
This fall Pixel 6 phones launched with Google Tensor, Google’s first mobile system-on-chip (SoC), bringing together various processing components (such as central/graphic/tensor processing units, image processors, etc.) onto a single chip, custom-built to deliver state-of-the-art innovations in machine learning (ML) to Pixel users. In fact, every aspect of Google Tensor was designed and optimized to run Google’s ML models, in alignment with our AI Principles. That starts with the custom-made TPU integrated in Google Tensor that allows us to fulfill our vision of what should be possible on a Pixel phone.
Today, we share the improvements in on-device machine learning made possible by designing the ML models for Google Tensor’s TPU. We use neural architecture search (NAS) to automate the process of designing ML models, which incentivize the search algorithms to discover models that achieve higher quality while meeting latency and power requirements. This automation also allows us to scale the development of models for various on-device tasks. We’re making these models publicly available through the TensorFlow model garden and TensorFlow Hub so that researchers and developers can bootstrap further use case development on Pixel 6. Moreover, we have applied the same techniques to build a highly energy-efficient face detection model that is foundational to many Pixel 6 camera features.
 |
| An illustration of NAS to find TPU-optimized models. Each column represents a stage in the neural network, with dots indicating different options, and each color representing a different type of building block. A path from inputs (e.g., an image) to outputs (e.g., per-pixel label predictions) through the matrix represents a candidate neural network. In each iteration of the search, a neural network is formed using the blocks chosen at every stage, and the search algorithm aims to find neural networks that jointly minimize TPU latency and/or energy and maximize accuracy. |
Search Space Design for Vision Models
A key component of NAS is the design of the search space from which the candidate networks are sampled. We customize the search space to include neural network building blocks that run efficiently on the Google Tensor TPU.
One widely-used building block in neural networks for various on-device vision tasks is the Inverted Bottleneck (IBN). The IBN block has several variants, each with different tradeoffs, and is built using regular convolution and depthwise convolution layers. While IBNs with depthwise convolution have been conventionally used in mobile vision models due to their low computational complexity, fused-IBNs, wherein depthwise convolution is replaced by a regular convolution, have been shown to improve the accuracy and latency of image classification and object detection models on TPU.
However, fused-IBNs can have prohibitively high computational and memory requirements for neural network layer shapes that are typical in the later stages of vision models, limiting their use throughout the model and leaving the depthwise-IBN as the only alternative. To overcome this limitation, we introduce IBNs that use group convolutions to enhance the flexibility in model design. While regular convolution mixes information across all the features in the input, group convolution slices the features into smaller groups and performs regular convolution on features within that group, reducing the overall computational cost. Called group convolution–based IBNs (GC-IBNs), their tradeoff is that they may adversely impact model quality.
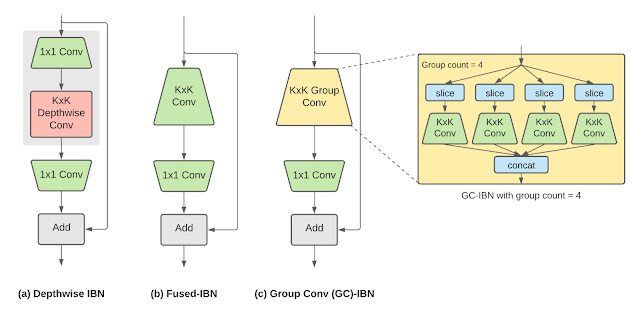 |
| Inverted bottleneck (IBN) variants: (a) depthwise-IBN, depthwise convolution layer with filter size KxK sandwiched between two convolution layers with filter size 1×1; (b) fused-IBN, convolution and depthwise are fused into a convolution layer with filter size KxK; and (c) group convolution–based GC-IBN that replaces with the KxK regular convolution in fused-IBN with group convolution. The number of groups (group count) is a tunable parameter during NAS. |
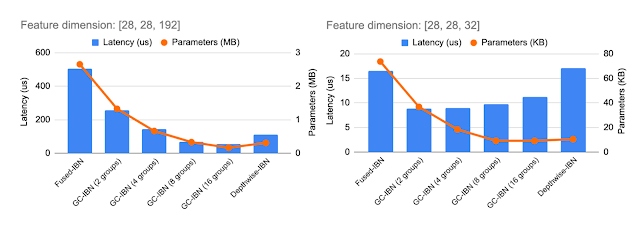 |
| Inclusion of GC-IBN as an option provides additional flexibility beyond other IBNs. Computational cost and latency of different IBN variants depends on the feature dimensions being processed (shown above for two example feature dimensions). We use NAS to determine the optimal choice of IBN variants. |
Faster, More Accurate Image Classification
Which IBN variant to use at which stage of a deep neural network depends on the latency on the target hardware and the performance of the resulting neural network on the given task. We construct a search space that includes all of these different IBN variants and use NAS to discover neural networks for the image classification task that optimize the classification accuracy at a desired latency on TPU. The resulting MobileNetEdgeTPUV2 model family improves the accuracy at a given latency (or latency at a desired accuracy) compared to the existing on-device models when run on the TPU. MobileNetEdgeTPUV2 also outperforms their predecessor, MobileNetEdgeTPU, the image classification models designed for the previous generation of the TPU.
