions from the research community.
The 1.0 update brings significant architectural, code quality, and documentation improvements as well as a plethora of new state-of-the-art neural networks and pretrained checkpoints in several languages. The best way to start with NeMo is by installing it in your regular PyTorch environment:
pip install nemo_toolkit[all]
NeMo collections
NeMo is a PyTorch ecosystem project that relies heavily on two other projects from the ecosystem: PyTorch Lightning for training and Hydra for configuration management. You can also use NeMo models and modules within any PyTorch code.
NeMo comes with three main collections: ASR, NLP, and TTS. They are collections of models and modules that are ready to be reused in your conversational AI experiments. Most importantly, for most of the models, we provide weights pretrained on various datasets using tens of thousands of GPU hours.
Speech recognition
The NeMo ASR collection is the most extensive collection with a lot to offer for researchers of all levels, from beginners to advanced. If you are new to deep learning for speech recognition, we recommend that you get started with an interactive notebook for both ASR and NeMo overview. If you are an experienced researcher looking to create your own model, you’ll find various ready-to-use building blocks:
- Data layers
- Encoders
- Augmentation modules
- Text normalization and denormalization
- More advanced decoders, such as RNN-T
The NeMo ASR collection provides you with various types of ASR networks: Jasper, QuartzNet, CitriNet, and Conformer. With the NeMo 1.0 update, the CitriNet and Conformer models are the next flagship ASR models providing better accuracy on word-error-rate (WER) than Jasper and QuartzNet while maintaining similar or better efficiency.
CitriNet
CitriNet is an improvement upon QuartzNet that uses several ideas originally introduced in ContextNet. It uses subword encoding through word piece tokenization and Squeeze-and-Excitation mechanism to obtain highly accurate audio transcripts while using a nonautoregressive, CTC-based decoding scheme for efficient inference.
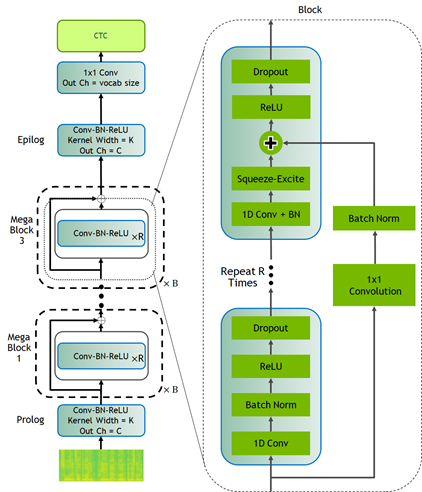
Conformer-CTC
Conformer-CTC is a CTC-based variant of the Conformer model that uses CTC loss and decoding instead of RNN-T loss, making it a nonautoregressive model. This model combines self-attention and convolution modules to achieve the best of both worlds. The self-attention modules can learn the global interaction while the convolutions efficiently capture the local correlations.
This model gives you an option to experiment with attention-based models. Due to the global context obtained by self-attention and squeeze-and-excitation mechanism, Conformer and CitriNet models have superior WER in offline scenarios.
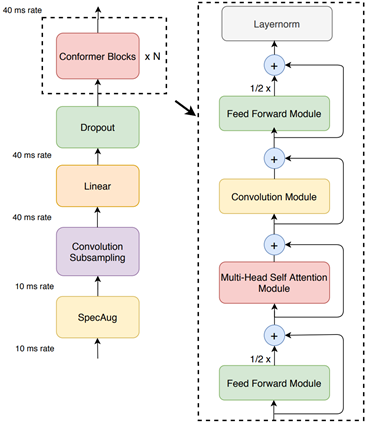
You can use Citrinet and Conformer models with CTC as well as RNN-T decoders.
We spent tens of thousands of GPU hours training ASR models in various languages. In NeMo, we offer these checkpoints back to the community for free. As of this release, NeMo has ASR models in English, Spanish, Chinese, Catalonian, Italian, Russian, French, and Polish. Moreover, we partner with Mozilla to make more pretrained models available with the help of Mozilla Common Voice project.
Finally, NeMo’s ASR collection contains reusable building blocks and pretrained models for various other important speech-based tasks such as: voice activity detection, speaker recognition, diarization, and voice command detection.
Natural language processing
Natural language processing (NLP) is essential for providing a great conversational AI experience. The NeMo NLP collection provides a set of pretrained models for typical NLP tasks such as question answering, punctuation and capitalization, named entity recognition, and neural machine translation.
Hugging Face transformers have fueled many recent advances in NLP by providing a huge set of pretrained models and an easy-to-use experience for developers and researchers. NeMo is compatible with transformers in that most of the pretrained Hugging Face NLP models can be imported into NeMo. You may provide pretrained BERT-like checkpoints from transformers for the encoders of common tasks. The language models of the common tasks are initialized in default with the pretrained model from Hugging Face transformers.
NeMo is also integrated with models trained by NVIDIA Megatron, allowing you to incorporate Megatron-based encoders into your question answering and neural machine translation models. NeMo can be used to fine-tune model-parallel models based on Megatron.