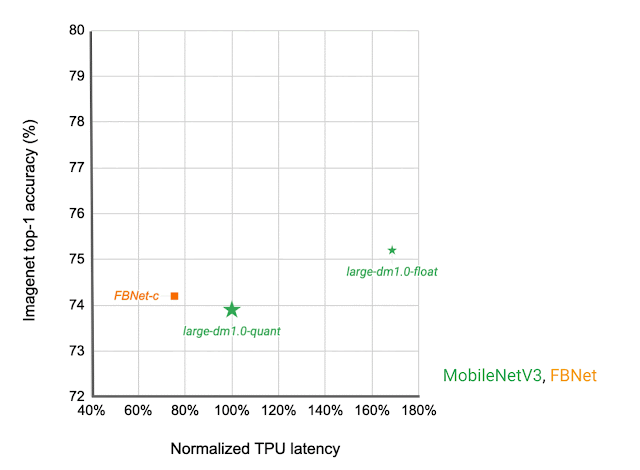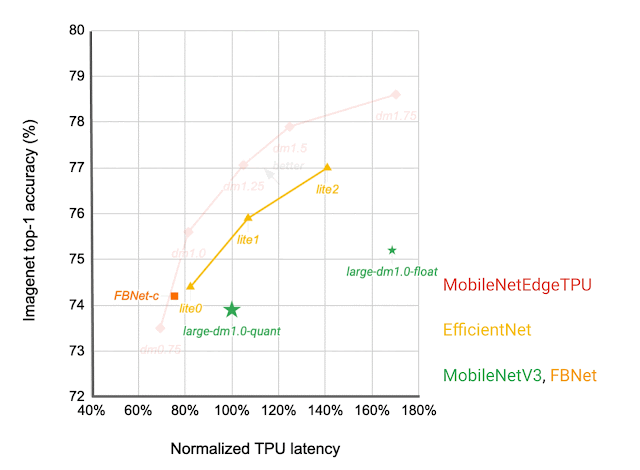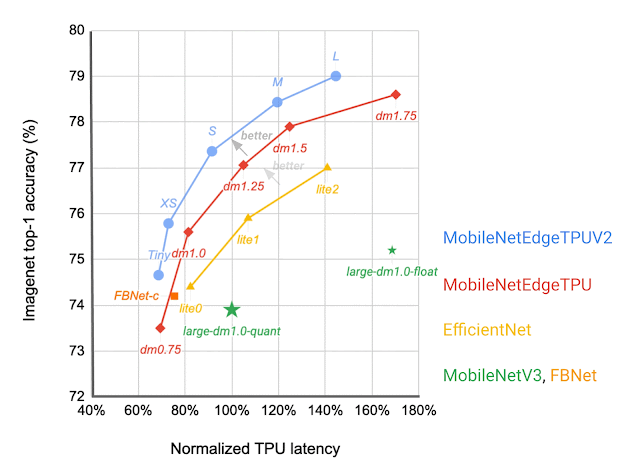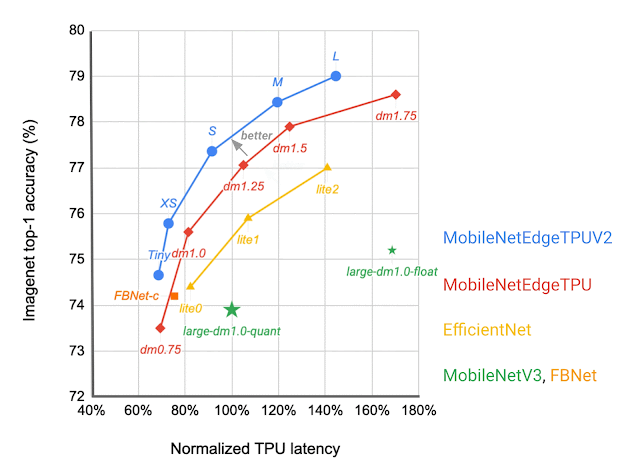 |
| Network architecture families visualized as connected dots at different latency targets. Compared with other mobile models, such as FBNet, MobileNetV3, and EfficientNets, MobileNetEdgeTPUV2 models achieve higher ImageNet top-1 accuracy at lower latency when running on Google Tensor’s TPU. |
MobileNetEdgeTPUV2 models are built using blocks that also improve the latency/accuracy tradeoff on other compute elements in the Google Tensor SoC, such as the CPU. Unlike accelerators such as the TPU, CPUs show a stronger correlation between the number of multiply-and-accumulate operations in the neural network and latency. GC-IBNs tend to have fewer multiply-and-accumulate operations than fused-IBNs, which leads MobileNetEdgeTPUV2 to outperform other models even on Pixel 6 CPU.