Neural machine translation
In today’s globalized world, it has become important to communicate with people speaking different languages. A conversational AI system capable of converting source text from one language to another will be a powerful communication tool. NeMo 1.0 now supports neural machine translation (NMT) tasks with transformer-based models allowing you to quickly build an end-to-end language translation pipelines. This release includes pretrained NMT models for the following language pairs in both directions:
- English Spanish
- English Russian
- English Mandarin
- English German
- English French
Because tokenization is an extremely important part of NLP and NeMo supports most widely used tokenizers, such as HF tokenizers, SentencePiece, and YouTokenToMe.
Speech synthesis
If humans can talk to computers, the computers should be able to talk back as well. Speech synthesis takes text as an input and generates humanized audio output. This is typically accomplished with two models: a spectrogram generator that generates spectrograms from text and a vocoder that generates audio from spectrogram. The NeMo TTS collection provides you with the following models:
- Pretrained spectrogram generator models: Tacotron2, GlowTTS, Fastspeech, Fastpitch, and Talknet
- Pretrained vocoder models: HiFiGan, MelGan, SqueezeWave, Uniglow, and WaveGlow
- End-to-end models: FastPitchHiFiGAN and Fastspeech2 Hifigan
End-to-end conversational AI example
Here’s a simple example demonstrating how to use NeMo for prototyping a universal translator app. This app takes a Russian audio file and generates an English translation audio. You can play with it using the AudioTranslationSample.ipynb notebook.
# Start by importing NeMo and all three collections
import nemo
import nemo.collections.asr as nemo_asr
import nemo.collections.nlp as nemo_nlp
import nemo.collections.tts as nemo_tts
# Next, automatically download pretrained models from the NGC cloud
quartznet = nemo_asr.models.EncDecCTCModel.from_pretrained(model_name="stt_ru_quartznet15x5")
# Neural Machine Translation model
nmt_model = nemo_nlp.models.MTEncDecModel.from_pretrained(model_name='nmt_ru_en_transformer6x6')
# Spectrogram generator that takes text as an input and produces spectrogram
spectrogram_generator = nemo_tts.models.Tacotron2Model.from_pretrained(model_name="tts_en_tacotron2")
# Vocoder model that takes spectrogram and produces actual audio
vocoder = nemo_tts.models.WaveGlowModel.from_pretrained(model_name="tts_waveglow_88m")
# First step is to transcribe, or recognize, what was said in the audio
russian_text = quartznet.transcribe([Audio_sample])
# Then, translate it to English text
english_text = nmt_model.translate(russian_text)
# Finally, convert it into English audio
# A helper function that combines Tacotron2 and WaveGlow to go directly from
# text to audio
def text_to_audio(text):
parsed = spectrogram_generator.parse(text)
spectrogram = spectrogram_generator.generate_spectrogram(tokens=parsed)
audio = vocoder.convert_spectrogram_to_audio(spec=spectrogram)
return audio.to('cpu').numpy()
audio = text_to_audio(english_text[0])
The best part of this example is that you can fine-tune all the models used here on your datasets. In-domain fine-tuning is a great way to improve the performance of your models on specific applications. The NeMo GitHub repo provides plenty of fine-tuning examples.
NeMo models have a common look and feel, regardless of domain. They are configured, trained, and used in a similar fashion.
Scaling with NeMo
An ability to run experiments and quickly test new ideas is key to successful research. With NeMo, you can speed up training by using the latest NVIDIA Tensor Cores and model parallel training features across many nodes and hundreds of GPUs. Much of this functionality is provided with the help of the PyTorch Lightning trainer, which has an intuitive and easy-to-use API.
For speech recognition, language modeling, and machine translation, we provide high-performance web dataset-based data loaders. These data loaders can handle scaling to tens of thousands of hours of speech data to deliver high performance in massively distributed settings with thousands of GPUs.
Text processing and dataset creation with NeMo
Proper preparation of training data and pre and post-processing are hugely important and often overlooked steps in all machine learning pipelines. NeMo 1.0 includes new features for dataset creation and speech data explorer.
NeMo 1.0 includes important text processing features such as text normalization and inverse text normalization. Text normalization converts text from written form into its verbalized form. It is used as a preprocessing step before training TTS models. It could also be used for preprocessing ASR training transcripts. Inverse text normalization (ITN) is a reverse operation and is often a part of the ASR post-processing pipeline. It is the task of converting the raw spoken output of the ASR model into its written form to improve text readability.
For example, the normalized version of “It weighs 10 kg.” would be “It weighs 10 kilograms”.
Conclusion
NeMo 1.0 release substantially improves overall quality and documentation. It adds support for new tasks such as neural machine translation and many new models pretrained in different languages. As a mature tool for ASR and TTS, it also adds new features for text normalization and denormalization, dataset creation based on CTC-segmentation and speech data explorer. These updates benefit researchers in academia and industry by making it easier for you to develop and train new conversational AI models.
Many NeMo models can be exported to NVIDIA Jarvis for production deployment and high-performance inference. NVIDIA Jarvis is an application framework for building multimodal conversational AI services that delivers real-time performance on GPUs.
We welcome external contributions! On the NVIDIA NeMo GitHub page, you can try out the examples, participate in community discussions, and take your models from research to production using NeMo and NVIDIA Jarvis.