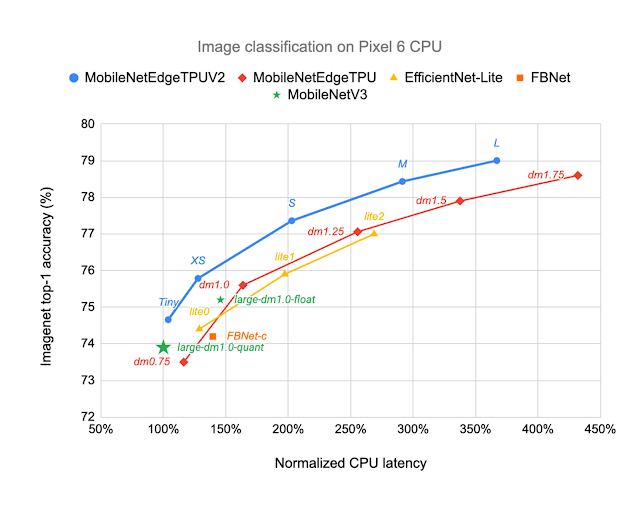 |
| MobileNetEdgeTPUV2 models achieve ImageNet top-1 accuracy at lower latency on Pixel 6 CPU, and outperform other CPU-optimized model architectures, such as MobileNetV3. |
Improving On-Device Semantic Segmentation
Many vision models consist of two components, the base feature extractor for understanding general features of the image, and the head for understanding domain-specific features, such as semantic segmentation (the task of assigning labels, such as sky, car, etc., to each pixel in an image) and object detection (the task of detecting instances of objects, such as cats, doors, cars, etc., in an image). Image classification models are often used as feature extractors for these vision tasks. As shown below, the MobileNetEdgeTPUV2 classification model coupled with the DeepLabv3+ segmentation head improves the quality of on-device segmentation.
To further improve the segmentation model quality, we use the bidirectional feature pyramid network (BiFPN) as the segmentation head, which performs weighted fusion of different features extracted by the feature extractor. Using NAS we find the optimal configuration of blocks in both the feature extractor and the BiFPN head. The resulting models, named Autoseg-EdgeTPU, produce even higher-quality segmentation results, while also running faster.
The final layers of the segmentation model contribute significantly to the overall latency, mainly due to the operations involved in generating a high resolution segmentation map. To optimize the latency on TPU, we introduce an approximate method for generating the high resolution segmentation map that reduces the memory requirement and provides a nearly 1.5x speedup, without significantly impacting the segmentation quality.
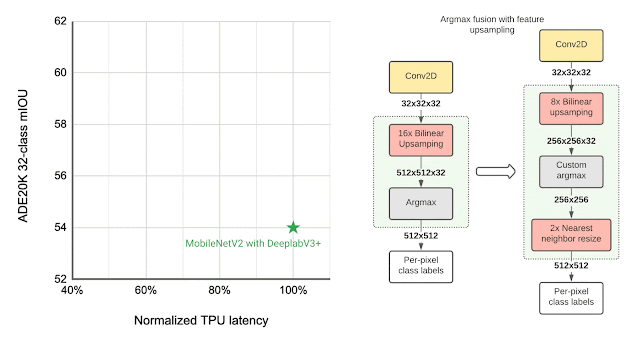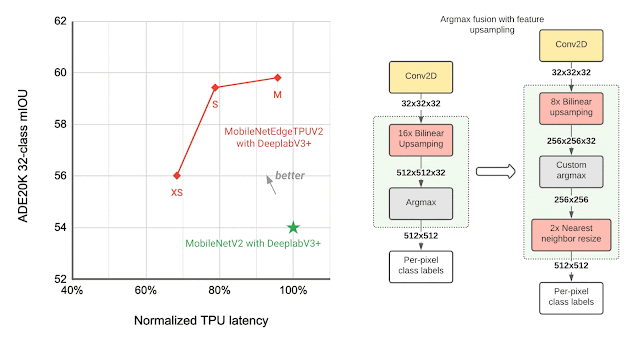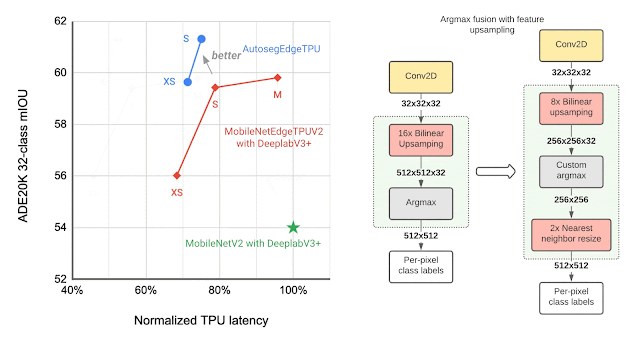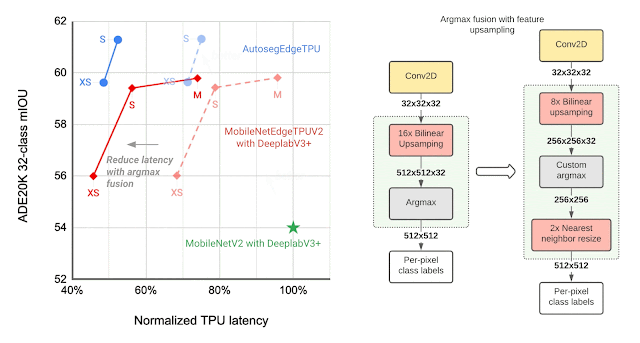 |
| Left: Comparing the performance, measured as mean intersection-over-union (mIOU), of different segmentation models on the ADE20K semantic segmentation dataset (top 31 classes). Right: Approximate feature upsampling (e.g., increasing resolution from 32×32 → 512×512). Argmax operation used to compute per-pixel labels is fused with the bilinear upsampling. Argmax performed on smaller resolution features reduces memory requirements and improves latency on TPU without a significant impact to quality. |
Higher-Quality, Low-Energy Object Detection
Classic object detection architectures allocate ~70% of the compute budget to the feature extractor and only ~30% to the detection head. For this task we incorporate the GC-IBN blocks into a search space we call “Spaghetti Search Space”1, which provides the flexibility to move more of the compute budget to the head. This search space also uses the non-trivial connection patterns seen in recent NAS works such as MnasFPN to merge different but related stages of the network to strengthen understanding.
We compare the models produced by NAS to MobileDet-EdgeTPU, a class of mobile detection models customized for the previous generation of TPU. MobileDets have been demonstrated to achieve state-of-the-art detection quality on a variety of mobile accelerators: DSPs, GPUs, and the previous TPU. Compared with MobileDets, the new family of SpaghettiNet-EdgeTPU detection models achieves +2.2% mAP (absolute) on COCO at the same latency and consumes less than 70% of the energy used by MobileDet-EdgeTPU to achieve similar accuracy.
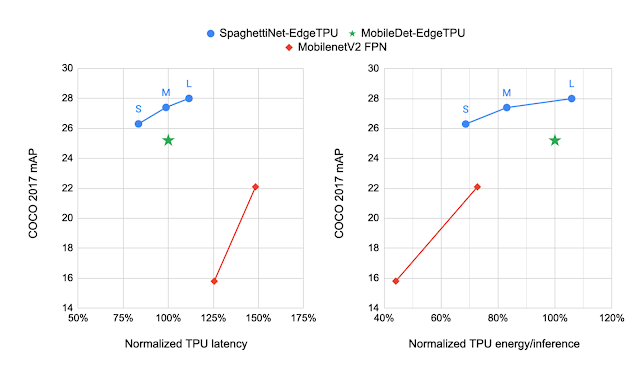 |
| Comparing the performance of different object detection models on the COCO dataset with the mAP metric (higher is better). SpaghettiNet-EdgeTPU achieves higher detection quality at lower latency and energy consumption compared to previous mobile models, such as MobileDets and MobileNetV2 with Feature Pyramid Network (FPN). |
Inclusive, Energy-Efficient Face Detection
Face detection is a foundational technology in cameras that enables a suite of additional features, such as fixing the focus, exposure and white balance, and even removing blur from the face with the new Face Unblur feature. Such features must be designed responsibly, and Face Detection in the Pixel 6 were developed with our AI Principles top of mind.
 |
| Left: The original photo without improvements. Right: An unblurred face in a dynamic environment. This is the result of Face Unblur combined with a more accurate face detector running at a higher frames per second. |
Since mobile cameras can be power-intensive, it was important for the face detection model to fit within a power budget. To optimize for energy efficiency, we used the Spaghetti Search Space with an algorithm to search for architectures that maximize accuracy at a given energy target. Compared with a heavily optimized baseline model, SpaghettiNet achieves the same accuracy at ~70% of the energy. The resulting face detection model, called FaceSSD, is more power-efficient and accurate. This improved model, combined with our auto-white balance and auto-exposure tuning improvements, are part of Real Tone on Pixel 6. These improvements help better reflect the beauty of all skin tones. Developers can utilize this model in their own apps through the Android Camera2 API.
Toward Datacenter-Quality Language Models on a Mobile Device
Deploying low-latency, high-quality language models on mobile devices benefits ML tasks like language understanding, speech recognition, and machine translation. MobileBERT, a derivative of BERT, is a natural language processing (NLP) model tuned for mobile CPUs.
However, due to the various architectural optimizations made to run these models efficiently on mobile CPUs, their quality is not as high as that of the large BERT models. Since MobileBERT on TPU runs significantly faster than on CPU, it presents an opportunity to improve the model architecture further and reduce the quality gap between MobileBERT and BERT. We extended the MobileBERT architecture and leveraged NAS to discover models that map well to the TPU. These new variants of MobileBERT, named MobileBERT-EdgeTPU, achieve up to 2x higher hardware utilization, allowing us to deploy large and more accurate models on TPU at latencies comparable to the baseline MobileBERT.
MobileBERT-EdgeTPU models, when deployed on Google Tensor’s TPU, produce on-device quality comparable to the large BERT models typically deployed in data centers.
 |
| Performance on the question answering task (SQuAD v 1.1). While the TPU in Pixel 6 provides a ~10x acceleration over CPU, further model customization for the TPU achieves on-device quality comparable to the large BERT models typically deployed in data centers. |
Conclusion
In this post, we demonstrated how designing ML models for the target hardware expands the on-device ML capabilities of Pixel 6 and brings high-quality, ML-powered experiences to Pixel users. With NAS, we scaled the design of ML models to a variety of on-device tasks and built models that provide state-of-the-art quality on-device within the latency and power constraints of a mobile device. Researchers and ML developers can try out these models in their own use cases by accessing them through the TensorFlow model garden and TF Hub.
Acknowledgements
This work is made possible through a collaboration spanning several teams across Google. We’d like to acknowledge contributions from Rachit Agrawal, Berkin Akin, Andrey Ayupov, Aseem Bathla, Gabriel Bender, Po-Hsein Chu, Yicheng Fan, Max Gubin, Jaeyoun Kim, Quoc Le, Dongdong Li, Jing Li, Yun Long, Hanxiao Lu, Ravi Narayanaswami, Benjamin Panning, Anton Spiridonov, Anakin Tung, Zhuo Wang, Dong Hyuk Woo, Hao Xu, Jiayu Ye, Hongkun Yu, Ping Zhou, and Yanqi Zhuo. Finally, we’d like to thank Tom Small for creating illustrations for this blog post.
1The resulting architectures tend to look like spaghetti because of the connection patterns formed between blocks. ↩
